基于深度迁移学习的糖尿病视网膜病变的检测
2020-12-08闫育铭罗德名尹思源傅笑添
闫育铭,李 峰,罗德名,尹思源,傅笑添,刘 峥,严 磊
(上海理工大学 光电信息与计算机工程学院,上海 200093)
引言
在过去的几十年里,患糖尿病的人数急剧增加,到2035年中国有近1.1亿糖尿病患者[1]。糖尿病可发展为影响心脏、血管、眼睛、肾脏和神经的疾病。糖尿病的主要并发症之一是视网膜病变,即糖尿病视网膜病变(DR)[2]。DR可以影响眼睛,损害视力,甚至导致失明。如果在其初始阶段未发现,可导致视力损害或永久性失明[3-4]。因此,为了将视力损害控制到最低程度,早期的诊断、定期的眼科检查和及时的治疗是非常必要的。
目前,已经开发了许多用于糖尿病视网膜病变自动检测的算法。Li等[5]采用一种自动提取眼底图像主要特征的方法,但是病变检测的准确性易受到病变大小的影响。Haloi等[6]提出了一种基于深度学习的像素智能微动脉瘤(MA)分类方法,但是测试过程中很容易将其他类型的小病变误解为MA。此外,Gulshan等[7]应用深度学习训练空白的Inception-v3模型,但这需要数周的时间。Xu等[8]提出了深度卷积神经网络方法,其中DR图像分类任务的数据增强优于传统基于特征提取方法获得的结果。然而仅有800个标记的眼底图像用于训练,训练周期需要2天。
综上所述,在鲁棒分类算法和自动识别性能方面仍存在着巨大挑战。因此,DR的自动一致性筛选的实际临床应用是有限的。为了最大限度地提高自动分级的临床效果,本文介绍了一种基于深度迁移学习的卷积神经网络方法,用于在眼底图像中对DR进行分类。如前所述,在过去的工作中曾进行过许多研究,这是一项医学成像融合了诊断相关性的任务。我们引入迁移学习方法使卷积神经网络(CNN)适应自行收集的数据集,然后分析网络性能并评价网络的功能。
1 迁移学习算法
1.1 算法框架
选择Inception-v3网络作为深度学习[9]的基础网络。首先,Inception-v3已经在ImageNet数据集[10]上进行了训练,ImageNet包括1 000个类别,训练得到的分类器可识别1 000种图像。然后在已经训练的Inception-v3网络基础上重新训练DR图像,将每个图像的像素强度和相关标签作为新输入送到该网络的瓶颈层中,通过减小所生成输出与基准值标签产生的误差自动调整网络参数,训练出一个新的分类器。方法框架如图1所示。采用基于Inception-v3网络的深度迁移学习方法对视网膜眼底图像进行分类。

图1 方法流程图Fig.1 Method flowchart
1.2 基于CLAHE的图像预处理
为了校正由非均匀照明引起的图像背景强度的潜在变化从而进一步增强图像的特征,对DR图像运用了对比度有限自适应直方图均衡(CLAHE)方法以增强DR病理体征和背景之间的对比度,如图2所示。CLAHE的核心在对灰度图像进行直方图均衡处理的基础上进行改进,考虑了周围区域对局部区域的影响。局部直方图可表示为
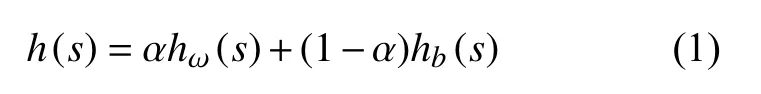
式中:s是灰度级;hω(s) 被视为图像中的归一化直方图;hb(s) 表示图像外的归一化直方图;α则指图像外部环境对图像内转换的影响,需满足0≤α≤1的要求。
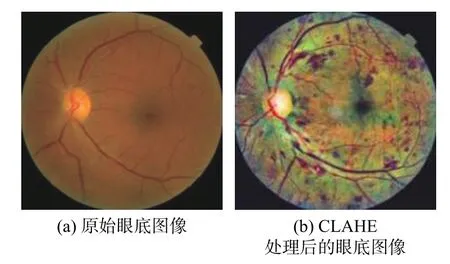
图2 眼底图片预处理示例Fig.2 Example of the preprocessing of fundus images
CLAHE方法可以有效地改善图像的局部对比度,从而可以获得更多的图像特征信息。此外,实验中还利用了卷积神经网络的自编码器结合CLAHE数据预处理方法,通过对数据集中的少数类样本进行训练,用生成器产生相似样本数据以降低原始数据的不平衡度,最后将平衡后的数据作为输入数据进行训练。
1.3 基于Inception-v3的深度迁移学习
实验基于Keras学习框架予以实现,借助TensorFlow后端进行实验操作。将网络的学习率设置为0.001,利用随机梯度下降(SGD)优化器,以每步100个图像批量训练网络层,直到再提高训练步数,准确性和交叉熵损失值都不会得到进一步改善,此时共计训练了50 000步。

图3 不同扩张率下的膨胀卷积Fig.3 The dilated convolution corresponding to different expansion rates
首先,使用从ImageNet数据集获得的预训练权重对卷积层进行初始化,以减少冗余过程实现加速训练。接着随机初始化Inception-v3模型中末端全连接层的权重,将新初始化的Inceptionv3从瓶颈层之前的所有卷积层和相应的最大池化层冻结起来,作为固定特征提取器。然后每个需要再训练和验证的DR图像在通过冻结层后作为瓶颈层的输入值送到神经网络中,通过学习计算ImageNet图像和DR图像数据集之间的特征空间偏移,将末端完全连接层由原来的1 000个输出类别调整为新的5个输出类别,即没有明显DR、轻度非增生性糖尿病视网膜病变(轻度NPDR)、中度非增生性糖尿病视网膜病变(中度NPDR)、严重非增生性糖尿病视网膜病变(严重NPDR)和增生性糖尿病视网膜病变(PDR)。在进一步训练过程中,尝试使用预训练的权重解冻并在我们的DR图像中使用反向传播进行更新,以便对卷积层进行微调,从而避免过度拟合。
在该网络中,我们尝试使用随机梯度下降优化器,同时考虑在训练过程中使用自适应学习率。在训练了5个时期之后学习率降低至初始值的10%,而验证集的准确性没有提高。考虑Inception-v3模型随着网络层数的不断加深,特征图的空间分辨率会逐渐降低。为了降低这种影响,本文在Inception-v3网络的卷积层中引入了膨胀卷积策略。膨胀卷积的原理如图3所示,图3(a)表示扩张率为1时的卷积核,相当于网络进行正常的3×3卷积操作,图3(b)表示扩张率为2时的卷积核,相当于5×5正常卷积核的感受野,图3(c)表示扩张率为3时的卷积核,相当于7×7正常卷积核的感受野。引入的膨胀卷积可以在不增加算法参数复杂度的情况下增大网络的感受野,从而提高网络捕捉特征信息的能力。此外在每个卷积层后增加了批归一化层,以减少中间变量迁移的问题,有利于加快神经网络训练过程收敛速度,避免了结构复杂度导致梯度消失的问题。
神经网络解决多分类问题的方法中,原始输出不是一个概率值,实质上只是输入的数值作了复杂的加权与非线性处理之后得到的一个值。为了将这个输出变成概率分布,需要使用Softmax层,根据瓶颈张量的数据生成概率。该瓶颈张量是通过增加偏差的像素强度检测权重之和计算的,描述如下:

式中:i是对应于给定输入的分类;ωi和bi分别表示权重和偏差;j是用于对输入中的像素求和的索引。
然后使用Softmax回归处理计算概率,可表示为

这里给定一个n维向量,Softmax回归函数计算概率,可以生成0~1范围内的相同维度向量,用于度量两个概率分布之间的相似性。
实验目的是预测每个输入的DR图像标签类别,并对其进行分类。一般情况下,对于分类任务,在神经网络中使用较多的损失函数是交叉熵。交叉熵损失函数用来评估当前训练得到的概率分布和真实分布之间的差异情况,通过减少交叉熵损失,从而提高模型的预测准确率。Softmax与交叉熵损失函数结合作为Softmax-交叉熵损失函数,用作Inception-v3网络的损失函数[11]。
假设现在有m组训练样本,···,其中x(i)是输入特征,y(i)是对应的类别标签。模型的参数 θ=(θ0,θ1,···,θn)T,则交叉熵损失函数的计算公式为

式中:1{∗} 是一个指示函数,当花括号内的值为真的时候,输出1,为假时则输出0。代表当输入样本为x(i)、模型参数为 θ 时分类标签y(i)的概率。
交叉熵刻画的是实际输出的概率与期望输出的概率之间的距离,交叉熵的值越小,两个概率分布就越接近。训练模型时,Softmax-交叉熵损失函数要求输入的标签必须是经过独立编码的数据,最终输出的是一个批次中每个样本的损失。
2 实 验
2.1 图像收集
本文使用的数据集来自上海市第一人民医院,基于眼底图像中各种DR的存在和严重程度,对每个图像使用识别号进行编码,并根据国际临床糖尿病视网膜病变(ICDR)严重程度来进行度量,由3位有经验的眼科医师分配DR严重程度[12]。评分是在全屏、高分辨率27 inch (1inch=2.54 cm)显示器上进行的。通过进一步分析,排除了由未对准、切片模糊导致的图像分辨率降低,同时排除某2种或多种异常共存以及除4种异常之外异常存在严重伪影的眼底图像。每个图像与诊断标签0、1、2、3、4相关联,表示无明显DR、轻度NPDR、中度NPDR、严重NPDR和PDR,如图4所示。只有专家之间具有明确共识注释的图像才被收入样本并导入数据库。同时由此产生的评估集由另一位资深专家作进一步检查,以避免评分中的任何错误。对于图像标签的不同意见,由高级眼科医生组成的专家委员会对其进行评估。数据集的选择和分配显示在图5中。其中,“转诊”被定义为中度NPDR或更严重的存在,且对没有明显DR或轻度NPDR症状而没有临床显著黄斑水肿(CSME)的患者提供“无需转诊”的推荐[13-14]。
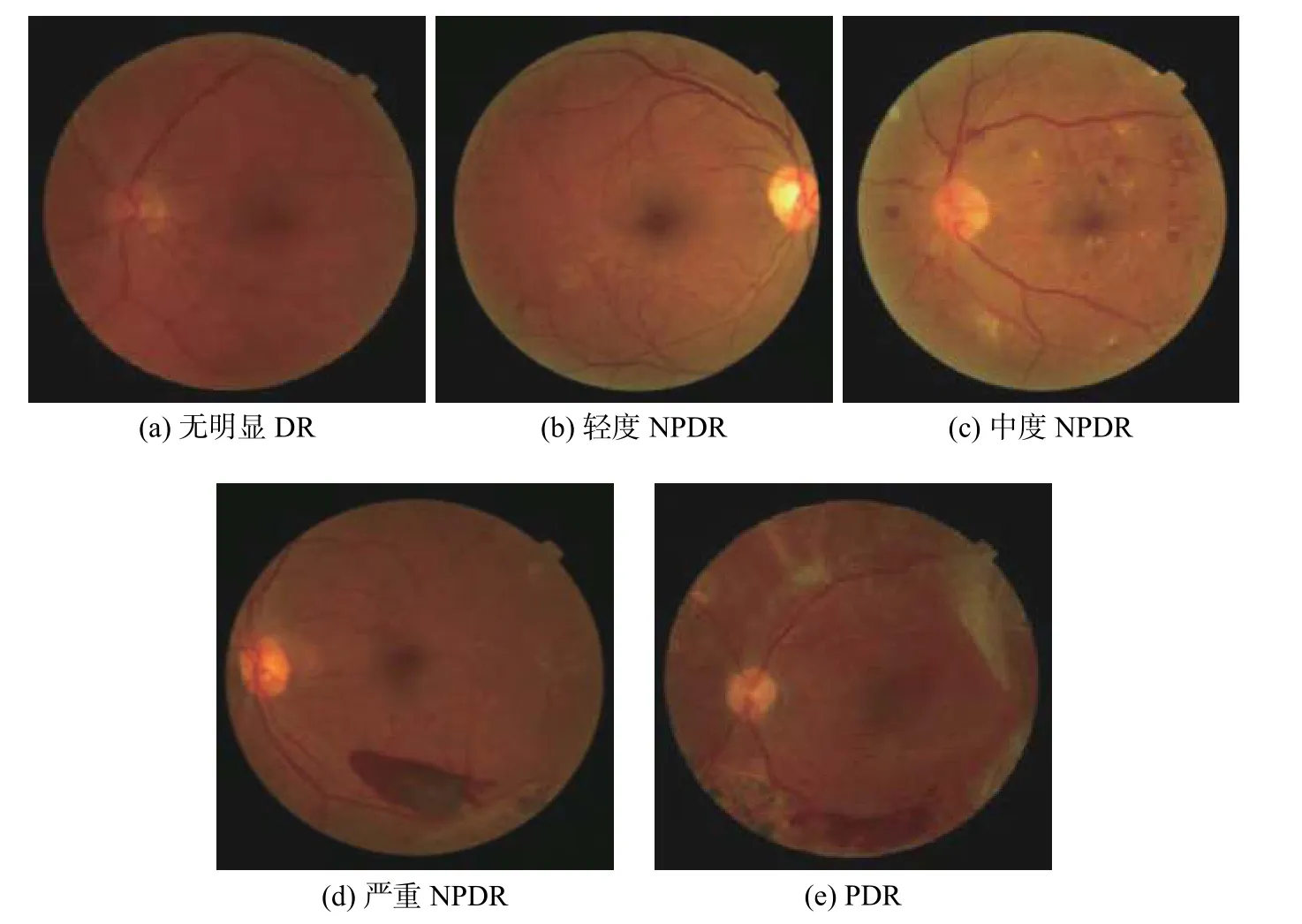
图4 视网膜眼底图像示例Fig.4 Examples of retinal fundus images

图5 眼底图像数据集的分配图(ACC:准确度;SE:灵敏度;SP:特异性;AUC:特性曲线下所围面积)Fig.5 Workflow diagram of the proposed approach for classifying fundus images (ACC:accuracy;SE:sensitivity;SP:specificity;AUC:area under the receiver operating characteristic curve)
最终,该实验数据来自上海市第一人民医院眼底图像数据集,包括5 278名成人患者的8 816张图像,其中1 374例被诊断为无明显DR,2 152例受轻度NPDR影响,2 370例为中度NPDR患者,1 984例为严重NPDR患者,其余为PDR病例。为了评估所提出的方法,选择1 174个没有明显DR的图像,1 952个具有轻度NPDR的图像,2 170个具有中度NPDR的图像,1 784个具有严重NPDR的图像,以及736个具有PDR的图像,共计来自4 429个患者的总共7 816个图像作为训练数据集,来自另外849名患者的图像用作验证数据集。应用构建的训练数据集以保留Inception-v3网络较高级别的权重和反向传播,同时在验证数据集上评估性能。
2.2 评价指标
在本研究中,所有统计分析均使用Python语言及Numpy和Scikit-learn模块(Anaconda Python,Continuum Analytics)。为了评估所提用于鉴定DR的方法性能,通过计算绘制验证数据集的灵敏度与1-特异性曲线。此外,我们还计算了验证数据集的分类准确度。计算灵敏度(S),特异性(P)和分类准确度(A)的定义如下:
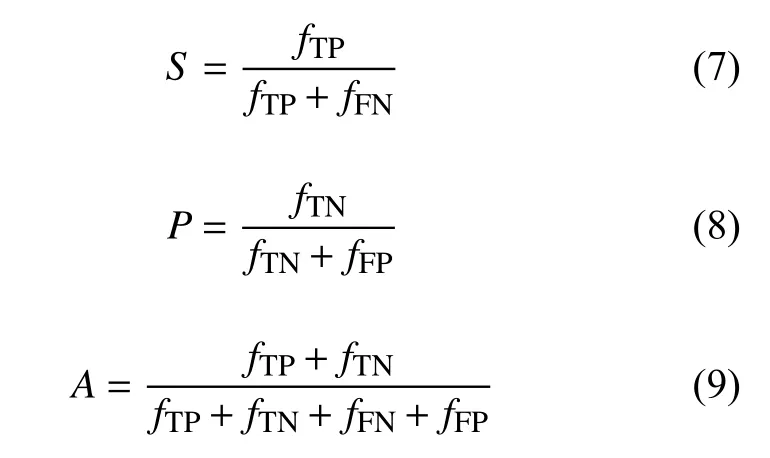
式中:真阳性(fTP)是指正确检测到的转诊总数;假阳性(fFP)代表无转诊被检测为转诊的总数;假阴性(fFN)描述转诊被检测为非转诊的总数;真阴性(fTN)是正确检测到的没有转诊的总数。
3 实验结果及分析
实验中原始DR图像总共19 233张,经过数据筛选后得到8 816张DR图像并对其进行分级和打标签。其中选取7 816张样本图片作为训练集(包括1 174张无明显DR,1 952张轻度NPDR,2 170张中度NPDR,1 784张严重NPDR和736张PDR),使用这些数据对网络模型的参数进行优化和拟合。此外,从每种类别分别选取200张图片组成验证集,用于模型中超参数的调整。在实验过程中采用SGD优化器,设置初始学习率为0.001,mini-batch为100,训练步数为50 000。另外,为了与实验结果进行对比,本文还对不同网络迁移学习的性能指标进行了对比,包括AlexNet、Vgg-s、Vgg-vd-16和Vgg-vd-19。整个实验在Ubuntu 16.04操作系统上进行训练,并基于Keras学习框架借助TensorFlow后端进行实验操作,完成本次实验的训练大约需要5 h。该系统采用Intel Core i7-2700K 4.6 GHz CPU,32 GB RAM,基于双AMD Filepro 512 GB PCIe的闪存,以及用于培训和测试的NVIDIA GTX 1080 8 Gb GPU。
使用自行收集的视网膜眼底图像数据集评估具有多级DR(无明显DR、轻度NPDR、中度NPDR、严重NPDR和PDR)患者的分类算法性能。多级DR患者图像分布如表1所示。

表1 转诊与非转诊DR患者图像分布Tab.1 Image distribution of referral and non-referral DR patients
采用基于Inception-v3模型的迁移学习方法,多级DR的分类结果被绘制成一个混淆矩阵,如图6(a)所示,其中矩阵中的数字显示了各类别预测的患者数量;NPDR表示非增生性糖尿病视网膜病变;PDR表示增生性糖尿病视网膜病变。对角线上的数值为正确分类患者的数量;对角线左下方的三角形是由于过度诊断导致的错误分类数量;对角线右上方的三角形是由于漏诊导致的错误分类数量。在无明显DR、轻度NPDR、中度NPDR、严重NPDR和PDR的多类比较中,验证数据集上的1 000个图像中有965个被准确识别,预测准确率高达96.50%。此外,我们还测试了模型的推荐转诊能力。当视网膜眼底图像被确定为转诊组(定义为中度NPDR、严重NPDR或PDR的图像)时,需要将患者及时转移给眼科医生进行进一步诊断和治疗。从图6(a)还可以看出,共14个无需推荐转诊的图像(共400个图像)被错误分类,使得Inception-v3的特异性为96.50%。有9个属于推荐转诊的图像(共600个图像)被错误地分类,使模型的灵敏度为98.50%。图6(b)是通过绘制多级分类的灵敏度与1-特异性得到的受试者工作特征曲线图(ROC曲线),ROC曲线下的面积(AUC)达到0.989 9。

图6 多分类比较结果Fig.6 Multi-class comparison results
经过50 000步的数据集训练,验证准确率和交叉熵损失值绘制在图7中。为了促进清晰的可视化趋势,将图像的平滑因子标准化为0.6。从图7可以看出,该算法能够对无明显DR、轻度NPDR、中度NPDR、严重NPDR和PDR进行正确分类,准确率为96.50%,验证数据集损失值为0.244 5。实验过程中所产生的部分中间结果如图8所示。模型对DR图像的定量预测结果如图9所示。此外,图10描述了针对每一类别DR图片预测概率统计的实验运行结果。
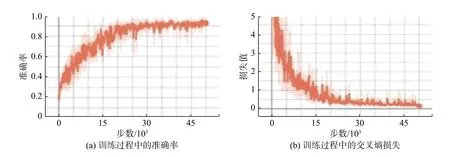
图7 训练数据集上的准确率与损失值Fig.7 Accuracy and loss on the training datasets
此外,通过微调不断优化更新权值,得到其他的卷积神经网络(AlexNet、Vgg-s、Vgg-vd-16、Vgg-vd-19)对DR图像的诊断结果,实验分类ROC曲线如图11所示。从图11可以发现,采用不同卷积神经网络得到的分类性能不同,Vgg-s的分类效果最佳,AlexNet的分类效果则最差,Vgg-vd-16和Vgg-vd-19相差不多,但是Vgg-vd-19的网络更为复杂,消耗时间也更多,且后期的效果稍次于Vgg-vd-16。与其他卷积神经网络相比,基于Inception-v3网络的深度迁移学习在提供高效、低成本和客观的DR诊断方面具有更高的效率。具体的准确率、灵敏度、特异性统计数据如表2所示。

图8 实验中间运行结果Fig.8 Intermediate results of the experiment

图9 实验结果图像示例Fig.9 Image examples of experimental result
由表2可看出,Inception-v3具有最高的准确率、特异性和灵敏度。由于Inception-v3的体系结构密集,可以有效地减少计算,比其他网络的训练速度更快,从而可以在获取新图像时用于实时诊断。所提出方法的关键优势在于它可以快速自动地学习更丰富、更具辨别力的图像特征,这种自主行为可以为捕获临床上重要的DR特征或模式提供更多的机会。

图10 实验运行结果Fig.10 Result of experiment operation
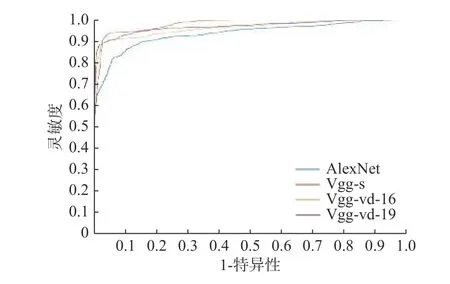
图11 多种卷积神经网络对DR图像的分类情况Fig.11 Classification of DR images by multiple convolutional neural networks

表2 基于不同网络的迁移学习性能指标对比Tab.2 Comparison of transfer learning performance indicators based on different networks
4 结论
本文提出了一种基于Inception-v3网络的深度迁移学习方法,能自动检测DR图像。该方法具有高准确率、高灵敏度和高特异性,并且在检测过程中不需要从视网膜眼底图像数据集中提取工程特征。在Inception-v3网络模型中引入了不同扩张率下的膨胀卷积策略,可以在不增加算法参数复杂度的情况下增大网络的感受野,从而提高网络捕捉特征信息的能力。此外,在每个卷积层后增加了批归一化层,以减少中间变量迁移的问题,有利于加快神经网络训练过程收敛速度,避免了因结构复杂导致的梯度消失问题。另外,本文还应用卷积神经网络的自编码器结合CLAHE数据预处理方法,通过对数据集中的少数类样本进行训练,用生成器产生相似样本数据以降低原始数据的不平衡度。这样不仅提供了对特定DR图像解释的一致性,还可以帮助眼科医生作出转诊决策。考虑到基于Inception-v3网络的深度迁移学习方法将被用作临床支持,进一步的工作是将提出的方法转换为可供专家使用的软件,充当筛选工具并提供第二决策意见。
