近红外光谱技术结合4种算法分析尾巨桉-马占相思制浆原料的混合程度与主化学成分
2020-11-09朱北平邓拥军房桂干
吴 珽,梁 龙,朱北平,邓拥军,房桂干*
(1.中国林业科学研究院 林产化学工业研究所;生物质化学利用国家工程实验室;国家林业和草原局 林产化学工程重点实验室;江苏省生物质能源与材料重点实验室,江苏 南京 210042;2.金东纸业(江苏)股份有限公司,江苏 镇江 212132)
制浆造纸工业是国民经济的重要组成部分,2019年我国纸和纸板总产量约为10 765万吨,行业总产值逾万亿元,居世界第一。同年纸浆消耗9 609万吨,其中进口木浆占24%,国产木浆占13%,进口废纸浆占10%,国产废纸浆占46%[1]。新冠疫情和贸易战的进一步升级制约了木浆的进口,我国近年颁布的“禁废令”则在短期内将进口废纸浆配额削减为0,因此未来行业纸浆原料将大力挖掘国内产能[2]。而废纸浆因重复回收多次打浆,纤维质量下降,结合纸和纸板产品多元化、高档化发展的实际需求,用国产木浆制取高品质纸产品已是制浆造纸行业近年的必然趋势[3],预计到2025年,我国国产木浆年消耗占比将增至35%以上。这意味着除了进一步发展制浆造纸经济林种植和林浆纸一体化产业外,有必要充分利用大量的枝杈材、小径材和林木剩余物制浆[4]。
我国南方制浆造纸经济林多以桉木、相思木混交,采伐切片后与枝杈材、小径材和林木剩余物等混合分装、运输、存储,生产时大批量原料木片无法保证混合均匀且各批次原料的化学成分含量不一[5]。如果按原定制浆工艺参数生产,往往出现磨浆能耗不够、化学品用量偏低的情况,导致纤维解离程度低,纸浆品质差;如按最高标准输入磨浆能耗,会加大化学品用量,引起成本高、污染重等问题。因此有必要实现混合原料的快速分析,以便实时在线调整工艺参数,保证生产的正常进行[6]。
近红外光谱(NIR)属于分子光谱,当分子受到近红外区域(780~2 526 nm)的电磁波辐射后,吸收特定频率的近红外光,使分子中原子的振动能级和转动能级发生跃迁,从而形成吸收光谱。近红外光谱结合化学计量学方法通过已知样品信息的光谱数据构建模型,利用模型对待测样品进行分析,可以提高常规定性定量分析的效率[7],近年作为一种快速分析手段已广泛应用于农林业[8-9]、轻工[10]、石油化工[11]等领域;并在制浆原料树种快速识别[12]、物理性质研究[13-14]及化学成分含量的测定[15-16]等方面发挥着较大作用。本研究选择云南、两广、海南等地广泛种植,具有代表性的制浆造纸原料树种尾巨桉(Eucalyptusurophylla×grandis)和马占相思(Acaciamangium),人为将两种样本混合以模拟生产线混合原料的状态。通过近红外光谱技术结合偏最小二乘法、支持向量机法、人工神经网络法和LASSO算法,建立混合原料混合情况以及综纤维素、聚戊糖和Klason木质素含量等重要参数的校正模型,确定最优建模方法,实现尾巨桉-马占相思混合原料的快速分析。
1 实验部分
1.1 原 料
实验所用的尾巨桉采自广东湛江,树龄5~6年;马占相思采自海南乐东,树龄6年,均为人工经济林制浆造纸适龄材。原木去皮后切削成木片,磨粉过筛,截取40~60目的细末,置于空气中充分平衡水分。随后将两种木粉按不同比例混合成145个样品,混合情况以尾巨桉的质量分数(含量)表示,均匀覆盖0%~100%区间。针对尾巨桉含量运用含量梯度法筛选出35个样品作为验证集,其余110个样品作为校正集用于建立校正模型。另取原木去皮后不同部位所磨成的尾巨桉木粉样品和马占相思木粉样品各10个,用于确定混合样品化学成分含量的代表性。
1.2 仪器选用与光谱采集
常见傅里叶近红外光谱仪能够提供准确优质的数据信息,但成本高,对外部环境要求较为苛刻,难以维护。而本研究最终的应用场所——制浆造纸车间往往温度、湿度变化较大,因此采用适应性强,易根据设备工序要求改装的阿达玛近红外光谱仪(浙江谱创仪器有限公司)获取样品的近红外光谱。设定仪器参数如下:扫描波长范围为1 600~2 400 nm;波长点数为100;光谱重复扫描次数为50次。为充分获取木粉样品信息,每个样品采样5次取平均光谱作为样品的原始光谱。
1.3 含量测定
尾巨桉-马占相思混合样品的混合情况以尾巨桉的质量分数(含量)表示,取样过程中人为混合尾巨桉和马占相思,控制并记录各样品中尾巨桉的含量,使其均匀覆盖0%~100%区间。
采集近红外光谱后测定所有145个混合样品的综纤维素、聚戊糖、Klason木质素含量,并测定20个单一树种样品的综纤维素、聚戊糖、Klason木质素含量。按GB/T 2677.10-1995测定综纤维素含量,按GB/T 2677.9-1994测定聚戊糖含量,按GB/T 2677.8-1994测定Klason木质素含量[17]。各样品的化学成分含量测定均做平行实验,以3组实验数据的平均值为实测值。
1.4 模型建立的方法与步骤
在Matlab 8.0中分别加载4种算法,结合交互验证中的留一法在不同参数条件下建立模型,当预测残差平方和(PRESS)最小时,表明模型参数最佳,模型性能最优。
1.4.1 偏最小二乘法偏最小二乘法(PLS)将矩阵分解和回归并为一步,同时分解光谱矩阵X和浓度矩阵Y,并将Y的信息引入X矩阵分解过程中,在每计算一个新的主成分前,将X的得分T与Y的得分U进行交换,使得X主成分直接与Y关联,从而保证获得最佳模型。该方法较好地将多元线性回归、典型相关分析和主成分分析结合,近年在近红外光谱分析中应用广泛[18]。模型建立的关键在于最佳主成分数n的确定。
1.4.2 支持向量机法支持向量机(SVM)是基于统计学习理论的机器学习算法。其主要思想是将原问题通过核函数实现低维空间的非线性问题到高维空间的线性问题的转化,并在高维空间中进行线性求解,以保证算法有较好的推广能力,同时解决了维数灾难问题。该算法选择径向基函数作为核函数,其关键在于ε不敏感损失函数中的ε值、径向基系数γ、惩罚参数C的确定[19]。
1.4.3 人工神经网络法人工神经网络(ANN)是一种旨在模仿人脑结构及其功能的信息处理系统,由大量处理单元(神经元)构成。大量神经元组成网络动态运行时,构成具有自适应、自学习能力的复杂系统。神经网络的连接方式有多种,本研究选取的反向传输神经网络(BP-ANN)具有逼近任意非线性映射的功能和很强的学习能力,应用最为广泛。其数据由输入层输入,经标准化处理,并施以权重传输到隐含层。隐含层经过权值、阈值和激励函数运算后,传输到输出层。输出层给出神经网络的预测值,并与期望值进行比较,若存在误差,则从输出开始反向传播该误差,进行权值、阈值调整,使网络输出逐渐与期望输出一致[20]。该模型的主要参数为隐含层神经元个数N1、学习速率v、动量因子m和学习次数N2。
1.4.4 LASSO算法LASSO(Least absolute shrinkage and selection operator)是一种处理具有复共线性数据的有偏估计,算法样本外的预测能力强,常用于经济、社会方向的大数据分析[21-22],近年在医学[23]、化工[24]等领域的数据处理及建模预测方面有较好的表现。其基本思想是在回归系数的绝对值之和小于一个常数的约束条件下,使残差平方和最小化,从而能够产生某些严格等于0的回归系数,得到解释力较强的模型。
设有p个自变量x1,x2,…,xp和因变量y,它们之间可建立如下的线性回归模型:
y=α+β1x1+β2x2+…+βpxp+
(1)
其中α为常数项;β1,β2,…,βp为回归系数;为随机扰动项。
对系数的绝对值进行惩罚,用残差平方和的最小值加上一个对回归系数进行的惩罚函数表示,即:
(2)
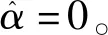
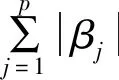
1.5 评价标准
RMSECV及RMSEP是均方根误差(RMSE)在模型建立与评价过程中不同阶段的不同表达形式,其值越小,说明模型的预测能力越强。RMSE的计算公式如下:
RPD定义为验证集标准偏差与预测均方根误差之比。AD直观反映预测值和标准方法测定值之差,其值应在模型实际应用时许可的误差范围内,通常应小于两次测定值之间误差上限的3倍。Bias是绝对偏差代数和的平均值,反映样品分析过程中的系统误差。另外,对测定值和独立验证的预测值进行双尾成对T检验。即假设近红外光谱法预测值和经典方法测定值之间无显著性系统误差,通过T检验计算出统计量进而计算P值,将P值与一定几率比较(通常取0.05),当该两组数据在大于5%的几率上相等,而在小于95%的几率上不相等时,可认为预测值和测定值之间无显著性差异[26]。
2 结果与讨论
2.1 测定数据的分布
20个单一树种样本的化学成分含量中,尾巨桉的综纤维素含量分布在78.22%~81.61%之间,马占相思的综纤维素含量分布在73.25%~77.44%之间。尾巨桉的聚戊糖含量分布在24.80%~30.51%之间,马占相思的聚戊糖含量较低,分布在18.03%~26.20%之间。尾巨桉的Klason木质素含量分布在21.23%~27.58%之间,马占相思的Klason木质素含量分布在22.65%~27.63%之间。校正集和验证集共145个混合样品的尾巨桉含量和3种化学成分含量分布见表1,其中尾巨桉含量均匀覆盖0%~100%区间,3种化学成分含量分布较广,基本覆盖了单一树种化学成分含量的区间。

表1 混合样品的含量分布情况Table 1 Content distribution of the mixed samples
2.2 样品的近红外光谱及其预处理
图1为样品的原始近红外光谱,其中横坐标为光谱波长,纵坐标反映样品对光谱的吸收强弱,可见原始近红外光谱的信号强度较弱,谱带重叠干扰严重,因此需对光谱数据进行预处理以消除无关信息和噪音的干扰。先对所有原始光谱数据进行一阶导数处理以消除基线和背景干扰,再通过标准正态变换处理(SNV)消除木粉颗粒大小不均匀导致的非特异性散射的影响。图2为经预处理后样品的近红外光谱。
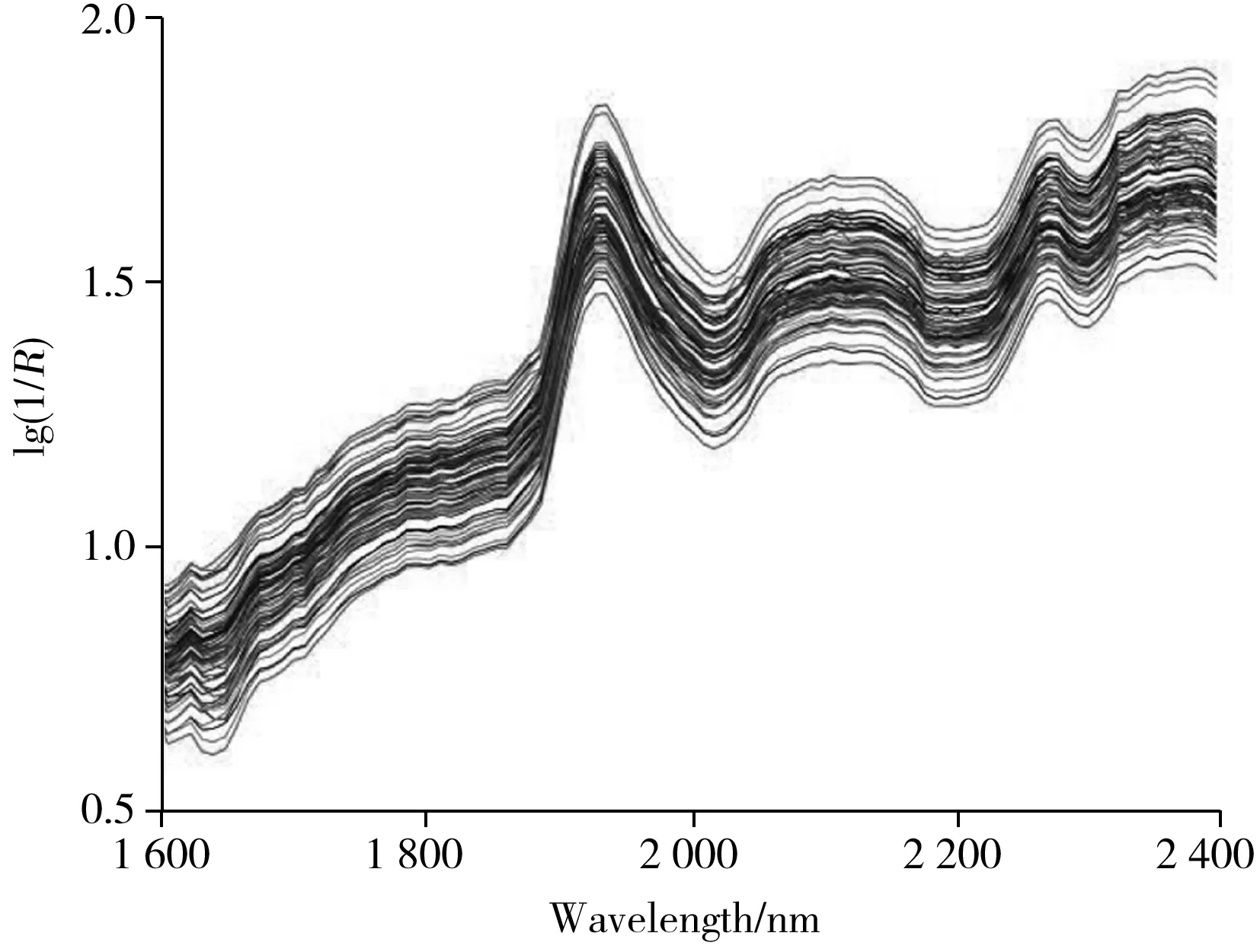
图1 样品的近红外光谱Fig.1 Near-infrared spectra of samples
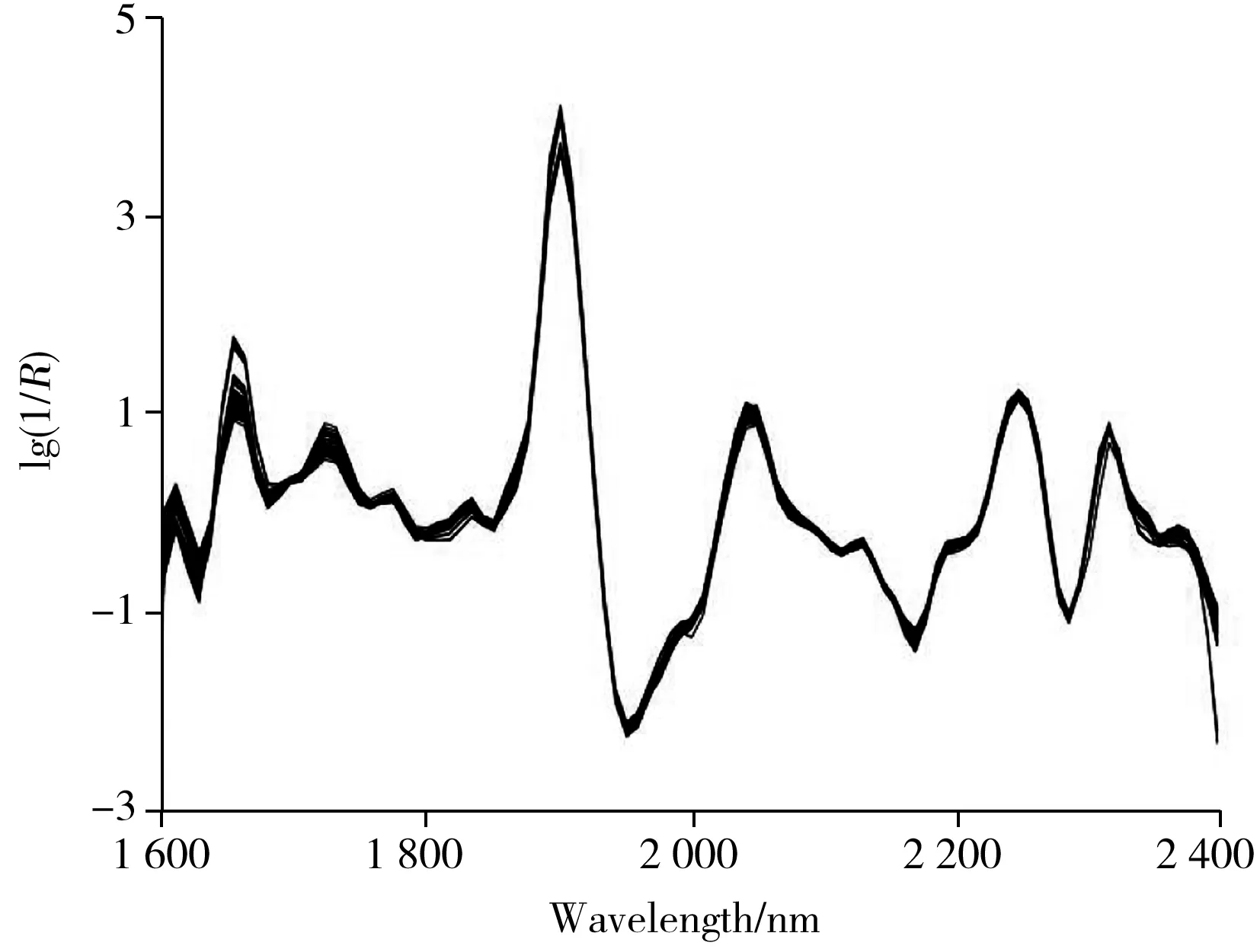
图2 一阶导数+SNV预处理后样品的近红外光谱Fig.2 Near-infrared spectra of samples pretreated by first derivative and SNV
2.3 模型的建立

表2 不同算法所建模型的参数Table 2 Parameters of models built by different algorithms
2.4 模型的独立验证

表3 模型的独立验证结果Table 3 The independent verification results of the calibration models
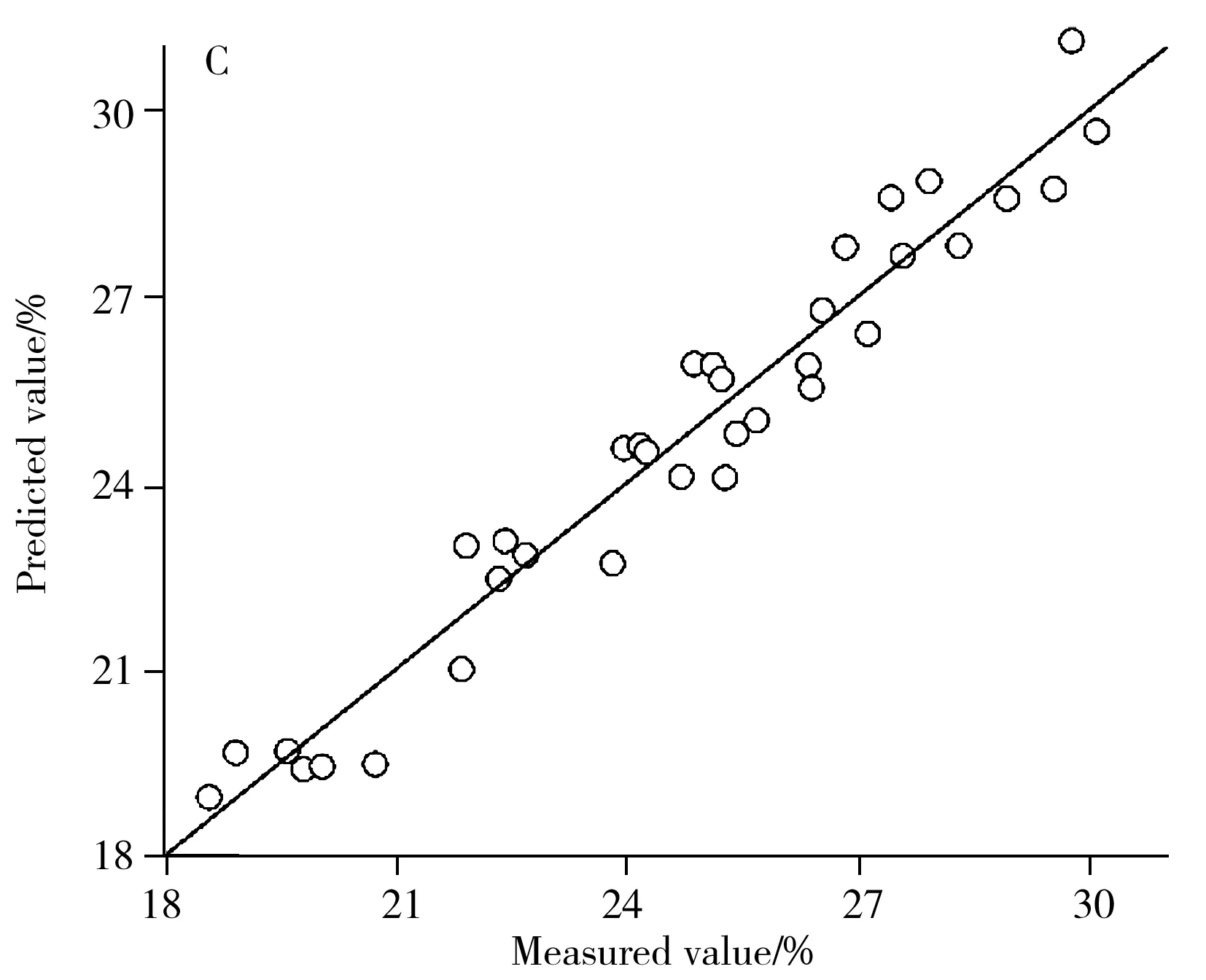
分别以测定值为横坐标,预测值为纵坐标作散点图(图3),可看出4个分析模型对相应化学成分的预测情况。尾巨桉含量分析模型的偏差(Bias)值为-0.098%,模型存在一定系统误差,使得预测结果偏小;双尾T检验P值为0.748 5>0.05,表明预测值和测定值无显著性差异。综纤维素模型的偏差值为-0.087%,模型同样存在系统误差使得预测结果偏小;双尾T检验P值为0.386 2,预测值和测定值无显著性差异。聚戊糖模型所得散点在y=x直线两侧均匀分布且数目差异不大,模型不存在明显的系统性误差;双尾T检验P值为0.951 8,预测值和测定值无显著性差异。Klason木质素模型所得散点在y=x直线两侧均匀分布且数目差异不大,同样不存在明显的系统性误差;双尾T检验P值为0.949 9,预测值和测定值无显著性差异。

3 结 论
本研究对尾巨桉-马占相思混合制浆原料样本的原始光谱进行一阶导数和标准正态变换预处理后,通过4种算法建立模型,确定了LASSO法建立的尾巨桉分析模型和综纤维素分析模型最优,模型RMSEP值分别为1.80%、0.60%,绝对偏差分别为-3.03%~3.17%、-1.03%~0.98%;偏最小二乘法建立的聚戊糖分析模型最优,RMSEP值为0.75%,绝对偏差为-1.26%~1.33%;支持向量机法建立的Klason木质素分析模型最优,RMSEP值为0.48%,绝对偏差为-0.82%~0.86%。其中尾巨桉分析模型和综纤维素分析模型适用于对尾巨桉-马占相思混合制浆原料较精确的快速分析,但模型均存在一定的偏移,使得分析结果略低于实测值。而聚戊糖模型和Klason木质素分析模型适用于非精确性的测定。本研究证实了LASSO算法用于制浆混合原料分析的可行性,与目前常用的其他化学计量学方法相比,该建模方法较为新颖,为算法择优选用以建立更精确的校正模型提供了更多的选择。
