地理分布式机器学习:超越局域的框架与技术
2020-11-20李宗航LIZonghang虞红芳YUHongfang汪漪WANGYi
李宗航/LI Zonghang, 虞红芳/YU Hongfang,3, 汪漪/WANG Yi
(1. 电子科技大学,中国 成都,611731;2. 南方科技大学,中国 深圳,518055;3. 鹏城实验室,中国 深圳,518055)
(1. University of Electronic Science and Technology of China, Chengdu 611731, China;2. Southern University of Science and Technology, Shenzhen 518055, China;3. Peng Cheng Laboratory, Shenzhen 518055, China)
随着5G技术的逐步商用,激增的数据为人工智能技术提供了丰富的数据资源,催生了人脸支付、辅助感知等新时代智能应用的萌芽。为强化智能应用的生命力,加速以深度学习为代表的智能模型的训练过程,分布式机器学习[1]成为业界重点关注的关键技术。数据并行的分布式机器学习将完整数据均匀分配给数据中心内的多个处理节点。这些节点各自维护一个本地模型副本以并行计算其数据切片上的本地梯度,并递交给其他节点计算全局梯度,随后全局梯度在所有节点间同步,最终被用于更新各节点的本地模型。
然而,训练所需的海量数据分散在多个机构的数据中心内,将这些数据碎片汇集于一个数据中心将引入巨额通信代价。业界对数据隐私和知识产权的愈发重视导致碎片之间更加割裂,使得人工智能技术从数据碎片中挖掘的知识具有明显的片面性。因此,要发挥大数据的集聚和增值作用,提供高质量的智慧化服务,就需要以数据隐私保护为前提,在多机构间进行高效的分布式训练,打破机构间的数据和网络壁垒,化解数据孤岛难题。
地理分布式机器学习[2](GeoML)是一种面向跨地域分布的数据中心的分布式训练范式。与联邦学习[3]类似,GeoML将训练样本保留在中心内,并在中心间交互模型数据,从而实现数据的隐私保护。需要指出的是,联邦学习将机构整体视为一个参与节点,而GeoML允许机构的中心内有多个参与节点,中心内通过大带宽局域网互联,中心间通过小带宽广域网互联,整体形成多中心跨域互联形态。鉴于数据在中心内的分布式存储现状以及业界对并行加速模型训练的需求,GeoML更适用于多中心跨域互联。
1 地理分布式机器学习机遇与挑战
近年来,人工智能的全球发展热潮势不可挡,并在智慧医疗、智慧城市、互联网金融等关键领域创造了巨大的社会效益。GeoML作为一种多中心跨域互联的分布式机器学习技术,为上述关键领域中大型数据孤岛的融合提供了安全且高效的解决方案,有力推动了人工智能数据能源的整合,因而正愈加受到业界的关注和重视。此外,联邦学习和隐私计算等新兴领域的安全成果(安全多方计算[4]、差分隐私[5]、同态加密[6]等)进一步巩固了GeoML的隐私保护能力,在较大程度上打消了合作机构对数据安全的顾虑,从而更利于GeoML的发展与落地。可见,GeoML正处于具有强烈需求且前置技术完备的时代,拥有无限的机遇和广阔的应用前景。
然而,GeoML同时面临着基础框架缺乏与通信开销庞大的挑战。一方面,业界尚缺乏适用于GeoML的通用开源软件框架。虽然部分开源深度学习框架(如MXNET)和联邦学习框架(如FATE)也能部署于多中心跨域互联场景,但这些框架无法区别和适配中心内/外差异化的集群环境,从而会不可避免地带来高额通信开销和资源浪费。另一方面,GeoML拥有比联邦学习更大的集群规模和更激烈的竞争环境,且需要在中心之间反复交换大量模型数据,使其面临更显著的通信开销。
针对上述挑战,我们在第2章提出一种GeoML通用软件框架,在第3、4章分别从通信架构和压缩传输机制着手优化通信,提出一种分层参数服务器(HiPS)架构减少广域传输梯度流数量,以及一种双向稀疏梯度传输(BiSparse)技术减少广域传输梯度流大小。
2 地理分布式机器学习软件框架
本文中,我们基于经典深度学习框架MXNET[7]开发了地理分布式机器学习框架GeoMX。该框架系统架构如图1所示,包括以下部分:
(1)数据源。数据源是指机器学习训练所需的视频、音频、图像、文本等数据的存储介质。根据数据实际存放位置的不同,处理节点可以从本地文件系统、所在数据中心的分布式文件系统(HDFS)以及远端S3存储中读取数据。
(2)数据处理模块。该模块负责加载与解析数据源中的数据,根据训练配置进行预处理、切片和采样,并将数据缓存到数据队列以供模型计算使用。数据预处理包括数据清洗、归一化、标准化、结构变换以及随机翻转、裁剪、色彩变换等数据增广操作,以保证数据符合格式规范,并且扩充数据以缓解模型过拟合。数据切片是指将存储于共享数据源的完整数据集进行切分,其中切片由多个处理节点分别维护。数据采样是指处理节点从数据切片中采集小批量样本用于计算梯度,常用采样方式包括随机采样、顺序采样、重要性采样等。
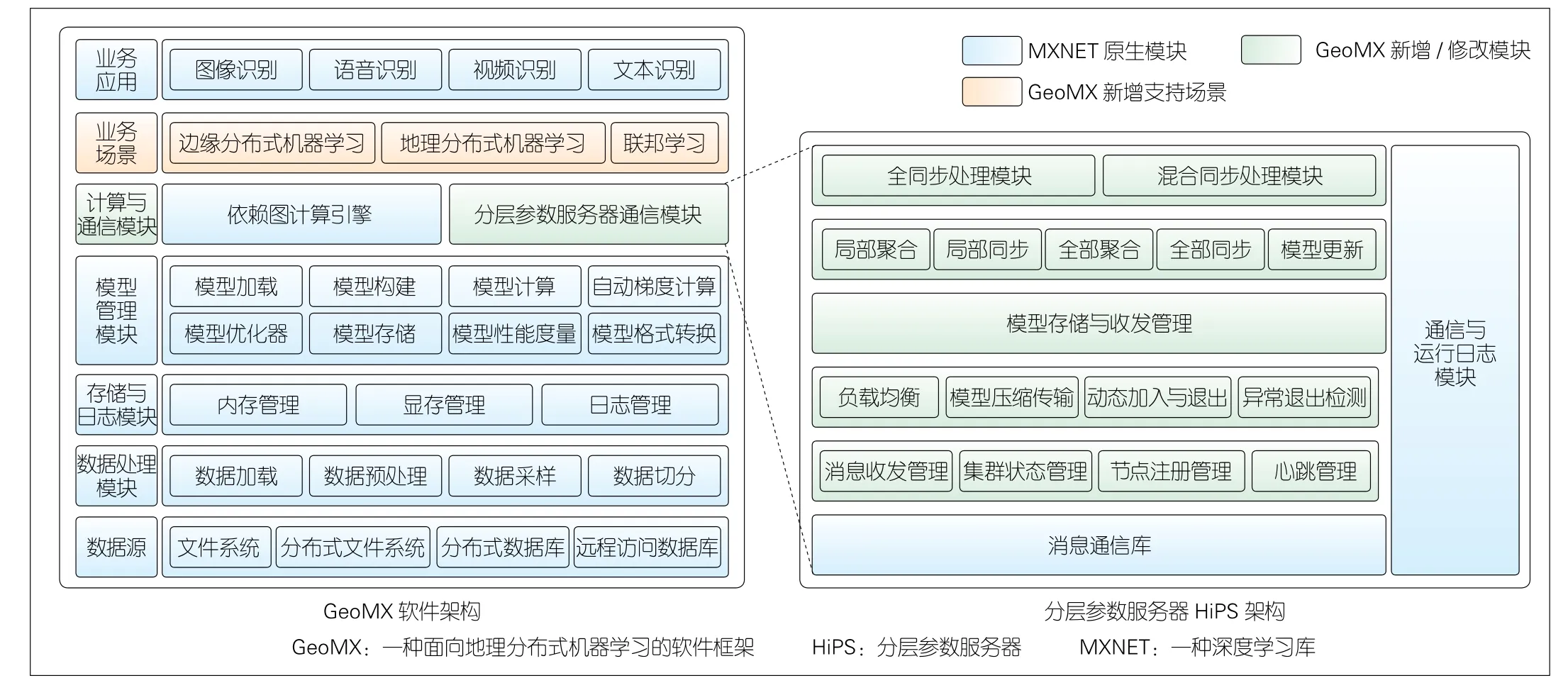
▲图1 GeoMX(左)与HiPS(右)系统架构图
(3)存储与日志模块。存储模块包括内存管理模块和显存管理模块,以分别负责内存和显存上存储空间的分配、释放以及垃圾回收;日志模块则为模型训练等操作提供便捷美观的进度跟踪、关键指标记录、系统运行状态记录等功能。
(4)模型管理模块。该模块负责模型计算图的构建以及模型参数的管理。模型计算图中的张量节点由模型构建模块产生,节点间的计算关系由模型计算、自动梯度计算和模型优化器模块产生。模型计算图中张量的加载、保存、格式转换等功能则由其他模块提供。
(5)计算与通信模块。模型计算图的计算由依赖图计算的引擎执行,该引擎可分析张量间的依赖关系和调度多个张量计算并行执行。多个处理节点间模型计算图的规约和同步由HiPS通信模块提供,该通信模块提供标准的PUSH和PULL原语,利用层次化通信架构和压缩传输机制实现高效通信。
(6)业务场景。GeoMX可部署于多种广域分布式机器学习场景。例如,云边端协同的移动边缘计算场景,微云、微数据中心和公有云组成的边缘计算场景,多个公有云跨域互联的场景,以及面向机构的联邦学习场景。
(7)业务应用。GeoMX不仅支持所有兼容梯度优化的机器学习模型,如神经网络、梯度支持向量机(GSVM)、梯度提升决策树(GBDT)等,还可用于支撑大多数复杂的智能应用,如图像、语音、视频、文本等的识别、检测、预测和生成任务。
在HiPS通信模块中,本文中我们主要关注以下技术:
(1)层次化通信架构。该架构将中心内/外网络环境分隔为两层,第1层在中心内实现局部聚合,第2层在中心间实现全局聚合。这样可有效减少中心间传输的数据量,也可降低中心的管理成本和安全风险。
(2)混合同步技术。该技术包含全同步模式和混合同步模式:全同步模式即中心内和中心间都采用同步并行,混合同步模式即中心内采用同步并行而中心间采用异步并行。针对这两种模式,可根据集群异构程度、对模型质量与训练效率的需求进行选择。
(3)压缩传输技术。该技术旨在压缩传输模型以减少中心间实际传输的数据量,从而降低通信开销。GeoMX支持的压缩方法包括半精度量化[8]、2bit量化[9]、深度梯度压缩(DGC)[10]、DGT[11],以及第4章提出的BiSparse技术。
3 HiPS架构及流量模型
在通信架构优化方面,我们基于参数服务器架构[12]提出HiPS架构。以全同步模式为例,假设有图2所示的一个中心机构和两个参与机构,各机构中心内的物理节点通过局域网互联,中心间通过广域网互联。
中心机构包括全局参数服务器、主控工作节点、本地调度器和全局调度器4个节点,其中前3个节点彼此互联,全局参数服务器与全局调度器互联。参与机构包括参数服务器、本地调度器和若干工作节点。参与机构内的所有节点彼此互联(工作节点间除外),参数服务器与全局调度器互联。参与机构内部节点构成中心内参数服务器架构,参与机构的参数服务器与中心机构的全局参数服务器和全局调度器构成中心间参数服务器架构。
HiPS流量模型如图3所示(调度器因不参与模型数据交互而被简化),其中各类节点功能如下:
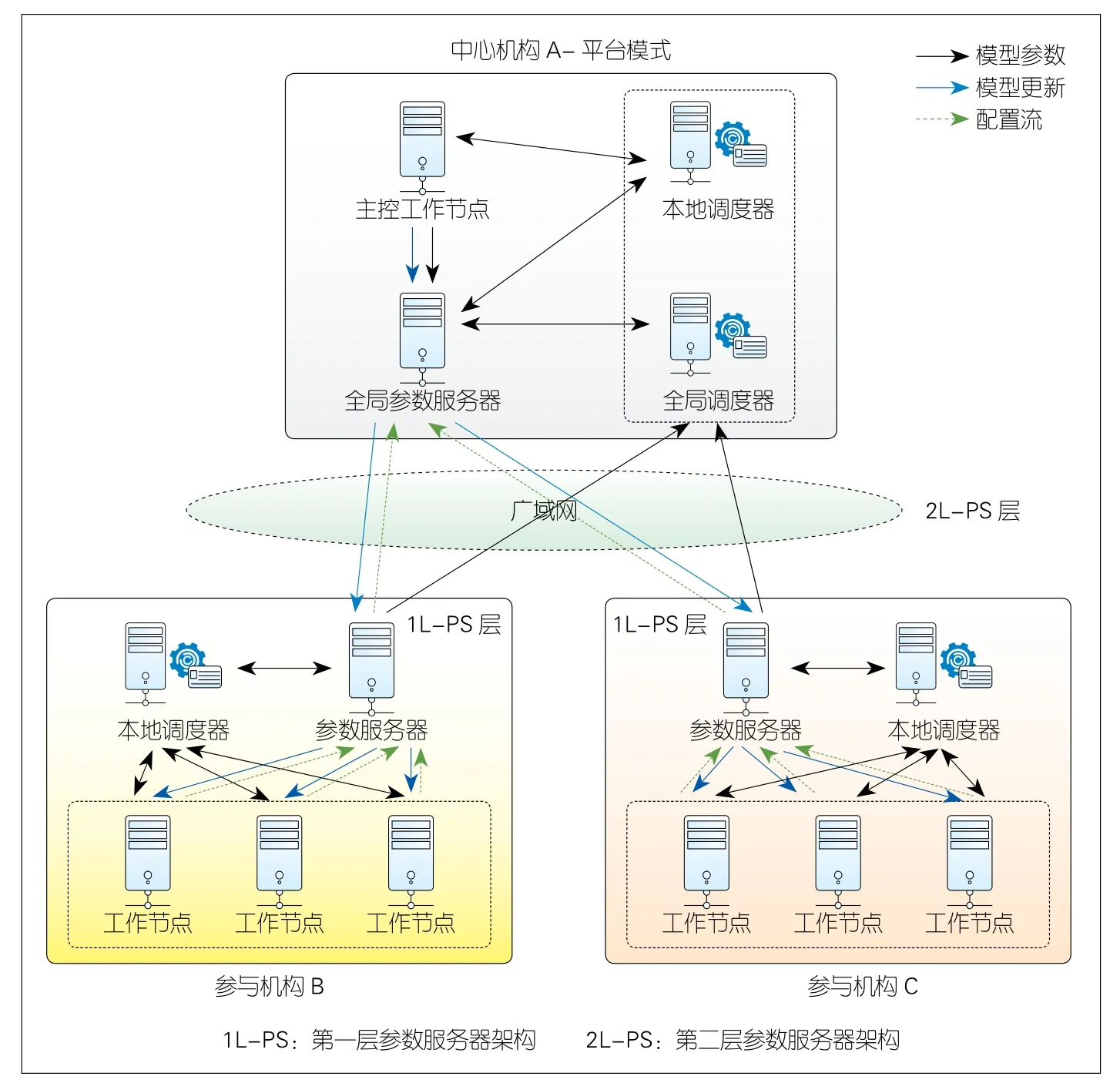
▲图2 分层参数服务器架构
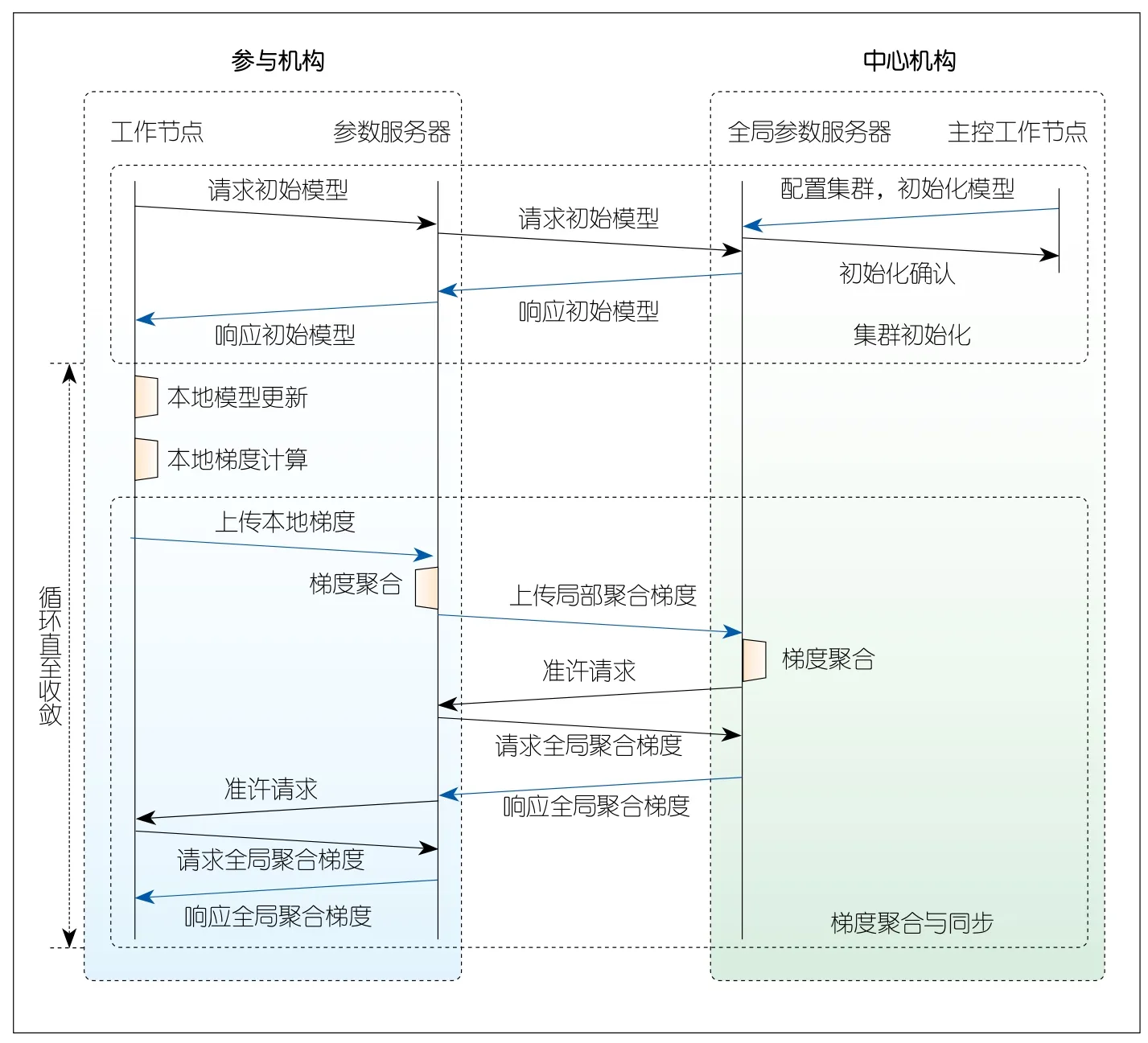
▲图3 分层参数服务器流量模型
(1)工作节点。该类节点位于参与机构内,负责加载、解析、清洗和预处理数据源中的数据并用于计算本地模型梯度。这些梯度由机构内的参数服务器聚合,并被用于更新本地模型。
(2)主控工作节点。该节点是位于中心机构的一个特殊工作节点,负责构建模型计算图,初始化图中的张量参数,并交付给全局参数服务器以初始化全局模型。此外,主控工作节点还负责集群的配置,包括设置同步模式、压缩策略和优化算法等。
(3)参数服务器。该类节点位于参与机构内,首先负责聚合机构内工作节点提交的本地模型梯度,并转发到中心机构的全局参数服务器。随后,该类节点从全局参数服务器获取最新模型数据,并同步到机构内的所有工作节点。
(4)全局参数服务器。该类节点位于中心机构内,负责对所有参与机构提交的局部聚合梯度执行全局聚合。本文中,我们默认全局参数服务器直接返回全局聚合梯度,但若主控工作节点设置了全局参数服务器的优化算法,全局参数服务器将用全局聚合梯度更新全局模型,并下发最新模型参数到参与机构。
(5)本地调度器。该节点位于所有机构内,用于机构内节点的注册、中止以及状态管理(节点地址、集群规模、心跳等),也负责管理机构内节点的动态加入和退出以及异常退出检测。
(6)全局调度器。该节点位于中心机构内,其作用与本地调度器类似,负责参与机构的动态加入和退出以及异常退出检测。
我们使用7台服务器构建计算集群来验证上述技术,其中每台服务器配有两张Tesla K40M计算卡,服务器之间使用千兆以太网互联。我们按1∶3∶3的比例将7台服务器分为中心机构A、参与机构B和参与机构C,并依照图2部署各个机构,其中B和C各部署6个工作节点。我们选择MXNET框架作为对照,其中中心机构部署一个参数服务器和一个调度器,两个参与机构各部署6个工作节点,并且所有工作节点与参数服务器直接通信。上述节点均部署于Docker容器中。本文中,我们将两个框架部署于1 Gbit/s带宽网络来模拟数据中心内的局域网环境,并使用Wondershaper工具将中心机构的上下行网卡带宽限制为155 Mbit/s以模拟数据中心间的广域网环境。
我们将图像分类数据集Fashion-MNIST[13]均匀切分到所有工作节点来训练ResNet-50[14]模型,并配置集群以全同步模式、无压缩模式运行,工作节点使用标准随机梯度下降(SGD)优化器更新模型参数。GeoMX与MXNET在局域和广域环境下的测试精度曲线如图4所示。在相同带宽条件下,GeoMX明显提高了MXNET的训练效率并且不损伤收敛精度。此外,多中心跨域互联场景下的GeoMX-155 Mbit/s训练效率略优于数据中心内的MXNET-1 Gbit/s。
为消除模型大小对上述结论的影响,我们用参数量递增的ResNet系列模型(ResNet-18/34/50/101)重复上述实验,并在表1中给出各组实验的单轮通信时延。实验数据再次展示了GeoMX趋同局域的通信效率:在所有模型上,GeoMX-155 Mbit/s的通信时延仅为MXNET-1Gbit/s的78%~87% 。
4 BiSparse技术
为进一步降低广域通信开销,在压缩传输方面,我们基于DGC[10]提出BiSparse技术,通过稀疏传输上下行梯度,可以有效减少中心间传输的梯度量。为实现通信高效且精度无损的稀疏传输,BiSparse不仅需要快速且准确地从大规模梯度张量中筛选关键梯度,并在稀疏空间中实现高效的传输和聚合,还需要解决因丢失非关键梯度而导致的精度损失。如图5所示,BiSparse具体包含如下技术:
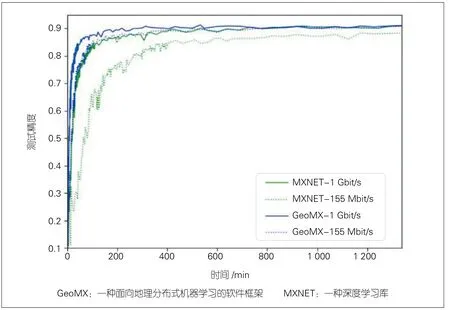
▲图4 GeoMX与MXNET在不同带宽下的测试精度曲线

表1 GeoMX与MXNET在不同模型下的单轮通信时延对比
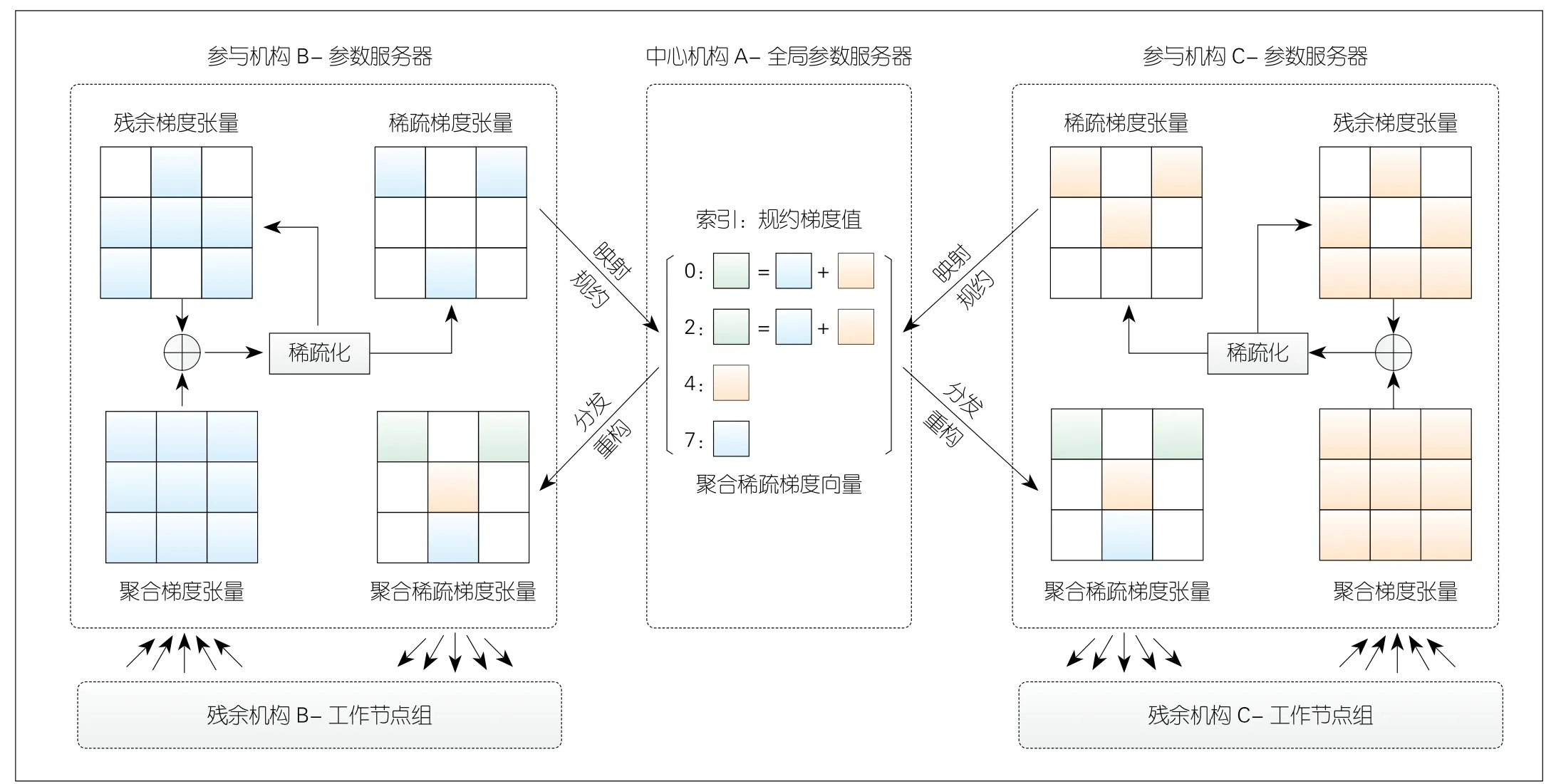
▲图5 双向稀疏梯度传输技术流程示意图
(1)梯度稀疏化技术。该技术旨在从大规模梯度张量中筛选出少量关键梯度,在保障模型精度几乎无损的前提下,以减少实际传输的梯度数量。假设某梯度张量包含N个梯度值,且指定压缩比例为k(0<k≤100%)。为快速确定梯度张量中绝对值最大的top-k个梯度值,我们按采样率s从梯度张量中随机采样sN个梯度值,并按绝对值从大到小的顺序进行排序,其中第skN个值T将被作为梯度张量中top-k个梯度绝对值的近似下界。因此,梯度张量中绝对值大于T的梯度值将被选为关键梯度并参与稀疏聚合。
(2)稀疏聚合与同步技术。该技术实现在稀疏空间中对关键梯度进行高效聚合与同步,包括映射、规约、分发与重构。在映射阶段,参与机构的参数服务器将稀疏梯度张量编码成元素(索引、梯度值)的向量,其中索引指梯度值在梯度张量中的相对偏移。在规约阶段,中心机构的全局参数服务器加和索引相同的梯度值,得到聚合稀疏梯度向量。在分发阶段,各参与机构的参数服务器从全局参数服务器获取聚合稀疏梯度向量,并在重构阶段转换为张量,随后该张量被下发给工作节点完成梯度同步。
(3)残余梯度修正技术。本文中,我们称梯度稀疏化时未选中的非关键梯度为残余梯度。为避免丢失残余梯度而导致精度损失,该技术缓存残余梯度并累加到下一轮的聚合梯度中,同时利用动量修正技术缓解因残余梯度延迟更新引起的收敛震荡。假设当前轮次t的聚合梯度张量为Gt,上一轮次缓存的残余梯度速度和位置张量为vt-1和ut-1,阻尼系数为m。当前速度vt由衰减的历史速度和当前施加的聚合梯度根据vt=mvt-1+Gt得到,并用于更新位置ut=ut-1+vt,其中ut将代表聚合梯度参与梯度稀疏化。最后,梯度稀疏化筛选出的关键梯度对应的速度值和位置值从张量vt和ut中置零,随后vt和ut作为残余梯度被缓存并累加到下一轮的聚合梯度中。
本文中,我们设置k= 1%,s=0.5%,m= 0.9,并在 1∶ 6~1 ∶ 100的广域与局域带宽比、参与机构B和C各4个工作节点下对比了GeoMX关闭/启用双向稀疏梯度传输GeoMXBiSparse与半精度量化[6]GeoMX-FP16(除稀疏梯度外,梯度均以16位浮点数传输)技术的收敛精度、时间、轮数以及传输数据量。如图6所示,稀疏化和半精度量化均能有效提高训练效率,其中稀疏化所取得的效率增益最为显著。此外,稀疏化结合半精度量化GeoMX-BiSparse-FP16可进一步减少40%的获得理想模型精度(90.4%)的时间。
为了验证上述优化技术应用于广域环境相比基础GeoMX应用于局域环境的增益,我们选择GeoMX-1 Gbit/s作为对比。表2数据表明,仅采用稀疏化技术就能取得约20%的训练效率增益(由10.6 h降到8.6 h)、10%的通信效率增益(由7.24 s降到6.58 s)以及90%的传输数据压缩率(上下行传输数据量分别由93.95 MB降到8.15 MB和9.90 MB),且保证收敛精度无损。对于两种优化技术相结合的方案,虽然稀疏梯度损失和半精度损失的双重影响导致了一定的收敛精度下降(由90.8%降到90.6%),但是对于对近50%的训练和通信效率增益(由10.6 h降到5.8 h、由7.24 s降到3.88 s)而言,损失0.2%的模型精度是可容忍的。为模拟带宽差异更显著的广域和局域通信环境,我们将广域带宽进一步限制到100/50/10 Mbit/s。由于广域带宽更加紧缺,每轮模型通信需要更长的时延,致使训练效率逐步劣化。在50 Mbit/s广域带宽下,GeoMX-BiSparse-FP16仍能取得趋同GeoMX-1 Gbit/s的训练效率(10 h vs.10.6 h)。当广域带宽持续减小时,即使近95%的传输数据压缩率也难以突破广域通信瓶颈,这就要求我们必须探索更先进的通信优化技术。
5 结束语
GeoMX是大数据与人工智能结合的必然产物,它推动着大型数据孤岛的融合,并反馈大数据与人工智能的发展进程。基础软件框架的普及与优化技术的全面覆盖将有力驱动GeoMX是的应用与落地,并与联邦学习和隐私计算等交叉领域技术互补,共同构建安全且高效的下一代人工智能技术体系。
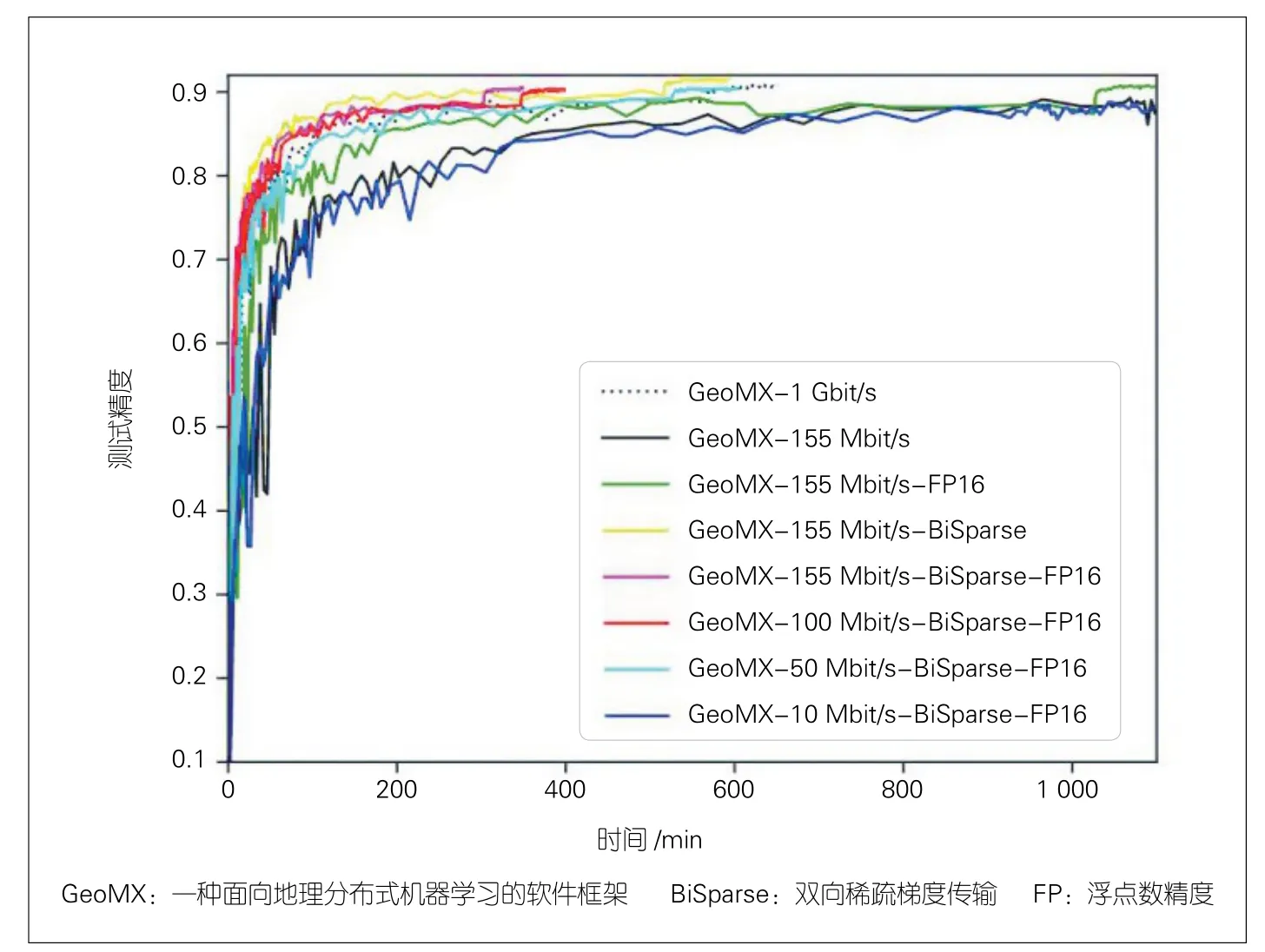
▲图6 不同压缩方案与广域带宽下的测试精度曲线
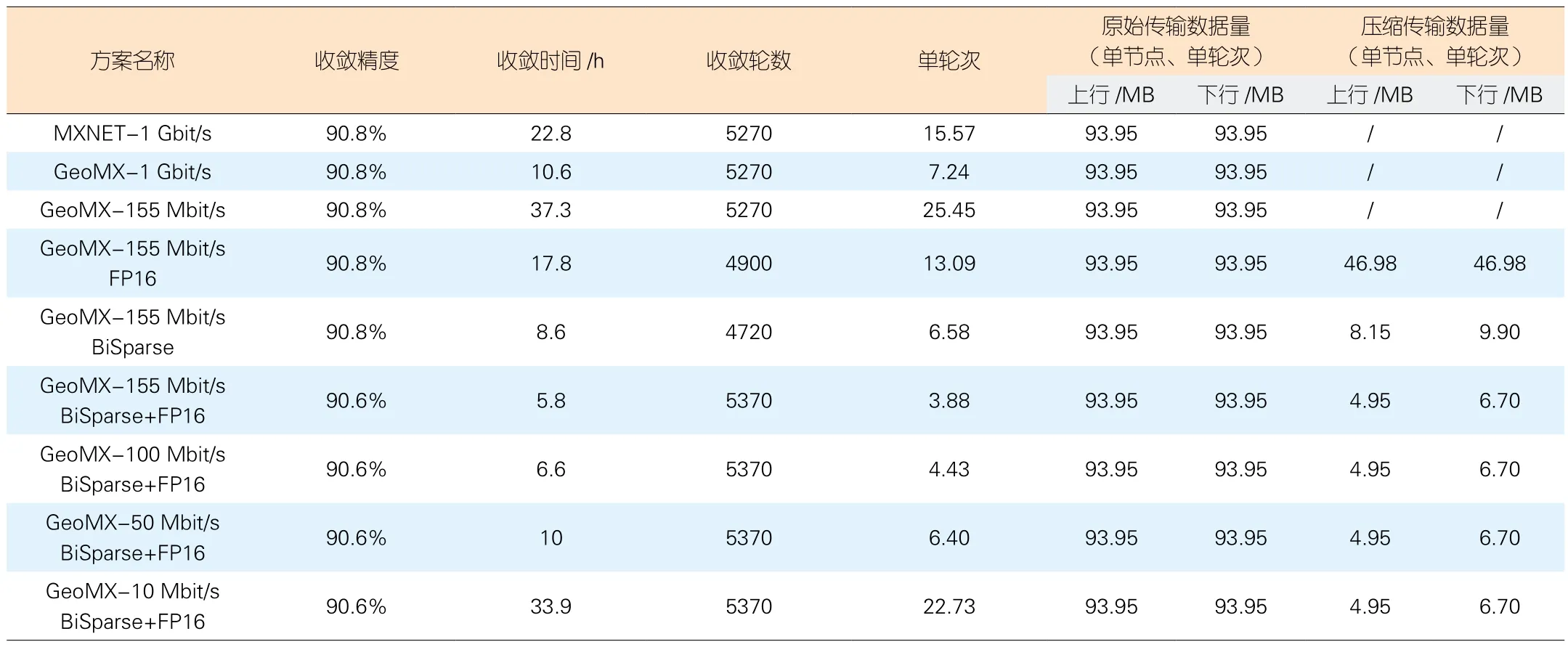
表2 不同压缩方案与广域带宽下各维度优化效果对比
致谢
感谢电子科技大学信息与通信工程学院张兆丰硕士对本文第4章技术与实验部分的贡献。
