数字经济、网络使用与居民收入
——基于分层线性模型的研究
2020-11-19周宛瑾
周宛瑾,张 龙
(西北大学 经济管理学院,陕西 西安 710127)
近年来,国家高度重视数字经济的发展。《国家信息化发展战略纲要》和《国家数字经济发展战略纲要》均对发展数字经济作出重要部署,出台了网络强国、宽带中国、“互联网+”行动和促进大数据发展等系列重大规划。可以看出,数字经济已经逐渐成为我国经济增长的重要驱动力。
数字经济的发展促使各地区的互联网普及率逐年提升。与此同时,居民对网络技术的使用能力也在不断增强。居民可以更便利地使用互联网获取有效信息、提升劳动技能,积累一定的信息资源。《人口与劳动绿皮书》提出,居民个人对互联网的使用可以使其年劳动收入增加46.52%。中国社科院一项调查研究显示,互联网对提升中低收入人群的收入有一定帮助。那么各地区数字经济发展水平是否对各地区居民收入水平造成影响,数字经济又是如何通过影响居民个人互联网使用进而影响居民收入的呢?
1 文献综述
1.1 数字经济发展对居民收入的影响
在宏观地区层面,区域数字发展水平的差异会导致社会阶级贫富分化。郝大海认为,各地区存在数字鸿沟,各地区经济发展差异会对居民能否接入互联网有很大影响[1];周文杰从宏观和微观两个层面,对国外数字鸿沟现象进行了测度和考察,认为数字信息分化会影响居民信息素养,从而导致社会阶级的贫富分化[2];李升实证检验了日本各地区因存在数字鸿沟而导致社会阶层分化,使得高阶层人群和低阶层人群的收入差距加大[3];柯惠新从社会层面和个人层面分析了亚太五国的地区数字鸿沟及其影响因素,发现数字信息发展水平差异拉大了富裕国家与贫穷国家之间的差距[4]。
1.2 网络使用对居民收入的影响
在微观个人方面,居民互联网使用能力的提升可以促进居民收入的增长。韩长根使用2010年至2016年CFPS(中国家庭追踪调查)数据发现,居民通过互联网学习、工作和社交,可以提高自身收入水平[5];毛宇飞使用CFPS数据研究发现,互联网对性别工资差距有影响,互联网的使用促进了性别工资的增长[6];华昱发现,使用网络进行学习和工作的居民会比未使用网络的居民获得更高的收入[7];陈玉宇利用全国家庭普查数据研究发现,个人通过使用电脑可以提升个人的劳动生产率,从而提高自身的工资水平[8];Pabilonia和Zoghi发现,个人使用计算机可以提升自身工资水平,但由于不同地区的互联网条件不同,对居民收入的影响也存在差异[9]。
从上述文献可以看出,数字经济与网络使用会对社会和个人产生影响。学者们在宏观层面上研究数字经济对地区社会发展的影响,在微观层面上研究互联网的使用对个人收入的影响。但很少有文献将这两个层面结合起来,分析数字经济是如何通过影响个人的互联网使用进而影响居民收入水平的。因此,笔者拟从宏观数字经济发展与微观居民个人互联网使用两个层面,采用分层线性模型,研究数字经济和居民个人的互联网使用对居民收入的影响。
2 实证分析
由于各个地区的数字经济发展水平会影响该地区居民对互联网的使用,会形成一个地区—个人的嵌套数据结构,因此,本文以省份为关键变量,链接个人与地区两层数据,通过逐步建立分层线性模型,来分析数字经济与居民个人的互联网使用对居民收入的影响。
2.1 变量定义与描述性统计
2.1.1 数据筛选
文章选取的微观数据来自2018年中国家庭追踪调查(CFPS)的个人问卷数据,宏观数据来自《中国统计年鉴》。在数据处理过程中,根据研究所需变量,在个人收入、网络使用、性别、年龄、受教育程度、城乡等选项中剔除了调查条目中填写不适用、不知道和缺失的数据。这样经过处理后,剩下11 026个样本,主要运用SPSS和HLM7软件进行分析。
2.1.2 变量选取
在个人层面上,使用的变量包括个人收入、城乡类别、性别、受教育程度、工作经验等;在地区层面上,使用的变量包括人均地区生产总值、数字经济发展水平等。
第一,被解释变量。居民收入是被解释变量,选取CFPS数据个人问卷中“工作总收入(元/年)”项目,指过去12个月所有工资、奖金、现金福利、实物补贴都算在内,并扣除五险一金所获得的收入。
第二,核心解释变量。居民对互联网的使用程度是核心解释变量,选取CFPS数据个人问卷中“互联网作为信息渠道的重要程度”项目,其中:1表示非常不重要,2表示不太重要,3表示一般重要,4表示比较重要,5表示非常重要。
第三,个人层次变量。第一,受教育程度。文章对受访者的受教育程度进行赋值的方法,其中,如果被访人的受教育程度是“本科及以上”时赋值为16,受教育程度是“大专”时赋值为14,受教育程度是“中专(高中)”时赋值为12,受教育程度是“初中”时赋值为9,受教育程度是“小学”时赋值为6。第二,性别。文章采用虚拟变量来表示,当被访人为男性时赋值为1,当被访人为女性时赋值为0。第三,城乡类别。文章采用虚拟变量来表示,当被访人为城镇户口时赋值为1,当被访人为乡村时赋值为0。第四,工作经验。文章采用被访人的年龄来表示潜在的工作经验,具体计算方法是,用年龄减去受教育程度的赋值再减去学前教育的6年。由于工作经验通常对收入具有非线性影响,所以把工作经验的平方也作为解释变量。
第四,地区层次变量。一是人均地区生产总值。文章采用人均地区生产总值来研究各地区经济增长状况对居民个人收入的影响。二是数字经济发展水平。一个地区的数字经济水平会直接或间接影响地区居民的收入和居民个人对互联网的使用程度,文章采用张龙等人的各地区信息水平得分来衡量各地区数字经济发展水平[10]。变量选取如表1所示。

表1 变量选取
2.1.3 描述性统计
由表2的描述性统计可以看出,在个人层面上,居民收入的均值为13 454.60;对互联网的使用程度平均水平为2.85,说明人们认为互联网对于信息获取一般重要;城乡均值为0.37,说明乡村人口偏多;工作经验均值为31;性别的均值为0.50;平均受教育年限为7.53,说明平均受教育水平为初中水平。在地区层面上,数字经济发展水平、人均地区生产总值的变异系数分别为10.16%(1.24/12.21=0.101 6)和3.66%(0.40/10.93=0.036 6),说明两者均存在一定的地区差异。

表2 描述性统计
2.2 模型构造
通过依次建立零模型、协方差模型、随机回归系数模型和完整模型,具体分析比较地区层面的数字经济发展水平和个人层面的互联网使用对居民收入的影响。
2.2.1 零模型
零模型,也称为随机效应的单因素方差分析,是在个人层次和地区层次都不加入自变量的前提下所建立的模型。对零模型进行可行性检验是运用分层线性模型的前提,如果组内相关系数不显著,那么可以运用传统的回归分析方法;反之,则考虑使用分层线性模型。其模型形式设定如下。
第一层:
incomeij=β0j+εij
(1)
第二层:
β0j=γ00+μ0j
(2)
将第二层的参数代入第一层,得到混合模型为:
incomeij=γ00+εij+μ0j
(3)
其中,εij~N(0,σ2),μoj~N(0,τ00),并且COV(εij,μ0j)=0
在上式中,income表示居民收入,i表示居民,j表示地区;β0j为第一层的截距项,代表居民的平均收入水平;γ00为第二层的截距项,代表总体的平均收入水平;εij为第一层的随机效应,μoj为第二层的随机效应,方差分别是σ2和τ00,分别代表了个人层次方差和地区层次方差。软件回归结果见表3。
从零模型回归结果可以看出,截距项为17 618.5,平均收入水平在1%的水平下达到统计意义上的显著。在方差分析中,个人层次所代表的组内变异为793 395 778.7,地区层次所代表的组间变异为96 177 879.1,组内相关系数ρ用来说明地区间差异可以解释收入方差的程度:
=0.108 11
(4)
计算可知,组内相关系数ρ为0.108 11,说明由于地区间不同所造成居民收入的差异占到了收入整体差异的10.81%。一般认为,当组内相关系数ρ≥0.059时,属于中度关联强度,说明居民收入在地区间的分布差异性比较大,在这种组间差异不能被忽略的情况下,应当运用分层线性模型进行分析。接下来,将把各层影响因素分别引入分层线性模型中进行估计与分析。
2.2.2 模型一:协方差模型
在零模型的基础上,在第一层模型中引入个人层面的互联网使用程度、城乡类别、工作经验、工作经验平方、性别、受教育程度等相关变量,建立第二层不包含任何地区层次变量的分层协方差模型,具体研究个人特征对居民收入的影响。
首先,对数据进行“中心化”处理,将每个观测值都减去该观测值所属组别的平均数,使其变量的数值变小,变量间的共线性机会变小,其模型形式设定如下。
第一层:
(5)
第二层:
β0j=γ00+μ0j
(6)
β1j=γ10
(7)
β2j=γ20
(8)
β3j=γ30
(9)
β4j=γ40
(10)
β5j=γ50
(11)
β6j=γ60
(12)
将第二层的参数代入第一层,得到混合模型为:

(13)
其中,εij~N(0,σ2),μoj~N(0,τ00),并且COV(εij,μ0j)=0

从模型一的回归结果可以看出,平均收入的估计值为17 912.3,比零模型略大。在固定效应部分,互联网使用程度对居民收入的影响显著为正,估计值为1 679.1,说明居民收入随着其对互联网使用程度的增加而增加。但城乡类别对居民收入的影响显著为负,估计值为-408.6,说明城镇居民的工资水平比农村居民低,这一点与实际不符,可能是由于微观数据中乡村户口的样本过多导致的。受教育程度对居民收入的影响显著为正,估计值为989.3,说明受教育程度的提升对收入有着显著的促进作用。性别估计值为正,说明男性比女性在劳动力市场上更具优势,收入更高。工作经验的估计值为负,工作经验平方的估计值为正,说明居民收入随着工作经验的增加先减少后增加,呈现“U”型趋势,主要原因在于此次微观数据中的被访者,大多数人还未开始工作,或刚刚进入工作岗位还未积累足够可以提升自身人力资本的工作经验,只有到达一定年龄阶段后,收入才会随着工作经验的增长而增长。
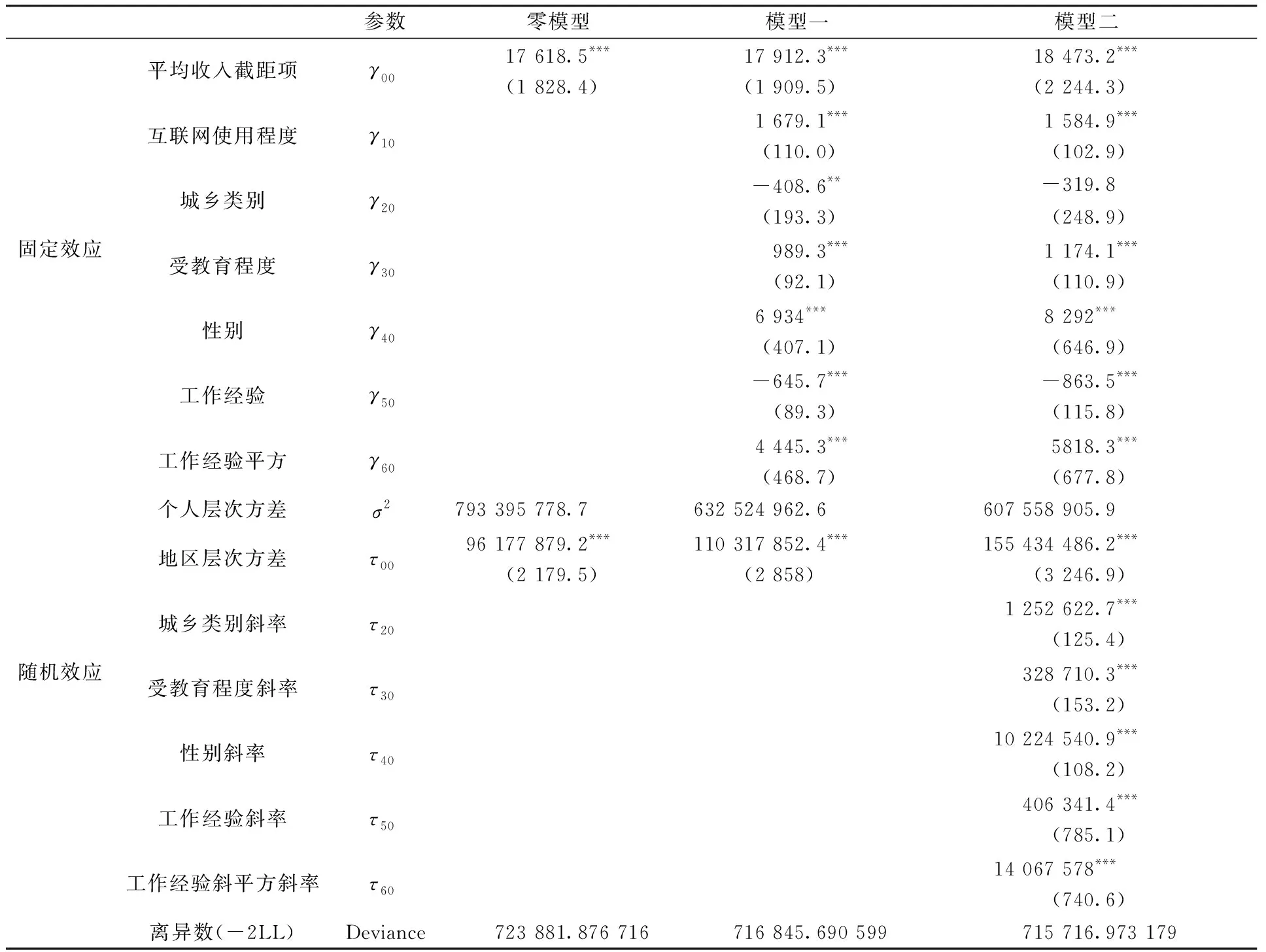
表3 零模型、模型一和模型二的回归结果
在方差分析和离异数分析中,可以计算方差缩减比例得出居民收入在组内差异和组间差异的解释程度。零模型和模型一的地区层次方差τ00的估计值分别为96 177 879.2和110 317 852.4,相对增加了14.7%;零模型和模型一的个人层次方差σ2的估计值分别为793 395 778.7和632 524 962.6,相对于零模型,模型一的方差相对减少了26.45%,说明控制第一层模型自变量之后,可以降低居民收入26.45%的变异程度。从整体上看,零模型和模型一的离异数分别为723 881.9和716 845.7,减少7 036.2,说明模型一对数据的契合度更好。
2.2.3 模型二:随机回归系数模型
接下来,在模型一协方差模型的基础上,将第一层模型中的截距项和斜率项在第二层模型中都设定为随机效应,即第一层回归模型中的回归系数都是可以随机变动的,建立包含随机效应的分层随机回归系数模型,进一步研究含有随机效应的个人特征对居民收入的影响,其模型形式设定如下。
第一层:
(14)
第二层:
β0j=γ00+μ0j
(15)
β1j=γ10
(16)
β2j=γ20+μ2j
(17)
β3j=γ30+μ3j
(18)
β4j=γ40+μ4j
(19)
β5j=γ50+μ5j
(20)
β6j=γ60+μ6j
(21)
将第二层的参数代入第一层,得到混合模型为:
(22)
其中,εij~N(0,σ2),μkj~N(0,τk0),并且COV(εij,μkj)=0,k=0,…,6,通过运用软件进行分析的回归结果如表3所示。
从模型二的回归结果可以看出,模型二的平均收入的估计值为18 473.2,比零模型和模型一要大,但是相差不大。在固定效应部分,除了城乡类别以外,互联网使用程度、所受教育程度、性别、工作经验、工作经验平方的斜率估计值对收入的影响都达到了1%的显著性水平,具体的含义也同模型一相同。在随机效应部分,因为模型设定中各地区间的回归线截距和斜率可以随机变动,所以受教育程度、性别、工作经验、工作经验平方斜率的方差比收入项小,达到了1%的显著性水平,说明地区间差异对各地区收入水平具有一定影响。
在方差分析和离异数分析中,模型二的个人层次方差σ2的估计值变小为607 558 905.9,与模型一相比减少了3.9%,这说明加入第一层随机效应后,对个人层次方差的改善幅度为3.9%。模型一和模型二的离异数分别为716 845.7和715 716.9,减少1 128.8,总体上来看,模型二比模型一对数据的契合度要好。
2.2.4 模型三:完整模型
最后,在之前模型的基础上,共同引入个人层次和地区层次的所有变量,建立模型三完整模型,研究个人层次变量和地区层次变量对居民收入的共同影响。此时,第一层模型中包括个人层次的自变量,第二层模型包括地区层次的自变量,并且第二层模型的因变量是第一层模型的回归系数,其模型设定形式如下。
第一层:
incomeij=β0j+β1j(internet)+β2j(urban)+
β3j(edu)+β4j(gender)+β5j(exp)+β6j(exp2)+εij
(23)
第二层:
(24)
(25)
(26)
β3j=γ30+μ3j
(27)
β4j=γ40+μ4j
(28)
β5j=γ50+μ5j
(29)
β6j=γ60+μ6j
(30)
其中,εij~N(0,σ2),μkj~N(0,τk0),并且COV(εij,μkj)=0,k=0,…,6
将第二层的参数代入第一层,得到混合模型为:
urban+γ30*edu+γ40*gender+γ50*exp+γ60*
exp2+u0j+μ2j*urban+μij*mternet+μ3j*
edu+μ4j*gender+μ5j*exp+μ6j*exp2+εij
(31)
在混合模型中可以看出,前12项属于模型的固定效应部分,后7项与随机扰动项有关的属于模型的随机效应部分。另外,γ11、γ21都代表了跨层级的交互作用对收入的影响,反映了地区层次变量通过个人层次变量施加给居民收入影响的调节效应,即第二层模型自变量通过第一层模型自变量对第一层模型因变量产生的间接影响。通过运用软件进行分析的所有回归结果汇总如表4所示。
通过对完整模型的回归结果分析,可以得出如下结论。
第一,互联网的使用程度对居民收入产生显著的正向影响,估计值为1 414,说明居民收入随着其对互联网的使用程度的增加而提高。
第二,个人特征对居民收入的影响方面,居民受教育程度对其收入产生了显著的正向影响,估计值为988.2,这说明居民收入会随着其受教育水平的提高而增加。性别对收入产生了显著的正向影响,估计值6 895.8,说明在当前劳动力市场上,男性比女性更有优势,能够获得更高工资。工作经验对收入的影响系数为负,估计值为-635.7,工作经验的平方对收入的影响系数为正,估计值为4 415.1,这说明随着年龄与工作经验的增长,居民收入随着工作经验的增加先减少后增加,呈现出“U”型趋势。主要原因在于,此次CFPS微观数据中的被访者大多数人还未开始工作,或刚刚进入工作岗位还未积累足够可以提升自身人力资本的工作经验,只有到达一定年龄阶段后,收入才会随着工作经验的增长而增长。但城乡类别相对于其他变量对收入的影响为负,估计值为-363.8,即城镇居民的工资水平比农村居民低,这一点与实际不符,主要原因在于样本中乡村样本数据较多。
第三,地区特征对居民收入的影响方面,人均地区生产总值的回归系数为正,估计值为13 911.7,说明经济发展水平越高的地区居民收入越高。数字经济发展水平代表该地区网络基础设施的建设能力,估计值为4 806.1,说明地区数字经济发展水平对收入也有正向促进作用。其中,具有跨层级交互作用的交互项估计值为970.4,表明数字经济发展水平与居民互联网使用对居民收入产生正向交互影响,即地区层次的数字经济发展水平会对个人层次的居民互联网使用程度产生正向影响,进而促进居民个人收入水平的提高,存在间接传递的调节作用。在其他条件不变的情况下,个人所处地区的数字经济发展水平每增加1个单位,该地区互联网使用程度对居民收入的影响会比处于平均数字经济发展水平的地区多增加970.4个单位的斜率。也就是说,一个地区数字经济发展水平越高,那么个人对互联网的使用程度就越高,居民的个人收入也会越高。
第四,在方差分析和离异数分析中,通过比较模型三完整模型与零模型可以发现,与零模型相比,完整模型的个人层次组内方差解释程度减少了20.59%,地区层次组间方差解释程度减少了80.32%,说明完整模型中引入第一层自变量和第二层自变量后,模型能更好地解释了居民收入的个人层次差异和地区层次差异。完整模型的离异数在各个模型中最小,所以完整模型对数据的契合度最好。

表4 零模型、模型一、模型二和模型三的回归结果
由以上所得的结果可知,个人对互联网的使用程度,不仅可以直接影响居民个人收入水平,同时也受到地区特征的束缚,即地区数字经济发展水平,会通过影响居民个人互联网的使用对居民收入产生调节作用。
3 结论与建议
3.1 结论
通过依次建立零模型、协方差模型、随机回归系数模型和完整模型等分层线性模型,分析了数字经济发展水平与个人互联网使用程度对居民收入的影响。研究结果表明:居民对互联网的使用、受教育程度、性别和工作经验均会对居民收入产生正向影响,人均地区生产总值和数字经济发展水平也会对收入产生显著的正向影响。与此同时,地区层次的数字经济发展水平会对个人层次的居民互联网使用产生正向调节效应,进一步促进居民个人收入水平的提高。
3.2 建议
由于我国地区间数字经济发展不平衡,东中西地区存在较大差异,同时居民个人的人力资本和对互联网使用能力也有所差异,为促进居民收入水平提升,本文提出以下建议。
第一,缩小各地区的数字经济发展差距,加强内陆欠发达地区的数字基础设施建设。财政应适度倾斜支持中西部落后地区,在全国建立现代化程度高、运作架构完善的综合信息网络体系,确保数字信息基础设施在协调区域经济发展方面发挥更大的作用。
第二,降低劳动者的网络使用门槛。由于劳动者互联网使用能力差异较大,政府应该开展大量的互联网技能培训课程,提升低技能劳动者对互联网的基本使用能力,降低不同群体间的“数字鸿沟”。
第三,提升劳动者的人力资本水平。由于劳动者的受教育程度和工作经验对居民收入有正向影响,因此政府应该扩大高等教育规模,增加技能培训课程,以提升居民劳动技能,同时消除男女在劳动力市场上的性别歧视,建立新的劳动保护法律法规,缩小男女工资差异,以促进居民收入的协调增长。
