数字化藏文古籍中多样性字体的实现方法研究 *
2020-11-30朱倩倩车文刚
朱倩倩,车文刚,苗 晗
(昆明理工大学信息工程与自动化学院, 云南 昆明 650500)
1 引言
文字是民族文化的承载工具,一笔一画都有着浓厚的文化底蕴。藏文作为藏族人民在政治、经济、文化和宗教活动中的文字承载工具,在中华民族历史文化发展长河中形成了独特的文字形式[1]。在长久的历史过程中,流传下来大量藏文经典文献,其中,许多经典文献采用雕刻这种原始方式传承至今,它们的最大特色是拥有风格迥异的雕刻字体,独特的雕刻方式和构造赋予其极致的美感,充分表现了不同历史文化背景下人们对雕刻字体的美学理解和文字背后的宗教精神[2]。
由于这些文献种类繁多,目前对这些经典藏文文献的保存方式主要有2种。一种是通过直接扫描保存成电子图像。这种方式保留了原版雕刻字体细节,但它需要处理的数据量巨大,且不能实现编辑、查询、排版等计算机文字信息处理的基本功能[3]。另一种是将古籍电子化保存成电子文档,采用统一的标准版藏文字体保存,实现了编辑、查询等功能,但却丢失了原版古籍中多样的雕刻字体[4]。
针对上述问题,本文提出一种既可以数字化藏文古籍中多样性的雕刻字体,又能实现古籍编辑、查询等功能的方法。目前,北京大学计算机科学技术研究所提出了风格学习算法,自动生成大规模手写字体[5];清华大学提出了SA-VAE(Style-Aware Auto-Encoder)框架,仅通过观察一个或者少数样本来生成不同风格的汉字[6]。这些方式生成的计算机手写字体,只还原了用户书写的一种字体,仍然没有实现手写字体的多样性和离散性。
因此,本文提出了计算机字体多样性表达的方法,使藏文经典文献在实现编辑、共享的基础上,保留原版文献中雕刻字体的多样性和离散性。
2 相关定义
本文以明末崇祯(1628-1644)年间铸成的理塘版《大藏经》为研究典例[7]。目前《大藏经》文献已经实现了采用统一的Microsoft Himalaya字体的电子文档保存。本文的目的是提取理塘版《大藏经》中多样和离散的雕刻字体,再通过字体多样性表达方法实现数字化理塘版《大藏经》中多样和离散的雕刻字体,还原原版文献中字体的细节,保存雕刻字体的美感和艺术效果[3]。
数字化具有多样性雕刻字体的古籍,主要工作是提取古籍中不同风格的字体和实现字体的多样性表达。因此,本文将研究内容分为5个部分:图像预处理、图像分割、字符识别、字体分类和字体多样性表达。图像分割,根据文本行间距的不同,采用不同分割算法,对于文本行间距明显的情况优先选用投影分割法[8],文本行间有重合但不粘连的情况采用连通域分割法[9],文本行或字符间有粘连的情况用滴水算法分割文本图像[10]。字符识别,本文采用由Oliva等人提出的全局GIST特征提取算法,对藏文文献中的字符进行识别, GIST特征是最好的全局特征之一,能快速描述文字在视觉维度上的结构信息,描述子相对简单[11],能很好地表征藏文的结构特征,因此GIST特征广泛应用于字符的特征描述。字体分类,字体分类算法目前不是很多,主要采用深度学习框架,利用深度学习来训练分类模型,对书法字图像进行字体的分类[12]。目前计算机字库中的藏文字体类别有限,因此利用深度学习训练模型来实现藏文字体分类显然在目前是不可行的。如何实现理塘版《大藏经》中字体的多样性表达,目前还没有发现相关研究,因此本文提出字体多样性表达方法。为了提高藏文字识别的准确性,指定标准Microsoft Himalaya字体作为参考字符集。为了研究需要,下面先给出如下定义:
定义1(雕刻字体) 本文要研究的雕刻字体就是雕刻在木板上的理塘版《大藏经》中的字体。
定义2(字体的多样性) 由于理塘版《大藏经》是在不同的时间阶段由不同的雕刻师雕刻而成的,受主观和客观因素的影响,同一部经文中呈现出一字多字体的现象,这定义为字体的多样性。
定义3(计算机字体的多样性表达) 计算机自动调用字体库中不同风格的字体,使同一个文字有多种字体呈现,这样就实现了字体的多样性表达。
3 提取雕刻字体
数字化理塘版《大藏经》雕刻字体的关键是提取经文中多样和离散的雕刻字体。因此,本节内容分为4个部分:图像预处理、图像分割、字符识别和字体分类。
根据理塘版《大藏经》雕刻字体具有多种风格的特点,初步构建理塘版《大藏经》字体的组成模型如图1所示。

Figure 1 Engraving font图1 理塘版《大藏经》字体
3.1 图像预处理
首先对理塘版《大藏经》文稿进行预处理。如图2a所示为扫描到计算机内的理塘版《大藏经》部分原始图,图像有边框,且文本存在倾斜,因此需要对图像进行去噪声、去边框、版面倾斜处理、二值化、反相等处理,得到如图2b所示的图像。图像预处理是为下一步的图像切分做准备[3]。

Figure 2 Image preprocessing图2 图像预处理
3.2 图像分割
观察图像中文本分布结构,由于文稿行与行之间排列规整,故分2步切分,先完成行切分,再完成字符切分。切分时可能会出现的情况有:
(1)行与行间有明显间距,易切分。
针对这种情况,采用操作简单、速度快的投影分割算法对文本图像做水平全局投影[8],以便将行间有明显间距的文本行做切分处理。如图3中像素值总和为0的点(图像背景区像素的值为0,目标区域的像素值为1),即为行切分点。
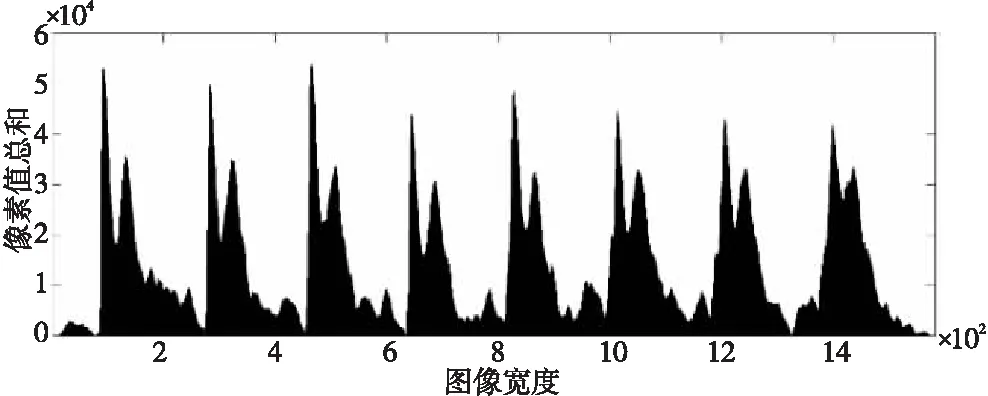
Figure 3 Projection of rows图3 水平投影图
(2)行与行间存在重叠,但不粘连。
针对这种情况,采用局部连通域分割算法,尽管图4a行间无公共间距,但是字母与字母之间是有明显间隙的,连通域分割算法正是针对这种情况的图像分割算法。本文采用8-邻域标记算法[13]:扫描每个像素点,遍历当前点上、下、左、右、左上、左下、右上、右下的点像素值,若与当前点像素值相同,则将位置相邻且像素值相同的点组成的像素区域赋予唯一的标记,这里用数字标记,根据标记的连通区域实现文字分割[9]。连通域分割算法可将无明显间隙但又不粘连的文本块分割成单个字符。

Figure 4 Connectivity detection segmentation图4 连通检测分割
(3)行与行间存在粘连。
字符之间存在粘连现象时(如图5a所示),本文采用文献[10]改进的滴水算法分割图像。首先采用Zhang提出的并行细化方法处理粘连字符,只保留图像的拓扑结构,然后确定候选分割点,再通过自组织映射网络确定最终分割路径(如图5b所示),实现粘连字符的分割。
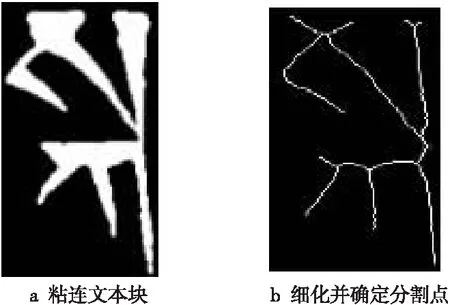
Figure 5 Image segmentation by improved drop-fall algorithm图5 改进的滴水算法分割图像
针对以上3种情况,采用不同的分割算法对文本图像进行分割,将理塘版《大藏经》文本切分成一个个单一字符图像。
3.3 字符识别
选取合适的字符特征是提高藏文字符识别准确性的重要因素。由于藏文字符特征相对简单,不同字符是根据形状来区分的,因此本文采用基于GIST全局特征的藏文字符识别方法。GIST特征是最好的全局特征之一,能快速描述文字在视觉维度上的结构信息,描述子相对简单[11],能很好地表征藏文的结构特征,是藏文字识别的有效途径。以Microsoft Himalaya藏文字库为识别参考依据。首先将Microsoft Himalaya字库中的字符渲染成图像,提取全局特征向量,建立标准藏文字库的全局特征向量库。2特征向量之间的相似度可以直接用欧氏距离计算得到。首先提取待识别字符全局特征,获得该字符的全局特征向量,然后分别与特征向量库中的特征向量计算欧氏距离,再根据相似度数值排序,返回相似度最大的特征向量对应的字符索引值,实现字符识别。如图6所示为雕刻字符识别过程。
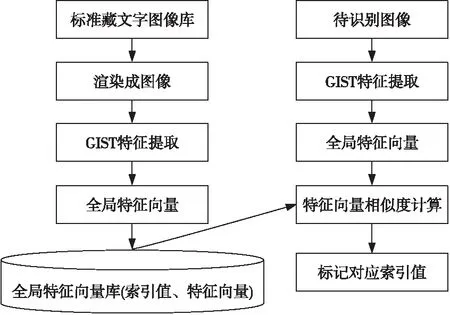
Figure 6 Carved character recognition process图6 雕刻字符识别过程
GIST算法通过多方向多尺度的Gabor滤波器组滤波后级联实现特征的提取[11,12]。
算法1GIST特征提取算法
输入:字符图像。
输出:字符图像的GIST特征向量。
步骤1字符图像归一化,尺寸为m×n。
步骤2将图像划分成a×b个相同大小的子区域,记a×b=S。每个区域按行标记为i(i=1,2,…,S)。每个区域的大小为r×c,其中r=m/a,c=n/b。
步骤3用Kn个通道的Gabor滤波器组分别对每个子区域进行卷积滤波处理,将处理后的特征组合得到该区域的GIST特征:
Gi(x,y)=cat(f(x,y)*gu v(x,y))
(1)
其中,cat为级联符号;f(x,y)为字符图像;*为卷积操作符;u和v分别表示滤波器组的尺度和方向;gu v(x,y)为滤波器组。
步骤4Gi的维数是Kn×r×c,对Gi的各个滤波通道结果求均值,然后按行进行组合,得到的向量就是全局GIST特征,即:
(2)
(3)
其中,G的维数为Kn×S。
本文在特征提取时将图像划分成3×3的网格区域,采用3个尺度8个方向的滤波通道,这样就得到3×8×9=216个维度的GIST特征向量。
根据GIST特征提取算法建立藏文标准字库的GIST特征库。GIST特征库存储标准藏文字库的所有藏文字符的索引值和特征向量。
同样采用GIST算法提取待识别字符图像的全局特征向量,然后分别与GIST特征库中的特征向量做欧氏距离计算,返回最大相似度特征向量的索引值完成识别。
3.4 字体分类
为了得到理塘版《大藏经》中不同风格的雕刻字体,需要对字符进行字体分类。不同风格字体的同一字符尽管全局特征区别不大,但是每种字体都有其独特的笔画和线条特征,因此本文采用Lowe[14]提出的尺度不变特征变换SIFT(Scale Invariant Feature Transform)的局部特征提取算法,通过将高斯差分层找到的极值点作为特征点来提取尺度、亮度和旋转不变量[15]。该算法是局部特征提取最好的算法之一,有很好的鲁棒性和稳定性[16]。通常通过独有的特征点(比如端点、折点、交叉点等)来表征不同字体的特征。最重要的是特征点的选择,选择区别性高,且具有较高重复性的特征点,便于特征点的匹配与区分。本文采用SIFT特征算法通过提取待分类字体的边缘和角点的特征信息来划分不同的风格字体。
算法2SIFT局部特征提取算法
输入:图像I(x,y)。
输出:图像I(x,y)的SIFT特征向量。
步骤1构造尺度空间,获取候选极值点。构造尺度空间是为了获取在不同尺度下都存在的极值点,通过不同尺度空间因子σ下的高斯函数G(xi,yi,σ)和原图像I(x,y)的卷积来构造不同的尺度空间L(x,y,σ),用运算速度更快的差分高斯函数DoG(Difference of Gaussina)来检测极值点;尺度空间表示如式(4)所示:
L(x,y,σ)=G(x,y,σ)*I(x,y)
(4)
其中,G(x,y,σ)为尺度可变高斯函数,如式(5)所示:
(5)
步骤2筛选稳定极值点。步骤1检测到的极值点是离散空间中的极值点,通过一个拟合精细模型来确定候选极值点的精确位置和尺度,关键点的选取依据它们的稳定程度。通过尺度空间DoG函数进行曲线拟合寻找极值点,剔除不稳定的边缘响应点以及低对比度的点,得到稳定极值点。
步骤3特征方向赋值。基于图像局部的梯度方向,分配给每个关键点位置一个或多个方向,后续的所有操作都是对于关键点的方向、尺度和位置进行变换,从而保证这些特征的不变性。
步骤4特征点描述。在每个特征点周围的邻域内,在选定的尺度上测量图像的局部梯度,这些梯度被变换成一种表示,这种表示允许比较大的局部形状的变形和光照变换。
获取到SIFT特征向量之后,通过计算2个待分类字体图像中对应关键点的距离判定相似度,判定是否为同一种字体。N维空间中2点的相似度量,用欧氏距离来计算:
(6)
其中,X、Y分别为待比较的2个特征向量,xi和yi分别为X和Y向量的第i个分量。
建立SIFT特征库,存储图像的索引号、特征点的数量以及特征点对应的特征向量。采用关键点特征向量的欧氏距离判定2幅图像中关键点的相似性。根据SIFT特征算法将藏文字根据字体风格的差异分为不同藏文的字体。
4 计算机字体多样性表达
理塘版《大藏经》是在不同的时间阶段由不同的雕刻大师共同制作完成的,因此经文字体风格呈现多样性和离散性的特色。理塘版《大藏经》内容量大,显然根据本文提取的理塘版《大藏经》的多种雕刻字体风格,通过手动切换这些字体来实现多样性是不现实的。那么计算机能不能自动切换字体来实现字体的多样性表达呢?基于此,本文提出字体多样性表达算法。
字体多样性表达算法旨在通过计算机自动调用不同风格的字体,将风格统一的字体替换成为风格迥异的雕刻字体。为了确保原输入文档的正确性,实验采用标准电子版《大藏经》。数字化理塘版《大藏经》其实就是将电子版《大藏经》统一的标准字体替换成风格多样的雕刻字体的过程。
本文将从理塘版《大藏经》中获取到的不同风格的字体存储到离散字体库,字体库中存储的信息为字体名(font)和索引值(index)。统计发现理塘版《大藏经》不同风格的雕刻字体呈离散分布状态,因此在字体替换过程中采用随机均匀模型来拟合多种风格字体的替换过程。
算法3字体多样性表达算法
输入:电子版《大藏经》,离散字体库。
输出:数字化理塘版《大藏经》。
Step1遍历电子版《大藏经》,找到第1个标准字体控制的字符character,定位该字符出现的位置P,统计该字符出现的次数Count;
Step2通过离散均匀随机函数产生的随机变量x,调用离散字体库中索引值为x的字体font(x);
Step3根据替换函数将P位置的标准字体替换成字体font(x);
Step4定位字符character出现的下一个位置;
Step5循环Step 2~Step 4,直到所有字符的标准字体替换成不同风格的雕刻字体;
Step6循环以上步骤,直到《大藏经》中所有的标准字体全部替换成离散字体库中的雕刻字体。
根据字体多样性表达算法,处理完整篇《大藏经》经文,得到具有多样性和离散性雕刻字体的数字化理塘版《大藏经》。
5 实验结果及分析
采用本文方法得到的实验结果如图1所示,其中,图7a为理塘版《大藏经》原图;图7b是电子版《大藏经》的经文片段;图7c是采用本文方法得到的实验结果图,该实验结果已经具备了理塘版《大藏经》中雕刻字体多样性的特色,并且实现了编辑、共享等计算机信息处理的基本功能。
对比图7b和图7c可知,相比统一单调的字体,具有多样性字体的古籍更具有美感;对比图7a所示的理塘版《大藏经》和图7c所示的数字化《大藏经》字体发现,图7c的经文版面显示效果已经明显接近原始的版面字体多样性表达的效果,精准的相似度测试还需要后续设计更加严格的校对方案,采用更加精确的技术来实现。
根据数字化理塘版《大藏经》中雕刻字体的实验结果,统计每一种雕刻字体出现的频度,具体数据如表1所示。
由表1可知,测试文本中10种字体出现的频度拟合随机均匀模型,与文本预期的结果基本符合,将标准字体随机均匀地替换成了10种雕刻风格字体。

Figure 7 Comparison of experimental results图7 实验结果对比图
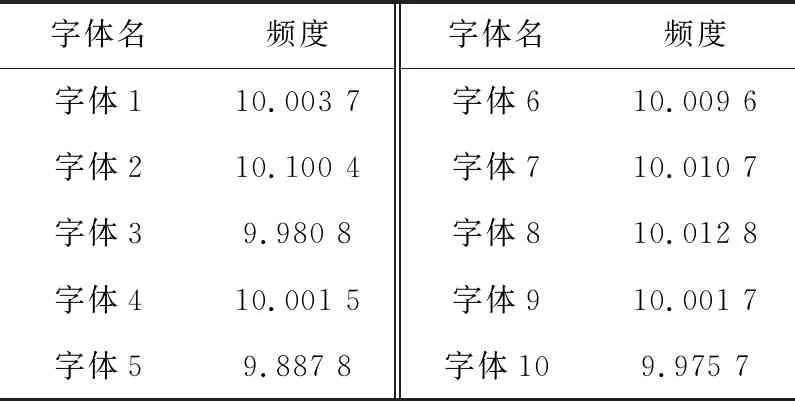
Table 1 Discrete font appearance frequency
本文研究对象不仅限于理塘版《大藏经》,对于任意藏文古籍都可以用上述过程实现古籍中字体的数字化,生成具有多样性和离散性字体的古籍。
6 结束语
本文以理塘版《大藏经》为研究典例,对实现具有多样性和离散性的雕刻字体的传统古籍的数字化的方法和技术进行了深入探索,实现了计算字体多样性表达,从而保留理塘版《大藏经》中多样性和离散性雕刻字体的美感和艺术效果。本文的研究为古籍的保护与传承提供了新方法,其中字体多样性表达算法为数字化古籍中具有离散性和多样性的字体提供了一个新的思路,为藏文字体文化的研究与探索提供了便利,具有一定的研究价值。
