基于交叉过采样的软件自承认技术债识别方法
2020-11-17徐克辉于化龙
黄 城,徐克辉 ,郑 尚, 于化龙*
(1. 江苏科技大学 计算机学院, 镇江 212100)(2. 中国舰船研究所,北京 100101)
技术债(technical debt,TD)[1-2]是经济学反映技术折中的一种隐喻说法.该隐喻被引入软件开发过程中,开发者为了追求项目短期利益,可能会有意选择捷径尽快完成代码实现.然而,过多的TD会对软件长期的健康发展造成不可预知的影响.随着软件系统越来越复杂,技术债受到了工业界和学术界的重点关注.
为了防止累积的技术债对软件质量造成损害,近年来,学术界展开了技术债的识别研究,通过静态源代码分析来检测技术债.文献[3]提出自承认技术债(self-admitted technical debt,SATD)的概念,指出开发人员清楚当前实现不是最优方法,并通过代码注释标识.例如,通过打开开源项目“JEdit”,能够发现某些评论描述“Need some format checking here”,这表明相应的代码有缺陷,需要捕获格式异常.文献[4]指出尽管项目中SATD的数量不多,但它仍将对软件复杂性产生负面影响.因此,文献[5]基于文本挖掘的方法来自动识别代码注释中的SATD,通过构建多个分类器,预测目标项目的SATD.
针对SATD识别,由于代码注释中SATD数量较少,数据集明显出现类不平衡问题,将严重影响分类器性能,但现有方法并没有考虑上述问题对识别结果的影响.因此,文中针对文本数据的特点,提出一种基于交叉过采样的方法,将源代码的SATD评论切成短词样本,并通过交叉组合生成新的SATD,继而扩展SATD样本数量,缓解数据集的类别不平衡问题,同时利用特征选择方法构建多个多项式朴素贝叶斯(naive Bayes multinomial, NBM)分类器,并对多个分类器结果进行集成投票决策,从而提高了SATD识别的准确率.
1 类别不平衡问题描述
类别不平衡问题,是指当数据集中某一类或某几类的样本数远多于或远少于其他类的样本数,进而导致所建立的预测模型忽略少数类性能的问题.
常用的类别不平衡学习策略主要包括:样本采样方法[6]、代价敏感学习算法[7-8]、阈值策略[9-10]及集成学习算法[11-12]等.其中,样本采样方法以其简单性及与分类器无关的特性而备受研究者青睐.因此,文中采用样本采样的方法来解决不平衡的SATD识别问题.
样本采样是通过增加少数类或减少多数类样本的方式使训练样本集在类分布上趋于平衡,其中,增加少数类样本的策略被称为过采样,而减少多数类样本的策略则被称为降采样.最简单的采样策略是随机降采样(random undersampling,RUS)和随机过采样(random oversampling,ROS),前者随机删除多数类样本,后者则对少数类样本进行随机拷贝,来增加其规模.研究发现RUS易导致大量信息损失,尤其在不平衡比率较高时,其性能将完全无法得到保证,而ROS则会易于使分类器陷入过适应,从而影响到其泛化性能.为了解决ROS的缺陷问题,文献[6]提出一种经典的改进算法,即少数类合成过采样技术(synthetic minority oversampling technology,SMOTE)算法,该算法通过在临近少数类样本间的连线上随机生成伪样本的方式,大幅提升了少数类样本集的多样性,并降低了训练出过适应模型的风险.
近年来,新的过采样算法层出不穷,但一直没有脱离出SMOTE算法的思想范畴.然而,此类算法有一个基本的限制条件,即样本的特征空间必须在实数域上可度量,其对于软件代码评论这样的文本数据并不适用.因此,对于SATD识别这类人物,就需要从全新的角度入手,设计具有高适应度的过采样算法.
2 实验方法
2.1总体设计框架
图1为文中方法的整体框架,图中可以看出,SATD识别系统主要由3个模块顺序组成,分别为数据预处理模块、特征构建与选择模块以及决策模型构建模块.这3个模块顺序执行,共同完成SATD样本的识别工作.
上述模型的主体继承了文献[5]提出的框架.唯一的不同之处在于文中考虑到了样本分布不平衡的影响,故增加了切分短文本、构建文本池与交叉过采样的步骤.
2.2交叉过采样策略
文中基于文本数据特点,借鉴了遗传算法中交叉算子的构造思想[13],设计一种交叉过采样算法,用以生成大量虚拟的SATD伪样本,同时在最大限度上避免后期建模中过适应现象的出现.
假设有两条完整的文本段A和B,其中A由两个短文本A1,A2顺序组成,B则有B1,B2顺序组成,则其可表示为:
A=A1A2
B=B1B2
所谓交叉过采样,即是将A,B之间后半段的短文本进行互换,组成新的完整文本段,即:
AB=A1B2
BA=B1A2
式中:AB与BA为新生成的文本样本.
在实际应用中,考虑到代码评论的文本结构更繁杂,有的评论可能只包括一个短文本,而有的则由多个短文本组成,故上述策略可能会受到文本样本这一构造特点的影响.为此,文中通过构建短样本池,将所有的SATD样本均切分为短样本,并置于池中,再从中随机进行选取,来生成虚拟的伪样本.

图1 总体设计框架Fig.1 Framework of the method proposed in this article
举例来讲,对于一条SATD评论:“TODO:Do we really need to do this? Carried over from old behavior”,在切分短文本时,其会被分割为“TODO:Do we really need to do this?”和“Carried over from old behavior”两个短文本,而对于另一条SATD评论“Need some format checking here”,则其不用切分,直接可以看做是一条短文本,当将它们均置于短文本池中时,若采用交叉过采样策略,则可能会生成类似于“TODO:Do we really need to do this? Need some format checking here”以及“Need some format checking here, Carried over from old behavior”这样的虚拟伪样本,尽管可能其在上下文语义上未必能解释,但却切实地提升了样本多样性,降低了后期建模出现过拟合的风险.
在采样过程中,还需定义一个重要参数,即采样率SR,其取值通常在[0,1]之间,并直接决定了需要生成的伪样本个数.其对应的计算公式为:
(1)

2.3文本预处理
预处理文本数据,可以为后续的特征构建提供帮助.文中采用了3个步骤来对文本样本进行预处理操作.
(1) 切词:将文本分解为单词、短语、符号或切分为其他有意义的元素的过程.文中的切词选择以单词为基本元素,即将每一个单词均切分出来,同时为了保证单词表示的唯一性,将所有切分出的单词中的大写字母作小写化处理.
(2) 停用词处理:停用词表示那些难以用于区分不同类别样本的词汇,通常这些词汇没有具体的实际意义,如介词等.文中已最大限度地筛选出停用词,同时对于少于两个字母或多于20个字母的词汇,视为停用词作删除处理.
(3) 词干提取:将变形词提取或者还原到词干、词基或词根形式的过程.文中也调用了词干提取的工具包,对所有评论数据进行了处理.
2.4特征构建、选择与基分类器构建
文中继承了文献[5]中所采用的特征构建特征、特征选择以及基分类器构造等方法.其中,采用词向量空间模型(vector space model,VSM)[14]表示每条评论.在VSM中,每个词对应于一个特征,由于评论中出现的词量较大,故导致特征空间的维度也较高,可能会造成“维数灾难”的问题,故需进一步采用特征选择方法来对其进行降维处理.文中继承了文献[5]中的方法,采用信息增益的特征选择方法[15]来筛选那些比较重要的特征.
在经过特征选择后的特征空间上,文中采用多项式朴素贝叶斯分类器[16]作为建模工具,来区分SATD与Non-SATD样本.选用NBM的原因在于它将每一维特征单独拆分开进行处理,可以有效地节省建模时间开销,同时前人工作也已发现,在处理文本数据时,NBM比传统的朴素贝叶斯(naive Bayes, NB)分类器的识别率也更高[17].
2.5集成分类器构建
SATD评论数据往往由多个不同的项目组成,每个项目都是一个独立的数据集,故应采用集成学习的框架来构造最终的决策模型,其中,每一个项目应单独训练一个基分类器.
文中采用了Bagging集成学习的框架来构造SATD预测模型,对于每一个源项目,均独立执行交叉过采样、文本预处理、特征构建与选择的过程,并为其单独训练一个NBM分类器.最后,采用多数投票的方式来构造集成决策模型.
2.6算法描述
文中算法流程与实施步骤描述如下:
输入:n个源项目集,采样率SR
输出:集成预测模型C
步骤:
(1) Fori=1:n
(2) 针对第i个源项目,对其SATD样本与Non-SATD样本进行划分;
(3) 将SATD数据分割为短文本,构造短文本池;
(4) 根据预设的SR,采用交叉过采样策略生成对应数量的SATD伪样本;
(5) 将新生成的SATD伪样本加入源项目中;
(6) 使用文本预处理技术进行切词、处理停用词并提取词干;
(7) 采用VSM模型构造词向量空间;
(8) 采用信息增益算法进行降维;
(9) 在降维后的数据上训练得到一个分类器,记为NBMi;
(10) End For
(11) 构造集成分类器C={NBM1, NBM2,…, NBMi}
在决策时,目标项目中的评论也需经过文本预处理,并转化进入词向量空间,保留与各基分类器相对应的特征,最终再由集成决策模型C给出对应的预测结果.至于交叉过采样策略,只需在训练时执行,在决策时则无需执行.
3 实验结果与分析
3.1 数据集与实验设置
实验采用与文献[5]完全相同的8个SATD评论数据集(表1).这些数据集虽然所采用编程工具的版本号不同,包含的评论数与SATD的数量也不同,但存在一个共同特点,即SATD评论在所有评论中的占比均较小,这是典型的类别不平衡问题.

表1 所用数据集Table 1 Data sets used
从表1可以看出,在每个数据集中,其样本数在2 492~5 426不等,SATD数在101~969不等,而SATD样本在所有样本中的占比最高只有17.8%,在某几个数据集上,占比甚至低于5%.
为了验证文中算法的有效性与优越性,与文献[5]的基线方法以及随机过采样ROS算法进行实验比较.特别需要指出的是,在实验中,ROS算法及文中算法的采样率SR均根据经验预设为0.5,而其他算法步骤中的参数设置均与文献[5]中的设置保持一致,保证了实验结果比较的公正性.
3.2 性能评价测度
与文献[5]一致,文中也采用查准率(Precision)、召回率(Recall)及F1分数(F1-score)这3个度量测度对各类算法的性能来进行评价,其实际含义与计算公式如下.
查准率 表示在预测为SATD的评论中真实的SATD评论的比例为:
Precision=TP/(TP+FP)
(2)
召回率 表示在真实的SATD评论中被预测为SATD评论的比例为:
Recall=TP/(TP+FN)
(3)
F1分数 表示查准率和召回率之间的调和比例为:
(4)
式中:TP、FP及FN等评价指标的含义如表2.
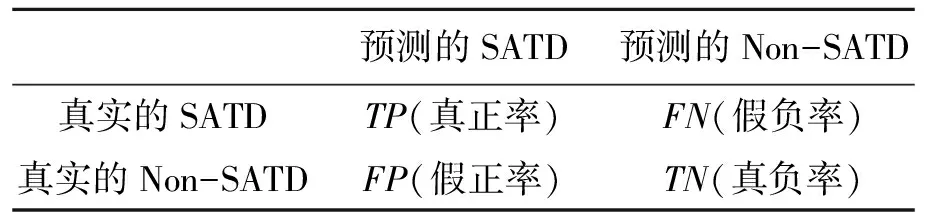
表2 混淆矩阵Table 2 Confusion matrix
3.3实验结果比较
表3给出了文中方法与基线方法和ROS算法在3个不同性能度量测度上的比较结果.基于表3中的实验结果,可以得出结论:
(1) 相比于基线方法,文中提出的交叉过采样算法可以提升分类的查准率,特别是在类别不平衡比率较高的数据集上,如Columba、JEdit、JFreeChart、JMeter及SQuirrel等,查准率相比于基线方法,均有较大幅度提升.此外,文中算法在8个数据集上平均的查准率(0.756)相较于基准算法(0.841),提升了11.24%.
(2) 在召回率测度上,文中方法的性能不但低于基准方法,而且相较于ROS算法,也有较大差距,特别是在那些不平衡比率较高的样本集上,这一现象更为突出.不过这是可以接受的结果,因为查准率与召回率是两个相对矛盾的度量测度,其中一个提升,几乎必然伴随着另一个的下降[18].
(3) 在F1分数这一度量测度上,文中方法获得了最高的平均结果.相较于基准方法的0.737,文中方法获得了0.756的F1分数测度值.特别值得注意的是,在大部分高度不平衡的数据集上,如Columba、JEdit、JFreeChart、JMeter,文中方法均得到了最高的F1分数测度值.这一结果表明:文中所提出的交叉过采样策略有助于调节查准率与召回率之间的关系,使之更为平衡.同时,自承认技术债的识别确实会受到样本分布不平衡的影响,而采用有效的类别不平衡学习技术可以切实提升其性能.
(4) 相比于ROS算法,文中算法无论在查准率还是F1分数测度上均显示出了明显的优势,进而表明交叉过采样策略可有效地避免建模时过适应现象出现.事实上,ROS在各评价测度上的表现甚至均低于基准算法,这也再一次地证明随机过采样会导致模型过拟合,进而降低其泛化性能.
总而言之,通过对表3中的实验结果进行分析,可以发现文中提出的交叉过采样策略是有效的、可行的,以及优越的.

表3 各类算法的性能比较Table 3 Performance comparison of various algorithms
3.4 采样率变化对算法性能的影响
文中通过实验研究采样率取值变化对算法性能的影响及影响规律.图2为3种不同性能测度值随采样率变化而变化的曲线.特别地,采样率的取值范围为[0.1, 1.0],每次调整的补偿为0.1.
从图2可以观察到,3种性能测度值随采样率变化的规律几乎是一致的.当采样率较低时,由于补充的伪SATD样本不够充足,因而各种性能测度值均较低.随着采样率提升,各种测度值均会快速提升,直至采样率到达0.5,继续增加采样率,性能提升将会逐渐放缓.当采样率达到0.9时,各种性能测度值均会达到峰值.在这一时刻,若进一步增加采样率,性能不但不会得到提升,反而会有一定程度下降.根据实验结果的反馈,用户在实际应用中不宜将采样率设置过大或过小,取一个居中值较合理.

图2 不同采样率下的分类性能Fig.2 Classification performance atdifferent sampling rates
4 结论
对软件技术债进行精确识别对于代码重构以及系统的长期维护和二次开发都具有重要意义,是软件工程中重要研究课题之一.文中关注到软件技术债数据中所存在的样本分布不平衡问题可能会对所建立的预测模型产生较大的负面影响.进而,结合文本数据自身的特点,提出了一种交叉过采样策略,并将其融入现有的识别算法中,提升了预测的准确率以及算法泛化性能.实验结果证明了该算法的有效性、可行性以及优越性.
