基于开放数据的上海城市公园使用活跃度时空特征研究
2020-11-20何仲禹
何仲禹
李岳昊
随着生活质量的不断提高,中国居民对健康的理解和追求正在发生变化:以治疗疾病为主的医疗健康模式开始向干预居民整体健康水平的社会模式转变。研究发现,生活环境对健康的影响比个体行为更加具有普遍性,也预示着存在改善公众健康的普适性环境解决方案,从而为城市规划与设计提出了新的课题。
在影响公众健康的诸多建成环境要素中,公园绿地无疑是其中最受关注的。公园绿地不仅具有良好的生态效益,也是居民进行体育锻炼和室外休闲娱乐活动的主要场所。近年来,公园绿地的供给日益受到重视,城市人均绿地面积逐渐提升;但与此同时,也出现了公园大小、分布、使用者失衡等结构性问题。本文通过对上海中环线内130个城市公园的实证分析,探讨影响公园使用活跃度的建成环境因素,以期为我国城市公园绿地的规划与建设提供参考。
1 研究背景
现有文献对城市公园与绿地的研究主要集中在规划设计方法[1-3]、生态景观格局分析[4-6]、绿地空间分布优化[7-9]及绿地效用评价[10-12]等几个方面。本文的研究重点是公园的空间结构,对其规划设计和效用评价也有一定涉及。在公园的空间分布问题中,可达性研究是其中的重要内容之一;早期可达性单纯以人均公园面积或绿地率作为评价依据,这种方法虽然简单易行,但只适合做粗略估算;随后出现了基于服务半径、直线距离或缓冲区的可达性计算方法,这类方法并没有考虑实际的出行路线,仍具有较大的局限性;近年来随着GIS技术的普遍应用,出现了基于路网并综合考虑交通方式或出行成本的网络分析法和阻力模型法,这2种方法的计算精确度大为增加,但仍需对部分参数进行主观赋值[13]。此外,目前的公园规划设计方法研究大多基于案例分析,主要关注功能、面积、文化意象和植被景观等设计要素,对公园内部的服务设施配置涉及较少。而对公园的效用评价研究一般包括基于使用者满意度的主观评价方法和基于使用者数量及基于评价指标体系的客观评价方法。
在大数据时代,作为研究基础的数据来源的本质变革为所有研究提供了全新视角。目前,国内已经产生一些应用大数据对城市公园进行研究的成果,但整体数量仍偏少。李方正等利用新浪微博签到数据分析了北京中心城区绿地的使用情况,发现绿地使用情况受绿地类型影响较大,不同类型绿地的使用影响因素存在差异[14]。王鑫利用网络POI数据分析了市民休闲活动聚集强度,对北京郊野公园选址提出了建议[15]。另有一些学者利用不同类型的大数据进行了公园评价研究[16-18]。
基于时间地理学的理论框架[19],活跃度可定义为一定时间或空间范围内研究对象数量或密度的动态分布,它反映了被评价媒介的可达性和受众满意度[20]。近期相关研究大都采用如出租车GPS定位数据[19]、二手房交易数据[21]、城市POI数据[22]等大数据,通过核密度分析的方法分析城市空间活跃度。张薇分析了城市绿道活跃度与17个城市设计因子的相关性[20],除此以外,针对公园绿地活跃度的研究还较为匮乏。根据既有研究,本文将使用者活跃度定义为公园使用者的数量、密度及其在时间上的分布,将其作为公园评价依据,考量公园基本空间特征、内部服务设施、公园可达性及使用者个人属性对公园使用活跃度的影响。本文使用数据均来自互联网平台的开放数据,从而为既有公园研究提供一种新的思路与方法。
2 研究方法
2.1 开放数据概念
开放数据和大数据是2个互有交集的概念,前者目前尚无统一的定义。开放数据对产生或存储于Web中的各种类型的数据,按照用户特定的需求和相应的互联网协议、规则、框架进行开发、加工、存储和组织等管理活动,从而实现数据开放、互通和共享[23]。开放数据一般具备以下3个特点:1)非歧视性,对所有人均开放;2)可读性,数据应能被机器自动识别;3)开放授权性,使用者具有免费访问、获取、使用、加值、传播的权利[24]。开放数据以政府和学术机构提供的数据为主要来源,随着信息技术发展,特别是智能移动终端的普及,一些移动互联网企业提供的开放型大数据,如签到、评价和轨迹数据,为描述人们的空间活动提供了便捷和精准的途径。
本文的研究思路如下:首先通过Python编程提取来自开放数据平台的相关数据,然后利用ArcGIS工具对数据进行相关空间计算,最后将计算结果导入SPSS建立统计模型,定量分析使用者属性、公园服务设施、公园可达性及使用者评价等要素对公园使用者活跃度的影响。

图1 130个公园的面积及与市中心距离分布图
2.2 数据获取
依据城市用地分类标准,城市公园可分为面积较大的综合公园(包括市级公园和区域性公园),面积小、数量多的社区公园,沿路或水系分布的带状公园,以及诸如动物园、植物园、儿童乐园等类型的专类公园。本文以上海中环线内130个免费块状城市公园为研究对象,主要包括综合公园和社区公园2类。
本文需要获取的数据包括130个公园的基本信息、公园使用者数量与评价、使用者个人属性及公园可达性4个方面。数据来自高德地图API、高德位智和大众点评等互联网平台。
2.2.1 公园基本信息
通过高德地图开放平台API获取公园的基本信息。首先,利用多边形搜索接口搜索中环线内所有的城市公园,并获得其名称、坐标及中心坐标信息。然后借助POIinfo接口获取公园的边界信息,并利用多边形搜索接口对公园边界内指定类型POI进行搜索,得到公园中各类服务设施及公园出入口的数量和位置。同时,利用公园边界数据,通过Haversine公式计算得到公园面积。本研究选定人民广场作为上海中心,根据公园中心坐标计算得到公园与市中心的距离(图1)。通过接口搜索得到距离公园最近的地铁站坐标,从而计算公园与最近地铁站的距离(表1)。
2.2.2 公园使用者数量、评价及个人属性
本文选取高德位智中区域指数来计算公园使用量。区域指数是指一定时间内发生在一定地理范围内所有通过高德位置服务发起定位请求的总数量。尽管区域指数只能记录特定地理范围内发起定位请求的特定人群,无法代表全体人群,但本文认为在某一特定类型的空间(如公园绿地)中,使用这种定位服务的人群比例差异不大,因此指数数据同区域内人群数量、群体活跃度成正比。本文最终分别获取了130个公园以天为单位、2018年4月29日—5月25日共4周的使用者数量数据。
与公园使用量相同,公园使用者的基本信息也从高德位智页面中提取。由于部分深度属性数据,如使用者收入、职业等信息只面向商业合作用户开放,故本研究仅收集了公园使用者的年龄分组和性别这2类信息。
本研究中公园服务评价数据主要来自高德地图用户对于公园的平均评分,评价采用5分制。而对于高德地图中缺失评分数据的公园,本研究采用大众点评或其他地图服务商提供的评分数据作为代替。在数值上,不同方式获取的公园评分存在一定无规律差异,但总体而言,本研究认为它们的组合可以代表使用者对公园服务的整体评价。

表1 130个公园的基本信息
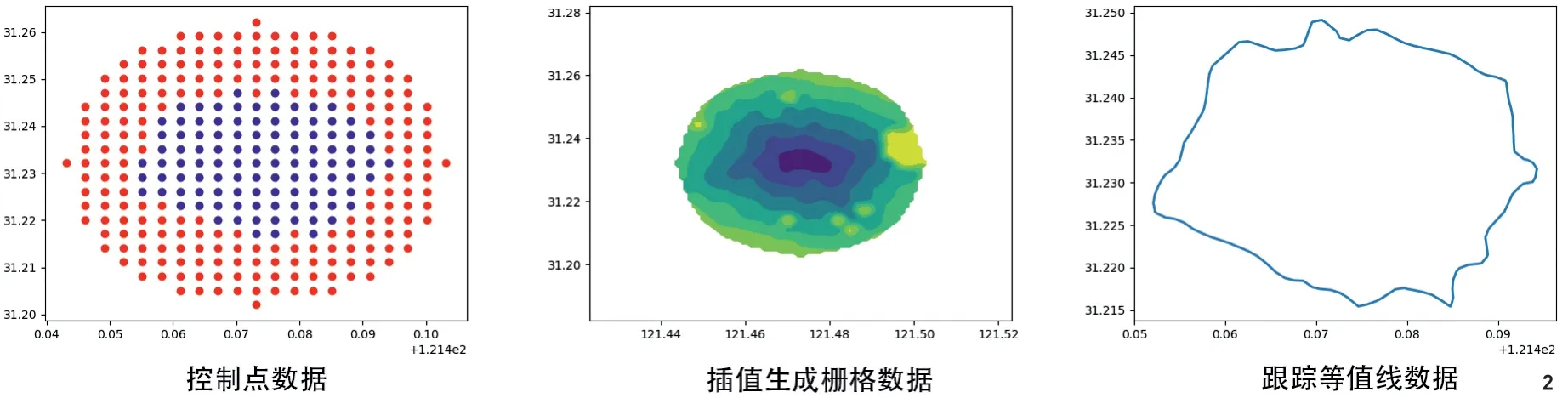
图2 控制点插值法数据示例
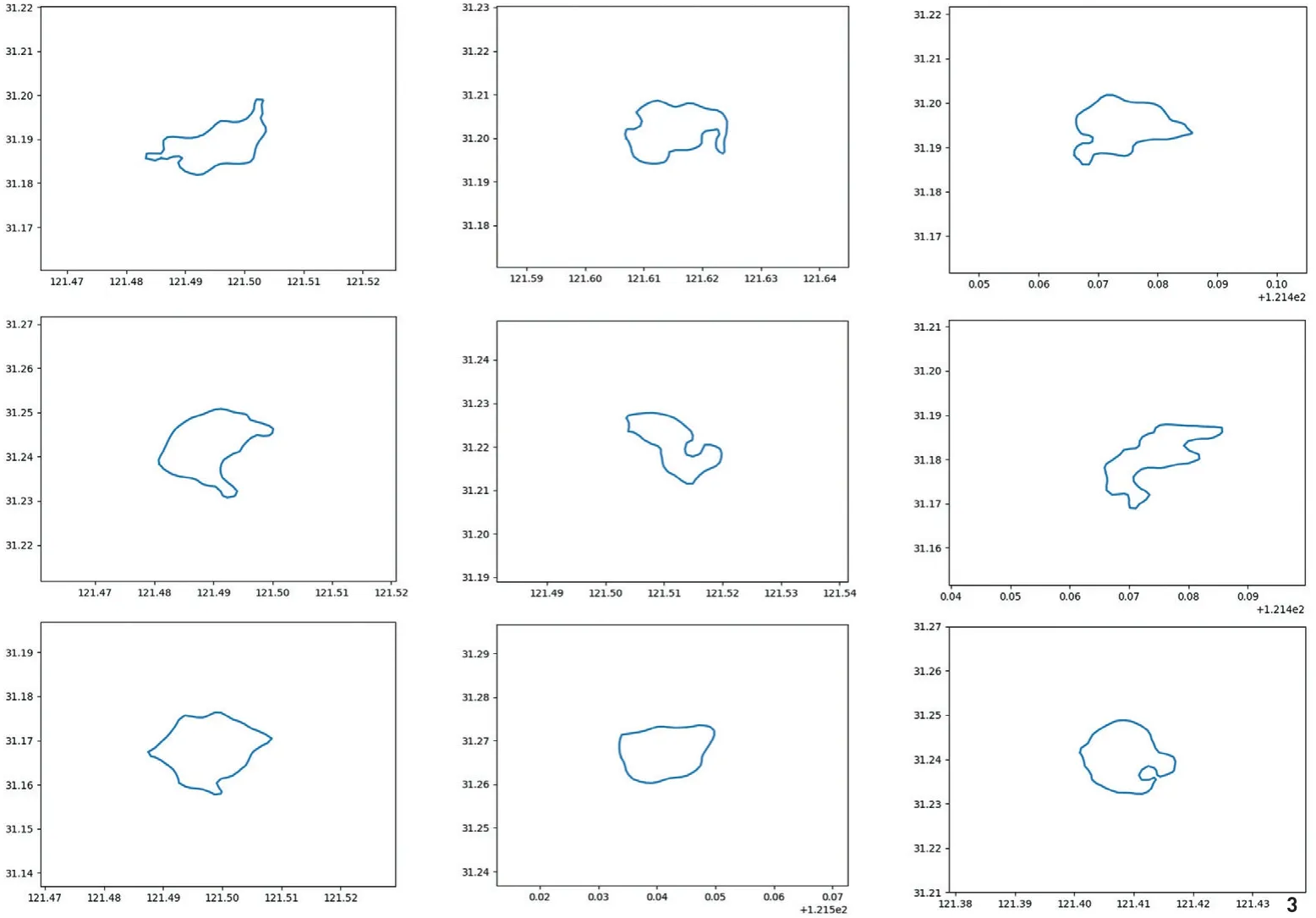
图3 部分公园步行15min可达范围示例
2.3 可达性计算
基于开放数据的特点,本文采用了与已有研究不同的可达性计算方法,即利用高德路径规划工具计算从公园出发、在工作日非高峰时间的一定时间内步行或车行的可达范围,从而避免了主观赋值,提高了计算的客观性与准确性。
具体而言,对于一个特定公园的步行可达范围,首先在以公园中心坐标为圆心、3km为半径的圆内,以300m为间隔沿南北和东西方向取控制点(经纬度不同),然后通过高德路径规划接口获取每个控制点到公园入口的时间距离。对于入口数量小于2个的公园,由于一般情况下这类公园属于没有围挡的开放性公园,因此采用的方法是首先计算控制点到公园中心的时间,然后假定公园呈圆形,计算其半径,在前面得到的时间距离的基础上减去从公园边缘步行至公园中心的时间,作为控制点到达公园的最终时间距离。对于入口数量大于等于2个的公园,则分别计算每个控制点到达公园每个入口的时间距离,然后从中取最短时间距离作为控制点到达公园的最终时间距离。
在获取从控制点到公园的时间距离后,利用控制点空间位置和时间距离数据,通过Matplotlib库和Scipy.interpolate库进行Cubic插值,得到描述到达公园时间距离的栅格文件,再追踪栅格文件特定时间(以min为单位)的等值线,计算边界内面积,得到公园服务范围数据(图2)。最终选取步行15和30min 2个可达区域作为下文统计分析的自变量。图3展示了按照上述方法计算得到的部分公园15min可达区域的范围,可以看到,根据公园空间边界、周边道路及交通状况的差异,这些范围也呈现出不规则的形状。
在对车行可达范围的计算上,本文主要考虑了30min机动车可达面积。一方面,机动车的空间可达范围远远大于步行的空间可达范围;另一方面,不同的交通区位等条件使得不同公园可达范围的差异性大大增强。因此,在机动车可达范围计算控制点的选取上,本研究采取了逐层搜索的方式,即从公园中心开始,以500m为半径变化梯度,由内而外搜索每个同心圆上各控制点到公园中心的时间距离。如果出现某个圆上所有控制点的时间距离均大于30min的情况,即视为已搜索到公园可达范围边界,停止搜索,然后利用插值法估算30min机动车可达范围。此外,由于公园机动车可达范围远大于公园自身范围,所以计算中忽略了公园入口与公园中心的差异。
从计算结果来看,步行15min可达范围与步行30min可达范围高度相关,但两者与车行30min可达范围均没有相关性。其中,步行15min可达范围最大的公园是鲁迅公园,覆盖面积达3.4km2;可达范围最小的是宜川公园,面积约为1km2;平均可达面积为2km2。步行可达范围较大的公园基本为大中型公园,大都沿内环路两侧分布,且相对集中于内环北部与西南部。车行30min可达范围最大的是嘉川路小游园,覆盖面积达1 014.3km2;覆盖面积最小的是管弄公园,为413.1km2;平均可达面积为707.8km2。车行可达范围较大的公园均临近城市快速路,面积较小,且大多沿中环路分布。需要指出的是,不同大小的公园,使用者步行与车行抵达的比重有所差异,因此其实际可达性应介于本文计算的步行与车行可达范围之间。
3 公园使用活跃度评价
3.1 公园使用活跃度特征
利用高德位智提供的7d周期内分时段区域指数,可以对130个公园的使用活跃度进行分析。从使用者性别比例来看,男性普遍占比在60%以上,这可能是由于男性相对女性更倾向于使用地图导航服务。从年龄层次来看,由于老年群体使用电子地图数量较少,因此统计得到的使用者以40岁以下人群为主,其中20~29岁人群约占45%,30~39岁人群约占35%。50岁以上中老年人群比例较高的公园基本为中小型社区公园,如西康公园、憩园、田中中心绿地等;而29岁以下年轻人比例较高的公园则大多为规模中等的区域性综合公园,如黄浦公园、广兰公园、古城公园等;市级大型综合公园各年龄层人群分布则处于平均水平。
从使用者活跃时间段来看,根据5月5—25日3周统计的平均值计算(4月28日—5月4日因包含五一假期,故未参与计算),其中21个公园的周末使用活跃度高于工作日,74个公园的工作日使用活跃度高于周末,35个公园无明显差异。就一天24h的周期而言,130个公园中使用活跃度呈现早、晚2个高峰,中午(傍晚)1个高峰或无明显高峰的比例各占约1/3,使用活跃度峰值在周末一般较为平缓,在工作日则更为集中。依据使用者活跃度的时间特征,可以将上海中环内公园划分为6种类型(表2),并可做出如下推断:小型社区公园使用者以居住在周边的居民为主,使用人数较少,各时段使用人数较平均;位于城市中心且周边就业密度较高的公园使用者数量最多,其使用者中周边就业人群的比例较高;靠近地铁站的公园更容易出现早、晚2个使用高峰;临近主要商业区的公园一般周末活跃度高于工作日,且使用高峰易出现在中午至傍晚,可能是由于使用者中购物人群比例较高;游乐设施较多的大型综合公园同样在周末的活跃度明显增高,可能是由于这些公园在周末会吸引来自全市各地区的各类使用者,平均使用者数量在6个类型中居第2位。
根据每个公园4周的日平均活跃密度与所有公园日平均活跃密度平均值的相对高低,划分其活跃度的高低;根据每个公园4周的日活跃度标准差(标准化)与所有公园日活跃度标准差平均值的相对高低,划分其活跃度稳定性的高低;从而将130个公园分为稳定高活跃、不稳定高活跃、稳定低活跃、不稳定低活跃4类(图4)。可以看出,活跃度高但人流波动大的公园(图4-1)主要集中在市中心;与之相对,活跃度低而人流波动小的公园(图4-2)多位于内环与外环之间。稳定的高活跃度公园(图4-3)主要位于浦西的居住片区内部;活跃度低且人流波动大的公园(图4-4)相对集中在浦东地区。
表2 依使用者活跃度特征划分的公园类型
3.2 公园使用活跃度影响因素
为进一步定量分析公园的建成环境特征、公园可达性、使用者个人属性和使用者评价对公园使用活跃度的影响,本文建立了回归模型。由于各公园面积差异巨大,因此分别计算统计周期内周末和工作日各公园的日平均使用者密度,将其作为使用活跃度表征,建立2个模型,模型中各变量定义如表3所示。
对于公共服务设施,根据高德地图定义的POI类型,本文主要统计了公园内部较为常见且可能对使用者数量产生影响的运动休闲、购物、餐饮和生活服务设施4种类型。通过对4类设施的相关性分析发现,各设施彼此相关性较强,其中生活服务设施与餐饮、购物设施的相关系数分别高达0.679和0.838(表4),为避免产生共线性问题,将生活服务设施数量从模型中移除。
在具体回归模型的选择上,本文比较了多元线性模型与柯布道格拉斯模型2种形式,并发现后者拟合度较好。因此,选用后者并通过对函数取对数的方式将其转换为线性关系。将表3中各自变量带入回归模型,并逐一去除不显著的变量,最终得到仅包含显著变量的回归结果,如表5所示。
从回归结果可以看出,2个模型具有较多相似之处。首先,公园使用者的年龄、性别构成等个人属性均对公园使用活跃度没有影响。其次,公园面积、与最近地铁站距离、与市中心距离3个基本空间属性与使用活跃度呈现显著的负相关关系。其中,在其他变量条件相同的情况下,公园面积越大,单位面积使用者数量越少,且是各变量中与活跃度关联最强的因素;而公园与市中心、与地铁站距离越近,则使用活跃度越高。再次,公园使用活跃度与公园内餐饮服务设施数量正相关,而与休闲娱乐服务设施数量不具备统计意义的相关性。最后,从可达性来看,车行30min可达范围与使用活跃度无关,而步行15、30min可达范围与使用活跃度均显著正相关,但步行15min对模型解释力度更强,说明15min的步行可达性对公园使用活跃度有着更大的影响。由于2个步行变量相关度较高,如同时放入模型会导致二者均不显著,因此最终模型仅纳入15min步行变量。2个模型最大的不同之处在于,使用者评价与工作日公园使用量无关,但与周末使用活跃度正相关,即使用者对公园评价越高,则公园使用强度也相应增加。这可能是因为周末人们时间较为宽松,对公园选择的灵活度更大,因此更倾向于依据主观偏好进行选择;而工作日则更多基于便利性进行选择。2个模型的整体拟合度也可支持这一推测:周末使用活跃度模型的拟合度为0.533,低于工作日的0.611,说明周末对公园利用的不确定性更大。
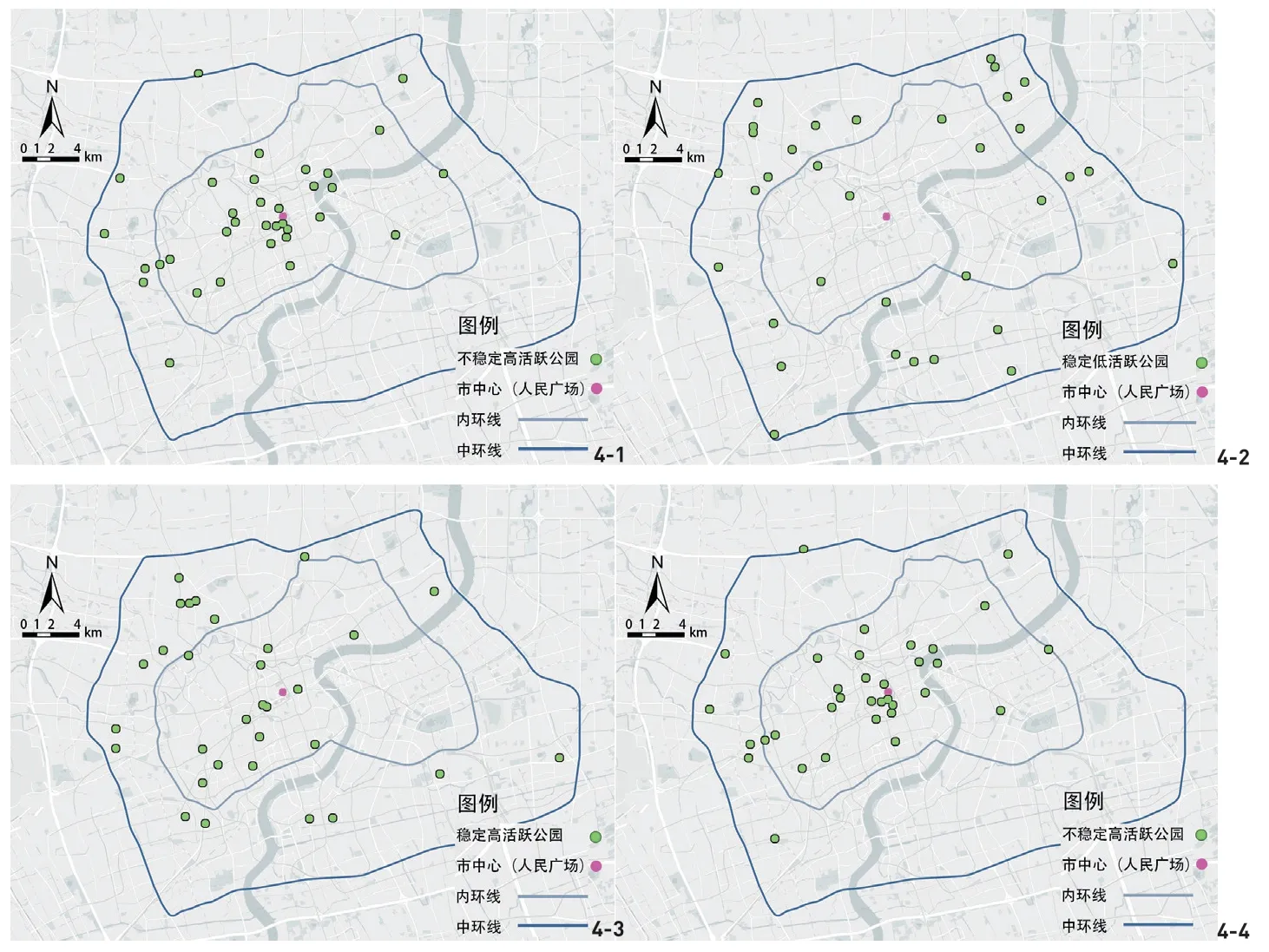
图4 依活跃度高低与稳定性划分的公园类型
4 结论与讨论
根据前文分析,为公园规划提出如下建议。1)在公园用地总量一定的情况下,提供分散、小规模的公园比集中、大规模的公园更有效。从公园空间属性与使用活跃度的关系来看,随着单个公园面积的增加,使用者总量上升,但单位面积使用者数量则呈下降趋势,公园使用效率下降;而单个公园面积与其使用满意度并无显著的相关性。当然,公园规模过小也并不利于其利用。从本文选取的样本来看,最小的公园面积为1 256m2,使用效率最高的公园面积大多分布在0.3~5hm2范围内。2)注重完善和丰富公园内的公共服务设施配置。随着公园内餐饮、购物、服务设施增加,公园使用活跃度增强,说明很多人利用公园的目的往往具有复合性,而不仅仅是到公园休闲或锻炼。3)公园布局与规划应提升基于实际路径的15min步行覆盖范围。良好的区位、公共交通条件与步行可达性对提升公园使用活跃度具有积极作用,位于30min步行时间内的公园仍对使用者具有吸引力,但随着步行时间的增加,其吸引力也将下降。除上述结论外,本文还发现不同类型公园的使用时间特征存在明显的差异。如大型市级公园周末活跃度高于工作日,临近就业中心的公园则相反,而居住区周边的小型社区公园则无明显差异;临近就业中心、商业区、旅游景区的公园一般白天有一个使用高峰,其他公园则有早、晚2个使用高峰。

表3 变量定义与预期效应

表4 公园各类服务设施数量间的相关性
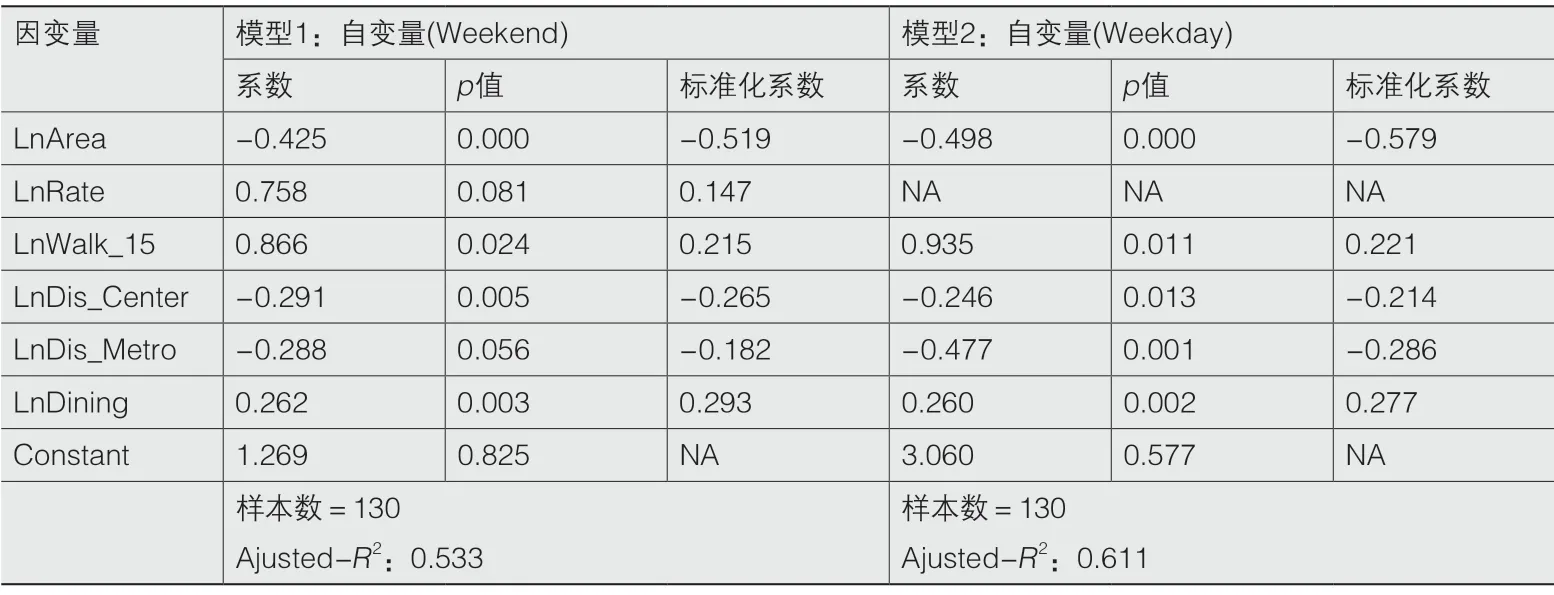
表5 回归分析结果
本文主要的创新之处在于开放数据的引入,既有文献利用微博、微信、POI等大数据对公园绿地的使用评价研究大都是基于某一时间截面的静态分析,而本文通过细化到小时的连续时间数据,从动态的角度揭示了公园使用的时空变化特征。此外,利用实时交通大数据计算可达性,提高了研究的精度和客观性。由于考虑了路网、出行速度和交通拥堵状况,从这种方法得到的部分公园可达范围存在着极大的空间非对称性(图3)。尽管对公园可达性的研究已大量存在,但本文和既存相关研究最大的不同在于:既有研究大多以一定范围的城市片区为对象,分析其内部所有公园在一定可达性条件下的空间覆盖率;而本文则以个体公园为对象,分析不同的可达性条件对公园使用情况的影响。
由于本研究是利用开放数据进行城市公园研究的初步尝试,因此也存在着一些不足之处。1)真正影响公园使用活跃度的是公园一定可达距离内的人口数量,但由于缺乏微观的人口分布数据,本文假设各公园周边人口密度接近,从而以用地面积代替人口数量,这与真实情况相比会有一定差异。2)由于技术手段限制,本文未能利用实时开放数据分析利用公共交通情况下的公园可达性,对步行和机动车也仅仅选取了3个时间距离。3)本文对影响公园使用活跃度的建成环境要素分析相对简单,未考虑公园形状、景观类型、植被覆盖率和水系等其他设计要素的影响。如果后续研究能在上述三方面进行改进,将会得到更为严谨和深入的研究结论。
注:文中图片均由作者绘制。
