基于故障相关慢特征分析的过程监测方法
2020-11-24陈先中
黄 健,杨 旭,陈先中
(工业过程知识自动化教育部重点实验室,北京科技大学 自动化学院,北京100083)
1 引 言
现代流程工业过程规模日益扩大,过程监测是保证过程生产安全、产品质量的关键。集散控制系统和计算机技术的蓬勃发展,推动了基于多元统计过程监测方法的发展[1-6]。传统多元统计方法假设过程采样之间是时序独立的,多元统计算法在特征提取时只能提取过程的稳态特征。在现代工业过程中,变量之间、操作单元之间有实际意义的耦合关系,因此过程数据会表现出时间上的动态性。动态主成分分析(principal component analysis,PCA)、动态独立成分分析等算法通过扩展矩阵方法来处理过程动态性问题[7-11]。近年来,慢特征分析(slow feature analysis,SFA)算法被引入过程监测领域[12],SFA算法根据特征的变化提取动态特征,适用于动态过程监测。Guo等[13]提出概率SFA算法;Shang等[14]明确指出动态性是表征过程变化的重要指标;Zhang等[15]将核SFA 算法用于非线性间歇过程;张汉元等[16]结合核慢特征判别分析和支持向量数据描述算法,改善过程的非线性特性。上述改进的SFA故障检测算法在特征选择与观测统计量构造方面,通过离线挑选部分重要特征构造统计量,没有充分利用在线监测数据的故障信息,可能造成故障信息无法有效表达。Ge 等[17]提出从全局监测性能出发的基于故障样本的独立元监测方法。Jiang 等[18]提出基于在线挑选敏感主成分的敏感PCA 算法。Huang 等[12]提出基于慢特征分析的在线特征重排和特征提取监测策略。这些算法是基于在线特征选择策略的过程监测算法,然而此类在线策略的研究仍不完善,在处理过程动态性方面以及特征选择的鲁棒性方面仍需要改进。因此,如何采用在线特征提取策略进行动态特征选择,加强故障信息在监测模型的表达,提高监测模型的监测效果值得深入研究。为解决这一问题,本文提出基于选择在线故障相关特征的SFA 故障检测算法,经过SFA特征提取,在线选择超过阈值的特征为故障相关特征,并构造监测统计量进行故障检测。
2 慢特征分析(SFA)

3 基于选择故障相关特征的SFA故障检测方法
SFA 可以提取过程中不同动态水平的特征,根据特征变化的缓慢程度排列。在实际动态工业过程中,故障可能发生在任何的动态特征中,因此经过SFA 进行动态特征提取,下一步需要选择重要特征对数据降维。由于SFA 是一种线性特征提取方法,通常认为权重矩阵W中具有较大L2范数的行对应的慢特征能够捕捉到过程的变化。对于第i个慢特征,其权重向量的L2范数li表示为

式中:ijW为权重矩阵W的(ith,jth)个元素。将慢特征按照li从大到小排序,选择权重向量前k个慢特征为离线重要特征,表示为

基于权重矩阵L2范数的特征选择策略是一种离线特征选择策略,离线方法只能预先选定若干个特征。而实际过程中,不同的故障可能表征在不同的特征中,离线方法没有利用到实时的故障信息,选中的特征可能不全是故障相关特征,造成信息冗余,监测模型的有效性低。因此,应充分利用在线监测样本信息,选择故障相关特征对数据降维,构造监测统计量。
3.1 选择故障相关特征策略

3.2 监测统计量计算
记d个故障相关慢特征为d s,构造基于故障相关特征统计量为

在正常数据提取的慢特征中挑选出当前样本的故障相关特征,由KDE 估计出当前监测样本的控制限。若所有在线慢特征统计量都没有超过平均阈值,则此选择故障相关慢特征分析(fault-related SFA,FRSFA)算法退化为SFA 算法,采用离线特征选择策略进行降维。
传统方法在建立监测统计量时,通常分别构造特征空间和残差空间两个统计量,特征空间和残差空间的统计量互为补充。本文提出在线选择故障相关特征的降维策略,经过特征选择,故障信息被集中在慢特征空间,残差空间几乎不包含故障信息,本文只建立慢特征空间的2S统计量。
3.3 故障检测流程
基于选择故障相关特征的SFA 故障检测算法的详细步骤如下。
离线建模:
第1步:收集正常工况下的数据,并对数据进行0均值和单位方差标准化;
第2步:采用SFA 算法提取过程数据的动态特征,并获取权重矩阵W;
第3步:根据权重向量的L2范数选择部分重要的慢特征;
第4步:根据选择的慢特征构造监测统计量,并采用KDE 算法估计统计量的阈值。
在线监测:
第1步:确定滑动窗口宽度h,获取当前窗口内的监测样本,并根据离线建模第1步对监测样本进行标准化;
第2步:根据离线建模第2 步的权重矩阵,计算监测样本的慢特征统计量s2test,并在窗口内求平均值;
第3步:对比每个慢特征统计量和离线建模第4步得到的平均阈值,挑选出超过平均阈值的慢特征为故障相关特征;
第4步:建立故障相关特征统计量;
第5步:返回离线建模第4步,根据当前挑选的慢特征建立正常数据的统计量,并估计过程的控制限;
第6步:对比监测统计量和控制限,判断当前监测样本是否为故障。
4 Tennessee Eastman(TE)过程仿真实验
TE 过程对于研究过程监测方法提供了很大帮助,已经被学术界广泛认可[22-23]。TE 过程有4 个反应,共生成2 种有效产物。这个过程有5个主要的单元操作:反应器、冷凝器、分离器、循环压缩机和气提塔。本文中的研究选取22 个连续测量变量和11个操纵变量用于故障检测,TE 过程仿真模型预设定21个故障。过程正常数据包含500 个样本。对于每个故障,故障数据包含960个样本,其中前160个样本是正常数据,161至960个样本为故障数据。
本文对比PCA、SFA、FRSFA 3种算法的监测效果,选取滑动窗口h= 10,置信水平α= 0.99。根据TE 过程的离线数据,经过计算离线重要特征的数量k=21。表1给出了21个故障的故障检测率。
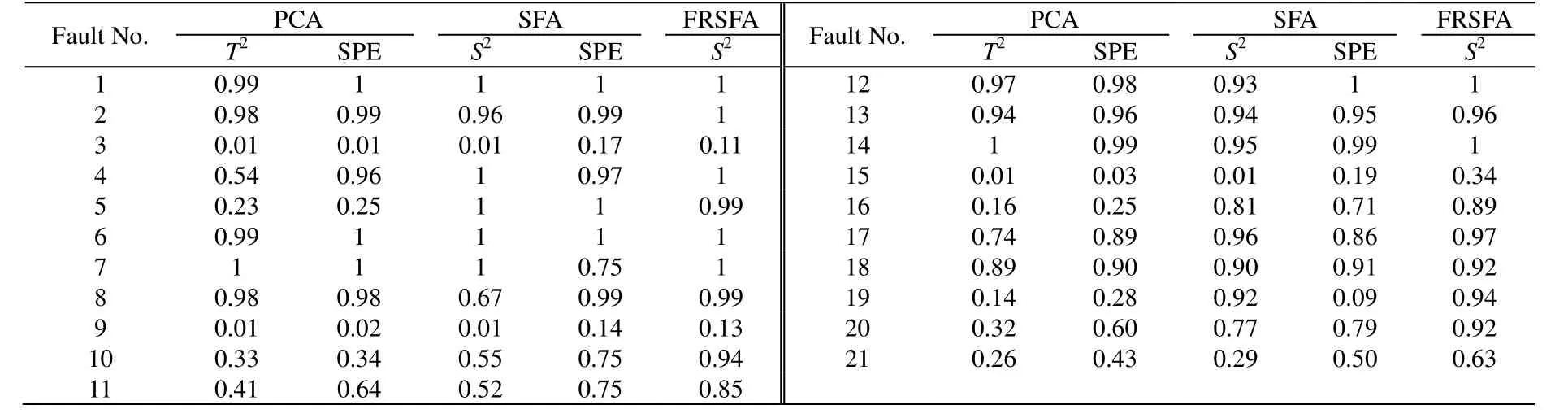
表1 PCA、SFA、FRSFA 故障检测率Table 1 Fault detection ratesof PCA,SFA and FRSFA
对于故障1、2、4、6、7、8及14这类故障幅值较大的故障,3种方法几乎都能达到100%故障检测率。对于故障5、12、13、17、18及19,FRSFA 的故障检测率能够与其它2种算法中最好的监测效果持平。提出的FRSFA 算法在检测故障10、11、15、16、20 及21时比其它2种算法有明显优势。故障3、9及15是公认的几乎无法检测的故障,3种算法都不能检测出故障3和9,本文提出的FRSFA 算法对故障15的检测率达到了0.34,显著高于其他2种算法。本文提出的FRSFA 算法充分提取过程的动态特征,根据在线样本选择故障相关信息,排除故障无关特征对监测结果的影响,相比于PCA 和SFA 算法,监测模型的有效性提高。为了进一步说明提出算法在选择故障相关特征方面的优势,以故障11为例,图1、2分别给出了根据L2范数排序的、根据在线特征大小排序的所有特征图。
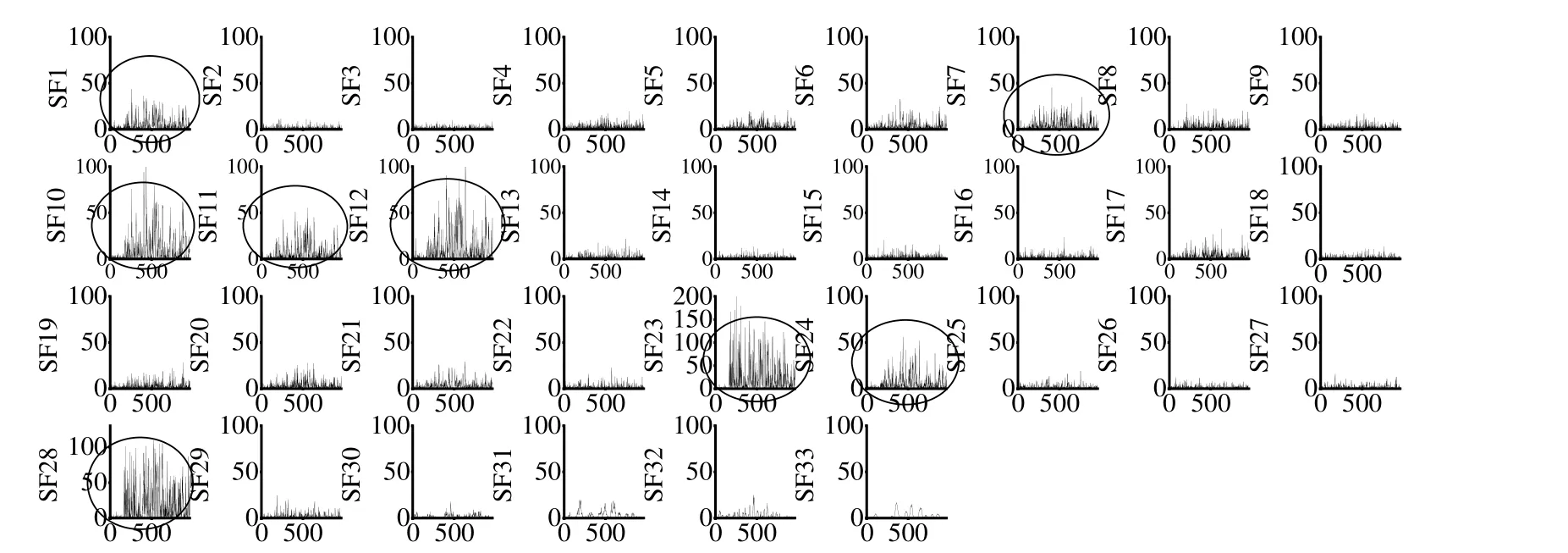
图1 根据权重向量L 2 范数排序的所有慢特征Fig.1 All SFsin the order of L2 norm of the weight vector
图1是将特征按照权重向量的L2范数排序的所有慢特征图,具有显著故障信息的特征(特征10、12、23、28)和较多故障信息的特征(特征1、7、11、24)在图中用圈标出,由于TE 过程离线特征个数k=21,仍然有3个表征故障信息的特征没有被挑选,导致特征空间的重要信息不足。因此,此特征选择方式有局限性,会导致监测效果不佳。图2 是根据在线特征的大小进行排序的慢特征图。可以看出,无论是显著表征故障的特征(特征1、2、3、4)还是较为显著表征故障的特征(特征6、7、9、10)都排在前位,进行特征选择时,这些特征超过了平均阈值,被挑选到特征空间,充分利用了过程的故障信息,提高了模型的有效性。
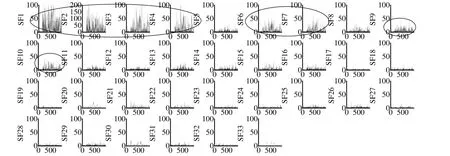
图2 根据在线特征大小排序的所有慢特征Fig.2 All SFsin the order of their values
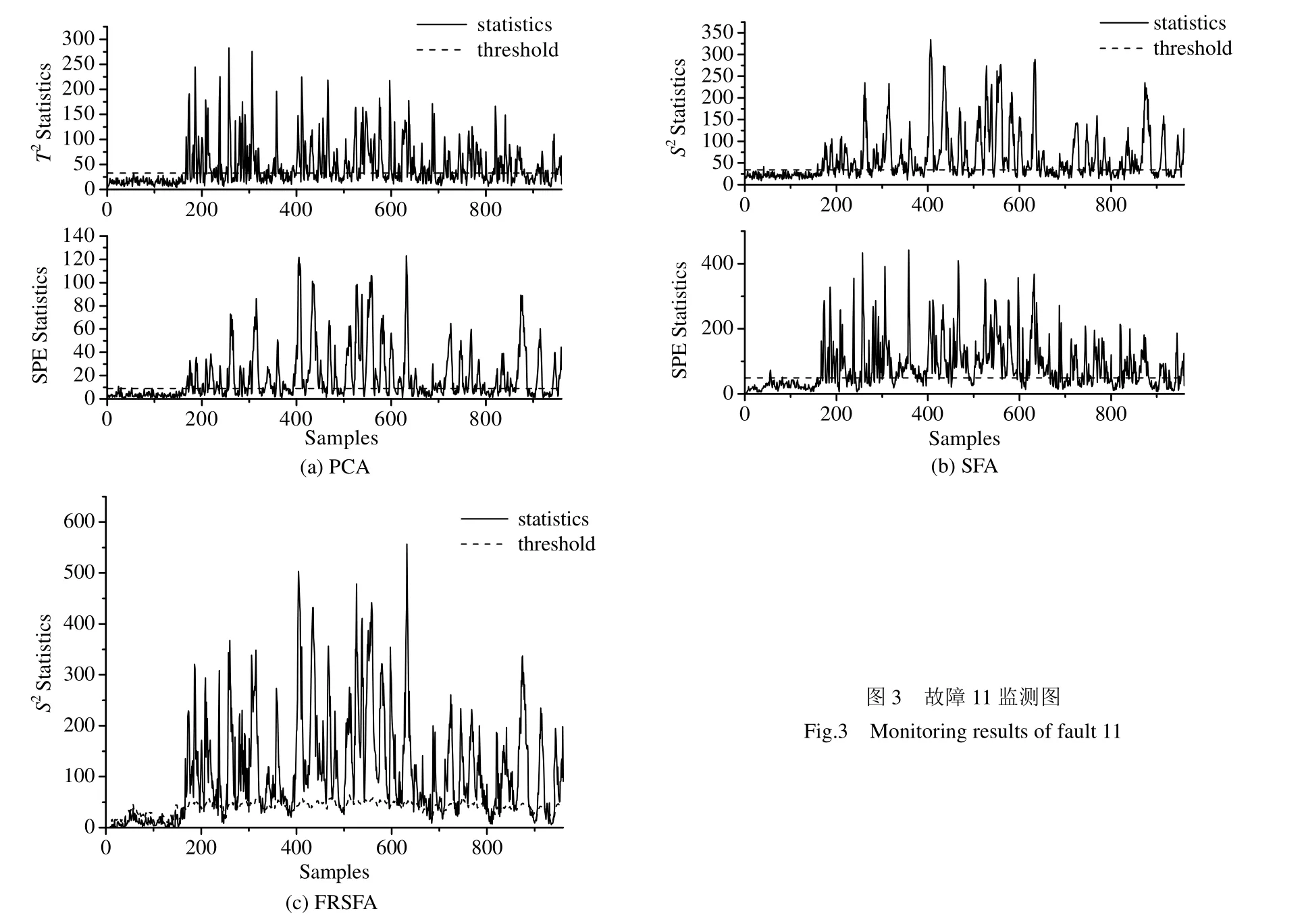
故障11是反应器冷却水进口温度的随机变化,图3(a)~(c)分别给出了PCA、SFA 和FRSFA 的监测效果。PCA 算法的2T统计量的监测效果比SPE统计量差,两个统计量的检测率分别为0.41和0.64,只能检测出其中一部分故障样本。SFA 的故障检测率也只有0.52 和0.75,相比于PCA,SFA 的效果有少量提高。本文的FRSFA 算法能够检测出大部分故障,故障检测率达到了0.85,显著改善了传统PCA 和SFA算法的监测效果。PCA 算法没有考虑到过程动态信息,且特征选择没有充分利用在线信息;SFA 算法虽然有效地提取了过程的动态特征,但是没有选择故障相关特征,造成监测模型冗余、有效性低。本文提出的算法在特征提取和特征选择方面充分考虑了动态过程的故障信息,集中故障相关特征监测,取得了优异的监测效果。
5 结 论
SFA 算法在进行降维时采用离线特征选择策略,没有充分利用在线样本的故障信息,导致特征空间信息冗余,监测模型的有效性降低。本文提出基于在线故障相关特征选择SFA 过程监测策略,首先计算出每个慢特征的阈值,将其作为挑选的基准;然后通过对比在线特征与阈值的大小,确定超过平均阈值的特征作为故障相关特征;最后采用核密度估计实时估计当前样本的控制限。采用SFA 算法提取过程的本质动态特征,克服了传统静态算法在动态过程监测方面的不足,提出的在线故障特征选择策略排除了故障无关特征对监测效果的影响,提高了监测模型的有效性。在TE过程进行仿真实验,相比于PCA 和SFA 算法,提出的FRSFA 算法监测性能更优。
SFA 算法能够提取出过程的动态特征,取得优异的监测效果。然而,本文研究的SFA 算法是一种线性特征提取算法,没有考虑到复杂工程的非线性特点,基于SFA 算法的改进算法还有很大的发展空间。同时,工业过程规模大、变量关系复杂,如何挖掘更多的工业过程信息,仍然值得研究。
