基于改进的Faster R-CNN目标人物检测
2020-11-11周华平桂海霞姚尚军丁金虎
周华平,殷 凯,桂海霞,姚尚军,丁金虎
(1.安徽理工大学 计算机科学与工程学院,安徽 淮南232000;2.淮北矿业物业管理服务有限公司,安徽 淮北235000)
0 引言
在计算机视觉任务中,常常面临一个基本问题:怎样理解现实世界中的场景结构? 在现实世界中,人们通过视觉获得的外部信息达到80%以上。人眼就如同监控器一样,我们通过视觉获得的信息往往是一段动态视频。而当提取监控器所记录的视频信息时,往往先将其拆分为一张一张的图像,通过对图像的分析来理解所记录视频的全部信息,理解图像的意思意味着理解真正的场景。图像处理越来越重要,并且目标检测是图像处理和计算机视觉任务的基础。目标检测任务不仅仅是单纯地检测目标是否在图像或者视频中,更重要的是能够确定目标所在的位置。比如,当进行一个人物的目标检测时,在一张图像中,可能存在一个甚至多个人物目标,可以轻松地判定图像中有人;然而,当想要在图像中确定目标人物出现的位置时,往往需要以某种方式探索。
目前,卷积神经网络[1]广泛应用于各种领域。在目标检测领域中,区域卷积神经网络R-CNN[2]显著地提升了目标检测器的准确率和运行速度,并且以R-CNN 及其变体Fast R-CNN[3]和Faster R-CNN[4]为代表的二阶段目标检测网络一直在各个常用的目标检测数据集上获得最高的准确率。相比AlexNet[5],VGG16[6]等特征提取网络,ResNet[7]具有更好的提取图像深层信息的能力。在使用Batch Normalization[8]解决了模型的收敛问题之后,原则上ResNet的深度可以持续增加,He等[9]使用ResNET来解决增加模型的深度反而导致训练误差的增加。
1 Faster R-CNN
Faster R-CNN目标检测网络主要分为两个步骤:① 定位目标。通过输入一张图片进入特征提取网络,经过一系列的卷积、池化操作来提取图像的特征图,目标检测任务不仅是检测目标,还有通过RPN网络在特征图上找到定位的候选目标。② 对目标的特定类别进行分类。范围框回归器用于修改候选目标的位置以生成最终候选目标区域,而softmax分类器用于识别候选目标的类别。本文使用分类网络来判别候选区域是否属于人,从而实现对目标人物的检测。Faster R-CNN结构如图1所示。
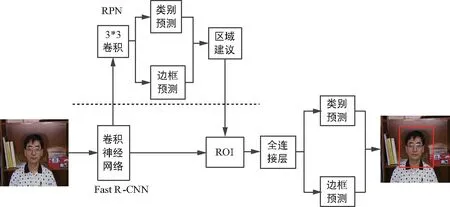
图1 Faster R-CNN结构Fig.1 Faster R-CNN Structure
1.1 特征提取网络
1.1.1 ResNet
本文通过对基于卷积神经网络的ResNet-101模型进行改进来完成对目标人物的特征提取,相比AlexNet,VGG16等特征提取网络,其特点如下:
(1) ResNet采用“shortcut”恒等映射网络的快捷连接方式,既不会产生附加参数也不会增加计算复杂度。如图2所示,快捷连接简单地执行身份映射,并将其输出添加到叠加层的输出中。通过SGD反向传播,使整个网络可以以端到端的形式进行训练,从而使得网络性能一直处于最优状态。
Xl+1=Xl+F(Xl,Wl),
(1)
Xl+2=Xl+1+F(Xl+1,Wl+1)=
Xl+F(Xl,Wl)+F(Xl+1,Wl+1),
(2)
(3)
(4)
式中,网络输入值为Xl,网络输出值为Xl+1,Xl+2,…,XL,ε,网络残差块为F(Xl,Wl),F(Xl+1,Wl+1)。
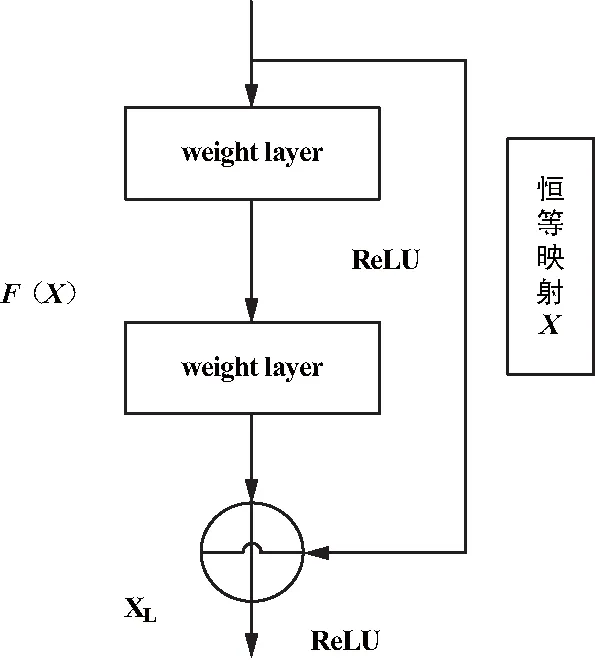
图2 残差网络模型Fig.2 Residual network model
(2) ResNet采用“Bottleneck design”网络设计方式结构,使用1×1的卷积改变维度,3×3卷积继承网络性能,并使3×3卷积的输入输出特征图数量得到控制。在层数较高时减少了3×3卷积个数,使得在增加网络深度和宽度的同时,大幅降低了卷积参数的个数和计算量。
1.1.2 改进的特征提取网络
在传统ResNet-101的基础上,结合图片的特点,尝试改进残差结构,通过增加网络的宽度,提取人物深层特征使网络学习到关键性的可区分特征,提出了一种改进的深度残差网络结构,从而提高目标人物的识别精度。本文使用的残差单元如图3所示,采用两个并列的3×3卷积层。其中1×1的卷积层作用是改变维度,两个并列的3×3卷积层继承了VGG网络的性能,单元采用预激活方式,所有的卷积层都使用ReLU作为激活函数,即在使用激活函数和卷积操作之前先进行批正则化,这种结构与原始残差单元相比在训练参数上相差不大,但后续实验表明,本文提出的残差单元结构对目标人物的检测和模型的性能都有明显提升。
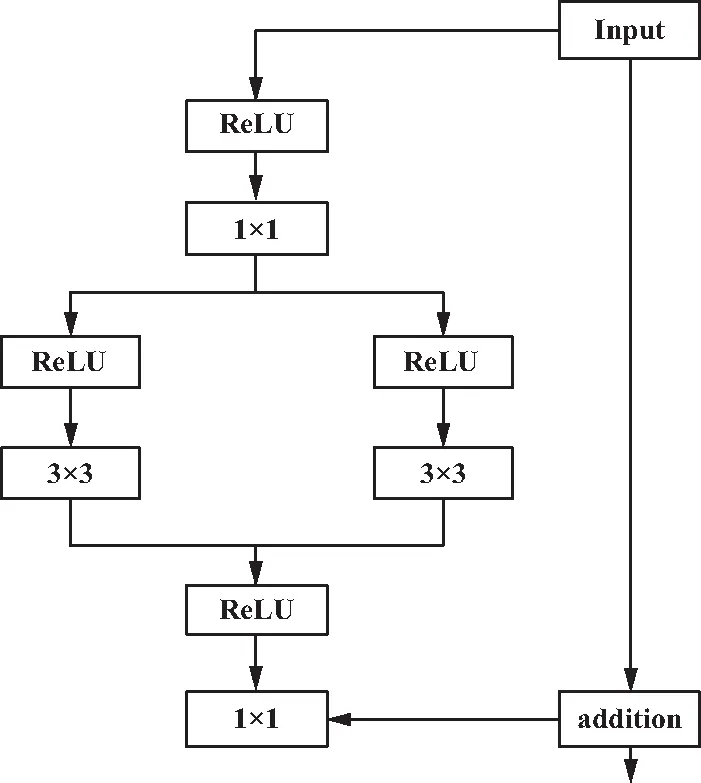
图3 残差单元结构设计Fig.3 Structural design of residual element
1.2 区域生成网络
区域生成网络(Region Proposal Network,RPN)具体结构如图4所示。

图4 RPN网络Fig.4 RPN network
特征提取网络提取图片特征时,是由低层向深层的一个过程,每一层都有各自的RPN,通过提取出的不同尺度的feature map来生成候选区域,不同比例对应的的RPN不同。当深层神经元接受范围扩大时,相应的锚定箱尺寸也增加。候选面积越大,RPN越小。在获得候选区域之后,特征通过RI pooling被转换成统一大小,并且最终将其发送到分类器,从而完成整个Faster R-CNN过程。
在RPN结构中,滑动窗口对特征图进行卷积操作产生n维特征向量,产生的特征向量输入到回归层和分类层。其中,滑动窗口滑动一次会预测出k个区域建议,回归层需要预测出包围框的宽高和中心坐标,分类层需要辨别建议框是前景还是背景的概率,因此回归层需要输出4k个坐标,分类层包含2k得分。RPN网络进行的是端到端的训练过程,使用反向传播法和梯度下降法进行调优。在训练时,RPN使用重叠交并比IoU进行正负标签的分配,IoU>0.7时分配正标签,IoU<0.3分配负标签。
1.3 检测网络
检测网络在Faster R-CNN中进行感兴趣区域(Region of Interest,ROI)池化操作。网络由边框分类网络与边框回归网络构成,并含有两个平行的输出层。在ROI提取通过RPN对应的区域特征后,使用检测网络对得到特征进行人物分类和边界框的预测。分类层的输出是人类和非人类分类中每个框架的概率分布;回归层输出的则是边框位置参数。此阶段的损失函数为:
L(p,m,tm,n)=Lcls(p,m)+λ[m≥1]·Lreg(tm,n),
(5)

(6)
2 实验验证
本文人物数据集包含320张图片,选择300张图片作为训练集,20张图片选为测试集,使用Image Labeler工具对图片进行标注,测试集图片尺寸更改为227×227 px。使用Matlab 2018b作为实验平台,实验所用设备为Windows 8.1家庭版64位,采用CPU为Intel(R)Core(TM)i5—5200U @2.20 GHz,内存4 G,GPU为NIVDIA GeForce 830 M,Cuda9.1实验过程中调用GPU进行加速运算,学习率设定为0.000 1,共进行1 000次迭代。
从表1可以得出,改进后的模型准确率最高,比原始模型的准确率高出1.6%,即对于AlexNet和原始的特征网络,改进后的特征网络能够更好地提取图片特征,可以更加准确地检测目标。同时,改进后的ResNet101网络模型mAP数值最高,即目标网络模型性能相对较好,从而增加模型的识别精度。所以改进后的模型检测效果相对较好。
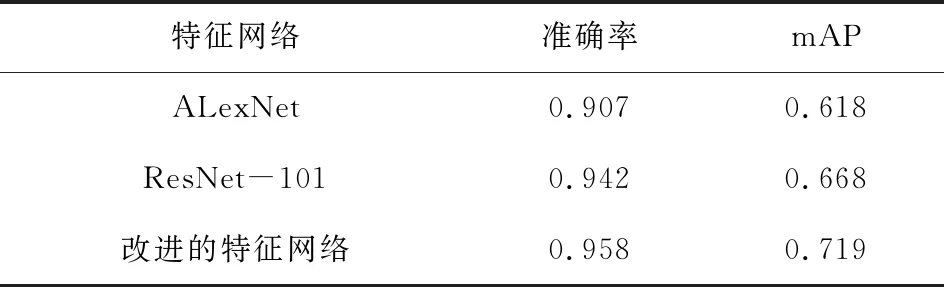
表1 不同特征网络下的准确率和mAP值Tab.1 Accuracy and map value under different characteristic networks
由图5可知,训练集中样本的数量不同对目标检测的准确率有一定的影响,识别精度会随着训练样本的增加而提高。在不同训练样本下,改进网络的识别精度一直高于原始网络,在低样本的情况下准确率明显高于原始网络,说明改进后的特征网络能够更好地提取图片特征,提高识别精度。
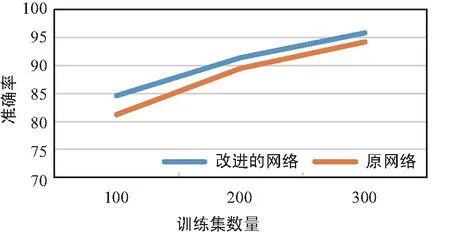
图5 不同训练集下的准确率Fig.5 Accuracy under different training sets
针对人物识别的准确率以及人物定位精度,在基于Faster R-CNN框架的基础上提出了一种改进其特征网络ResNet-101的方法。并用人物图像训练模型,最后得到人物检测和定位的结果如图6和图7所示,可以得到如下的结论。

图6 单目标人物检测率Fig.6 Single target detection effect

图7 多目标人物检测率Fig.7 Multi-target character detection effect
① 改进基于卷积神经网络的ResNet-101特征提取网络设计,为了让模型对目标更加敏感,本文在原始网络的基础上增加了网络的宽度,该改进使网络学习到关键性可区分特征,从而提高目标人物的识别精度。
② 相对原始模型,改进的Faster RCNN模型对人物识别的准确度提升了1.6%,并且在一张图片上含有多个人物时依然能够精确地定位识别人物在图像中的位置,这充分说明了改进的Faster RCNN的鲁棒性更强。
3 结束语
以Faster RCNN框架为基础,提出了一种改进的特征网络模型。实验结果表明相对于传统方法,改进方法在测试精度和泛化能力上都有比较明显的优势,验证了本文所提出方法的有效性。随着深度学习的快速发展,目标检测技术已经取得了长足的进步,但是与人眼分辨物体的能力还有一定差距。为了使目标检测更好的应用在生活中,在接下来的研究中,将继续扩充数据的规模、充实样本的多样性以及通过对RPN的改进来提升模型的性能,同时将改进的技术应用于视频检测当中。
