复杂网络食品安全舆情传播分析
2020-12-07刘姝王思宇王梦可
刘姝 王思宇 王梦可


摘 要:随着食品安全事件在網络上的不断曝光,食品安全已是网络媒体关注的热点问题。为了弥补传统网络舆情分析的不足,本文基于微博对复杂网络环境下的食品安全舆情进行分析和研究,实现通过复杂网络相关计算来识别微博上传播食品安全相关舆情的意见领袖,并验证意见领袖是否是舆情传播的关键节点,实现对舆情传播的跟踪、管控。
关键词:食品安全;复杂网络;意见领袖识别;舆情传播管控
Abstract:With the continuous exposure of food safety incidents on the Internet, food safety has become a hot issue for online media. In order to make up for the shortcomings of traditional online public opinion analysis, this article analyzes and researches food safety public opinion in a complex network environment based on Weibo, and realizes complex network-related calculations to identify opinion leaders who spread food safety-related public opinion on Weibo. This paper also verifies that opinion leader is the key node of public opinion, and realizes the tracking and control of public opinion communication.
Key words:Food safety; Complex networks; Identification of opinion leaders; Control of public opinion dissemination
中图分类号:G206
1 有关食品安全复杂网络舆情的概述
在信息和话语权充分开放的新媒体时代,食品安全网络舆情应运而生,网络已成为食品安全信息传播的载体以及民众对食品安全事件表达观点和情感的主要平台。由于食品安全网络舆情的形成速度快、传播迅速、影响范围大,互联网在为食品安全舆情提供平台的同时也带来了更多不可控的因素[1]。如果与食品安全相关的监管和执法部门不能及时发现当前的热点舆情,并进行相应的监控和及时的引导,当前的食品产业链很容易受到不良影响,并可能会危害社会经济的稳定及健康发展。虽然国内外一些学者对食品药品安全网络舆情方面已做一些研究,但很大一部分研究只是停留在网络舆情的效应方面[2],对舆情传播控制方面的研究相对较少[3]。
本文较以往研究,从网络舆情的传播控制入手,构建合理的舆情传播控制模型,以此来分析舆情的发展特点和传播规律。通过“极少量意见领袖控制绝大部分重要传播”的社交传播规律特性,将舆情关注从传统的监管“事件”转为监管“人”,用复杂网络分析技术来计算和评价社交传播节点的重要程度,以实现舆情的有效监管。
2 重大舆情的定义及原始数据的获取
2.1 原始数据的获取及信息统计
基于500个重要的食品安全相关字段,查找距离数据抽取时间最近的前69 691条微博,这69 691条微博出现的时间跨度为2014年1月1日 10:01:02到2017年4月27日 21:14:05。其中有78 456个用户参与了这期间微博的发布和转发。平均每个用户发布或转发了1.313条微博,每条微博被1.478个用户发布或转发过。
针对每条微博,构建以用户为节点的微博转发树。69 691条微博对应于69 691棵微博转发树,其中节点为微博用户,如果用户a从用户b处转发了目标微博,则两者之间形成一条转发连边。图1展示了用户或微博的分布特性。图1(a)为用户的转发量分布;图(b)为每条微博被参与用户的转发次数分布;图(c)为转发树中用户节点的度分布;图(d)为转发数中的树规模分布。图(a)(b)与图(c)(d)的区别在于,前者中每个用户可能会多次转发特定微博,因此用户的转发量,以及微博的被参与用户数目会有重复计数。由图1可知,这4种分布皆呈现常见的幂律分布形式,此处选择具有Top-N转发量的微博作为重大舆情。图2展示特定微博转发量的时间分布特性。从图2来看各个微博在不同时间的转发量分布比较均匀,且每个时期都有转发量特别大的特定微博。
2.2 数据集划分
为了预测在未来一段时间,哪些用户会大概率转发重大舆情,将69 691条微博根据时间信息划分为训练集和测试集。以2016年12月31日 22:50:25为分界点,在之前出现的微博及转发行为作为训练集,在之后出现的微博及转发行为即为测试集,注意,由于微博在任何时间段都会不断发生转发行为,训练集和测试集中的微博会出现重叠现象。本文的目标是基于训练集识别重要的意见领袖,并利用这些意见领袖预测其在测试集时间区间内参与的重大舆情的比例。
训练集数据覆盖了33 638条微博,有37 472个用户参与到这些微博的发布或转发行为中。平均每个用户参与1.418条微博,每条微博有1.581个用户参与。测试集数据覆盖了36 140个用户,有43 065个用户参与到这些微博的发布和转发行为中。平均每个用户参与了1.158条微博,每条微博有1.370个用户参与。
2.3 模型构建及验证
利用训练集数据,通过不同的模型策略计算用户的重要性值并对其进行排序,获取前Top-r的用户作为意见领袖,计算这部分用户能够覆盖测试集中重大舆情的比例s。本实验中选被转发总量在前20%的微博为重大舆情。本文构建以下3个模型。
(1)Model1。用户在训练集中的粉丝量fa(选取训练集中用户最新时刻i的粉丝状态)用户I 的重要性可根据公式(1)计算。
(2)Model2。用户参与的所有微博的被转发量f,被评论量c,被点赞量的总和a,用户参与程度为α,则用户I的重要性可根据公式(2)计算。
(3)Model3。Model1和Model2的混合可得出(3)。
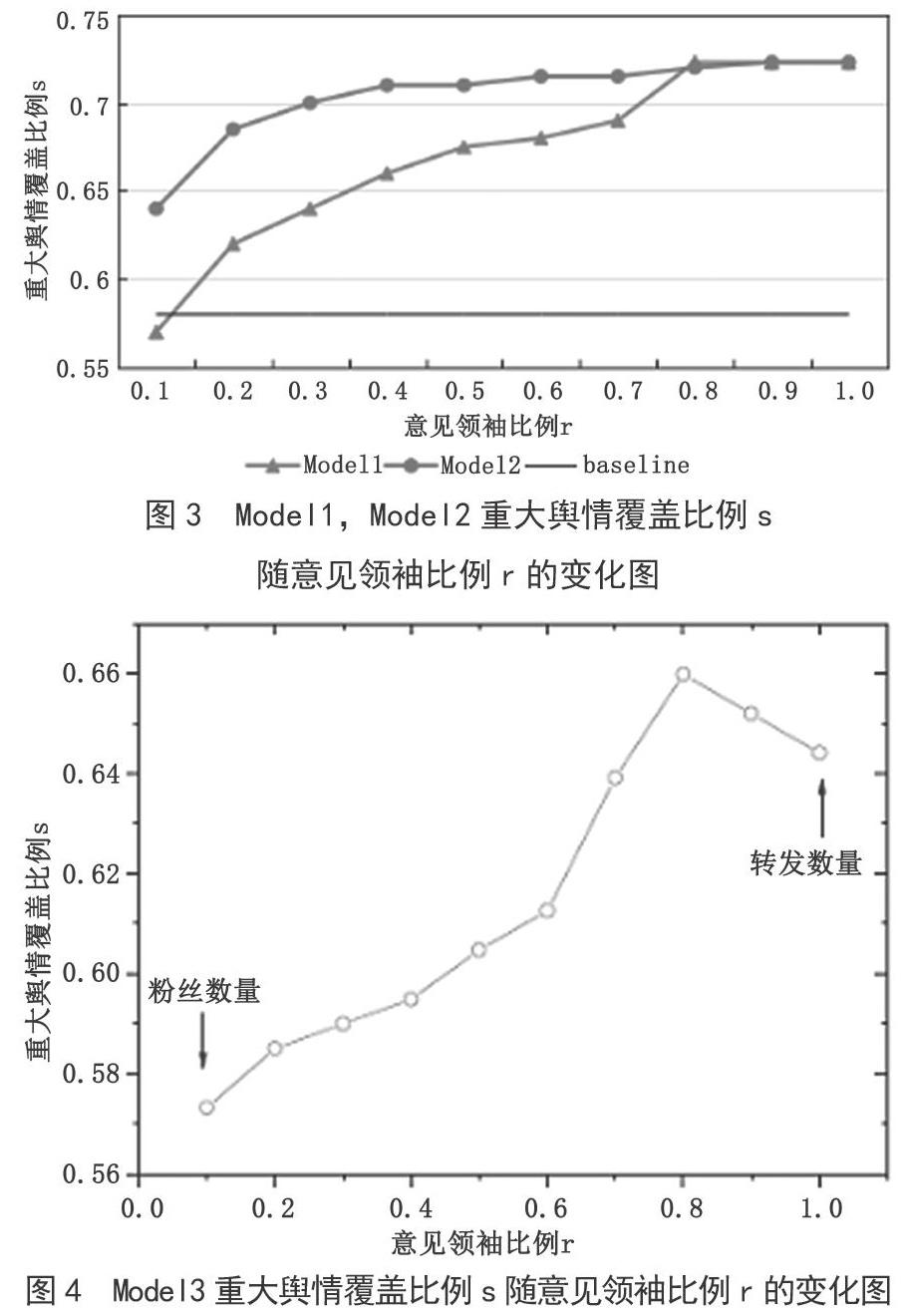
图3给出了Model1和Model2的实验结果。随着选取意见领袖比例r的变化,Model2明显优于Model1。作为对比,同时给出了一个基准对比,即选取训练集中所有重大舆情的参与用户(这些用户占训练集用户9.97%)在测试集时间中所能覆盖的重大舆情的比例(baseline线图)。而如果用训练集的所有用户做预测,可以覆盖测试集中重大舆情的72.3%。也就是说,在本数据集中,利用监管用户,监测重大舆情的预测上限为72.3%。可以看到,利用历史中参与重大舆情的所有用户,预测的重大舆情的效果要低于Model1和Model2指标。图4进一步给出了Model3的预测效果。预测最优值略高于Model2。
的实验结果。由图4可知,最好的模型可以用10%的意见领袖覆盖到测试集中64.3%的重大舆情。同时可知利用Model1,也就是利用用户粉丝数获取意见领袖要弱于利用Model2,即用户参与微博被转发量、点赞量和评论量。而之前的思路,即从参与重大舆情的用户中进行细粒度筛选的策略失效,如图3相关数据所示,利用所有参与重大舆情的用户作为意见领袖来覆盖重大舆情,覆盖率要远远低于其他两种模型,而这部分用户占比为9.97%。根据对比分析,可以用10%的用户(指参与的微博具有过被转发行为的用户总数的10%)覆盖64.3%的重大舆情,即能力范围之内所能覆盖到的重大舆情的88.9%(64.3%/72.3%)。
以上表明,可以通過意见领袖来实现对舆情传播的跟踪、监控。意见领袖作为舆情传播的关键节点,往往是对某一事件发表态度的活跃者,其言论或信息是其他用户评论和转发的焦点,具有重大影响力。
3 结语
本文通过对食品安全网络舆情的形成、特点进行研究,从中查找出了食品安全舆情的关键控制点,分析了复杂网络舆情的传播路径和方式,有助于实现对食品安全网络舆情事件的实时监测和实时分析,对改善食品安全监督、弥补食品安全监管具有推动作用。
参考文献:
[1]董凯欣,傅荧,孙晓峰,等.基于社会网络分析的企业网络舆情预警机制研究——以食品安全网络舆情为例[J].电子商务,2015(8):54-55,57.
[2]吴林海,吕煜昕,吴治海.基于网络舆情视角的我国转基因食品安全问题分析[J].情报杂志,2015,34(4):85-90.
[3]陈静静,刘升.基于大数据挖掘的食品安全管理研究[J].中国物价,2020(7):86-88.
