数据融合在护理机器人排便监测中的应用研究
2020-11-23刘晓军陶晋宜
刘晓军,陶晋宜,杨 刚,王 帅
(1.太原理工大学电气与动力工程学院,山西 太原 030024;2.西安电子科技大学电子工程学院,陕西 西安 710071)
1 引言
随着社会的进步和人民生活水平的提高,人们越来越关注人口老龄化这一热点问题。因人体年老和各项身体机能的衰退,全国丧失生活自理能力的人数在不断增加[1],将人工智能技术应用于养老产业,使得以护理机器人为核心的智能老龄护理成为解决失能老人护理的新手段,智能护理机器人以饮食护理、睡眠护理、排泄护理和助医服务等多种护理方式提供养老服务,其中排泄护理在解决传统护理引发的伦理问题上显得尤为重要。目前针对失能老人的传统排便护理模式已难以满足护理要求,护理人员在承担繁重的日常护理之外,还需承担巨大的心理压力,而且对于大小便失禁的老人,若没及时处理,常常会引发各种感染疾病。
现阶段我国的护理床结构简单,排便监测还是采用单一参数的传感器,获得的特征信号具有一定的局限性,容易引发误报或者漏报的问题。文献[2]设计了一种大小便自动感应及处理装置,其信号处理模块简单,并不能充分利用传感器信息来实时监测排便。针对以上问题,提出了BP 网络与改进的D-S 证据理论相结合的数据融合算法,通过仿真建模对实验结果进行分析,验证改进算法的可行性,从而将其运用到护理机器人上,提高排便监测的准确性和实时性。
2 多传感器数据融合结构模型
多传感器数据融合[3]可以从不同角度反应事物的各个方面,实现信息的互补。神经网络[4]作为数据融合的一种方法,通过建立输入与输出的映射关系,运用传感器信息和系统决策进行指导性学习,确定权值分配,完成网络的训练,最后将实测数据与信息进行模式匹配比较,得到准确判决。
考虑到每个传感器对排便的敏感程度不同及其性能差别的影响,可能对神经网络输出结果有很大的影响,增加D-S 证据理论[5-7]的决策级融合,又因经典的D-S 证据理论[8]无法处理高度冲突的证据体,所以引入矛盾系数改进证据理论,将BP 网络结合改进的D-S 证据理论数据融合算法应用于护理机器人排便监测系统中,它的具体算法原理,如图1 所示。

图1 数据融合结构模型图Fig.1 Data Fusion Structure Model
3 BP 网络
BP 网络是一种模拟人脑信息的非线性信息处理系统,具有很好的鲁棒性。特征级融合是对预处理后的参数信息进行分析处理,并将融合结果送到决策级进行全局决策。因此该层既要特征提取,又要局部决策,故特征级融合采用BP 网络,通过不断调整权值使实际输出与期望输出的总均方差最小。
3.1 数据预处理
经医院实地调研获取的各参数信息数量级相差比较大,为消除不同量纲对结果的影响,在BP 网络训练之前需对样本数据进行归一化处理,使数据处在[0,1]区间:
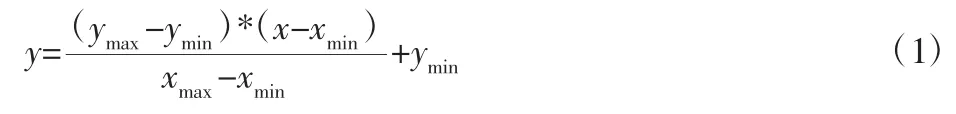
式中:ymin、ymax—归一化的区间,即 ymin=0、ymax=1,xmin、xmax—输入样本的最小值和最大值。
3.2 BP 网络初始化
BP 网络的构建需根据输入输出决定,而一个3 层的BP 网络可以实现对任意非线性函数的逼近,因此建立3 层的BP 网络来实现n 维到m 维的映射:

式中:X=[x1,x2,…,xn];xi—输入层第 i 个节点的输入值;Y=[y1,y2,…,ym];yi—输出层第 i 个节点的输出值。
隐含层节点数直接影响BP 网络的非线性性能,节点数过少会导致网络的容错性降低,节点数过多可能导致不收敛。通常情况,隐含层的节点数根据经验公式确定:

式中:p—隐含层节点数;n—输入层节点数;m—输出层节点数;a—[1,10]之间的常数。
4 D-S 证据理论
4.1 基本概念
对于识别框架Θ,如果函数m:2Θ→[0,1]满足下列条件:

式中:m(A)—A 的基本概率赋值,表示对A 的信任程度。
假设在同一识别框架 Θ 下,m1、m2、…、mn是 n 个独立证据源的基本信度分配函数,焦元分别为Ai(i=1,2,…,N),那么多个证据源的组合规则为:

式中:K—冲突因子,表示各证据之间的冲突程度。
4.2 改进的D-S 证据理论
D-S 证据理论在面对高度冲突证据时会产生有悖于常理的问题,得到与实际情况完全偏离的结果,针对此问题,许多学者提出了改进方法,文献[9]默认证据之间的权重相等,并没有考虑到证据的重要性问题。文献[10]根据3-D 冲突信息的结构特点和各焦元被各证据所支持的度量进行直接融合,计算比较复杂。针对排便监测的复杂性,引入矛盾系数改变各个证据的权重,使高度冲突的证据所占的权重较小,从而减小对融合结果的影响。
有识别框架Θ,命题A 的基本信度分配函数有m1(Ak),m2(Ak),则这两条证据的冲突系数如下:
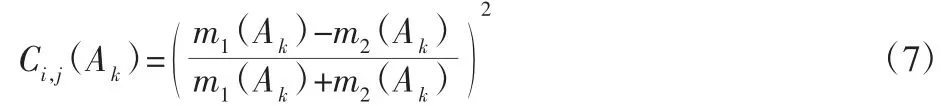
Ci,j(Ak)越小,两个证据存在的冲突越小,若命题Ak的基本信度分配m1(Ak)和m2(Ak)完全相等,则证据之间不存在冲突,若m1(Ak)和m2(Ak)不相等,Ci,j(Ak)值表示两证据间的冲突程度。
对于识别框架中的任意一个命题Ak,当有n 条证据时,命题A 矛盾矩阵定义如下:

式中:矛盾矩阵反映了命题中不同证据之间的冲突程度。
每条证据的相互矛盾系数如下:

式中:Vi(Ak)—在对命题A 合成时基本信度分配所占的比重;n—证据体的个数;每条证据与其他证据存在高度冲突时相互矛盾系数Gi(Ak)的值为n;Gi(Ak)/n—证据的不可信程度。综合式(5)和式(10),改进的D-S 证据理论组合规则如下:


式中:Vi(Ai)—命题A 对应证据的权重。与式(5)相比,上式通过增加矛盾系数改变各个证据的权值,进而应用权值信息改变组合规则以提高证据理论对各证据之间冲突的处理能力。
4.3 D-S 证据理论数据融合决策
将BP 网络输出结果归一化处理,并将其转化为D-S 证据理论的基本信度分配,具体公式如下:

式中:En—输出层所有神经元的误差和,作为D-S 证据理论的不确定因素m(θ);y(Ai)—BP 网络的输出结果;dni、yni—第i 个神经元的期望输出值和实际输出值。
采用以下准则进行目标识别结果的判决:
(1)最终的识别结果应具有最大的基本信度分配。
(2)最终的识别结果与其他结果的基本信度分配值之差要大于设定的阈值ε1。
(3)不确定基本信度分配m(θ)小于设定的阈值ε2。
(4)最终的识别结果基本信度分配值要大于不确定基本信度分配 m(θ)。
5 实例分析
通过调研得到不同时间段的样本数据,剔除样本中特征重复高的数据,最终选取330 组作实例分析,数据分为三组,分别用t1、t2、t3表示,每组参数下 110 组数据,其中 90 组数据作为训练样本,20 组数据作为测试样本。
5.1 基于BP 网络的特征级监测
将湿度、温度及氨气参数信息预处理后作为BP 网络的特征输入,分别用 X1、X2、X3表示。设理想输出[1,0,0]表示有大便排泄、[0,1,0]表示有小便排泄、[0,0,1]表示无排泄,分别用 A1、A2、A3表示输出状态,通过多次训练不断调整网络权值,3 个BP 网络的隐含层节点数依次设为7、6、7。综上,特征级融合3 个组对应的 BP 网络结构分别为 3×7×3、3×6×3、3×7×3,隐含层和输出层的传递函数分别为tansig()和purelin(),训练算法采用梯度下降动量和自适应lr 的BP 算法训练函数traingdx。训练的最大迭代步数设为5000 步,学习率为0.01,目标误差为0.005。
将三组共270 组数据构成的特征向量作为训练样本,利用MATLAB 平台构建网络结构分别对3 个BP 网络进行训练,训练过程误差曲线,如图2 所示。3 个BP 网络迭代步数分别在578步、1289 步和329 步时训练精度误差满足0.005 以下,同时收敛程度均达到预定的网络性能参数设置目标。将各组的测试样本输入到训练好的BP 网络中,由于输出结果篇幅太长,取其部分输出结果,如表1 所示。观察表1 中的输出结果,在特征级融合阶段,3 个BP 网络的各输出节点基本反映了大小便的监测状态,能初步判断有无排泄,但部分监测结果识别率并不高,如t2组中的小便识别误差达到了0.3659,取阈值ε1=0.3、ε2=0.5,根据目标识别准则识别结果将无法判断,可能误判断造成误报警。

图2 BP 网络误差曲线图Fig.2 BP Network Error Curve
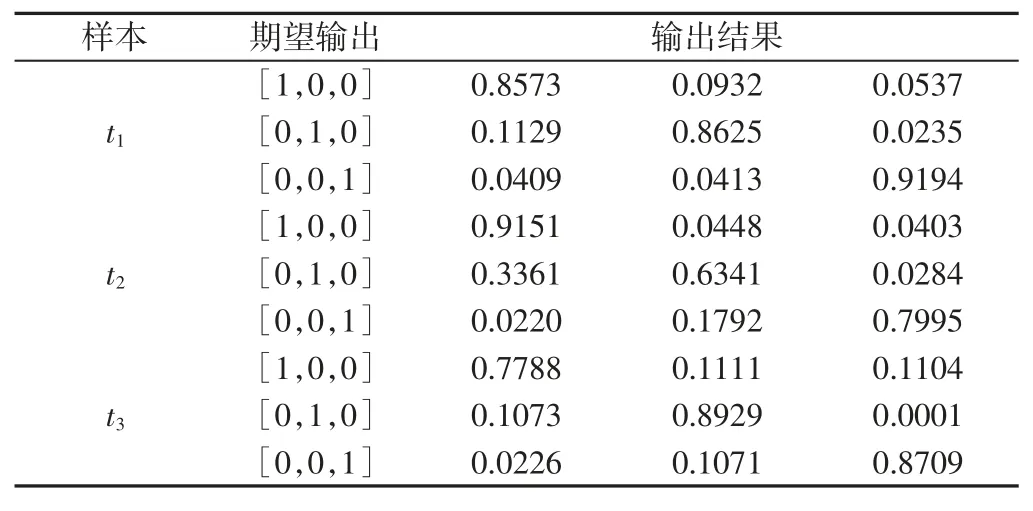
表1 BP 网络的部分监测结果Tab.1 Partial Monitoring Results of BP Network
5.2 基于D-S 证据理论的决策级监测
进一步利用表1 中的融合结果,通过式(13)和式(14)计算方法,经归一化处理获得决策级融合D-S 证据理论的基本信度分配,如表2 所示。
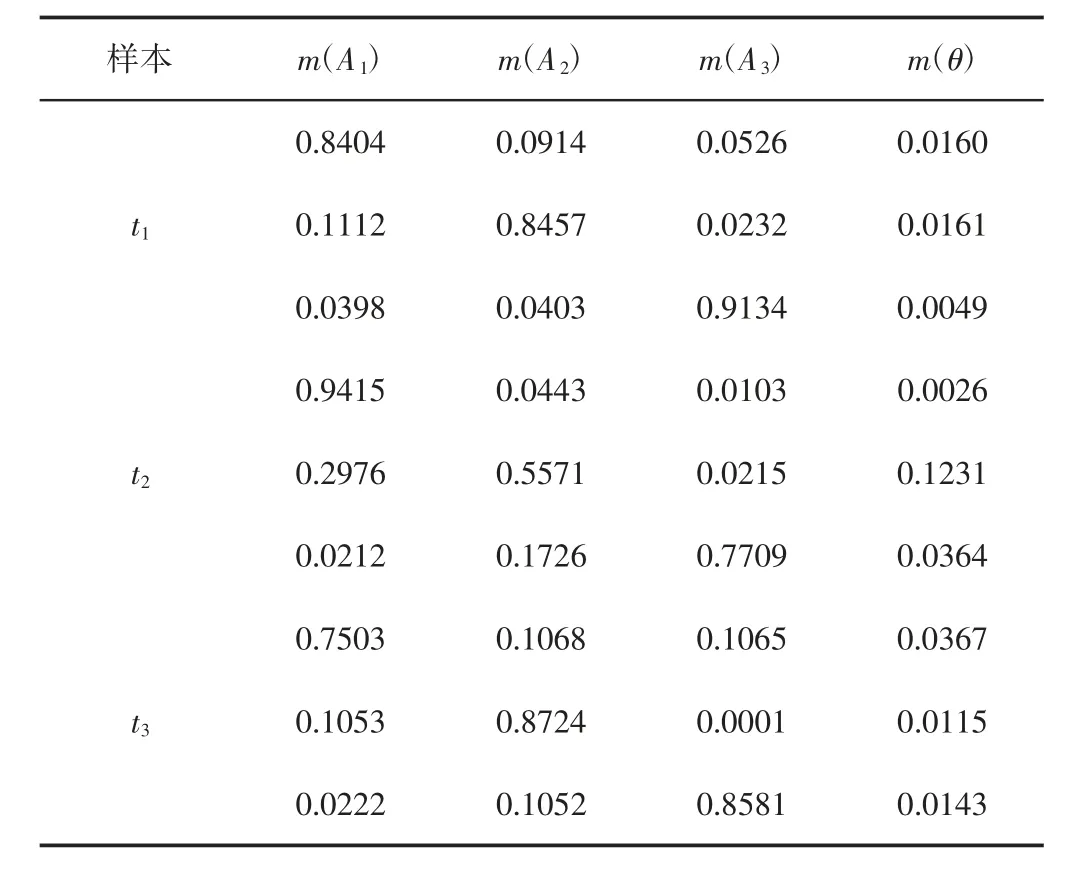
表2 D-S 证据理论的基本信度分配Tab.2 Basic Confidence Distribution of D-S Evidence Theory
依据表2 中的基本信度分配,分别采用D-S 算法、Murphy算法和改进的D-S 算法进行决策级融合,结果如表3 所示。
同样取阈值ε1=0.3、ε2=0.5,相比于BP 网络的特征级融合,在决策级融合阶段消除了输出结果不明确的情况。从表3 可以看出:(1)经典的D-S 算法识别率相对较低,并没有考虑证据冲突的情况,暴露出D-S 合成规则的缺陷;(2)Murphy 算法融合得到的小便概率值为0.914256 远小于算法的概率值,这是因为Murphy 算法只是对证据冲突部分进行平均分配,忽略了证据权重的问题,在某些情况下并不能得到理想的结果;(3)这里算法利用冲突之间的有效信息,引入矛盾系数改进证据组合规则,融合结果的识别率都在0.94 以上,而且收敛速度更快,同时可观察到算法的不确定性融合精度降到10-5,这是因为这里算法考虑了证据之间的关联性,降低了结果的不确定性,使得决策结果更精确,更接近事实。
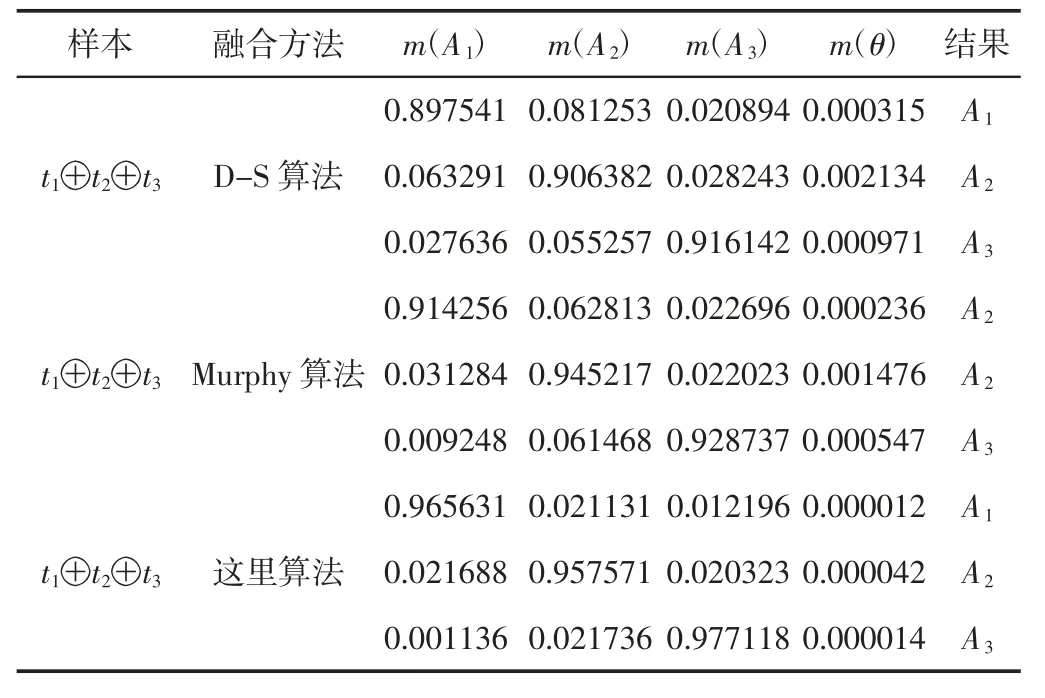
表3 不同D-S 算法的融合结果Tab.3 Fusion Results of Different D-S Algorithms
6 结论
主要研究了一种基于多传感器数据融合的护理机器人排便监测方法,通过分析得出以下结论:
(1)在特征级监测阶段,利用BP 网络进行初步融合,获得决策级融合中证据组合所需的基本信度分配;
(2)决策级融合阶段,在传统的D-S 证据理论基础上引入矛盾系数改进证据组合规则,通过矛盾系数改变证据间的权重降低了其他结果对最终决策的干扰,具有更好的辨识性,不确定性大大降低;
(3)基于BP 网络和改进的D-S 证据理论相结合的数据融合监测方法增加了系统工作的可靠性,大大提高了护理机器人排便监测的智能化水平,满足了护理机器人自动感应排泄的要求。
