基于改进YOLOv2的白车身焊点检测方法
2020-11-14何智成王振兴
何智成,王振兴
(湖南大学 汽车车身先进设计制造国家重点实验室,长沙 410082)
0 概述
白车身焊点质量对汽车的性能有着重要的影响,焊点质量检测决定着白车身性能的可靠性。目前大部分的白车身焊点手动检测需要耗费大量的人力资源,效率低下。采用自动化的检测可以提升焊点检测的效率,焊点检测系统采用传统图像处理、霍夫圆变换的检测方法[1]受环境的影响较大,在光照过亮、过暗或者焊点有污渍的情况下检测效果不理想,且焊点轮廓不是标准的圆形,增大了霍夫圆变换检测方法的检测难度。
近年来,很多研究机构与研究者对基于深度学习的目标检测算法进行研究。文献[2]提出了R-CNN目标检测方法,该方法使用卷积神经网络进行目标检测,但是检测时间过长。文献[3]提出了Fast R-CNN,将卷积特征提取、目标分类、边框回归融合为一个阶段,大幅节省了检测时间。文献[4]提出了Faster R-CNN,该方法将区域建议、卷积特征提取、目标分类、边框回归融合到一个网络中,在检测性能上有很大的提升。R-CNN、Fast R-CNN、 Faster R-CNN等方法的思路都是基于区域建议的目标检测方法,虽然速度有了很大提升,但是仍然难以满足实时性的要求。文献[5]提出了YOLO目标检测算法,该算法在速度上大幅提升。文献[6]提出了SSD目标检测模型。文献[7]在YOLO的基础上结合了SSD、Faster R-CNN的锚框机制,提出了YOLOv2检测模型。YOLOv2在速度和精度上相比YOLO都有一定提升。为提升小目标检测能力,文献[8]结合FPN[9]特征金字塔的方法提出了YOLOv3目标检测算法,采用多尺度预测提升了小目标检测能力。
目前有很多学者对YOLOv2目标检测算法进行了研究并且应用于各个领域,文献[10]采用YOLOv2目标检测算法进行了车辆的实时检测。文献[11]采用YOLOv2目标检测算法进行无人机航拍图定位研究。文献[12]采用YOLOv2进行红外图像行人检测研究。文献[13]采用DenseNet[14]的方法对YOLOv2进行改进,构建Tiny-yolo-dense,并应用到了芒果检测中。文献[15]在YOLOv2的基础上,提出使用更少的卷积层和去除卷积神经网络中批量标准化层的方法,得到轻量实时的目标检测模型YOLO-LITE。文献[16]采用去除YOLOv2的两个连续的3×3×1 024的卷积层的方法对YOLOv2进行改进得到了YOLOv2-Reduced,从而减少模型参数,提高运行速度,并且在SAR图像船只检测中得到了良好的应用。文献[17]提出去除YOLOv2最后两个3×3×1 024的卷积层以减少模型参数,使用三层特征融合的方法进一步提高模型的检测精度,并构成YOLOv2_Vehicle。可见,在目前的YOLOv2改进方法中,最常用的是对YOLOv2的卷积神经网络模型结构进行改进和优化,以满足研究对象所需要的速度和精度要求。卷积神经网络模型决定着目标检测算法的精度与速度,目前常用的卷积模型中有VGG[18]、GoogLeNet[19]、ResNet[20]和DenseNet[14]等,这些网络往往是模型较大,参数较多,运行速度较慢。为解决这一问题,文献[21]提出MobileNet,并给出了深度可分离卷积的概念,以减少模型参数,加快运行速度。为进一步提升模型精度,文献[22]提出了MobileNetv2,相比于MobileNet,检测精度更高。
为提高焊点位置检测效率,本文综合考虑目前常见的YOLOv2改进方法及深度分离卷积的作用,用MobileNetv2替换YOLOv2卷积层,同时采用细粒度特征的方法将不同层的特征进行融合,运用GIoU loss[23]改进损失函数并进行训练比较,构建一个轻量的焊点检测模型FGM_YOLO。
1 YOLOv2目标检测算法
YOLOv2目标检测算法是一种单阶段目标检测方法,其检测流程如图1所示。本文设置输入图片大小为224×224,将图片划分为7×7的网格,每个网格预测5个预测框,然后去掉置信较低的预测框,最后经过非极大值抑制[24]得到最后的预测结果。

图1 YOLOv2算法检测流程
1.1 网络结构
YOLOv2的模型结构如图2所示。输入图片经过一系列的卷积、最大值池化操作,之后将低层特征进行重整操作与高层卷积的特征进行融合,随后进行两次卷积操作,最后送入检测层。YOLOv2采用这种细粒度特征的方法,使得深层的特征引入了浅层的特征。由于浅层特征的感受野更小,具有更高的分辨率,而且浅层特征包含物体的轮廓信息,深层特征包含了丰富的语义信息,因此采用深层特征与浅层特征融合的操作使得YOLOv2模型的检测效果更好。

图2 YOLOv2模型结构
1.2 损失函数
当输入图片大小为224×224时,YOLOv2模型的特征提取层最终输出特征为7×7×B(C+5)。共7×7个网格,各网格有B个锚框(anchor),每个anchor有位置和置信共5个参数,C为检测类别数。模型损失函数如式(1)所示:
(1)
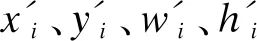
YOLOv2的损失函数包括位置损失、背景置信损失、前景置信损失和类别损失。首先计算anchor与真实框的交并比(Intersection over Union,IoU),这里计算IoU时只考虑anchor与真实框的形状。将IoU最大的anchor与真实框匹配。匹配的anchor预测结果与真实框相比得出类别、位置以及有物体的置信损失(前景损失)。式(1)的第1项为位置损失,(2-wihi)表示根据真实框的大小对位置损失权重进行修正。式(1)的第2项为无物体的置信损失(背景损失):无物体处的真实置信为0,把预测框与真实框的IoU小于阈值的预测框作为背景,另外其他大于阈值但是没有与真实框匹配的预测框忽略不计算损失,这里阈值取0.6。此时IoU的计算考虑预测框与真实框的位置和大小,IoU示意图如图3所示,其中左下侧框为真实框位置,右上侧框为预测框位置,真实框与预测框的交集面积为:
(2)
真实框与预测框的并集面积为:
(3)
交并比为:
(4)

图3 交并比示意图
式(1)的第3项为有物体的置信损失,有物体处的真实置信为该anchor的预测框与真实框的IoU。式(1)的第4项为有物体的类别损失,但是由于本文待检测的物体只有白车身焊点这一种类别,因此本文中的损失函数没有类别损失。
2 模型改进
虽然YOLOv2模型相比其他的目标检测模型规模较小,但是由于生产车间的工控机很少配置GPU,因此YOLOv2仍然参数过多,时效性不强,不能用于对实时性严格要求的焊点检测中。为提升焊点位置检测效率及精度,本文从卷积结构、损失函数、锚框聚类3个方面对YOLOv2算法进行了改进得到最终的FGM_YOLO模型,该模型训练流程如图4所示。
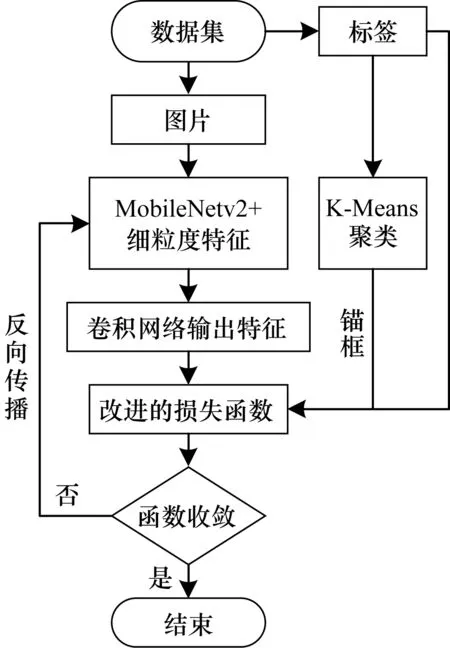
图4 FGM_YOLO训练流程
2.1 卷积结构改进
由于标准卷积的计算量以及卷积核参数比较多,ANDREW等人提出了深度可分离卷积代替标准卷积,深度可分离卷积将标准卷积分为深度卷积(Depthwise Convolution,DW)和点卷积。标准卷积及深度分离卷积的结构如图5所示。
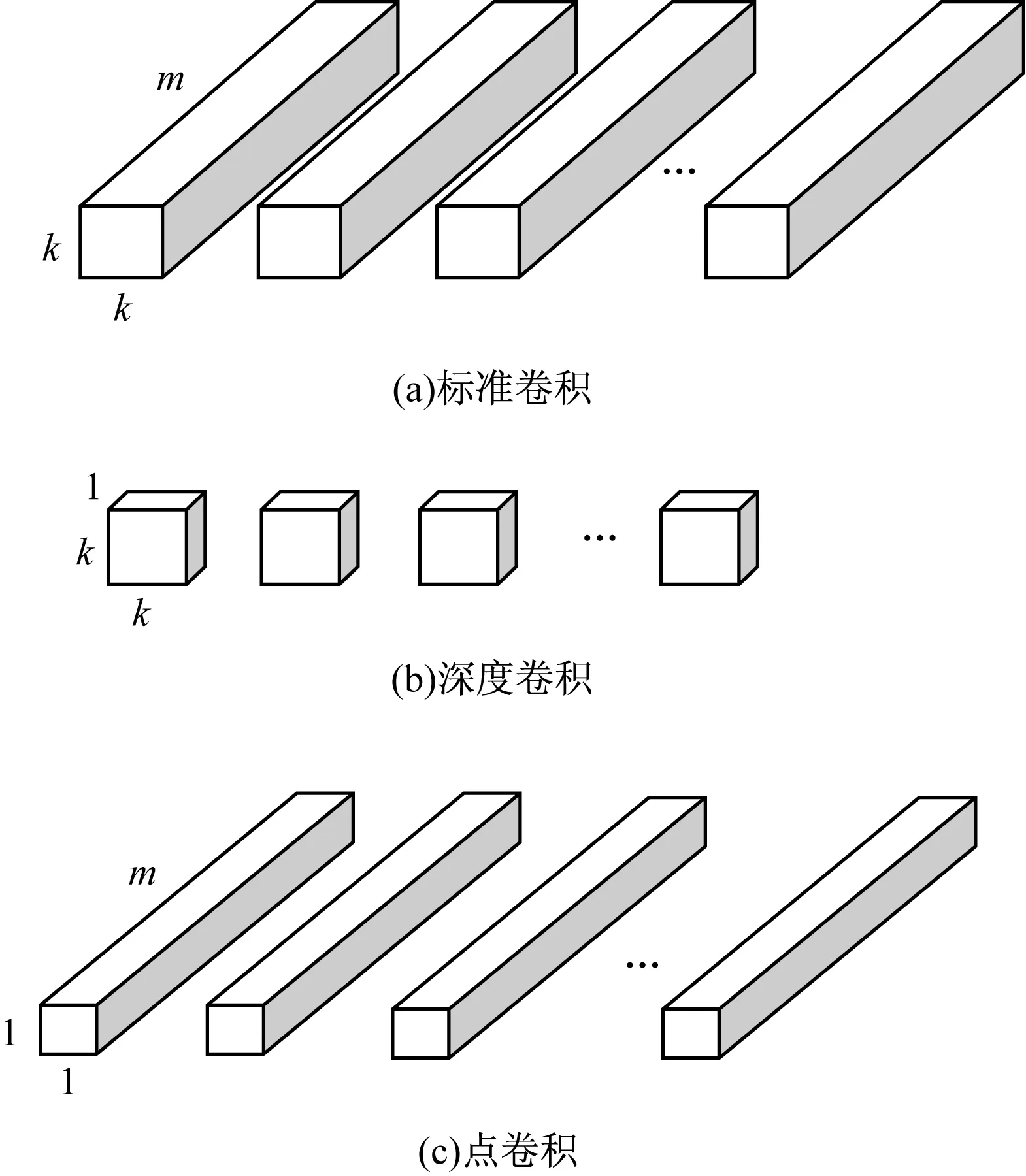
图5 标准卷积、深度卷积与点卷积结构
假设某一卷积层的输入特征为w×h×m,输出特征为w×h×n,卷积核的大小为k×k,则采用标准卷积的计算量为:
w×h×n×m×k×k
(5)
采用深度分离卷积的计算量为:
w×h×m×k×k+w×h×n×m×1×1
(6)
计算量之比为:
(7)
采用标准卷积的参数个数为:
m×n×k×k
(8)
深度分离卷积的参数个数为:
m×k×k+m×n×1×1
(9)
参数之比为:
(10)
通过对比可知,采用深度可分离卷积相对于标准卷积计算量和参数会减少。深度可分离卷积的应用将会使模型对硬件计算能力的要求降低、节省成本。
MobileNetv2模型是SANDLER等人提出的第2代轻量级模型,该模型相比于MobileNet参数更少,MobileNetv2是在ResNet的网络基础上引入了深度可分离卷积并且在残差块上进行了改进。MobileNetv2的卷积块如图6所示,卷积块输入特征通道数为cin,首先经过1×1卷积扩充为输入通道数的6倍,经过深度卷积之后通过1×1卷积进行通道压缩使通道数与输入通道相同。在残差块的最后一层卷积之后没有采用Relu激活而是采用了Linear激活以防止特征被破坏。当深度卷积的步长s=1时进行shortcut连接,如图6(a)所示。深度卷积的步长s=2时不进行shortcut连接,如图6(b)所示。
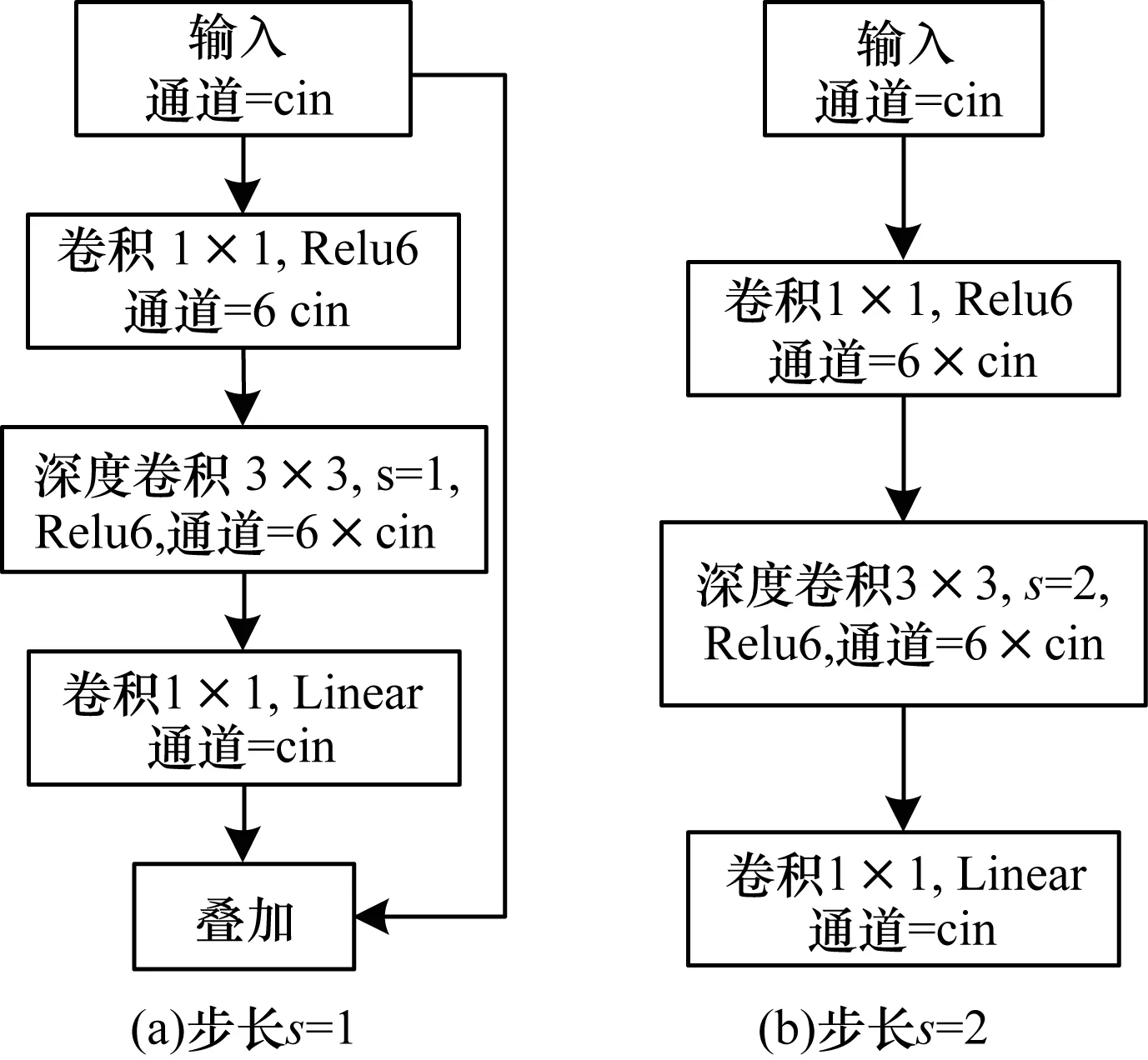
图6 MobileNetv2卷积块结构
本文用MobileNetv2卷积层代替YOLOv2的darknet19得到了M_YOLO模型。采用细粒度特征方法,将第12个卷积块的输出特征经过重整操作之后与最后一层的输出特征融合,然后经过一次卷积操作,为减少参数,该层卷积的卷积核大小为1×1。最后连接到检测层得到改进的焊点检测模型FM_YOLO,FM_YOLO模型结构如图7所示,其中,a指经过图6(a)中的卷积块结构操作,b指经过图6(b)中的卷积块结构操作,c为卷积通道数目,s为卷积步长。

图7 FM_YOLO焊点检测模型
2.2 损失函数改进
YOLOv2的损失函数相同,目标检测算法中的大小、位置损失一般为预测框长宽、位置与真实框长宽、位置的均方误差。但是在目标检测中评价一个物体是否被正确检测出,IoU是一个重要的度量标准,而且IoU对尺寸变化不敏感,直接优化IoU会有更好的结果。但是当预测框与真实框不相交时,IoU一直为0,无法进行优化。为了把IoU作为损失函数直接进行优化,HAMID等人提出了广义IoU的概念(Generalized Intersection over Union,GIoU)。GIoU能够克服在IoU<0时无法继续优化的问题,而且GIoU对尺寸变化也不敏感。本文采用GIoU代替原来的位置损失函数能够直接对度量标准进行优化,会使得位置检测更加准确。如图3所示,预测框与真实框的交集为I,预测框与真实框的并集为U,预测框与真实框的最小包围框的面积为:
(11)
GIoU为:
(12)
在FM_YOLO模型的基础上,本文将GIoU作为损失函数的一部分得到FGM_YOLO模型,FGM_YOLO模型的损失函数如式(13)所示:
(13)
2.3 K-means锚框聚类
YOLOv2目标检测算法引入了锚框(anchor),采用K-means聚类算法[25]得到anchor数量及大小。本文采用K-means算法对白车身焊点数据集进行聚类得到适合白车身焊点的anchor个数和大小。
K-means聚类算法中的K代表了聚类的类别数。在K-means聚类时,设定不同的K值不断优化距离值进行聚类。聚类anchor时距离用聚类损失loss表示,每个数据与哪个聚类中心的交并比最大即loss最小则归为哪一类,新的聚类中心为同类anchor长的均值与宽的均值。在聚类时不断优化loss直至loss收敛时聚类结束。交并比(IoU)如式(14)所示,这里计算交并比时只考虑长和宽,聚类anchor的损失函数如式(15)所示:
(14)
loss=1-IoU(b,c)
(15)
其中,b为标定的真实框,c为聚类的中心,bw、bh为真实框的宽和高,cw、ch为聚类中心的宽和高。
本文对制作的白车身焊点数据集,采用K-means聚类算法进行聚类得到候选区域anchor的数量以及大小。聚类结果如图8所示,图8为聚类损失loss、平均交并比(Average Intersection over Union,AvgIoU)随着anchor数目的变化曲线。
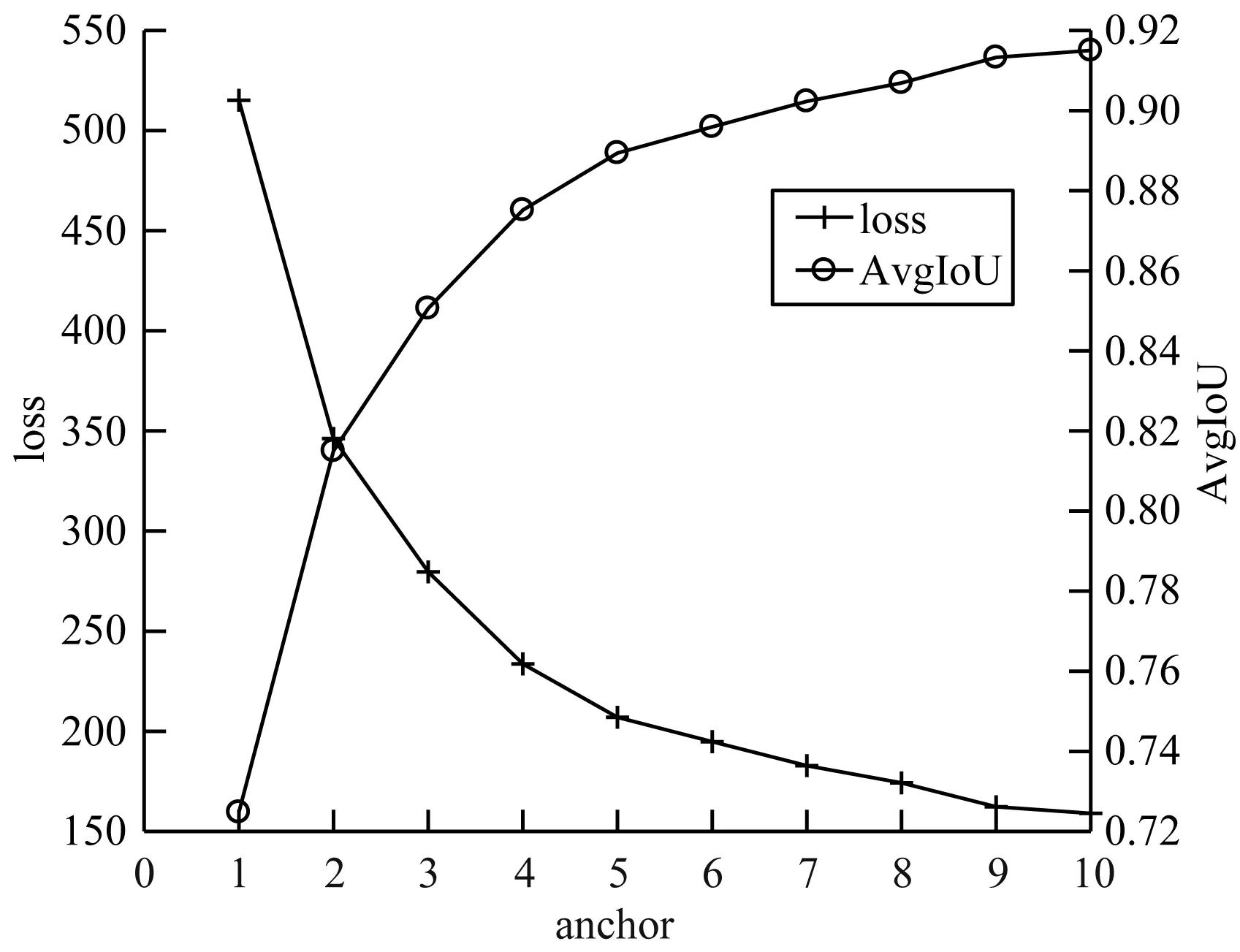
图8 聚类损失及平均交并比
根据聚类损失、平均交并比与聚类中心个数的变化曲线可以看出,当anchor个数为5时,聚类损失和平均交并比变化减缓。考虑计算精度与速度,本文对于白车身焊点数据集选用5个anchor,分别为[0.718,0.667]、[1.006,0.921]、[1.400,1.328]、[0.854,0.815]、[1.149,1.115]。
3 实验结果与分析
3.1 数据集制作
在算法的验证中,目标检测模型训练需要规范标注的数据集。由于没有现成的白车身焊点数据集,因此在实际生产车间采集了4 000张不同位置、不同光照亮度的白车身焊点图片。然后对焊点图片进行标注建立了白车身焊点检测数据集,其中3 200张白车身焊点图片作为训练集,800张白车身焊点图片作为测试集。白车身焊点图片样本如图9所示。

图9 焊点样本
3.2 训练结果
3.2.1 评价指标
目标检测模型的评价指标一般采用均值平均精度 (mean Average Precision,mAP)进行评价。mAP是所有类别的平均精度(Average Precision,AP)的均值,AP是召回率(Recall)与准确率(Precision)曲线所包围的面积,其中召回率指的是所有待检测物体中正确检测出的物体所占的百分比,准确率指的是所有检测出的物体中正确检测的物体所占的百分比。本文采用COCO[26]数据集的评价标准。对于白车身焊点,如果预测框与真实框的IoU大于阈值则认为是检测出了焊点,若预测框与真实框的IoU小于阈值则认为是没有检测出焊点。对于一个焊点若正确的检测出来则为真正类(True Positive,TP),若对于一个不是焊点的位置检测为焊点则为假正类(False Positive,FP)。设白车身焊点的总数为N,则检测的召回率为:
(16)
检测准确率为:
(17)
当召回率变化时记录当前召回率对应的最大的准确率,制作召回率与准确率的曲线图(P-R曲线)。P-R曲线所围成的面积就是当前阈值下模型的AP,设置10个IoU阈值,然后计算各个阈值下AP的均值,最终得到模型的AP。
3.2.2 实验平台及检测结果
由于Keras简单方便,本文采用Keras深度学习框架。电脑配置:显卡为1050ti 4 GHz显卡,CPU为i5-8400,运行内存为8 GB。对3 200张白车身焊点数据集进行了数据增强及训练,训练轮数为500轮,选用SGD优化器,学习为0.001,batch size为16,训练输入图片大小为224×224。分别用YOLOv2,Tiny_YOLOv2、M_YOLO、FM_YOLO、FGM_YOLO、YOLO-LITE、YOLOv2-Reduced、YOLOv2_Vehicle进行训练。训练完成后在测试集上进行测试,对模型的输出结果采用非极大值抑制之后得到最终的检测结果。
本文方法FGM_YOLO与YOLOv2、Tiny_YOLOv2及Tiny-yolo-dense、YOLO-LITE、YOLOv2-Reduced、YOLOv2_Vehicle在IoU阈值为0.75时的P-R曲线如图10所示。从图10可以看出,本文FGM_YOLO模型的P-R曲线完全包围其他模型,可知本文方法在IoU=0.75时的AP值最高。
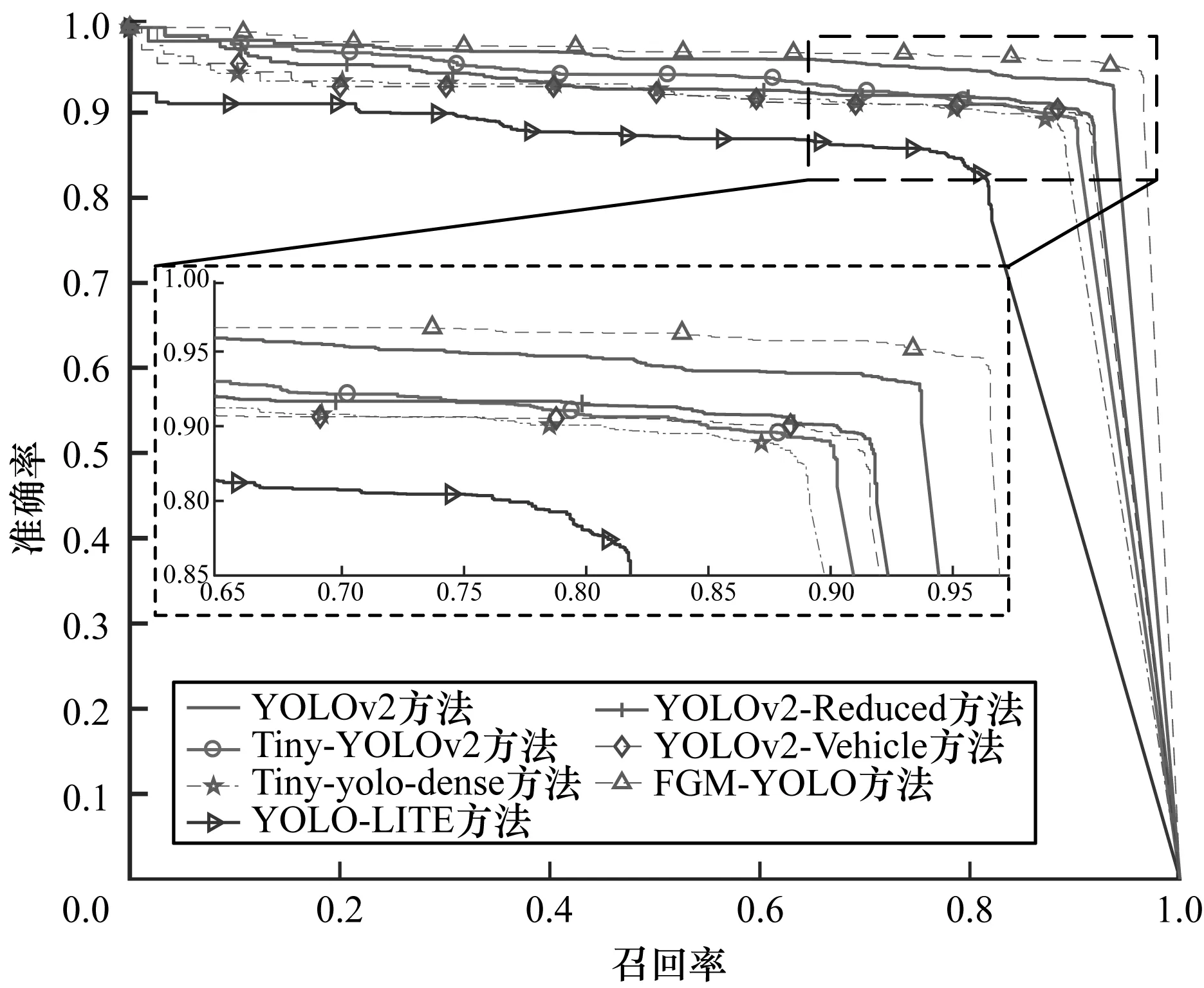
图10 不同方法P-R曲线
各个模型的检测结果及模型的参数数量如表1所示。
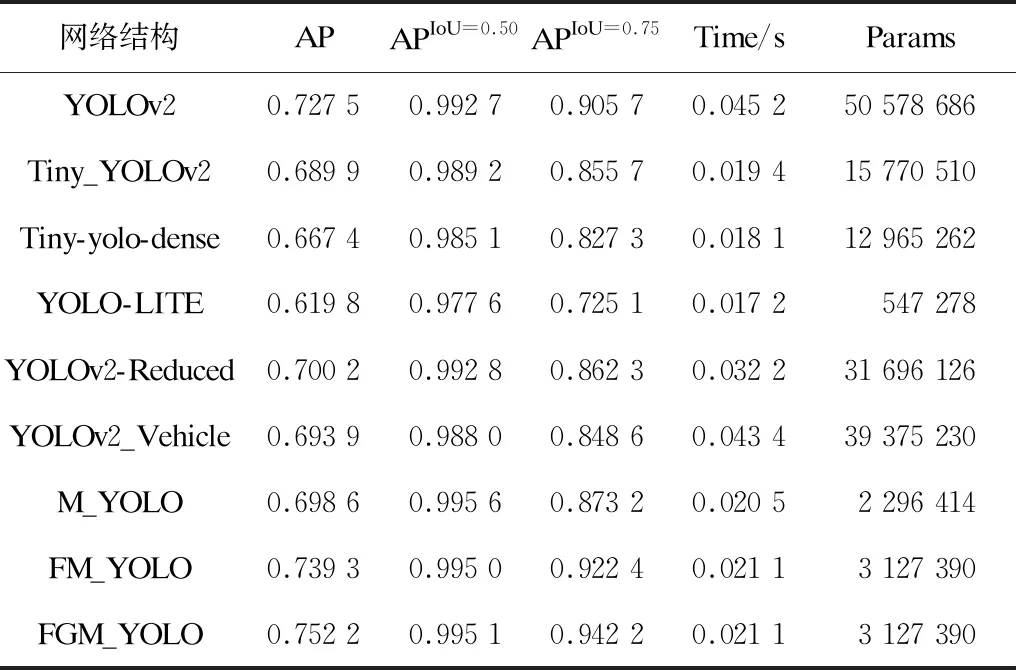
表1 不同模型结果及参数数量
由表1的测试结果可知,M_YOLO相比于原YOLOv2参数个数减少到了YOLOv2参数的1/22, APIoU=0.50提升了0.29%,但AP、APIoU=0.75下降明显。在MobileNetv2的基础上加入细粒度特征FM_YOLO的AP 、APIoU=0.50、APIoU=0.75相比于YOLOv2分别提升了1.18%、0.23%和1.67%。采用GIoU loss的FGM_YOLO的AP 、APIoU=0.50和APIoU=0.75相比于YOLOv2分别提升了2.47%、0.24%和3.65%,每张图片的检测时间约是YOLOv2的1/2,模型参数约是YOLOv2的1/16。FGM_YOLO检测速度比YOLO-LITE和Tiny-yolo-dense分别慢了0.004 s和0.003 s,但检测精度提高明显。FGM_YOLO相比于YOLOv2-Reduced、YOLOv2_Vehicle,检测精度与速度都有明显提升。另外,对比YOLOv2-Reduced、YOLOv2_Vehicle的检测结果可以发现,采用三层特征融合相比于两层特征融合,在焊点数据集上检测精度并没有提升且出现了稍微下降。
YOLOv2、Tiny-yolo-dense、YOLO-LITE、YOLOv2-Reduced、YOLOv2_Vehicle与本文提出的FGM_YOLO检测结果对比如图11所示。从图11可以看出,FGM_YOLO检测结果比YOLOv2、Tiny-yolo-dens、YOLO-LITE、YOLOv2-Reduced、YOLOv2_Vehicle漏检与误检更少。可见本文所提出的检测方法与YOLOv2及其他改进方法相比在焊点检测中有一定的优势。

图11 不同模型焊点检测结果对比
为进一步展示本文方法的效果,图12对传统图像处理检测方法(采用灰度变换、滤波、边缘检测、霍夫圆变换)的检测结果与FGM_YOLO的检测结果进行了对比。其中,图12(a)~图12(d)第1行为原图,第2行为FGM_YOLO模型的检测效果,第3行为图像处理方法的检测效果。通过比较可知,在光照过暗或光照过亮的情况下,传统的图像处理检测方法基本失效,在生锈和有污渍的情况下,传统的图像处理方法受到锈斑、污渍的影响,出现焊点检测不出或检测位置与真实位置偏离的情况。而本文提出的焊点检测方法FGM_YOLO相比于传统的检测方法受光照影响很小,检测效果更好。

图12 FGM_YOLO与图像处理方法焊点检测结果对比
4 结束语
为解决白车身焊点质量自动检测时在复杂环境下焊点图像识别与定位困难的问题,本文提出一个轻型、快速、精度更高的白车身焊点位置检测模型。将YOLOv2的卷积层替换为轻量卷积神经网络Moilenetv2,采用细粒度特征方法进行特征融合,并引入GIoU loss改进模型的损失函数,最后聚类获得适合焊点大小的anchor。通过重新训练得到了效果更好的焊点检测模型FGM_YOLO,相比原YOLOv2模型,该模型参数大量减少,检测精度提升,检测速度更快,可适用于对实时性要求严格且工控机没有GPU的车间生产线。相比于传统图像处理检测算法,本文方法受光照、污渍、锈斑等影响更小,解决了鲁棒性差的问题,检测效率大幅提升。下一步将研究更高精度目标检测算法并结合模型量化、剪枝、蒸馏等方法,扩充数据集以提高检测精度和速度。
