k均值聚类法在识别低弱地球化学异常中的应用:以内蒙古阿木牛林场地区为例
2020-11-25周吉晨李随民张诗敏
周吉晨,李随民,张诗敏,焦 建
河北地质大学,河北 石家庄 050031
0 前言
数据处理与解释是勘查地球化学工作的重要环节,在化探数据的处理中,背景值及异常下限的确定对地球化学异常的圈定与解释具有重要的意义。土壤是在已风化基岩之上岩石(矿石)风化作用的残留疏松物[1],对原岩具有继承性,土壤数据会因受到原岩的影响而出现异常,若不能准确确定背景值,就无法客观的反映地质信息。许多学者对消除背景值的影响进行了研究,提出了多种解决方法[2-7],这些方法对于强异常的发现和提取有较好的效果,但对低弱异常的识别效果不佳。目前针对低弱异常识别的方法有:子区中位数衬值滤波法[8]、趋势面法[9-10]、等。低弱异常的识别对找矿具有重要的意义。
论文利用内蒙古阿木牛林场地区1∶5万化探数据,通过k均值聚类方法实现对研究区样品的分类,每一类可视为一个单独的个体。然后对每个子类中的数据进行标准化和分析,从而达到突出低弱地球化学异常的目的,为进一步找矿提供参考。
1 研究区地质概况
调查区位于大兴安岭北段东坡,大兴安岭主脊在西北部通过。地势西高东低,山脉走向以近南北向、北西向、北东向为主,总体构造线方向为北东向、北东东向,其中北东向构造控制着地层和侵入岩的展布方向,次之为北西向构造,褶皱构造不太发育。地层自下而上划分为古生界下奥陶系铜山组、侏罗系满克头鄂博组、玛尼吐组、白音高老组,第四系全新统沼泽堆积物和冲洪积物等。其中侏罗系分布最广,奥陶系少量分布,第四系沿沟谷、河床分布。古生界下奥陶系铜山组的岩石组合以变质砂岩、变泥质粉砂岩、变细砂岩、变砂质泥岩为主,中间夹有变中酸性火山熔岩和大理岩。满克头鄂博组为一套酸性火山熔岩、火山碎屑岩喷发沉积组合,多数直接喷发不整合覆盖与古生界地层和中侏罗世侵入岩之上。玛尼吐组是以中性火山岩—火山碎屑岩喷发沉积为主的一套地层,岩石组合以安山岩、安山质含角砾熔结凝灰岩、英安岩、多斑角闪安山岩为主,局部以安山岩与火山碎屑岩互层出现。白音高老组地层是一套偏碱性酸性火山岩—火山碎屑岩夹少量中酸性火山岩等特征的岩石组合,其岩石组合颜色整体偏浅,多呈现灰白色,为灰白色流纹岩与灰白色流纹质凝灰岩互层产出为特征。区内侵入岩十分发育,主要有中三叠纪二长花岗岩,中侏罗世二长花岗岩,早白垩纪二长花岗岩、花岗斑岩、石英二长斑岩、石英正长岩等,其中中侏罗世二长花岗岩在研究区发育大面积出露,主要分布在研究区中部和东部(图1)。
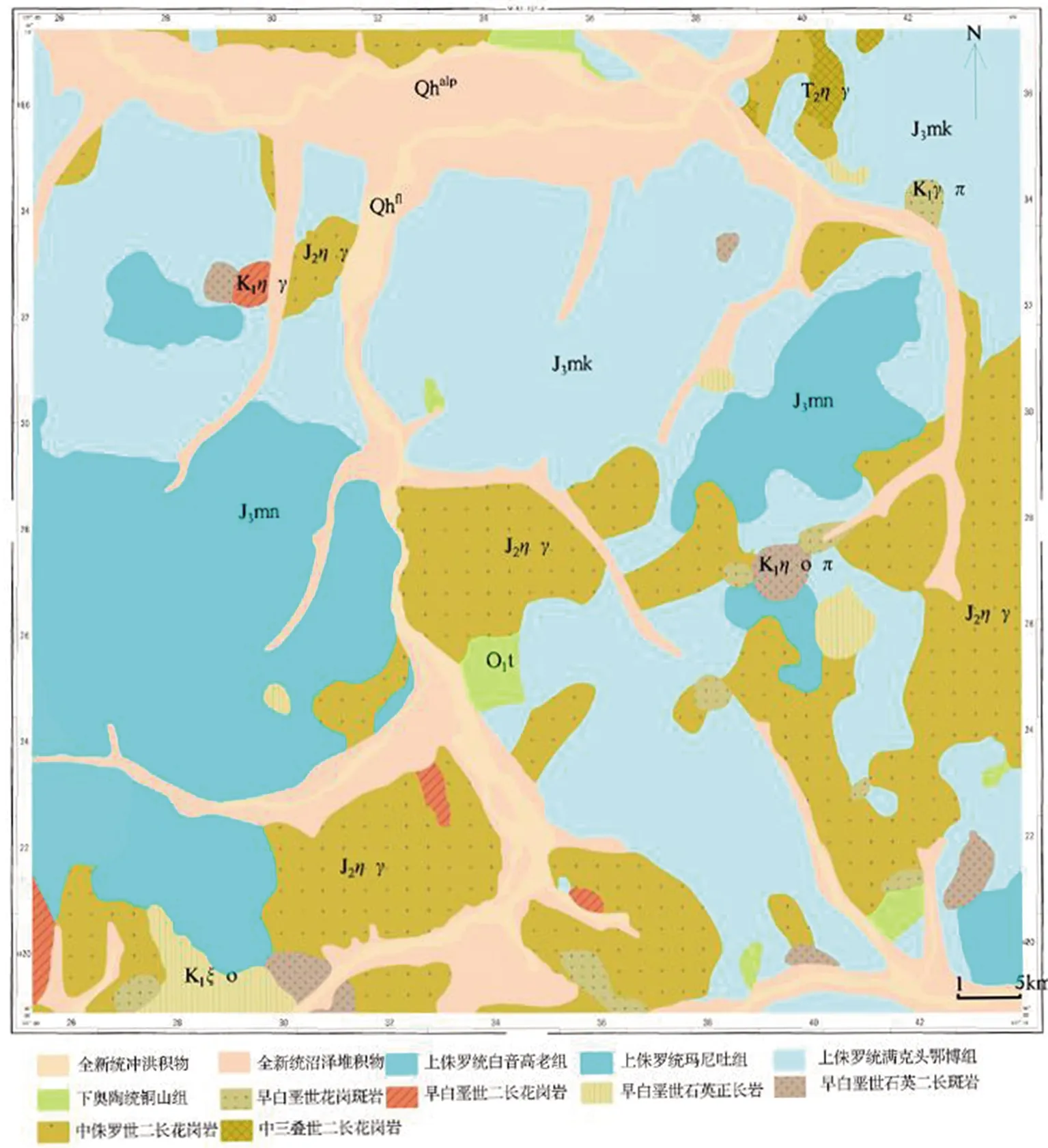
图1 研究区地质概略
2 基本原理及方法
聚类是数据挖掘的一种重要的手段,k均值聚类算法是一种得到最广泛使用的基于划分的聚类算法,该算法简单、快速,对处理大数据集,该算法是相对可伸缩和高效的[11]。论文利用该方法对数据进行分类,然后进行正态转换,对异常样品进行剔除,将剩余数据进行标准化。该方法可形成一个突出低弱地球化学异常的标准化数据集,作为进一步计算和编图的基础数据。
2.1 k均值聚类算法的基本思想
在整个数据集中,随机选择k个数据,每个数据作为一个簇的中心,然后计算其它数据与这个中心的距离,跟据距离将这些数据划分到最近的簇。所有数据划分好后,再计算每个簇的平均值,并以该平均值为中心重新聚类,以此往复,直至满足收敛函数的要求,即:
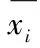
2.2 K均值聚类方法描述
输入:n个数据对象,数量为k
输出:k个满足收敛函数的簇
(1)从n个对象中任意选择k个对象,每个对象作为初始聚类中心;
(2)计算每个对象与聚类中心的距离,根据距离把每个数据划分到距离最近的簇;
(3)重新计算每个簇中的平均值,重新选定聚类中心;
(4)计算收敛函数,满足收敛条件则结束,否则回到第(2)步。
3 内蒙古阿木牛林场地区低弱地球化学异常的识别
本次土壤测量采样密度为8.90点/km2,采集样品2 518个,所有样品均采集为基岩风化产物中的残积层或岩屑,且为多点采集,组合成为一个样品。采样时避开了各种污染、废石堆和河床堆积物,不能取样时弃点在记录中进行了注明;采样后留有明显标志。土壤测量以-4~+20目为采样粒级。通过对数据的预处理,剔除特异值后,本次分类的有效数据为1 675个。
3.1 分类数的确定
分类主要依据来源为内蒙古阿木牛林场地区地质单元的数目和k均值聚类法的轮廓系数。
最优分类数k的选取对于k均值聚类方法至关重要,最优分类数可以通过轮廓系数确定[12]。轮廓系数的下公式计算如下[13]:
其中,Si代表第i个变量的轮廓系数;ai代表一个簇中第i个变量到其它所有变量的平均距离;bi代表到其它所有变量的最小距离。通过给定的初始分类数可以计算出相应的平均轮廓系数,轮廓系数的值在-1至1之间,值越大则代表聚类效果越好。同时选取的类数不应过小。
根据内蒙古阿木牛林场地区的地质单元数目和K均值聚类的轮廓系数,该地区可分为5大类。(图2)

图2 研究区分类图
3.2 分类标准化
首先检测每个子类内元素是否符合正态分布,对于近似正态分布的数据,采用3S法剔除异常值,直至符合正态分布。剔除异常值后,通过检测,近似正态分布的元素按照以下公式进行均值和标准差的运算,即:
呈近似对数正态分布的元素按照以下公式进行均值和标准差的运算,即:
其中,μ为数据的自然对数值;σ为数据的自然对数标准离差。
根据各类数据的均值和标准差,计算异常下限值和衬度值,然后将所有子类数据合并为一个数据集。
内蒙古阿木牛林场地区1:5万化探数据可分为5类,论文选取研究区潜在成矿元素Pb、Zn元素与传统方法圈定的异常进行对比。首先,对每类数据正态化后进行3S检验,将异常值剔除,然后计算标准差、方差和异常下限值,如表1、表2所示:
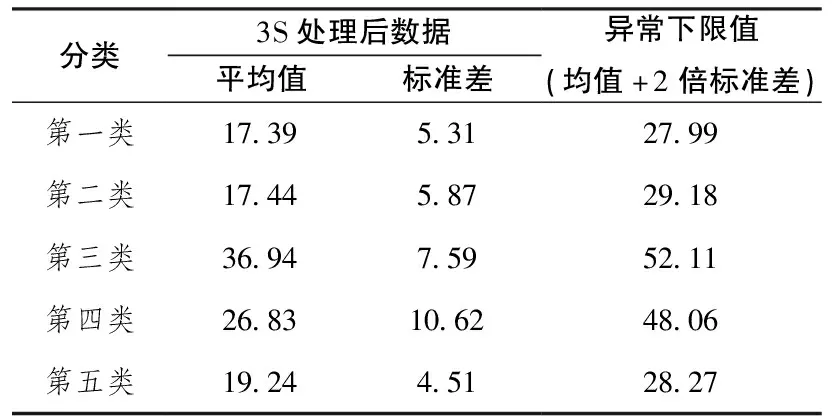
表1 k均值聚类法Pb元素异常下限值
根据各类的异常下限值,利用Excel表分别计算5类中Pb、Zn元素的衬度值,即Pb、Zn元素与该元素异常下限的比值。将得到的衬度值合成为一个数据集,并用surfer软件制作等值线图。
3.3 分类数据与原始数据进行对比
将未分类原始数据中的Pb、Zn元素进行特异值剔除,使其符合或近似符合正态分布,然后采用平均值加2倍标准差的方法确定Pb、Zn元素的异常下限值,作为传统方法圈定元素异常的依据(表3)。
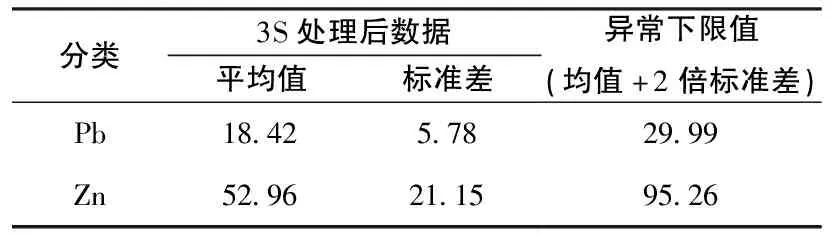
表3 传统方法Pb、Zn元素异常下限值
从传统方法和k均值分类法(图3、图4)圈定的异常可以看出,Pb、Zn元素的分布受到了岩性地层分布的控制,大部分异常区与中侏罗世花岗岩相对应。若研究区内岩性变化较大,按统一的异常下限确定元素异常可能仅是对岩性的反映,不能真实反映异常情况。因此,传统方法圈定异常并不是适用地质条件较复杂的地区。而k均值聚类法不仅使原有的北北西方向的Pb异常得到了加强,而且显示出Pb、Zn的低弱异常(实线圈定区)。若使用传统方法,这些异常往往被忽略。
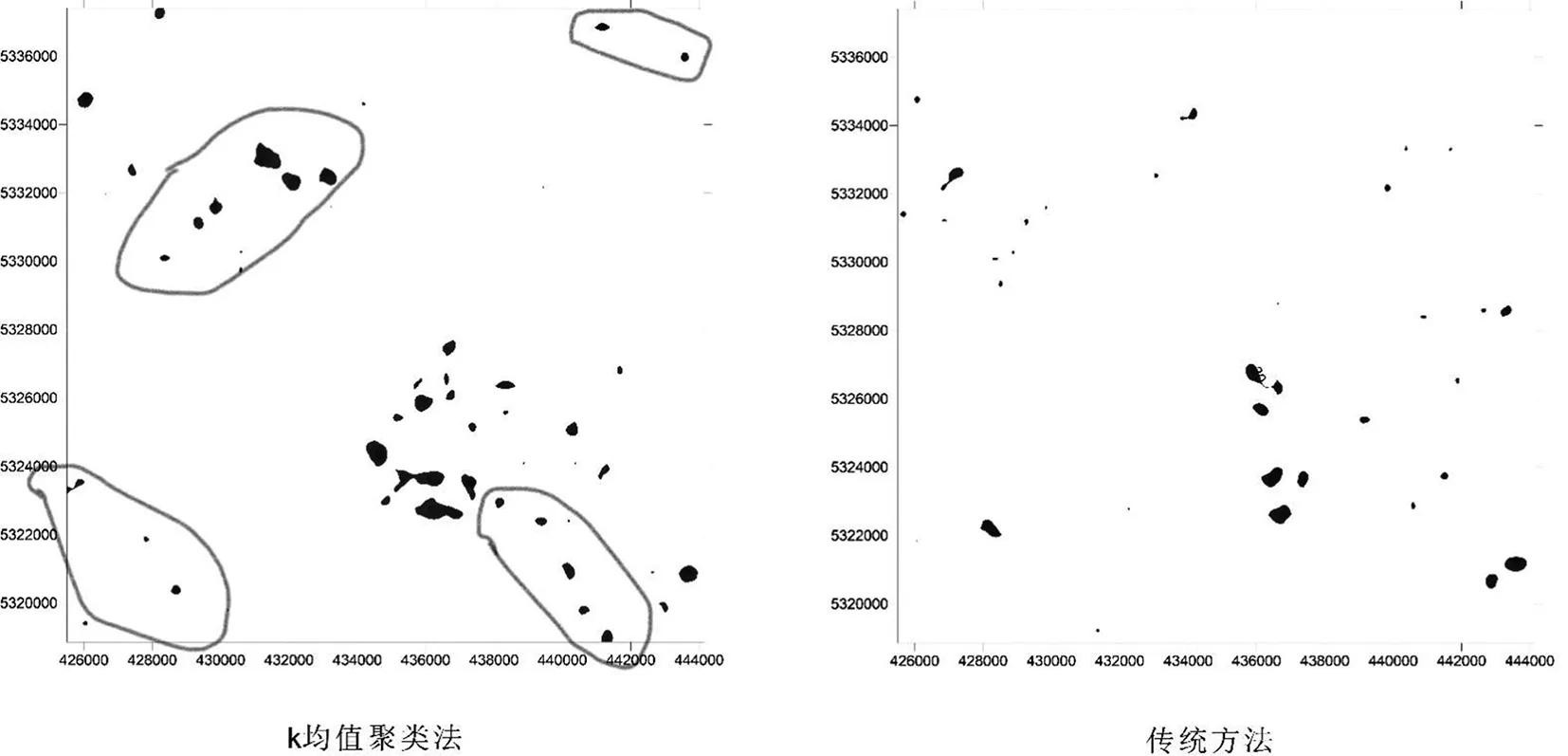
图3 Pb元素异常圈定对比图
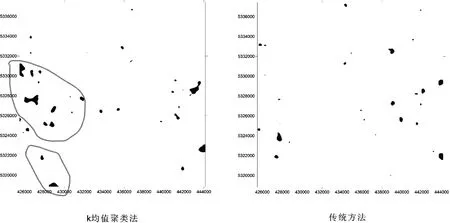
图4 Zn元素异常圈定对比图
4 结束语
论文利用k均值聚类法对研究区元素进行分类,并对每个子类的数据进行标准化,计算其均值、方差和衬度值。以Pb、Zn元素为例,在与传统方法圈定地球化学异常的对比中发现,分类处理可以有效的强化原有异常,识别低弱地球化学异常。与传统方法(全地区统一异常下限值)圈定异常不同的是,分类方法和传统方法圈定异常的区域有所差异,分类方法可以消除岩性对异常的影响,显示出一些低弱异常的区域,而传统方法圈定的异常可能因岩性的影响而出现偏差。
