一种基于百度指数的城市日游客规模预测方法
2020-12-07任欢刘婷康俊锋潘宁李敏靓艾顺毅
任欢,刘婷,康俊锋,潘宁,李敏靓,艾顺毅
(1.杭州师范大学理学院,浙江杭州 311121;2.首都师范大学资源环境与旅游学院,北京 100048;3.江西理工大学建筑与测绘工程学院,江西赣州 341000;4.郑州旅游职业学院,河南郑州 450000)
科学合理且精准的游客规模预测不仅能为景区管理者提供管理决策依据,也能提醒游客避开热点区域,增强旅游体验效果。因此,游客规模预测一直是旅游研究的重要方向之一。传统的游客规模预测大多基于政府及相关管理部门的统计报告数据和抽样调查数据,存在时间尺度较大、数据滞后、数据量达不到预测建模要求等问题[1]。以新浪微博为代表的位置签到数据在旅游研究中获得了广泛关注,成为重要的数据源。位置签到数据是利用带有GPS的智能终端记录某一时刻某处产生的具有空间性、时间性和社会化属性的数据信息,以大众签到的兴趣点为主要表现形式[2],是一种重要的众源地理数据。旅游景区的位置签到数据可精确到日,通过研究位置签到数据与实际数据的关系,模拟实际游客量,以弥补传统预测方法在时效性和精确度上的不足[3]。通过获取游客出行前的网络搜索数据,预测其之后的旅游活动成为互联网时代探究旅游出行特征的新方法。百度公司推出的以海量网民行为数据为基础的数据分析平台——百度指数(http://index.baidu.com),是网络搜索数据的优质数据来源。
基于百度指数预测实际数据最早在社会领域得到应用,如预测失业率和流行病[4]等,之后在居民消费预测[5]、股票市场预测[6]、房地产市场预测[7]等经济领域得到广泛应用,并取得了丰硕成果。当前,基于百度指数的旅游研究多集中于探讨实际游客量与网络关注度在时间维度[8-10]和空间维度[11-12]上的关系,结合网络搜索数据和实际游客数据建立预测模型的研究[13-14]逐渐兴起,如任乐等[15]结合百度指数与历史数据构建北京市旅游客流量预测模型等,但其中使用的实际游客量多基于传统统计数据,模型的解释变量多由简单的关键词词组构成,忽视了网络大数据本身的地理位置等特有属性。.
本文以杭州市为例,用新浪微博签到人数模拟实际游客量,结合计量经济学中的协整检验和格兰杰因果关系检验,分析百度指数与新浪微博签到人数之间的关系,用新浪微博签到人数单独建立杭州市日游客规模自回归移动平均(auto regressive moving average,ARMA)模型并进行预测,然后与加入基于百度指数空间分布特征及主成分分析后提取的3 个解释变量的向量自回归(vector auto regression,VAR)模型进行预测精度的比较与分析,通过挖掘数据时空属性的价值以填补游客规模预测过程中网络数据的冗余、关键词选取的随机性,以得到更快速准确的预测效果。
1 游客规模预测方法
1.1 基于ARMA 模型的游客规模预测
ARMA 模型是时间序列分析的重要方法,常用于资料的长期追踪研究。式(1)为(p,q)阶的自回归移动平均模型,即ARMA(p,q)。
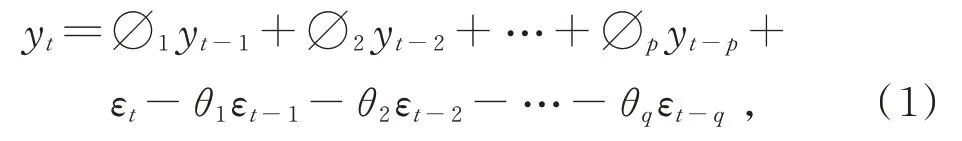
其中,p为自回归模型的阶数,q为移动平均模型的阶数;∅1,∅2,…,∅p为自回归系数,θ1,θ2,…,θq为移动平均系数,这些均为模型的待估参数;εt为残差,yt为观测值。AR 模型和MA 模型是ARMA(p,q)模型的两种特殊情况,若阶数q=0,则为自回归模型AR(p);若阶数p=0,则为移动平均模型MA(q)。
本研究使用景区内每日新浪微博签到的时间序列数据单独构建ARMA 模型,以预测游客规模。
1.2 基于VAR 模型的游客规模预测
VAR 模型是多元时间序列分析中最常用的方法之一。它基于数据的统计性质,将系统中每个内生变量作为系统所有内生变量的滞后值的函数,并用其构造模型,通常用于预测相互联系的时间序列系统,分析随机扰动对变量系统的动态冲击,解释各种经济冲击对经济变量形成的影响[16]。本研究基于百度指数数据对ARMA 模型进行优化,首先,用技术取词法确定百度指数关键词;其次,根据百度指数数据的空间分布特征提取3 个主成分,分别通过单位根检验、协整检验和格兰杰因果关系检验分析新浪微博签到人数和3 个主成分的关系;最后,构建新浪微博签到人数与百度指数的VAR 模型:
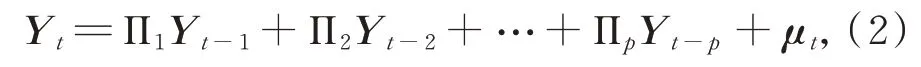
其中,Yt为由k个内生变量组成的向量,Yt=(TPt,BD1t,BD2t,…,BD(k-1)t);μt为k维随机扰动向量;p为滞后阶数;Π1,Π2,…,Πp为k×k维待估系数矩阵。
基于百度指数的游客规模预测优化技术路线如图1 所示。
2 实证研究
2.1 研究区域和数据来源
选择杭州为旅游目的地进行研究。杭州市位于我国东部,是浙江省的省会城市,旅游资源丰富,美丽的自然风光与独特的人文历史景观合而为一,为我国最佳旅游目的地城市之一。
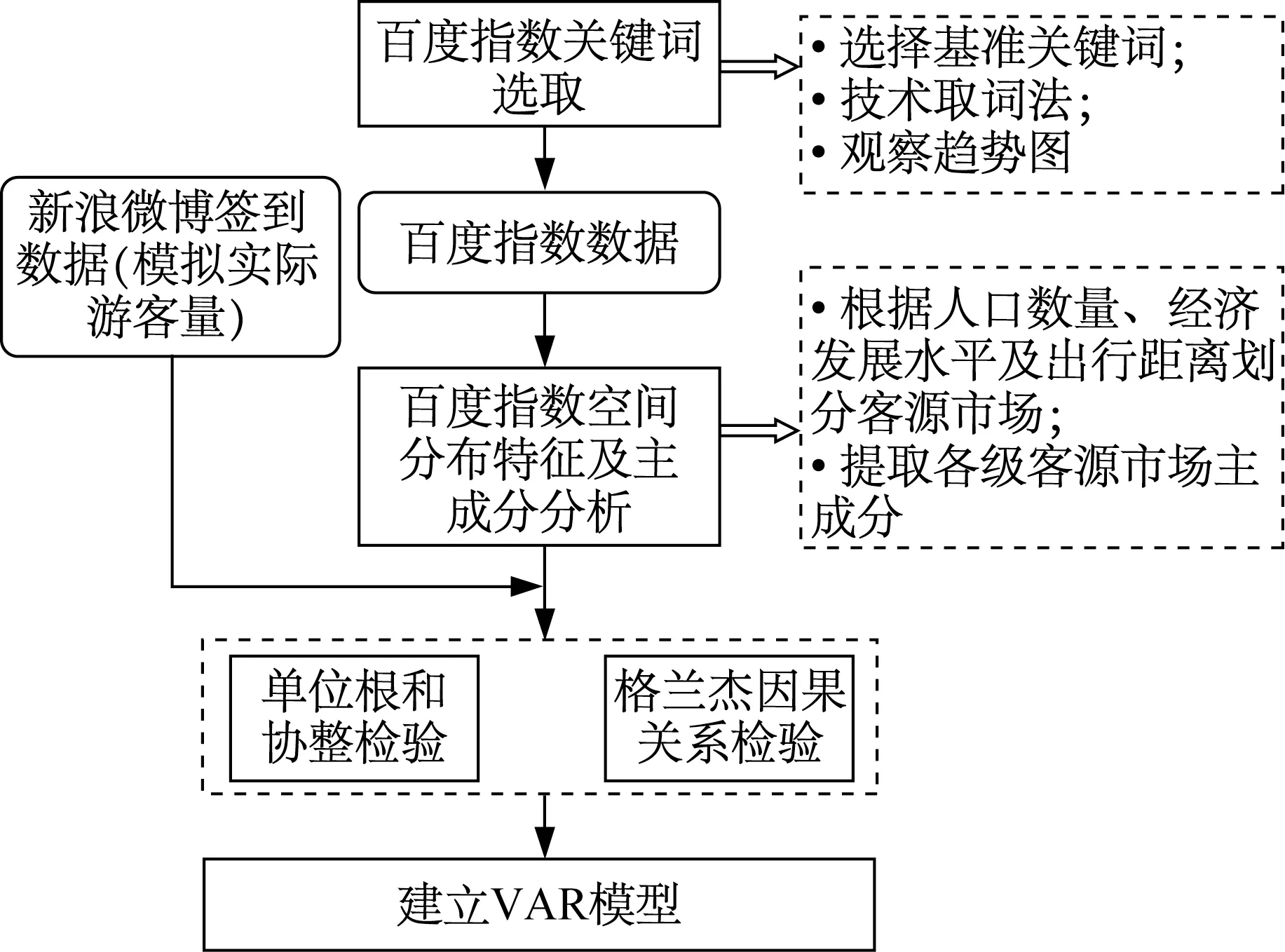
图1 基于百度指数的游客规模预测模型优化技术路线图Fig.1 Optimization technology roadmap of tourist scale forecast model based on Baidu index
通过新浪微博应用程序接口(application programming interface,API)抓 取2012—2015 年 杭州市景区兴趣点(point of interest,POI)位置签到数据,根据微博用户注册信息分析客源市场结构,并与2014 和2015 年浙江省国内旅游抽样调查报告中的客源市场结构进行相关性分析。利用皮尔森相关系数研究实际游客市场结构与微博签到用户市场结构的关系。计算结果表明,2014 和2015 年杭州市客源市场结构与微博签到用户市场结构之间的相关系数分别为0.980 和0.973,p值均小于0.05,即实际游客市场结构与微博签到用户市场结构之间有极强相关性,可用新浪微博每日签到人数模拟实际游客量。为此,采用2012—2015 年在新浪微博平台上杭州市所有景区POI 每日位置签到数据(以下简称微博签到人数)模拟实际旅游人数。
本研究的解释变量为杭州旅游相关关键词的百度指数。考虑百度指数的地理空间属性,共获取2012—2015 年34 个省(直辖市、自治区、特别行政区)以及全国逐日时间序列的百度指数数据。
2.2 ARMA 模型与预测分析
首先,用微博签到人数模拟实际游客量,根据微博签到人数时间序列的自相关和偏自相关图,选择ARMA 模型的阶数。其次,根据拟合优度R2、赤池信息准则(Akaike information criterion,AIC)、施瓦兹信息准则(Schwarz criterion,SC)和均方根误差(root mean squared error,RMSE)对模型进行评价,最终确定的ARMA 模型为ARMA(8,2)。此模型具有较小的AIC 值和SC 值,模型调整后的拟合优度较高,拟合效果较好,且具有较小的预测均方根误差。为比较模型的预测能力,选择2012 年1 月1 日至2015 年12 月31 日的数据作为训练样本,选择2016 年1 月的数据作为测试样本,进行模型检验,公式如下:

其中,WEIBO 表示微博签到人数。调整后的拟合优度为0.715 7,AIC 值为11.735 2,SC 值为11.778 7,AR 模型根的倒数和MA 模型根的倒数均在单位圆内,表明模型是稳定的。用式(3)对样本期内的杭州旅游人数进行预测,均方根误差为84.721 3。同时,对样本期外的2016 年1 月的杭州旅游人数(这里指用微博签到人数模拟的游客量)进行预测,均方根误差为111.172 3。
2.3 基于百度指数的VAR 模型的优化
2.3.1 百度指数关键词的选取及其空间特征分析
采用技术取词法选取百度指数关键词。首先,利用网络技术尽可能获取所有相关搜索关键词,并构建词与词间的相关性;然后,基于关键词词组和关键词与研究目的相关性分析结果,确定模型关键词。选取百度指数关键词的步骤如下:
(1)以“杭州旅游”为基准关键词,采用技术取词法找到相关的搜索关联词,发现与“杭州旅游攻略”“杭州旅游景点大全”和“杭州旅游”的关联程度较高。
(2)通过观察3 个关键词的百度指数搜索趋势图,发现“杭州旅游攻略”的搜索数据更具趋势性变化且逐年递增,因此,将“杭州旅游攻略”确定为百度指数关键词。
对比2012—2015 年杭州市微博签到人数与“杭州旅游攻略”百度指数数据(图2(a)和(b))可以发现,百度指数增幅大于微博签到人数增幅,且两者差距逐渐增大,说明越来越多的人在出行前通过百度搜索旅游目的地相关内容,了解目的地信息,制订旅行计划。选 取2013 年8 月7 日至2013 年12 月9 日(图2(c)和(d))为时间窗口,发现两者虽然在数值上差异很大,但是在整体趋势、起伏变化和滞后性等方面大致相似。
在ARMA 模型基础上,增加百度指数关键词“杭州旅游攻略”,并将其作为模型的解释变量以优化模型,为避免模型的共线性,降低对预测模型的干扰,需要根据百度指数的地理空间特征提取更合适的解释变量,以进一步提高预测精度。
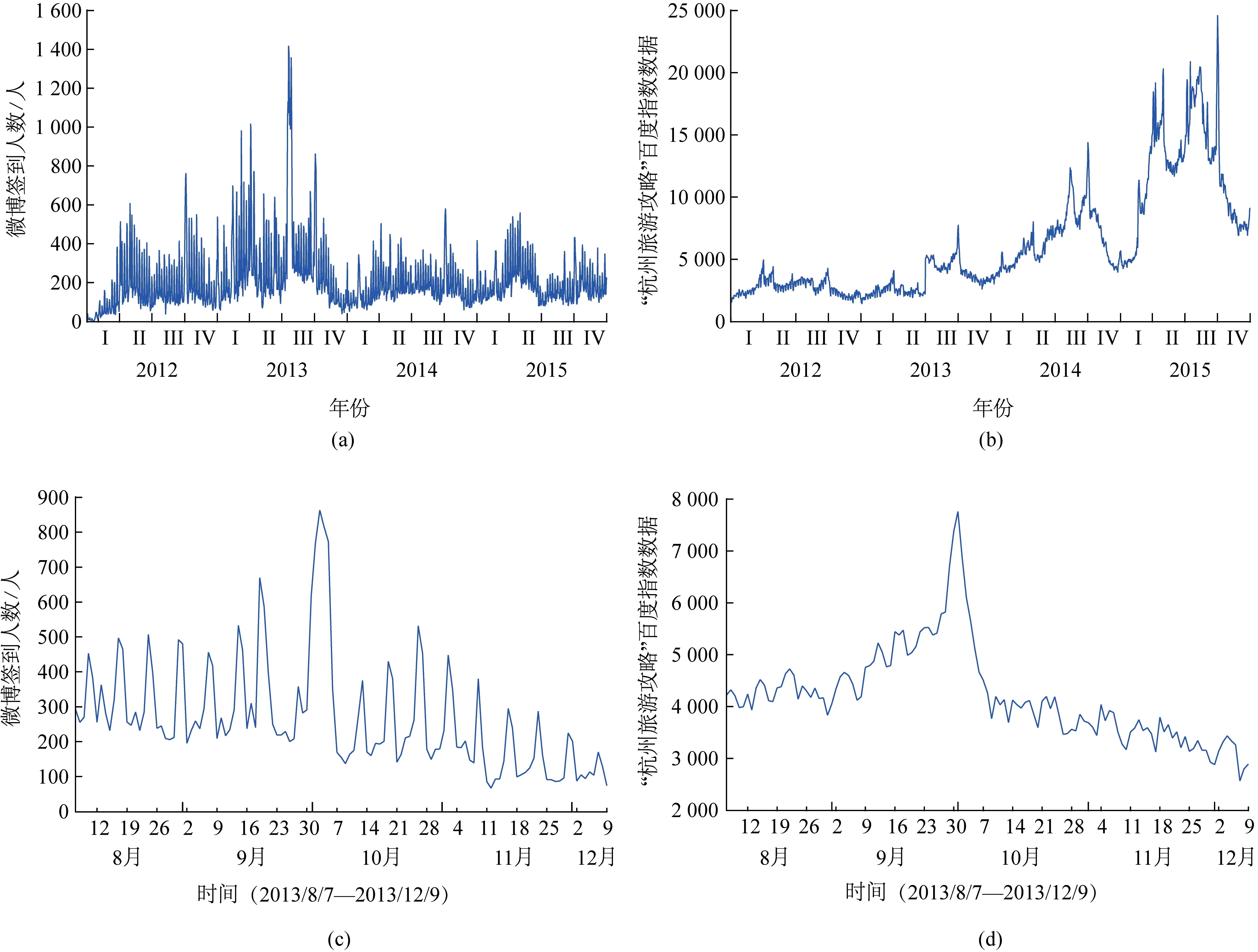
图2 微博签到人数与“杭州旅游攻略”百度指数数据对比Fig.2 Comparison of the Baidu index data of"Hangzhou Tourism Strategy"with Sina Weibo check-in number
综合考虑地区人口数量、经济发展水平及出行距离,对34 个省(直辖市、自治区、特别行政区)进行可视化分类,将客源市场划分为核心市场区域、一般市场区域和边缘市场区域。其中,核心市场区域经济发达,与杭州距离较短或者两地间交通便捷;一般市场区域人口规模较大、经济水平中等且与杭州市有一定距离;边缘市场区域人口规模较小或距杭州市较远。地区分类结果如图3 所示。图3 中,距离指地区行政中心到杭州市的距离,以km 为单位;圆形大小代表人口规模,以广东省人口规模为基准进行变换;颜色代表所在的市场,红色为核心市场区域,黄色为一般市场区域,绿色为边缘市场区域(为更好地展示效果,图中未标注与杭州市距离超过3 800 km 的新疆和西藏,此两地实际属于边缘市场区域)。
由图3 和图4 可知,核心市场区域、一般市场区域和边缘市场区域最明显的差异是百度指数数据。为减少预测模型中的自变量,降低多重共线性的干扰,对3 个市场区域的百度指数进行主成分分析。首先,分别计算3 个市场区域中变量的KMO(Kaiser Meyer Olkin)统计量,得到核心市场区域、一般市场区域和边缘市场区域的KMO 值,分别为0.896,0.969 和0.985,说明适合用主成分分析法。然后,在核心市场区域中提取一个主成分HXSC(核心市场),贡献率为93.027%;在一般市场区域中提取一个主成分YBSC(一般市场),贡献率为94.521%;在边缘市场区域中提取2 个主成分F1、F2,贡献率分别为63.909% 和5.940%,将这2个主成分按解释比例分配,构成一个新的成分BYSC(边缘市 场,BYSC=63.909%×F1+5.940%×F2)。将所有原始变量(34 个省(市、区),已经被分为3 个市场区域)线性组合为3 个综合变量HXSC、YBSC、BYSC(见图4(d)),并且用此3 个变量代替3 个市场区域,它们与3 个市场区域的原始变量关系如下:
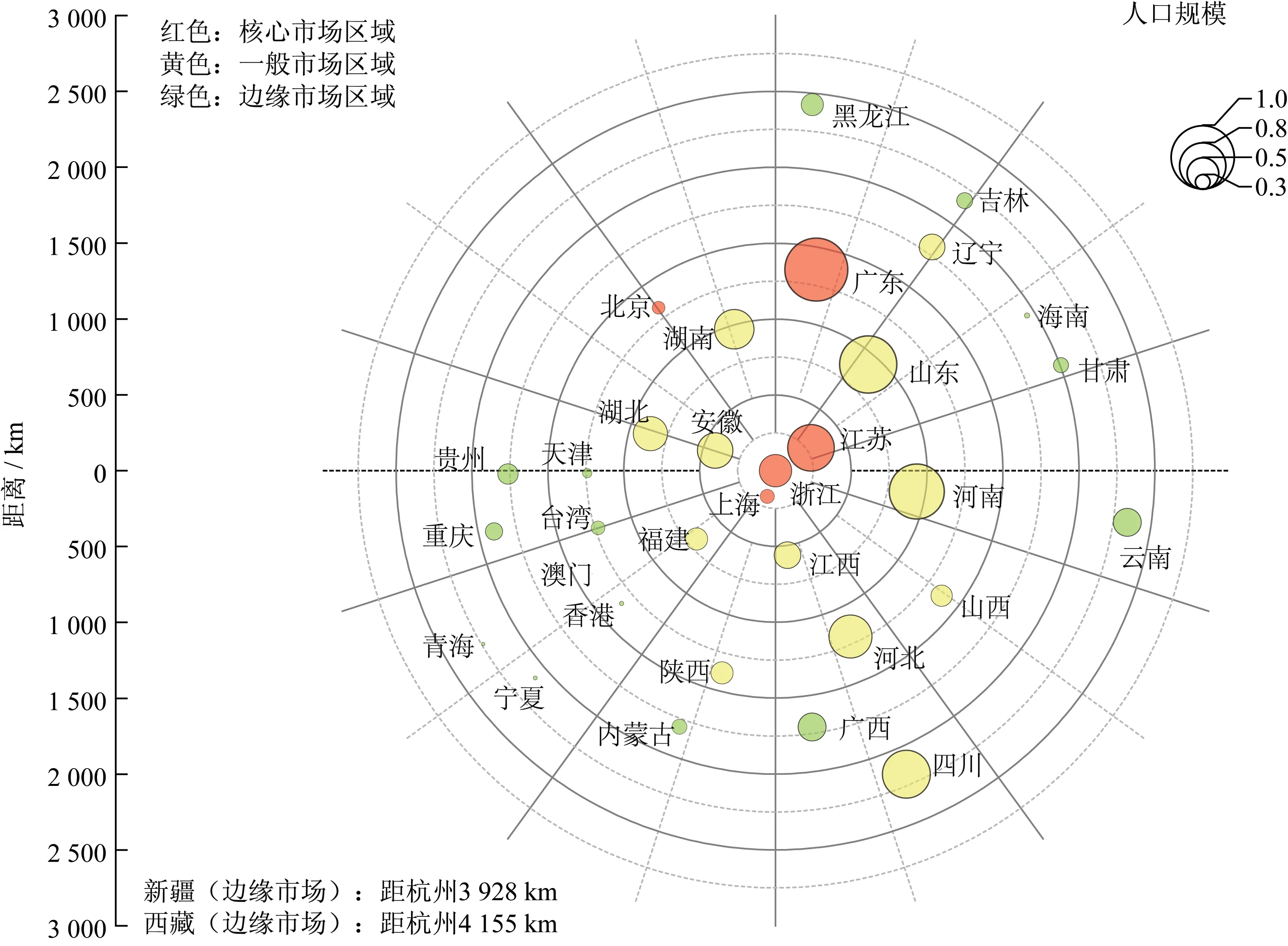
图3 地区分类结果Fig.3 Results of regional classification


2.3.2 单位根检验和协整检验
为保证时间序列的平稳性和避免伪回归现象,在建立计量经济学模型之前对序列进行单位根检验和协整检验。单位根检验采用ADF 检验法[16],检验结果见表1。
由表1 可知,微博签到人数序列和主成分核心市场原序列为平稳序列,一般市场和边缘市场的原序列不平稳,一阶差分后平稳,为一阶单整。此4个变量符合协整检验的前提条件。采用Johansen协整检验微博签到人数与百度指数3 个主成分之间的均衡关系,结果如表2 所示。由表2 可知,原假设为“最多有3 个协整关系”的特征根迹检验和最大特征值检验在0.05 显著性水平上接受原假设,说明微博签到人数、核心市场、一般市场和边缘市场4 个变量间存在3 个协整关系,即百度指数基于地理空间分类的3 个市场与微博签到人数之间具有长期均衡关系,因此可以用这4 个变量建立VAR模型。
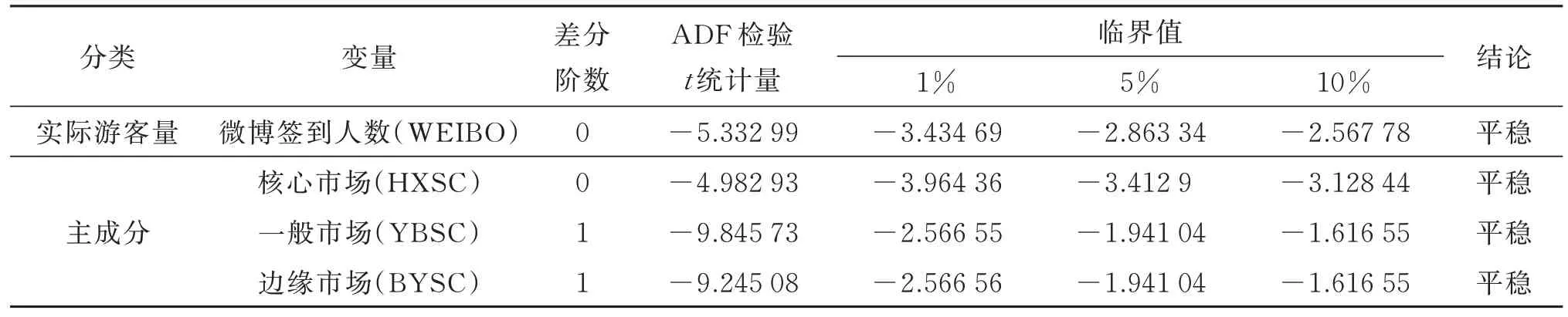
表1 变量的单位根检验结果Table 1 The results of variables unit root test
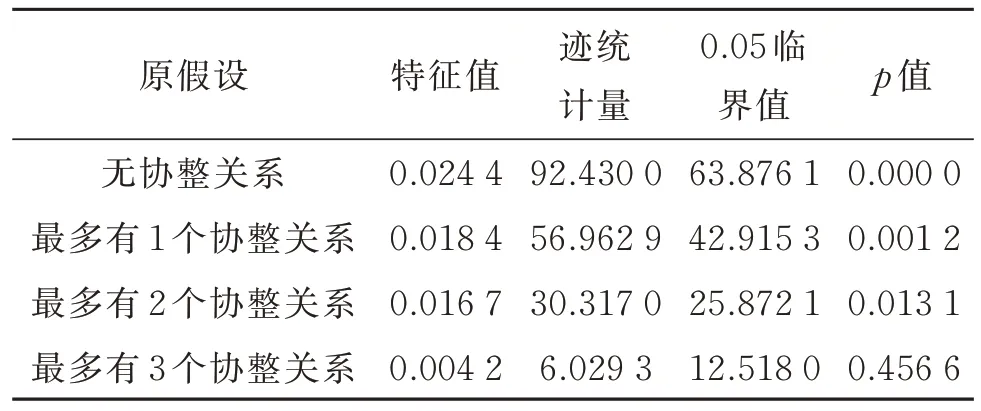
表2 Johansen 协整检验结果Table 2 The result of Johansen co-integration test
2.3.3 格兰杰因果关系检验
格兰杰因果关系能够检验变量之间是否具有预测能力,其对滞后期的选取较敏感。根据AIC 和SC等信息准则确定最优滞后期,对核心市场、一般市场、边缘市场与微博签到人数进行格兰杰因果关系检验,结果如表3 所示。
由表3 可知,主成分核心市场与微博签到人数间存在双向因果关系,即主成分核心市场与微博签到人数互为格兰杰因果的概率几乎为100%。主成分一般市场、主成分边缘市场与微博签到人数均存在双向因果关系。即这3 个主成分与微博签到人数都是相互影响的。本质上可以将百度指数看作某地区对杭州的公众关注度的表征,所以这一结果也验证了“实际游客到访前会关注旅游目的地城市,到访后会提高对旅游目的地城市的关注度”这一结论。
2.3.4 建立VAR 模型
将3 个主成分作为解释变量加入VAR 模型进行预测。首先,通过滞后长度准则确定VAR 模型的最优滞后阶数。在5 个评价指标(似然比检验LR、最终预测误差FPE、赤池信息准则AIC、施瓦茨准则SC、汉南-奎因信息准则HQ)中,3 个指标的最优滞后期为23,因此选取VAR(23)进行建模。该模型以微博签到人数为被解释变量,以其自身和3 个“杭州旅游攻略”百度指数的主成分为解释变量,构成回归函数,公式为
其中,WEIBO 表示微博签到人数,HXSC、YBSC、BYSC 分别表示从核心市场、一般市场、边缘市场提取的3 个主成分,其中C(j,i)表示参数j(包含1~4,分别代表参数WEIBO、HXSC、YBSC、BYSC)的系数估计值,滞后阶数i=1,2,…,23。调整后式(9)的拟合优度为0.765 4,AIC 值 为11.586 3,SC 值 为11.927 2。此模型的所有特征根倒数的模都在单位圆内,因此该模型是稳定的。
VAR(23)模型与ARMA(8,2)模型的预测效果对比如表4 所示。加入关键词的3 个主成分后,VAR(23)模型的拟合优度得以提高,AIC 值减小,增强了对微博签到人数的解释能力。利用式(9)对样本期内人数进行预测的均方根误差为73.799 5,与ARMA(8,2)模型的均方根误差84.721 3 相比,预测精度提高了12.9%。为进一步检测式(9)的预测能力,对样本期外(2016 年1 月)的杭州实际游客量进行了预测,预测的均方根误差为80.206 6,与ARMA(8,2)模型预测的均方根误差111.172 3 相比,精度提高了27.9%。因此,VAR(23)模型较ARMA(8,2)模型具有更好的预测能力。

表4 ARMA(8,2)模型和VAR(23)模型预测效果对比Table 4 Comparison of prediction effect between ARMA(8,2)model and VAR(23)model
3 结论
以杭州市为例,基于2012 年1 月1 日至2015 年12 月31 日的微博签到人数以及百度指数数据,利用协整检验和格兰杰因果关系检验,分析了微博签到人数与具有地理空间属性的百度指数间的关系,对微博签到人数单独预测模型和加入具有时空分布特征的百度指数数据后的模型进行了比较,并对比了2 个模型的预测精度,得到以下主要结论:
3.1 微博签到人数与旅游统计调查数据具有较强的相关性,利用精确到日的微博签到人数模拟游客量,可降低数据的时间粒度。
3.2 百度指数在时间特征上具有延后性和前兆效应。杭州市微博实际签到人数与经空间划分从“杭州旅游攻略”百度指数中提取出的核心市场、一般市场和边缘市场3 个主成分之间存在长期均衡关系,且3 个市场与微博签到人数之间均存在双向格兰杰因果关系。研究表明,微博签到人数与百度指数数据是相互影响的,百度指数与实际出行人数具有相关性,实际游客到访前会关注旅游目的地城市,到访后会提高对旅游目的地城市的关注度。此外,研究发现,从百度搜索到实际旅游的滞后期为1~23 d,因此,不仅可以利用百度指数数据预测未来23 d 的游客规模,而且还可以利用这23 d 的窗口期加强旅游目的地城市的宣传,提高潜在游客的旅游意向,将其转变为实际游客。
3.3 旅游目的地临近区域搜索率较高且出行率随之增加。根据关键词“杭州旅游攻略”的百度指数数据的空间划分结果,发现为“杭州旅游攻略”提供最大搜索量的核心市场除距离杭州较近且人口规模大、经济发达的上海、江苏省等外,还包括与杭州距离较远但拥有便利交通的北京、广东省等,说明旅游出行率还与交通便利程度有关。因此,需及时关注不同市场的交通发展状况,新增交通路线会改变途经地区对旅游目的地的搜索贡献量,从而引起三级市场的变化。
3.4 百度指数的地理位置属性有助于提升预测精度。本文依据百度指数的地理位置属性将其划分成3个市场,相比基于微博签到人数单独建立的ARMA模型,基于百度指数地理空间分布特征建立的模型在样本期内的预测精度提高了13.1%,在样本期外的预测精度提高了27.9%,说明百度指数对预测实际游客量有正向作用。同时,模型的优化结果说明,除数值外,数据的地理位置属性也存在研究价值。
值得说明的是,本文提出的基于百度指数的游客规模预测VAR 模型,在研究区域上有一定局限性,适用于有实际游客量的地区,如可监控游客量的封闭景区。此外,微博、QQ、微信等社交平台和百度、谷歌等网络搜索引擎都是信息的载体,人们在微博等社交网站上表达观点、宣泄情绪等所体现的是信息供给行为,反映了使用者的情绪;而用网络搜索引擎搜索信息,体现的是信息需求行为,反映了使用者的关注度[17]。因此,未来的研究既可以从多平台角度入手,又可以加入互联网信息内容进行分析,获得游客的观点和行为,进一步推进基于互联网大数据的旅游规模预测研究。
