基于时间卷积网络的多项选择机器阅读理解
2020-11-14杨姗姗姜丽芬孙华志马春梅
杨姗姗,姜丽芬,孙华志,马春梅
(天津师范大学 计算机与信息工程学院,天津 300387)
0 概述
机器阅读理解是在限定上下文的条件下为给定问题找到答案的一类任务,它是自然语言处理的核心任务之一[1]。近年来,机器阅读理解已经成为评价人工智能系统在自然语言处理领域的一个重要应用问题,计算机语言学领域对其给予了极大的关注。传统的机器阅读理解系统主要依赖于语言注释、结构化的外界知识和语义分析[2],对专业知识的要求较高,不具备普遍适用性。随着深度学习在自然语言处理领域的广泛应用,基于深度神经网络的机器阅读理解也迅速发展[3-5]。当前机器阅读理解一般分为完形填空式、问答式和多项选择式三类。
早期基于深度学习的机器阅读理解主要是完形填空式。完形填空式任务是在机器阅读并理解一篇文章的内容后,要求机器对指定问题进行回答,而问题一般是被抽掉某个实体词的句子,机器回答问题的过程就是预测问题句子中被抽掉的实体词,且一般要求被抽掉的实体词在文章中出现过。2015年,大型的完形填空阅读理解数据集CNN/DailyMail[2]和CBT[6]的相继公布为机器阅读理解提供了丰富的语料,基于深度学习的机器阅读理解方法也随之得到广泛应用。文献[7]将注意力机制应用于机器阅读理解,并提出了经典的ASReader模型。文献[8]基于多跳结构提出门控注意力模型。文献[9]提出用于机器阅读理解的迭代交替注意力机制。但是有学者对CNN/DailyMail进行详细评估后发现,该类任务需要处理的逻辑相对简单,现有的针对完形填空式任务的机器阅读理解方法基本已经达到了该类任务的准确度上限[10]。
由于完形填空式任务的解决相对简单,学者们试图构造出更加复杂的阅读理解数据集来增强机器对文本的推理,而近年来问答式阅读理解数据集SQuAD[11]和NewsQA[12]引起了广泛关注,问答式机器阅读理解也随之兴起。问答式任务是在给定文章和问题的条件下,机器阅读进行一定的推理,进而预测出正确答案,且正确答案一般是文章中的文本段。目前,很多有效的机器阅读理解模型已经被应用于问答式任务,文献[13]使用双向注意力机制对文章和问题进行匹配,并构建了BiDAF模型。文献[14]将自匹配注意力机制应用于序列的自关注,提出自匹配网络。文献[15]将卷积神经网络、多头注意力机制和前馈神经网络相结合作为编码器,并提出QANet模型,但是由于问答式任务中正确答案是文章中的文本段,一般通过检索出答案的开始位置和结束位置即可得到答案,因此多数面向问答式任务的模型主要关注浅层的语义,并不适用于更深层次的推理。
当前机器阅读理解任务面临的主要挑战仍然是多句推理,这对挖掘深层语义提出更高的要求。针对多项选择式和问答式任务的机器阅读理解方法存在的上述局限性,且不能很好地解决该问题,因此进行复杂语义推理的多项选择式任务逐渐占据主流。多项选择式任务是给定了文章、问题和候选答案,机器经过理解和推理,从候选答案中选择出正确的答案,候选答案多数是由句子组成,且一般不会在原文中出现。相比于完形填空式和问答式任务,由于正确答案多数无法在原文中找到,多项选择式任务将会更加复杂、更具有代表性,因此本文以多项选择式任务为研究内容。面向多项选择的机器阅读理解模型主要是基于循环神经网络,文献[16]使用双向GRU进行特征提取,并结合注意力机制提出分层注意力流模型,文献[17]使用分层的双向长短期记忆(Long Short-Term Memory,LSTM)网络分别提取句子级别和文档级别的特征。利用循环神经网络提取特征,尽管从理论上能够捕获无限长的记忆,从而建立上下文间的长期依赖关系,但是仍存在梯度消失问题,且随着需要处理序列的增长,还有一定程度的信息丢失,导致无法捕获全局的语义关系。
为有效地对文章、问题和候选答案进行匹配以减少特征的丢失,基于时间卷积网络(Temporal Convolutional Network,TCN)[18],本文构建一种面向多项选择的机器阅读理解M-TCN模型。该模型在中国初高中英语考试的阅读理解数据集RACE[19]上进行训练,并与现有机器阅读理解模型进行对比分析,以验证该模型的机器阅读理解性能。
1 模型搭建
针对多项选择式任务,本文采用深度学习技术构建一种M-TCN模型,该模型结构如图1所示。在图1中,假设P表示文章,Q表示问题,A表示一个候选答案,该模型通过预训练好的词向量文件将P、Q和A中的每个单词向量化,并采用单层的双向LSTM网络[20]对向量化后的序列进行编码,以获得文章、问题和候选答案的上下文表示。为了对文章、问题和候选答案进行匹配,构建三者之间的内在联系,分别计算文章和问题以及文章和候选答案之间的注意力,并利用融合函数将注意力值与文章的上下文表示相融合。同时,使用TCN和最大池化方法对匹配表示分层进行句级聚合和文档级聚合。M-TCN模型的目标是计算出每一个候选答案的概率,并以概率最大的候选答案作为预测标签。
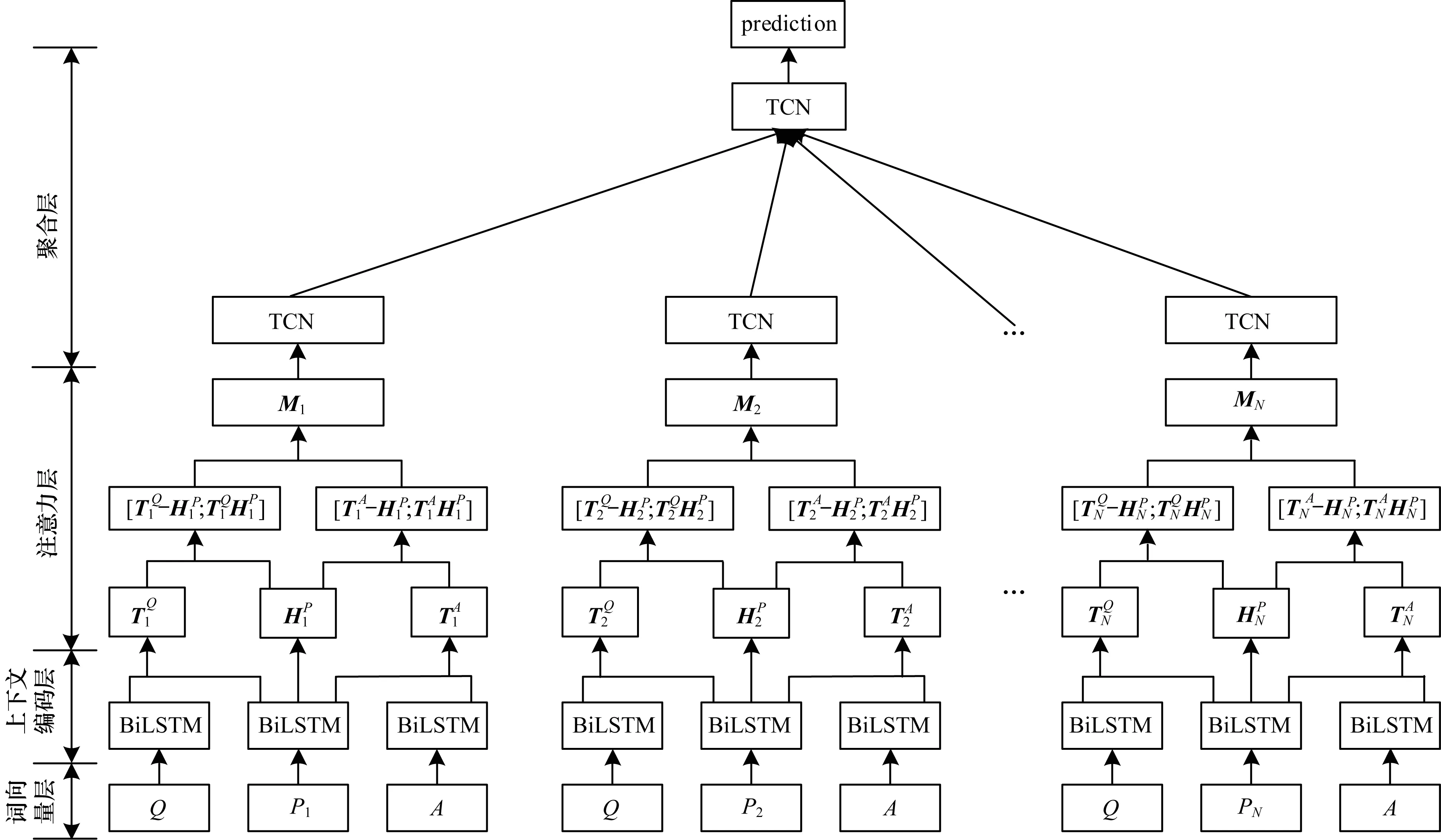
图1 本文模型结构Fig.1 Structure of the proposed model
1.1 词向量层

1.2 上下文编码层
1.3 注意力层
注意力层主要负责匹配和融合来自文章、问题和候选答案的信息。本文使用注意力机制同时对文章和问题以及文章和候选答案进行匹配,在存在监督训练的过程中,通过更新参数矩阵学习来显示出问题和候选答案中与文章密切相关的内容,忽略与文章不相关的内容,注意力向量的计算方法如下:
Sq=Softmax(Hpδ((HqWm+bm)T)
Sa=Softmax(Hpδ((HaWm+bm)T)
Tq=SqHq
Ta=SaHa
(1)
为了整合原始上下文表示,从不同层次反映语义信息,本文将文章上下文表示Hp分别与问题注意力向量Tq以及候选答案注意力向量Ta相融合,并产生矩阵Q′和A′,Q′和A′的计算方法为:
Q′=β(Hp,Tq)
A′=β(Hp,Ta)
(2)
其中,β是一个需要训练的融合函数,最简单的融合方法是将2个输入相结合,然后进行线性或非线性变换。为了更好地提取融合特征,文献[21]提出一种基于差异性与相似性的融合方法,该方法能有效组合不同的表示形式,同时本文参考文献[17]采用的融合方式对β进行如下定义:
β(Hp,Tq)=δ([Tq-Hp;Tq·Hp]Wz+bz)
(3)
其中,[;]表示矩阵的连结操作,“-”“.”表示2个矩阵之间逐元素的减法和乘法操作,Wz和bz是需要学习的参数。
将Q′和A′相结合得到注意力层的输出,计算方法为:
M=[Q′;A′]
(4)
1.4 聚合层
为了捕获文章的句子结构,建立句子之间的联系,本文在匹配层的基础上建立了聚合层。首先将文章分为单个的句子,并用P1,P2,…,PN分别表示文章中的每个句子,其中,N表示文章中句子的总个数。对于每一个三元组(Pn,Q,A),n∈[1,N],通过前几层的处理可以得到匹配表示Mn。为了捕获Mn中上下文间的长距离依赖关系,减少特征丢失,本文采用TCN来提取高层特征。
TCN是一种特殊的一维时间卷积网络,用于序列建模任务,文献[15]表明,TCN在多种任务和数据集上的性能均优于LSTM等典型的循环神经网络,且相比于循环神经网络,TCN可以记住更长的历史信息,捕获更全局的语义关系。在序列建模任务中,一般有以下2个要求:
1)模型产生与输入长度相同的输出。
2)信息的传递是单向的,且未来的信息仅由过去的信息决定。
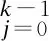
(5)
其中,d表示空洞因子,k表示卷积核的大小,空洞卷积如图2所示。TCN中还加入了残差连接[22]、权值归一化[23]和空间Dropout[24]来提高性能,TCN的整体架构如图3所示。
图2 空洞卷积示意图Fig.2 Schematic diagram of hole convolution
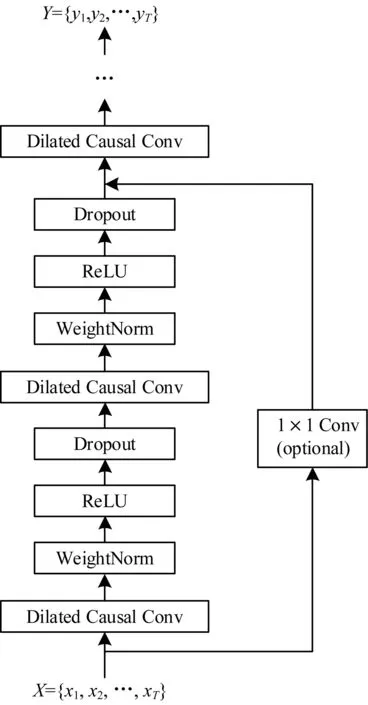
图3 TCN整体结构Fig.3 The overall structure of TCN
本文模型采用2个分层的TCN,第一层TCN的输入是匹配表示Mn,得到的输出紧接着进行最大池化,计算方法为:
Sn=MaxPooling(TCN(Mn))
(6)
S=[S1;S2;…;SN]
D=MaxPooling(TCN(S))
(7)
(8)
其中,Wv是需要学习的参数。
2 实验与性能分析
2.1 数据集
机器阅读理解的效果与采用的数据集密切相关,本文采用RACE数据集。RACE数据集是一个基于中国初高中英语考试的多项选择阅读理解数据集,由27 933篇文章和97 687个问题组成,每个问题配有4个候选答案,且只有一个正确答案。为了对应初中和高中阅读理解难度水平,该数据集包含2个子数据集,分别为初中阅读理解数据集RACE-M和高中阅读理解数据集RACE-H。将RACE数据集看成三元组{P,Q,A}的集合。实验数据的具体信息如表1所示,该数据集的样例如表2所示。
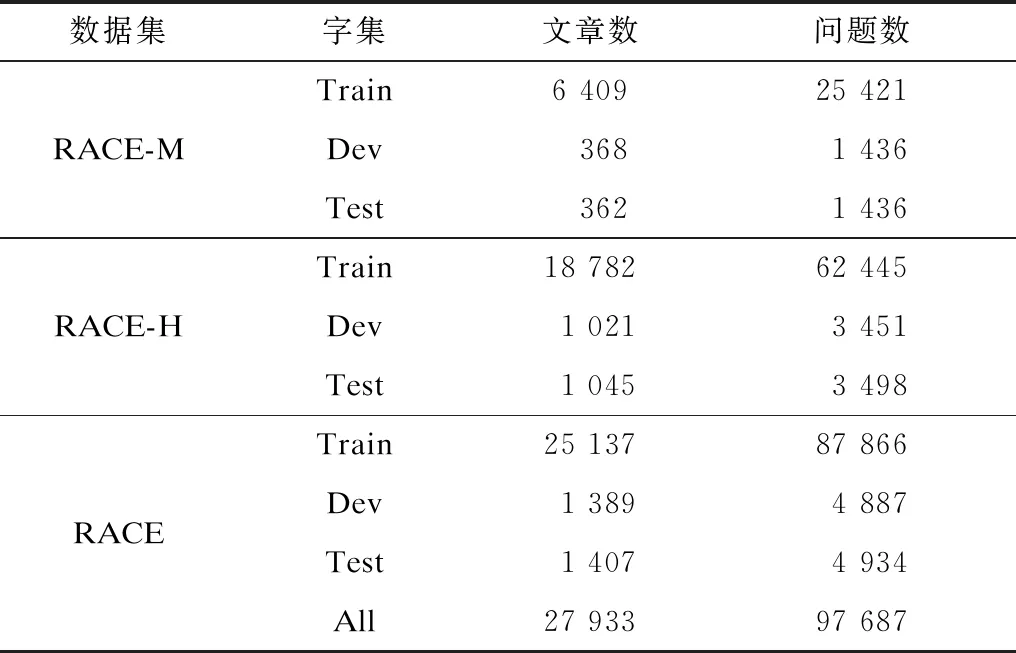
表1 实验数据信息Table 1 Experimental data information

表2 RACE数据集的样例Table 2 Example of RACE dataset
2.2 实验环境和参数设置
本文模型在配备有英特尔i7 CPU以及NVIDIA GTX1080Ti GPU的计算机上进行训练,采用深度学习框架Pytorch,集成开发环境为Pycharm。在深度学习中模型参数的调整对实验结果有重要的影响,参数过大或过小都会影响模型的精度。本文通过实验并结合经验手动调节参数,对模型进行科学训练,以提高资源利用率。其中,参数的调整包括TCN层数、TCN隐层节点数与学习率等,并探索了这些参数在不同配置下对模型精度的影响。
2.2.1 TCN层数的选择
从理论上来讲,增加TCN的层数可以增强非线性表达能力,提取更深层次的特征,从而提升模型的性能。在利用本文模型进行机器阅读理解的过程中,需要对TCN的层数进行实验验证,验证结果如表3所示。从表3可以看出,模型的精度随着TCN层数的增加呈现先上升后下降的趋势,这是由于TCN层数越多,模型的参数量越大,反而不易训练,为了使模型能够保持良好的性能,实验选择TCN的层数为3层。

表3 TCN层数对模型精度的影响Table 3 Influence of TCN layers on model accuracy
2.2.2 TCN隐层节点数的选择
TCN隐层节点数是模型提取数据特征能力大小的重要参数,且如果TCN隐层节点数太少,则网络性能较差,如果TCN隐层节点数太多,虽然能够减小网络的系统误差,但是会使得训练时间延长,甚至出现过拟合,因此选择合适的隐层节点数十分重要。本文考察了不同TCN隐层节点数对模型精度的影响,结果如表4所示。从表4可以看出,模型的精度随着TCN隐层节点数的增加呈现先增加后降低的趋势。因此,实验选择TCN隐层节点数为450。

表4 TCN隐层节点数对模型精度的影响Table 4 Influence of the number of hidden nodes in TCN on model accuracy
2.2.3 模型学习率的选择
学习率控制着参数更新的速度,如果学习率过大可能导致参数在最优解两侧振荡,如果学习率过小会极大降低模型的收敛速度。图4给出了本文模型在不同学习率下的精度。从图4可以看出,随着训练次数的增加,模型的精度逐渐趋于稳定;当学习率为0.001时,本文模型的精度最高,为了保证模型的收敛速度以及性能,实验将学习率设置为0.001。
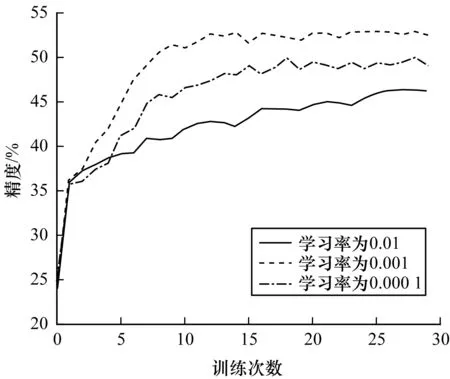
图4 学习率对模型精度的影响Fig.4 Influence of learning rate on model accuracy
2.3 实验结果与分析
为了对模型效果进行评估,实验将GA(Gated Attention)[8]模型、ElimiNet(Eliminate Network)[25]模型、HAF(Hierarchical Attention Flow)[16]模型、MRU(Multi-range Reasoning Units)[26]模型、HCM(Hierarchical Co-Matching)[17]模型与本文模型进行比较,并以精度作为衡量模型性能的指标,结果如表5所示。从表5可以看出,本文模型在RACE-H数据集与RACE数据集上的精度分别达到了48.9%、52.5%,均优于其他基线模型,仅在RACE-M数据集上的精度次于MRU模型,说明了本文模型有效且具有一定的优势。
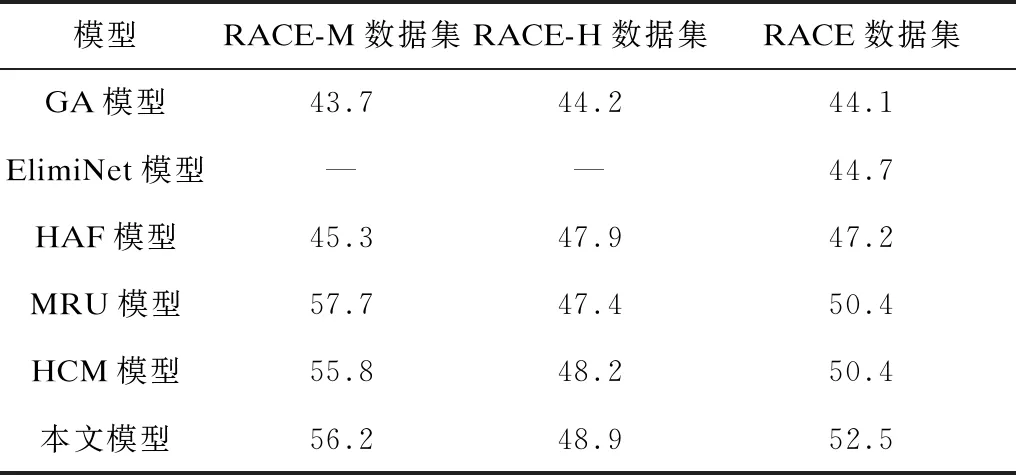
表5 本文模型与基线模型的精度对比Table 5 Accuracy comparison between the proposed model and the baseline model %
为了证明本文模型中各个功能模块的有效性,本文还进行了模型简化实验来探索注意力机制、融合函数以及TCN对模型效果的影响,结果如表6所示。从表6可以看出,当从本文模型中去除注意力机制、融合函数或者TCN时,该模型的精度分别下降了9.1%、7.8%、7.9%,下降的幅度较大,证明了注意力机制、融合函数以及TCN是影响模型效果的重要因素。

表6 在RACE数据集上的模型简化实验结果Table 6 Experimental results of model simplification on RACE dataset %
3 结束语
本文提出一种基于TCN的机器阅读理解M-TCN模型,并将其应用于多项选择任务。该模型使用注意力机制对文章、问题和候选答案进行匹配,采用TCN提取高层特征。实验结果表明,M-TCN模型在RACE数据集上的预测精度达到了52.5%,与同类模型相比具有一定的优势。后续将在本文工作的基础上,采用预训练技术进一步提升模型效果,并不断增强其推理能力。
