超算环境科学工作流应用的容错*
2020-12-07李于锋莫则尧肖永浩赵士操段博文
李于锋,莫则尧,肖永浩,赵士操,段博文
(1. 中国工程物理研究院 计算机应用研究所, 四川 绵阳 621900; 2. 北京应用物理与计算数学研究所, 北京 100094)
在科学发现和工程仿真中,使用一系列相关软件完成数据收集、建模、模拟、分析成为普遍现象。各步骤间可能有数据依赖或控制依赖关系,这些软件相互协作才能获得最终结果。科学工作流管理系统对这些软件及其数据依赖关系进行组合,并控制各部分在时间、空间以及资源等约束条件下按序完成,已经成为复杂科学计算流程管理的必要手段,有效推动了科研进展[1]。面向大规模数据集和复杂计算流程的超算环境科学工作流技术提供了自动化、流程化的方法,并为用户屏蔽作业投递和数据传递转换等细节,极大地促进了超算环境和应用平台的协同发展。
在超算环境中,资源失效是常见现象,如计算结点死机或网络模块出现故障等问题造成无法正常工作等。据估计E级计算的平均无故障时间(Mean Time Between Failure, MTBF)已缩短为数分钟[2]。资源失效会造成任务和流程中断执行。另外,在复杂流程(通常表现为稠密大规模有向图)中组件数量大、配置烦琐,对系统环境变量及运行参数有严格要求,用户使用易出现配置错误导致软件组件运行异常,也同样造成任务运行失败和流程中断执行。如何对任务运行失败进行预防或者失败后进行自动恢复,以保证流程整体自动持续运行,是工作流容错研究的重点问题。
容错作为科学工作流管理系统的重要组成部分,随着科学工作流运行环境从单机、集群、异构多集群到云的变迁,涌现出多种容错策略,在不同的运行模式下,为工作流平台的稳定运行提供了有力保障。特别是对于长时间运行的科学工作流,或者数据处理步骤繁多的流程,提供错误自动恢复机制尤为重要。
国内外已经出现了很多工作流系统平台,这些工作流系统都提供了容错相关的功能。比如美国加州大学研究者基于Ptolemy II[3]系统开发的Kepler[4]系统,广泛应用于包括生态学、分子生物学、化学、计算机科学、电子工程和海洋学等领域;美国南加州大学信息科学研究所开发的系统Pegasus[5],已应用于地震及灾害模拟,引力波探索(Laser Interferometer Gravitational-wave-Observatory, LIGO)等领域;英国曼切斯特大学计算机科学学院开发的Taverna[6]工作流套件,广泛应用于生命科学等领域;英国加地夫大学开发的Triana[7]网格集成计算环境,可用于天文学计算和网络数据处理等领域。这些工作流管理系统的容错功能将在本文第二部分进行阐述。
为了支持超算环境下科学和工程计算领域数值模拟流程的高效设计与自动执行,中国工程物理研究院计算机应用研究所自主研发了HSWAP工作流应用平台[8-9],以高性能应用软件作为组件封装的基本单位,配置简单,部署便捷,支持跨平台应用的协作。本文设计的容错模型和方法将以HSWAP系统为验证平台,基于日志分析,利用数据驱动的方式实现了容错功能,为错误自动恢复、工作流无间断运行提供了重要支撑。
1 科学工作流容错的分类
工作流系统的容错分为任务级和工作流级[10-11],其中任务级又可分为任务重试、检查点/重启动、替换资源、多副本运行等,工作流级可分为替换任务、冗余多任务、用户定义的异常处理、基于修复工作流等。具体分类如图1所示。任务重试是在任务出错后,简单地重新执行该任务,通常会设置一个最大重试次数,即超过该重试次数后若还没有恢复成功,则放弃重试。检查点重启动机制[12]需要任务本身支持检查点重启动功能,在任务运行过程中进行一定间隔的检查点信息保存,在任务异常出错后能够从最近的检查点恢复执行。替换资源方式是指在任务运行失败后,切换到其他资源继续运行该任务,以应对资源失效造成的异常。任务多副本运行是指同一个任务(同一实现)在多种资源上同时运行,确保至少有一个运行成功,这是一种预防失效的方式。工作流级容错的替换任务方式是指任务运行失败后,会执行任务的另一种实现,该实现同样完成原来任务的目标;冗余多任务是指会同时运行多个替换任务,也是预防失效的方式;用户定义的异常处理机制通常是在组件级别对出错情况进行处理。基于修复工作流是指工作流执行过程中异常发生后记录失败的任务信息,生成新的工作流以备后续提交重新运行。

图1 工作流容错的分类Fig.1 Taxonomy of fault tolerance
面向基于数据流的科学工作流管理系统,Ustun等[13]提出了多数据实例相关的容错框架。首先识别出数据处理管线(pipeline)中的错误模式,提出的恢复方法包括容许限定次数的失败项、以哑数据代替因错误数据而不能执行的任务输出、立即重执行错误任务(需考虑数据实例依赖关系)、依赖工作流实例的恢复(考虑中间数据的存储代价和生成代价)等。另外,文献中利用编程语言模型中的异常处理等技术[14]或研发新的异常处理语言[15]给容错研究带来了新技术路线,但由于和原工作流系统的紧耦合性,不易推广。
2 典型工作流系统的容错设计
Taverna科学工作流管理系统中的容错采用了任务重试和替换任务两种策略,任务重试中工作流设计者可定义最大重试次数,该策略也可应用于子工作流容错;替换任务允许在任务重试达到最大次数后选择执行一个不同的任务。
Triana工作流系统的容错是面向用户的,如错误发生时,会产生警告信息,并允许用户修改后继续执行;在工作流级支持轻量级的检查点/重启动和工作流服务的选择。在中间件级和任务级,所有预定义的异常会被Triana引擎感知(死锁、活锁和内存泄露除外);在最底层的资源失效方面,借助GridLab GAT工具可以识别资源失效,但是错误恢复机制还未完善。
Pegasus的容错是基于DAGMan和HTCondor开展的。例如,在作业运行错误后进行重试或重新提交处理,通常可以在作业文件中设置作业重试次数。针对数据传输的可靠性问题,Pegasus传输服务会首先尝试高性能的并行传输,失败后会进行更安全的低速单连接传输。如果重试次数已达最大,将生成修复工作流待后续重新运行。另外,Pegasus还支持进行重新资源规划以重用失败时已生成的数据,并通过调度任务到不同资源来实现容错。
Kepler科学工作流系统中的容错是通过一个称为Checkpoint的复合actor实现的。actor是Kepler中的专有概念,表示一个执行组件。检查点复合组件包括一个子工作流和若干可替换的子工作流,当错误发生后,发出错误时间信息,检查点内所有工作流停止执行并处理错误,决定是否重运行该子工作流或者运行一个可替换的具有同样功能的子工作流。
已有工作流系统的容错存在的问题有:容错生命周期管理不健全,如Taverna、Triana等;容错处理与执行任务紧耦合,扩展方式不灵活,如Kepler、Taverna等;没有独立的容错机制,依赖其他(网格基础设施提供的)资源管理工具实现,如Pegasus、Triana等。
容错的设计需要考虑可灵活配置的错误恢复策略、与工作流执行引擎的解耦模型、容错处理的全生命周期管理等问题。如此设计方可将容错服务功能方便集成到多种科学工作流系统。HSWAP是面向高性能计算领域的工作流系统平台,其以封装数值模拟软件和应用形成松耦合、粗粒度的工作流为特色,下文提出的容错模型和方法设计在该类平台上的实现十分便捷。
3 容错模型和方法设计
3.1 容错全生命周期管理
工作流执行异常出现后,对异常的发生、消息的流转以及针对异常的处理进行全面的分析,有助于给出全面系统的容错方案。容错的生命周期如图2所示,首先是错误发生,生成错误事件,然后错误被监控工具识别监测,最后进入错误处理流程,包括错误恢复策略以及相关的恢复动作。

图2 容错全生命周期管理Fig.2 Full period management of fault tolerance
为支持容错,工作流系统在设计时应考虑异常状态管理以及错误信息的传递,比如错误发生后,流程执行中断进入待恢复状态,还要考虑错误事件的描述,事件消息的发出和相应的消息跟踪。容错处理流程的过程如图3所示,包括异常信息监测、错误信息识别、错误信息分类、错误恢复处理四种主要的功能步骤。

图3 容错处理流程Fig.3 Fault handling process
异常信息监测是指异常事件消息发出后,容错模块能够感知和探测到异常;错误信息识别则是从工作流系统日志等记录中有效识别出错误信息;错误信息分类则是为了进一步的容错处理缩小处理方式范围;错误恢复处理则是采取相应的执行动作,以使得工作流从中断暂停状态转移至继续执行或等待用户救援状态。
3.2 基于决策树的ECA容错模型
异常处理可以采用基于事件-条件-动作(Event-Condition-Action,ECA)的模型[10]构建。ECA模型如图4所示,针对不同的错误事件,在不同的条件下执行相应的动作。

图4 ECA模型Fig.4 ECA model
在ECA模型中,事件集表示所有发生的事件,每类事件都有一个明确的标识,表明相应的信息,比如任务运行失败、网络服务超时等异常信息。条件集里的条件表明当前工作流系统的运行状态和运行环境,比如工作流引擎是否停止响应、资源是否可用等。动作集里的动作表明实现错误恢复需要执行的命令,可以是单个命令,也可以是多步骤的多条命令组合成的复合动作。ECA模型具有很好的灵活性,针对同一事件,对应不同的条件下,则可执行不同的动作指令;在相同条件下,不同事件也可对应不同的动作指令。
在异常事件和环境条件可监测、可探察的前提下,灵活配置错误恢复动作是ECA模型的特色。本文扩展了简单的ECA模型,使得事件发生后,可以结合多个条件来最终选择相应的动作执行。具体地,引入决策树算法,基于决策树高效实现事件-条件集合到动作集合的映射。基于决策树的错误恢复动作选择示例如图5所示。

图5 基于决策树的错误恢复Fig.5 Failure recovery based on decision tree model
基于决策树模型设计的错误恢复针对每个事件都有一颗不同的决策树。允许不同的事件有不同的处理逻辑,比如图5中事件1的处理逻辑必须判断两个条件才能给出最终的恢复动作,而事件2在条件3满足的前提下只需判断一个条件就可以决定恢复动作。另外,不同事件的决策顺序也不相同,图5中事件1需要先判断条件1,然后判断条件2或条件3;而事件2则先判断条件3,然后视结果可能判断条件1。如此设计有助于减少环境探查,快速决定错误恢复动作。具体的执行动作决策如算法1所示。
算法1中决策变量是指某一个条件的布尔值,即对任一条件,都有两个状态表示是否满足。比如计算结点网络故障不可达(无法连接)、计算结点可连接两个状态,每个状态下都有后续不同的处理逻辑。

算法1 容错动作决策
3.3 错误信息和恢复动作
针对超算环境科学工作流系统的执行特征,设计了错误事件信息的要素,如图6所示。错误信息包括错误信息的发出位置、出错模块、引入环境、产生时间、发生频率、严重等级、造成影响等七个维度。

图6 错误信息要素Fig.6 Elements of fault information
虽然错误信息包含的要素较多,但在实际工作流执行过程中能够获得的信息却是有限的,需要建立日志系统来存储和分析历史错误信息,补充相对完整的错误信息,方便后续的错误恢复策略选择决策。

图7 错误恢复处理方式Fig.7 Failure recovery methods
容错设计考虑了在发生异常事件后可配置不同的处理方式。支持的处理方式如图7所示,有重试、替换、重启动、错误传播、忽略、标注和用户介入七类。重试又包括任务重试和子流程重试,任务重试表示仅重运行出错任务,子流程重试则重运行出错任务所在的子流程(工作流的一个子结构)。替换类的处理包括替换资源、替换任务和替换子流程。替换资源表示同一任务在不同的资源上重运行;替换任务表示选择执行另一个具有同样功能但不同实现的任务;替换子工作流则表示选择执行另一个具有相同功能的子工作流执行。重启动(或称检查点-重启动)方式一般需要任务实现支持,在任务运行过程中,会以一定间隔保留后续恢复时所需的数据信息(检查点信息记录),在错误恢复时,会从检查点处重新加载信息继续执行而不会从头开始计算。错误传播是指将错误信息从出错任务所在的执行模块传递到工作流系统引擎、用户界面以及日志系统(将来可能通过网络远程传输给客户端或其他系统)。对于一些不影响流程主要功能完成度的异常信息,可采取忽略的处理措施。对于未知异常,可采取标注的方式记录异常出现的场景及其造成的影响等信息。当任务配置参数出现错误引发异常时,通常需要用户介入,以用户的专业知识修正任务配置参数,才能够达到错误恢复的目的,这可通过科学工作流的“人在回路”(human in the loop)等技术实现。
3.4 容错与科学工作流系统的关系
异常信息和处理方法、处理策略设计好之后,应该考虑如何将容错与科学工作流系统进行有效融合,既能有效发挥出容错的重要作用,又不影响原有工作流系统的设计。本文提出如图8所示的设计架构来确定各子系统间的关系。容错服务和科学工作流引擎独立开发和部署,基于远程过程调用(Remote Procedure Call,RPC)和日志服务及消息来进行交互。

图8 容错与科学工作流系统的关系Fig.8 Fault tolerance architecture in HSWAP
异常事件发生后,由监控模块探测到错误信息,生成错误事件传递给科学工作流引擎,进而形成错误事件信息,并将该信息发送至日志服务器(可基于 Elastic Search-Logstash构建)。容错服务会间隔轮询日志服务获得所有出错事件,并用预先配置好的错误恢复准则进行错误分析,然后触发错误恢复动作,完成错误恢复。
如此的容错架构设计有三方面的优点:一是模块化,将容错服务与工作流管理系统和日志系统解耦,实现了松耦合以及容错模块可插拔、可替换的目的;二是服务化,将所有错误统一集中管理,并实现了高并发的处理逻辑,可同时处理不同用户、不同工作流实例的错误恢复;三是单向消息机制,数据传输代价小、效率高、逻辑清晰,在实际系统开发中简单实用。
4 容错在HSWAP系统的实现与验证
4.1 HSWAP简介
HSWAP是中国工程物理研究院计算机应用研究所开发的超算连贯计算引擎[8-9],旨在HPC环境中使用科学工作流技术提供集成的超算服务模式助力科研人员提高工作效率。基于HSWAP开发的石油地震勘探平台以及材料高通量计算平台等行业计算平台,已在实际项目中得到应用并发挥了重要作用。
HSWAP的主要特色是为超算用户屏蔽使用超算系统的复杂性,以计算软件为基本封装单位形成可复用组件,进而实现灵活可定制业务流程的功能。流程以有向无环图(Directed Acyclic Graph, DAG)表达,实现流程中结点间依赖管理和数据自动传递和转换功能。平台的架构和相关模型如图9所示。
4.2 HSWAP的容错实现和验证
HSWAP平台提供了日志系统,这为实现上文提出的容错架构提供了方便。引擎执行过程中,会通过Logstash服务将运行时相关信息写入Elastic Search数据库,相关信息在容错模块可以用来进行容错动作决策。

(a) HSWAP的模块架构(a) Architecture of HSWAP

(b) HSWAP的流程和组件模型(b) Workflow and component models of HSWAP图9 HSWAP平台的架构和业务模型Fig.9 Architecture and models of HSWAP
在HSWAP中提供了基于数据完整性校验的两类错误识别和恢复方法。在超算系统中,任务作业退出后,是否正常完成任务目标需要多方面的考虑,其中数据完整性是最常见的判别标准之一,特别是对于数值模拟仿真类任务,生成完整而正确的数据文件几乎是唯一的标准。基于数据判别的容错流程如图10所示,分为三个步骤,即出错标识、信息收集、错误恢复。

图10 基于数据完整性校验的容错流程Fig.10 Fault tolerance based on integrity of data
基于数据完整性校验的出错标识在HSWAP工作流引擎中完成,主要是利用工作流组件的自定义配置功能,对不同的任务配置不同的数据完整性校验策略,比如数据体量、数据结束标识监测等,当数据完整性不达标时,发出错误信息。日志信息会收集所有任务运行上下文信息,以便容错模块对错误进行分析定位。容错服务根据出错事件,基于可配置的ECA规则(如图11所示),执行错误恢复逻辑,最后通过HSWAP引擎接口调用自动恢复流程执行。

图11 错误恢复策略配置文件示例Fig.11 Example for fault tolerance strategy
面向单个数值模拟任务的检查点-重启动错误恢复方式在HSWAP的实现流程如图12所示。流程执行监控、结果文件正确性校验、重启动参数配置和输入文件准备、重投递运行等一系列过程自动化执行,无须人工干预。实际使用中结合重试、重启动两种方式,解决了资源不稳定等问题引起的执行中断问题。

图12 基于检查点-重启动的容错Fig.12 Fault tolerance based on checkpoint-restart
HSWAP平台针对材料计算等领域高通量计算模式提供了特有支持,功能包括数百上千并行任务的并发投递、监控和容错。高通量计算模式如图13(a)所示,一般表现为大量并发执行的相似任务,用于材料分子筛选等参数扫描类计算或大数据分析等领域。在容错设计上,用户可定义高通量计算出错的判别标准,如以计算完成百分比作为失败阈值(fail_threshold)。当高通量并发任务失败比例(fail_ratio)超过此阈值,标识任务失败,并重启动失败部分的任务计算,完成容错恢复执行。高通量计算的失败比例定义为式(1),其中num_all为该高通量所并发执行的所有子任务(或称计算实例)数,num_failed为其中运行失败的子任务数。
(1)
例如,若对某高通量计算任务,需要并发执行100次不同的通量计算(可能为不同参数运行同一软件组件),设失败阈值为20%,若100个计算实例中失败数为20以下,则认为该高通量计算成功运行,不进入容错处理;若失败数为30,此时失败比例大于失败阈值,进入容错处理过程,只需要重试或重启动运行失败的30个计算子任务,运行完毕重复容错过程,直到满足高通量计算任务的成功运行阈值标准,或者达到最大重试次数并报告错误信息。
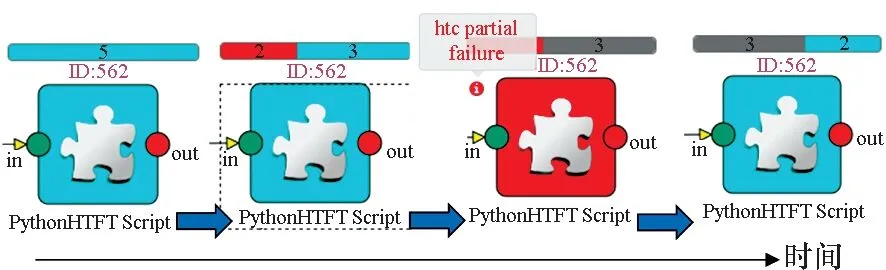
HSWAP平台针对高通量计算的容错过程如图13(b)所示,其中失败阈值设为20%,每个图标表示同一高通量计算任务在不同时刻的状态,图标上部表示子任务数目及状态,蓝色为正在运行,红色为失败,灰色为成功结束。实测结果表明容错模块能够正确识别错误,并按要求重运行失败的任务,满足自动恢复运行的需求。

(a) 高通量计算模式(a) High throughput computing pattern
(b) 高通量计算的容错(b) Fault tolerance of high throughput computing图13 高通量计算及其容错Fig.13 High throughput computing and fault tolerance
复杂超算应用具有计算规模大、运行时间长等特征,高通量计算等复杂流程也愈加普遍。由于机器故障,程序参数配置错误等异常造成运行中断现象常常出现。依靠人工查看、修改配置、重新投递作业的方式进行错误恢复,会严重影响执行效率。在某百万亿次超算平台上,某工程项目中冲击波计算程序的实际运行情况统计如表1所示。
表1中人工重启动间隔是指在任务失败后开始计时,直到人工发现错误并投递作业,再次投递排队后继续运行的时间。由于作业可能在深夜或凌晨中断运行而用户无法及时发现,加之重投作业造成再次排队等待时间,实际应用的完成时间就会大幅增长,自动容错技术能够缩减人工重启动间隔时间,显著缩短工程仿真或其他科学研究领域的计算周期。

表1 某冲击波计算任务的容错效率Tab.1 Performance and fault tolerance of some shock computing software
5 结论
本文针对超算环境中工作流应用的容错机制展开讨论,调研了容错在典型科学工作流系统的实现方式以及容错的分类。提出了完整的容错生命周期模型;在事件-条件-动作的处理逻辑基础上,提出了可配置的基于决策树的错误恢复模型;设计并实现了模块化、可扩展的科学工作流系统容错架构。本文提出的容错模型已在自主研发的超算环境工作流管理系统HSWAP中实现。面向单个任务和高通量任务应用场景分别给出了容错实现策略,并通过实际算例在超算平台上验证了容错对于提高流程执行效率的作用。目前实现的工作流系统和容错模块并没有系统软件的权限,作为应用级系统,无须系统管理员权限就可方便部署,助力加速科研和工程实践过程;但是未能进行超算平台软硬件基础设施的健康信息探查,提供给错误信息分析模块的信息还不够全面,仅从应用的视角实现了错误日志分析功能。下一步的工作将包括全面探测底层软硬件系统和应用各模块的运行信息,给出更准确的出错原因分析。另外,基于可靠性感知的调度方案设计以及云上容错[16-18]也是值得深入研究的技术方向。
