基于倒排索引的铁道供电集群监控H-CRQ技术
2020-12-07屈志坚范明明孙旭兵王子潇
屈志坚,范明明,赵 亮,朱 丹,孙旭兵,王子潇
(1.华东交通大学 电气与自动化工程学院,江西 南昌 330013; 2. 常州市轨道交通发展有限公司,江苏 常州 213000)
随着我国高速铁路规模越来越大,牵引供电系统、铁路电力系统、铁路通信信号电源和接触网隔离开关等四电设备的综合调度监控,已逐步应用于高速客运专线供电系统所有重要高、低压回路,纳入近全景采集的铁路配电网、牵引变电网及接触网等各类测控终端和监控线路中,使铁路供电综合调度监测系统采集信息呈指数级增长[1-4]。据调研,浙赣铁路10 kV电力调度监控系统仅2个月获取监测数据量即达300 GB以上,按此计算,1年监测数据量为1.8 TB,以服役期15年算,总存储量可达27 TB,监测数据的体量明显超出了常规关系数据库TB级容量限制[5],且数据体量的增长速度远超计算机性能的增长,在工程中须进行转存储处理,否则就会由于铁路10 kV电力系统监测数据体量的持续增大使系统响应速度达到1 min左右,而该系统的查询响应时间应控制在百毫秒级。海量监测数据一方面增加了系统的维护工作量,另一方面使传统数据存取方式产生越来越大的延迟,千万级以上的海量监测数据查询响应慢易造成调度界面卡屏,影响调度信息的实时处理,严重时甚至可能导致关键故障信息的迟报、漏报甚至丢失,威胁行车安全[6]。因此,迫切需要研究铁路供电监测的高效查询响应技术,提出新的海量监测数据的快速处理方法[7]。
现有针对海量监测数据快速查询问题的研究方法主要分为两大类。第一类为扩展数据库方法,具体有2种:①采用分布式磁盘数据库技术[8],通过将海量监测数据存入分布式数据库中,把数据分别存储在不同主机磁盘上,与关系数据库相比,可利用分布式磁盘数据库扩展存储海量监测数据,但由于数据仍存储于硬盘介质,存取实时性受到限制[9],难以满足海量监测数据的快速存取需求。②采用内存数据库技术[10],将监测实时数据驻留内存,获得比关系数据库快几个数量级的存取速度,随机访问时间可达0.05 ms,约为磁盘访问的5‰,但内存数据库容量易受物理内存的限制,如俄罗斯Knizhnik研发的开放内存数据库FastDB,嵌入式内存数据库SQLite,容量均限制为100 GB以内,内存造价高,存储空间远小于磁盘容量,难以扩展。
鉴于高速铁路供电数据的典型特征是集群化处理,另一类解决方法是使用集群技术,具体有2种:一种为使用Hive查询引擎对数据预处理[11-12],将海量监测数据映射为数据表,并将查询命令转换为MapReduce操作进行批量查询处理,但MapReduce进程的查询启动慢、开销大,文献[13]中使用Hive查询引擎查询千万级数据耗时达120 s,难以满足海量监测数据的快速查询要求。另一种为基于非关系型(Not only SQL,NoSQL)HBase数据库集群,通过热点缓存和热点评分处理,将数据量大、出现频繁的数据驻留HBase数据库集群节点缓存,检索时可直接从缓存中搜索结果[14-16]。但一方面,由于常规热点缓存(Hotspot-Cache Query,H-CQ)技术通过更新关键词索引缓存的时间戳,区分缓存被访问的频繁度,为避免同时读写时间戳冲突,需对数据更新操作加互斥锁,同一时间只允许一个线程操作,须等待写入完成才能进入查询线程,故对多线程读写操作支持不够,而牵引负荷波动幅度大且变化频繁,间歇短时过负荷甚至超出200%,母线电压波动超出20%,因此监测数据的频繁更新将使常规H-CQ技术的多线程读写性能受到较大影响。另一方面因HBase数据库集群是一种以键值对形式存储的数据库,对非主行键索引查询的支持不够,难以满足铁路供电监测系统按站所和设备编号等非主行键快速查询的要求,若能利用倒排索引技术改变数据存取结构[17],从非主行键进行索引定位,就可完成非主行键数据的快速搜索,同时,改变H-CQ技术的更新替换方法,避免缓存时间戳操作,以提高H-CQ技术的多线程读写性能,该研究尚未见文献报道。
本文设计出了一种新的基于倒排二级索引结构的热点缓存替换(Hotspot-Cache Replace Query,H-CRQ)技术,改变铁路供电监测数据索引结构以实现在铁路供电监测集群中进行关键词查询,并在倒排索引的热度缓存环节中设计访问顺序编码,通过顺序编码更新淘汰缓存数据,避免对缓存时间戳系统属性操作,提高热点缓存处理在铁路供电监测集群中的多线程读写性能。以工程实测数据进行算例测试,验证本文所提集群监控处理的新方法,可有效提高铁路调度监测海量数据查询效率与多线程读写性能。
1 铁路供电海量监控数据索引设计
1.1 铁路供电监测数据采集
铁路供电系统与设施是铁路行车装备的重要组成部分,沿线的车站、变电站、接触网等设备装配有大量电压互感器、电流互感器和各类传感器,收集了大量运行参数信息,同时测控终端的采样频率越来越高,使监测数据体量越来越大,数据采集过程见图1。
铁路供电监测系统的终端单元,如远程控制终端(RTU)、馈线终端设备(FTU)、信号电源监控终端(STU)、开闭所测控终端(DTU)、变压器监测终端(TTU)等,装有大量传感器和互感器,收集铁道供电系统的供电设备参数、信号电源状态、配电所变压器运行状况、开关设备运行参数以及报警信息等数据,通过通信网络传递给通信前置机。通信前置机按统一标准将监测数据解析处理后上传至调度中心HBase海量数据库集群,生成监测数据的倒排索引进行存储并运用H-CRQ技术将热点部分存储在分布式集群缓存中,集群调度工作站通过海量数据库集群查询读取监测数据和报警信息,对铁路供电系统运行状态进行实时监控并调度管理,形成铁路供电海量数据集群监控的信息流。

图1 铁路供电监控系统数据的采集
1.2 铁路供电监测数据的倒排索引结构
铁路供电调度系统的主要任务是监视整个铁路供电系统的电气设备运行状态并调度管理,实际工程应用中存在需根据调度人员的需求查找特定数据的场景,例如在铁路供电调度系统中通过采集时间和站所号查看某一时间该站所有设备的运行状态或是通过测控终端编号查看某一测电气设备随时间变化的运行状态报表,如何在海量监测数据中快速定位数据是搜索的关键。图1中铁路供电监测数据存入数据库集群时会生成主行键Id作为惟一标识编号,而监测数据中的测控终端编号、采样值、采集时间、归属站所等属于非主行键。由于HBase数据库是一种以键值对形式存储的数据,对非主行键查询支持不够,因此设计一种监测数据的倒排索引结构。倒排索引以关键词为索引核心和链表访问入口,由属性值及该属性值所属数据的地址组成,由于不通过数据主行键,而是非主行键关键词来定位数据,所以称为倒排索引。
倒排索引的储存形式定义为关键词及它的位置、主行键Id,在查询时直接根据关键词检索,避免逐条查找数据。以铁道供电监测数据记录为例,描述倒排索引设计,见图2。包括数据主行键Id,铁道供电监控终端的采集时间Timestamp,归属站所Station,测控终端编号Rtu,采集对象标识Analogname以及采样值Analogvalue。

图2 铁路供电监测数据的倒排索引设计
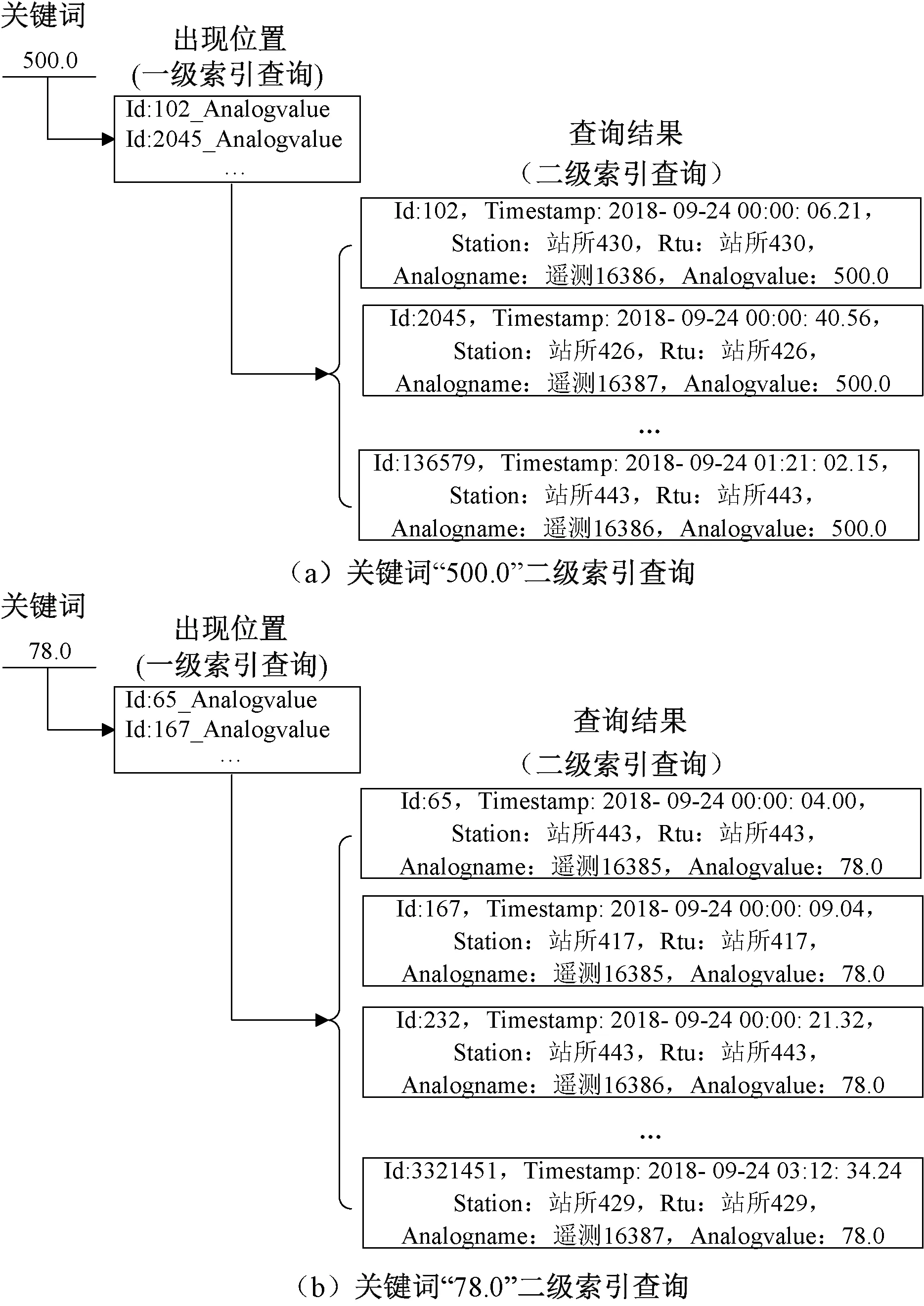
如图2所示,铁道供电监测数据记录正序索引搜索关键词时需按搜索要求逐条索引对比,对关键词的搜索效率不高。重新构造的倒排索引,由监测信息表中关键词及其出现的位置组成,如关键词“站所443”,出现位置为“Id:1_Station”“Id:1_Rtu”“Id:2_Station”“Id:2_Rtu”,其中“Id:1_Station”代表关键词出现位置为主行键Id为1,列名为Station。这种倒排索引结构可直接根据关键词索引数据位置,通过二级索引快速定位目标数据。
2 铁道供电监控数据的查询
2.1 构建铁道供电监控数据的二级索引
在HBase数据库分布式存储的基础上,利用倒排索引设计一种铁路供电监测数据的二级索引方法,二级索引系统的读写访问架构见图3。
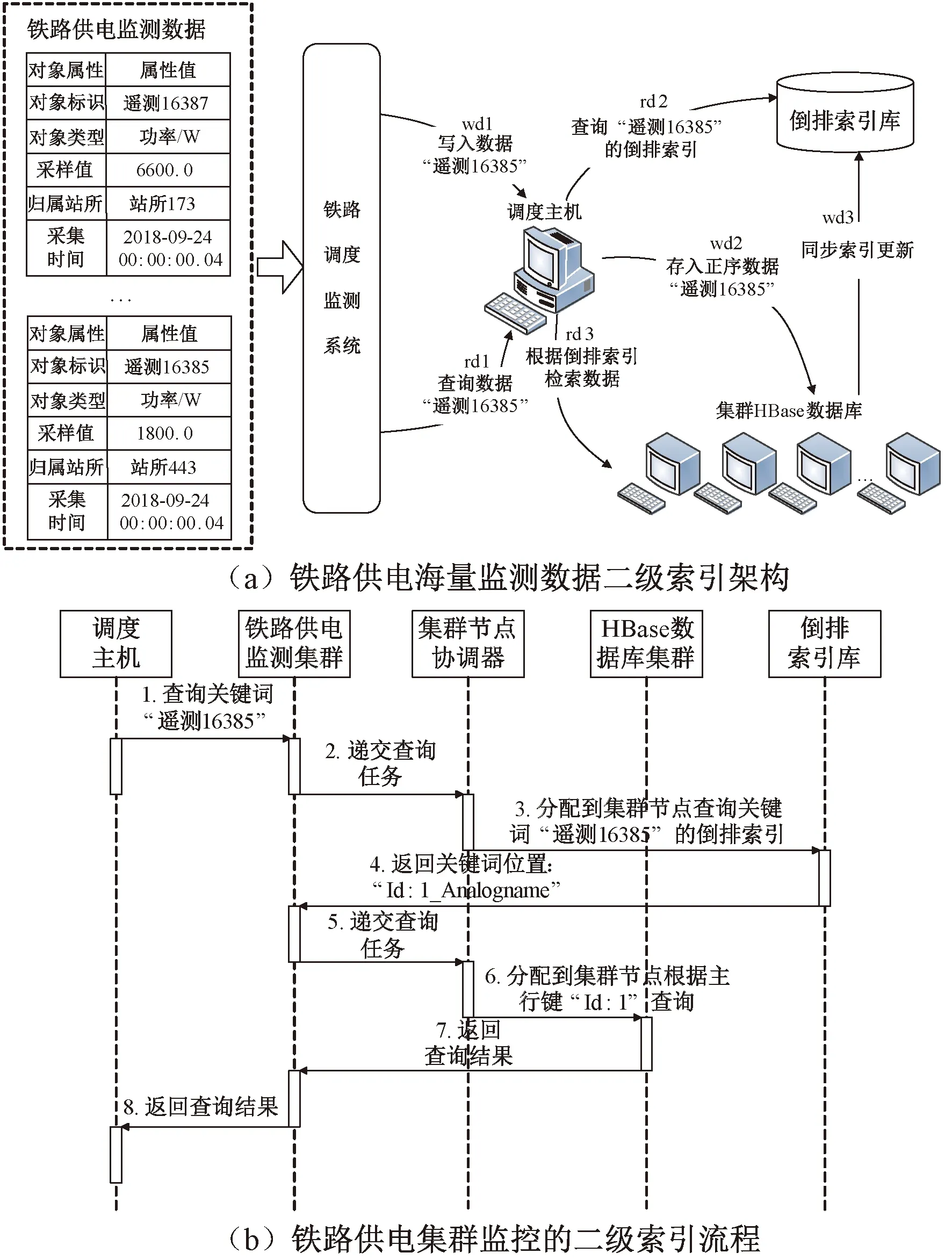
图3 铁路供电海量监测数据二级索引设计
以向铁路调度监测系统写入如图2所示的铁路供电监测数据为例,说明该架构实现二级索引的具体步骤,见图3。
(1)铁路调度监测系统的二级索引查询架构见图3(a),写入数据时:
wd1:数据“Id:1,Timestamp: 2018-09-24 00:00: 00.04,Station:站所443,Rtu:站所443,Analogname:遥测16385,Analogvalue:1800.0”写入铁路供电调度系统中。
wd2:铁路供电调度客户端将正序监测数据存入HBase数据库集群。
wd3:更新HBase数据库集群正序监测数据,重新构造索引结构同步至倒排索引库完成更新。
(2)读取数据时,通过二级索引架构读取:
rd1:在铁路供电调度主机客户端查询界面中输入所需数据关键词,如“Analogname:遥测16385”等。
rd2:调度客户端在倒排索引库中找出“Analogname:遥测16385”的倒排索引。
rd3:调度客户端根据所得倒排索引在集群HBase数据库中检索相应数据。
该架构实现二级索引查询的具体步骤见图3(b)。在调度主机查询界面输入数据非主行键关键词,如“遥测16385”;铁路供电监测集群将接收的倒排索引查询请求送至集群节点协调器,分发给集群节点倒排索引库。倒排索引库将检索到的关键词“遥测16385”相应倒排索引“Id:1_Analogname”返回监测集群;监测集群根据接收的倒排索引主行键“Id:1”发出主行键查询任务给集群节点协调器,分发给集群各节点HBase数据库中进行搜索。数据库进行一级索引,将主行键“Id:1”对应的数据返回铁路供电监测集群和调度主机。
通过非主行键条件查询快速定位所查数据主行键,再按主行键查询到调度主机需要的数据,以实现非主行键的二级索引和快速查询。
2.2 集群监控数据索引缓存
由于监测数据库体量大,采集时间、归属站所、测控终端编号等关键词重复度高,铁路供电调度系统进行监测和报警信息查询时,关键词查询结果过多影响读取速度,导致调度系统工作效率下降,可将这部分关键词倒排索引存入铁路供电调度集群的缓存中处理。而单台调度主机缓存处理能力有限,所以在HBase数据库集群中设置分布式缓存空间,实现多台集群节点缓存资源的共享,缓存查询系统工作流程见图4。
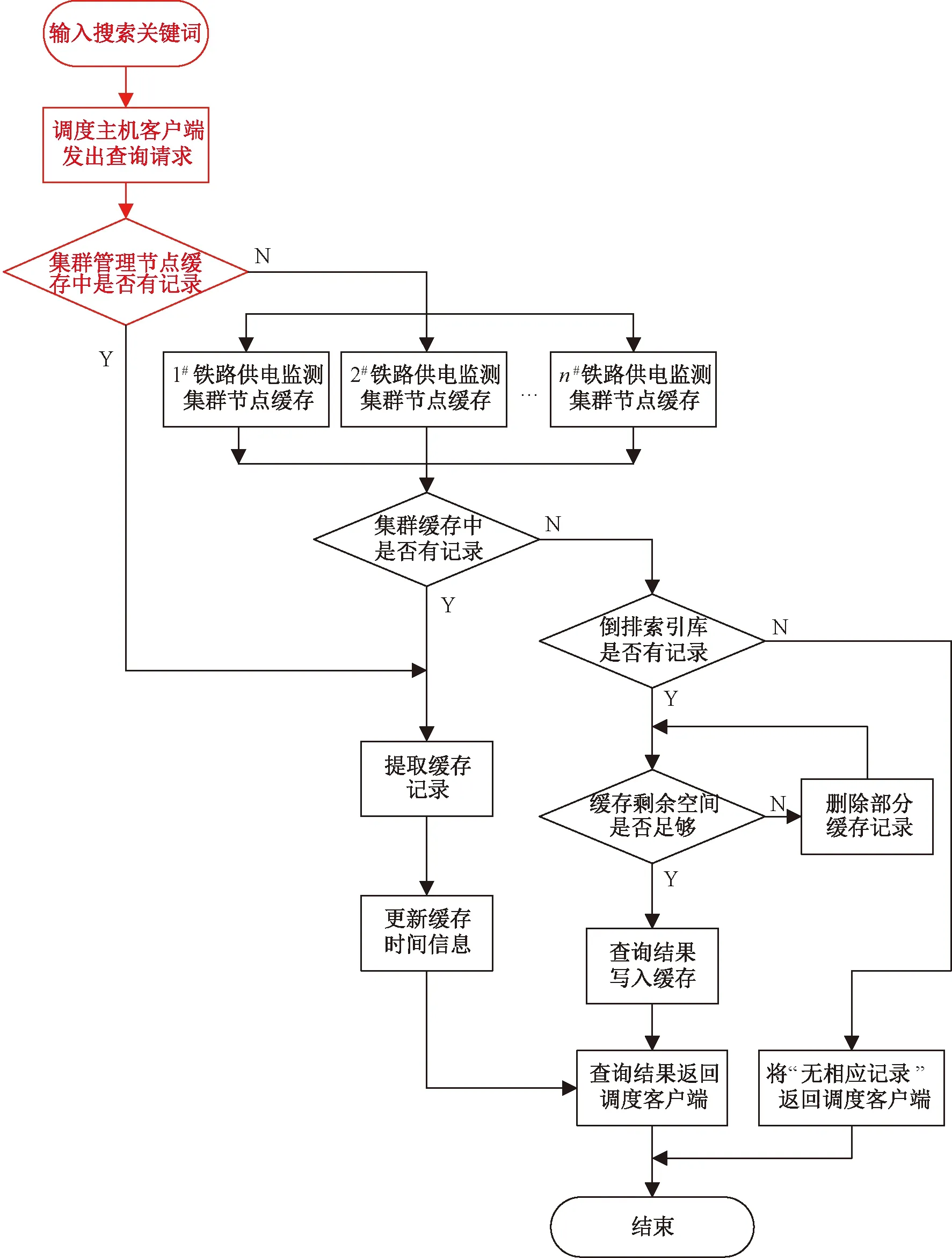
图4 缓存查询工作流程图
调度主机客户端接收查询请求,先检查铁路供电监测集群管理节点缓存是否存有此关键词检索结果。若无,则由任务调度模块将请求转发到其余铁路供电监测集群节点中继续查询。如果检索到相应缓存,则将查询结果送至调度客户端,同时更新缓存中此条记录的相关信息。若所有集群节点均未缓存所需信息,将请求转发至倒排索引库中查询。当集群倒排索引库中未储存相应数据时,将“无相应记录”返回调度客户端。当检索到相应数据时将查询结果送至调度客户端,同时将查询结果加入缓存,缓存服务器需要检查缓存区是否存满,若不满则写入缓存,否则删除部分缓存写入新数据。
直接按加入缓存顺序删除已有数据缓存的原生替换方法未考虑参考时间、归属站所、测控终端编号等重复度高的热点关键词进出缓存机制,可以通过热点缓存技术将热点关键词驻留缓存,提高搜索效率。
3 热点缓存的改进替换方法
3.1 热点缓存
缓存系统从逻辑上包括调度层和缓存层:调度层管理调度主机与集群节点缓存及数据交换,由节点管理模块和任务调度模块组成;缓存层包括缓存更新模块和缓存替换模块,对集群缓存中数据进行更新与淘汰,缓存系统架构见图5。
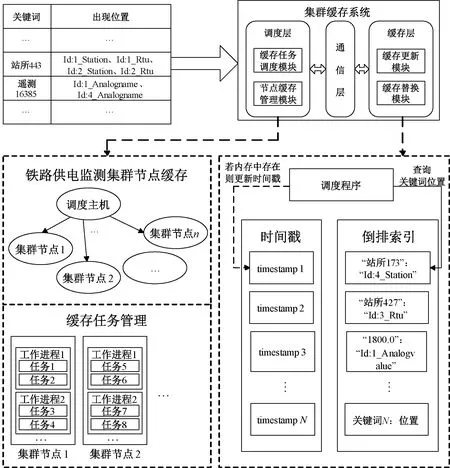
图5 缓存系统架构
在缓存系统处理时,将关键词查询的倒排索引结果,如关键词“站所173”位置为“Id:4_Station”,“站所427”位置为“Id:3_Rtu”,“1800.0”位置为“Id:1_Analogvalue”等储存在缓存中。H-CQ方法储存结构为链表,系统初始阶段缓存大量空闲,记录直接写入缓存,按写入顺序将关键词及其位置保存于缓存中。当缓存空间存满,缓存系统开始根据替换方法对缓存中的记录进行淘汰替换。
H-CQ方法以缓存历史访问时间进行替换,若缓存近期被访问,则未来可能被再次访问,缓存未被访问的时间越长,未来再次被访问的概率越低,当缓存空间存满时,将未被访问时间最久的数据淘汰,热点缓存淘汰过程见图6。

图6 热点缓存淘汰过程
以关键词倒排索引查询结果集“索引结果1”到“索引结果8”,组成链表式缓存存储在集群节点的缓存中,当调度主机提交查询申请“站所443”时,检查缓存空间可得“索引结果9(关键词:站所443,出现位置:Id:2_Rtu)”并未存入缓存,则将“索引结果9”保存至缓存中链表式缓存结构的头部,并把尾部未被访问时间最长的记录“索引结果8”从缓存中删除。当调度主机提交查询申请“遥测16385”时,可得“索引结果4(关键词:遥测16385,出现位置Id:4_ Analogname)”已存入缓存,则直接将“索引结果4”缓存记录返回调度主机,再把“索引结果4”提到链表式缓存结构的头部,其余数据顺次后移。
H-CQ方法管理更新缓存记录的时间戳,淘汰时根据时间戳淘汰未被访问时间最长的倒排索引记录,保留被访问可能性较高的记录。但为避免同时读写时间戳冲突,同一时间只允许一个线程对时间戳操作,对读写操作加互斥锁,故H-CQ方法对多线程读写的支持不够。
3.2 改进缓存淘汰策略及命中率
在工程应用中,铁路供电监测数据实时写入,若缓存系统仅支持单线程读写将严重影响读写效率,因此设计了一种新的热点缓存的淘汰策略,对H-CQ方法进行改进。改进的H-CRQ方法为每个缓存记录添加一个顺序编码AccessNum,表示访问顺序号,通过顺序编码管理更新缓存,避免对时间戳系统属性进行操作,提高H-CQ方法的多线程读写能力。同时设计一个自增型整数变量X,新增或访问缓存记录时将X赋值给AccessNum并不断自增。
改进的H-CRQ方法先设定期望保存的缓存记录数为KeepNum,期望删除的缓存记录数为RemoveNum,Xmax为变量X当前的值,Xmin为遍历缓存后记录中AccessNum的最小值。缓存更新时,遍历关键词索引缓存,对AccessNum进行讨论:
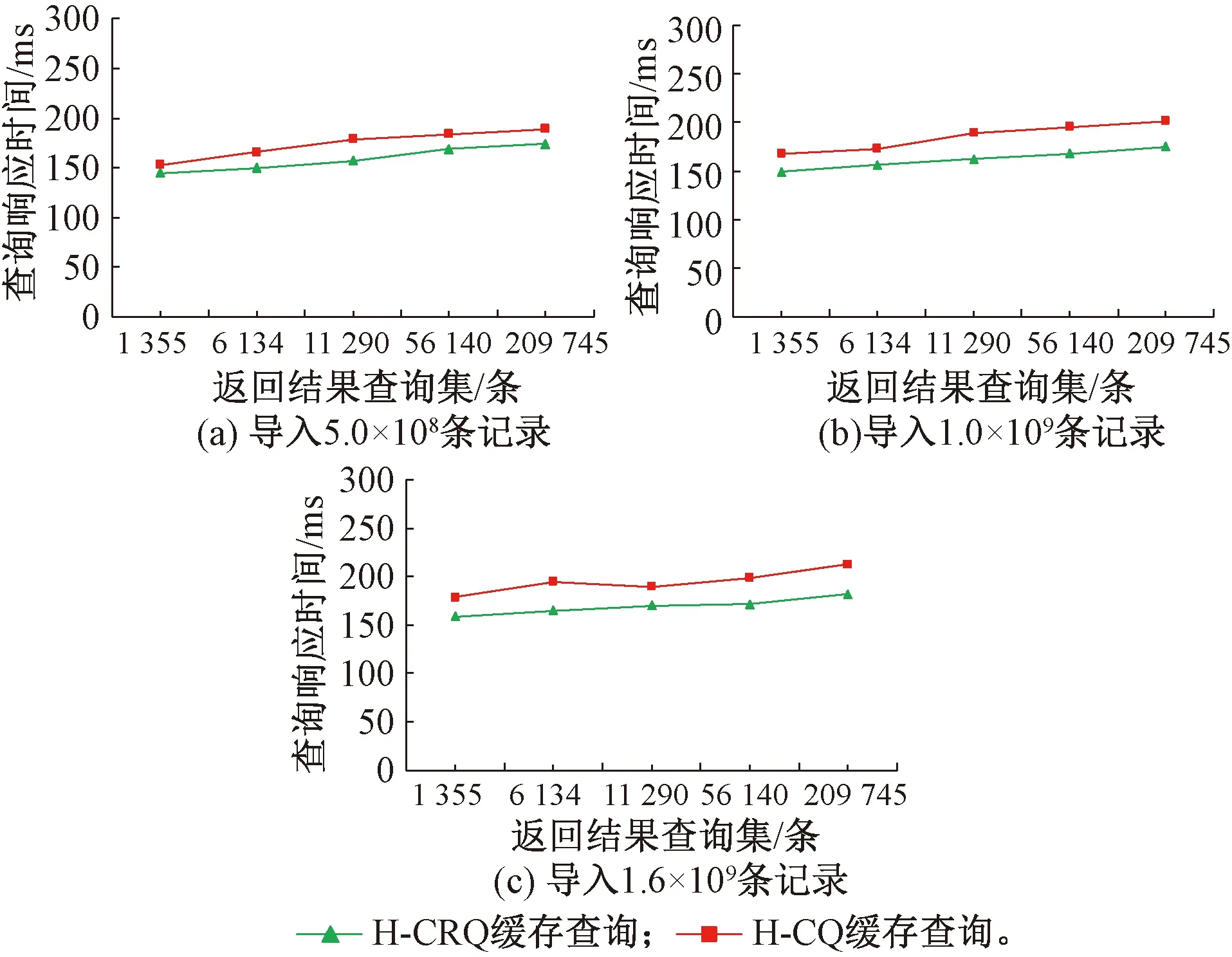
(1)若某一倒排缓存记录的AccessNum (2)若某一倒排缓存记录的AccessNum>Xmax+KeepNum,表示该缓存记录在近期被访问过,保留符合此条件的缓存; (3)对于Xmin+RemoveNum≤AccessNum≤Xmax+KeepNum的缓存记录,若一次遍历直接将缓存记录数量降到了KeepNum,则完成淘汰过程;若仍需继续淘汰关键词索引缓存,则对符合此条件的缓存重新遍历。如此反复淘汰,可使缓存容量降至KeepNum。 缓存空间的大小L为链表长度,即关键词索引缓存记录从链表头部到尾部被淘汰的替换次数,可反映缓存替换方法的更新速度。缓存记录被放入缓存后若在被淘汰前被再次访问视为缓存被命中,命中率代表监测数据集群进行的非主行键查询时该关键词索引已被缓存的概率。 因幂律分布适用于描述关键词的重复度与被使用频率的关系,所以关键词被查询的次数分布服从幂律分布,被查询的频率与它重复度排名的常数次幂成反比关系 pr∝r-c (1) 式中:pr为按重复度排名后,排序为r的关键词被查询访问的概率;c为幂律函数的常数。 根据热点缓存方法的替换策略,将按重复度排名后,排序为r的关键词索引结果缓存记录于缓存空间的概率,表示为 (2) 由于缓存空间包含有L个关键词索引结果缓存,令改进热点缓存算法的命中率为P,可得到命中率P的计算式 (3) 由于泊松分布用于描述单位时间内随机事件发生的次数,故关键词单位时间内被多次访问的概率服从泊松分布,由此可得排序为r的关键词单位时间内查询k次的概率Pt为 (4) 结合式(3)、式(4)可得,单位时间内排序为r的关键词被查询k次的命中率P′为 P′(Xr=k)=PtP= (5) 从式(5)可得,缓存空间的大小L对热点缓存算法的命中率P′有影响,呈正相关的关系。但根据最近最小使用原则,热点缓存容量一般设置为当前可用内存容量的1/8,缓存空间设置过大会影响计算机处理性能,导致查询的实时性下降。 以天水—兰州铁路10 kV供电监测系统导出的实测工程数据为算例,其供电示意图见图7。 图7 铁道供电监测系统算例示意图 根据铁路供电监测系统工程中的典型调度监测主站配置,设置2台数据服务器和2台主、备调度工作站搭建集群,在CentOS 6.8系统环境下,部署1个主节点和3个工作节点的铁路供电监测数据非主行键查询集群,集群环境参数见表1。 以遥测数据的采集时间Timestamp,归属站所Station,测控终端编号Rtu,采集对象标识Analogname以及采样值Analogvalue进行测试,对非主行键数据建立二级索引,测试设置缓存大小L对集群监控查询性能的影响及H-CRQ方法的查询性能。 表1 铁路供电监测数据非主行键查询集群环境 使用铁路供电监测数据非主行键查询集群,分别在一主一备模式和铁路供电监测“四机集群+查询测试机”模式下,导入1.6×109条铁路10 kV供电监测数据记录,并持续向集群数据库中更新监测数据,测试不使用缓存的扫描查询、H-CQ缓存查询和H-CRQ缓存查询在不同缓存空间大小情况下,查询相同关键词的查询性能,结果见图8。 图8 不同缓存大小时的查询性能对比 如图8所示,缓存空间过大时会对H-CQ缓存查询和H-CRQ缓存查询的性能造成影响。在铁路供电监测集群分布模式下,缓存中每个关键词出现位置平均为17个字节,每条缓存记录可返回查询结果集记录平均为10 000条,约占166 kB。若缓存记录条数设置为15 000条,缓存空间约占用2.37 GB,占集群总内存的12%,接近最近最小使用原则设置的当前可用内存1/8,因此当缓存空间设置小于15 000条时,不会对集群运行产生影响,H-CQ缓存查询和H-CRQ缓存查询性能均优于原生查询。而当缓存记录条数为18 000条时,缓存空间约占2.85 GB,占集群总内存的14%,超过了当前可用内存的1/8,对集群性能产生影响,查询处理的实时性降低,缓存查询耗时明显增加。 根据式(5)可得,缓存空间记录条数L与缓存查询的命中率P′呈正相关关系,而命中率P′越高,铁路供电监测数据集群进行非主行键查询时进行缓存查询的概率越大。则可得L设置越大,铁路供电监测数据集群进行缓存查询的概率越大。但缓存空间设置过大会影响集群工作性能,将给缓存查询处理带来一定的延时。 综上表明,并不能一味靠增加缓存空间大小达到增加铁路供电监测数据集群进行缓存查询的概率,提高查询效率的目的。在集群中根据可用内存合理设置缓存空间记录条数,可增加缓存查询命中率P′且不会对铁路供电监测数据集群运行产生影响,能有效提升铁路供电监测数据集群查询效率。 在四机集群中分别导入5.0×108、1.0×109和1.6×109条铁路10 kV供电监测数据记录,并设置缓存空间为15 000条,使用扫描查询和H-CRQ缓存查询对亿级铁路供电监测数据进行关键词查询,测试H-CRQ方法对海量重复数据查询优化效果。然后分别使用H-CQ缓存查询、H-CRQ缓存查询进行查询测试,对比多线程读写的情况下2种缓存算法的查询性能。 (1)关键词二级索引查询测试 在铁路供电监测数据集群正常运行情况下,以1.6×109条算例监测数据记录为输入,对关键词进行查询,关键词二级索引查询结构见图9。 图9 关键词查询结构 (2)H-CRQ缓存查询与扫描查询性能对比 在铁路供电监测数据集群正常运行情况下,分别以5.0×108、1.0×109和1.6×109条算例监测数据记录为输入,使用扫描查询与H-CRQ缓存查询对不同重复度的关键词数据进行查询性能测试,测试结果见图10。 图10 不同重复度的非主行键查询性能对比 由图10可得,非主行键二级索引查询返回结果集大小对原生非主行键查询性能有很大影响。如导入1.6×109条监测数据记录,当查询结果集记录条数为1 355条时,扫描查询与H-CRQ缓存查询性能无明显差距,耗时均为160 ms左右。但当查询结果集记录条数达万级以上时,扫描查询耗时明显增加,如查询结果集为209 745条记录时,扫描查询耗时312 ms,而H-CRQ缓存查询耗时182 ms。综上表明,H-CRQ缓存查询可以改善铁路供电监测数据非主行键查询集群中海量数据非主行键的查询性能,对重复度达20万条记录以上的数据记录,查询性能提高了42%。 (3)多线程读写情况下查询性能对比 在铁路供电监测数据集群正常运行情况下,分别以5.0×108、1.0×109和1.6×109条算例监测数据记录为输入,并持续向集群数据库中更新监测数据,同时使用H-CQ缓存查询和H-CRQ缓存查询对不同重复度的关键词数据进行查询性能测试,测试结果见图11。 图11 多线程读写下H-CQ与H-CRQ查询性能对比 由图11可知,多线程读写情况下,铁路供电监测数据写入对H-CQ缓存查询性能有一定影响,H-CQ缓存查询读取数据时,H-CQ方法对数据库更新操作加互斥锁,需等待写入进程结束后开始查询读取数据。等待写入操作时间不同,铁路供电监测数据写入对H-CQ缓存查询性能有不同程度的影响,而H-CRQ缓存查询的性能并未被数据写入操作影响,查询时间均少于H-CQ缓存查询。在写入进程影响下,导入1.6×109条监测数据记录,H-CQ缓存查询结果为209 745条的查询操作比H-CRQ缓存查询耗时多31 ms。表明H-CRQ缓存查询在多线程读写情况下查询性能优于H-CQ缓存查询,对重复度达20万条记录以上的数据记录,查询性能比H-CQ查询高15%。 (1)利用倒排二级索引和动态缓存机制,提出一种铁道供电综合监控海量数据的H-CRQ集群处理方法。将监控数据结构改变为倒排索引结构,查询直接根据特定关键词检索,并将倒排索引查询结果储存在缓存中,设计H-CRQ方法对缓存进行更新替换。通过四机铁路供电监测数据集群的非主行键查询测试比较,验证了H-CRQ缓存查询可有效提高铁路供电监测集群海量重复数据查询效率。 (2)以铁道供电实测监控信息数据为算例,进行多组非主行键查询响应测试。结果表明,缓存空间大小设置不超过当前可用内存的1/8时,H-CRQ查询可有效提高铁路供电监测集群海量重复数据查询效率,对重复度达20万条记录以上的数据记录,查询性能比全扫描查询高42%,且在铁路供电监测数据不断写入情况下,查询性能比H-CQ查询高15%。3.3 H-CRQ方法的命中率
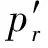
4 实验与结果分析
4.1 搭建测试集群


4.2 缓存空间对查询性能影响测试

4.3 查询性能对比测试

5 结论
