基于近红外光谱技术与化学计量学的绿茶无损鉴别方法研究
2020-11-09李尚科蒋立文丁胜华
李 杰,李尚科,蒋立文,刘 霞,丁胜华,李 跑,*
(1.湖南农业大学 食品科学与技术学院,食品科学与生物技术湖南省重点实验室,湖南 长沙 410128;2.湖南省农业科学院 湖南省农产品加工研究所,湖南 长沙 410125)
茶作为世界三大饮料之一,不仅具有怡人的清香以及可口的滋味,同时具有诸多药理保健功效。绿茶是我国的主要茶类之一,由于其未经发酵的加工工艺,较其它茶类保留了鲜叶的大部分天然物质,含有较多的多酚类、叶绿素类以及咖啡因等成分,且在抗衰老、预防癌症、抑菌、抗氧化等方面具有特殊效果[1-2]。然而市场上的绿茶品种繁多,加工工艺和产地的差异导致其在风味以及微量元素上存在显著差别。对比不同价位、不同产地的绿茶发现,不同品种绿茶的理化成分存在较大差别,其中茶多酚、酚氨比、抗坏血酸、表没食子儿茶素没食子酸酯、酯型儿茶素与非酯型儿茶素的含量具有较为显著的差异[3]。虽然不同品种绿茶在理化性质上存在较大差异,但根据外观等表面特征较难实现对其快速准确的鉴别,因而市场上出现了不少无良商家“以次充好”的现象,如何快速准确地鉴别绿茶品种以及优劣是现阶段亟待解决的问题。
近红外光是介于中红外与可见光区范围内的一种电磁波,具有较强的穿透能力,因此可通过采集样品的近红外光谱,利用其对有机物中含氢基团振动的倍频和合频吸收以得到样品中有机物的组成以及分子结构信息[4]。相较于传统理化分析方法的繁琐、检测费用较高、对样品有破坏性等缺点,近红外光谱凭借其快速无损、操作简便以及无污染等特点,在食品[5-7]、石油[8]、医药[9]、烟草[10-11]等行业逐渐崭露头角。就绿茶检测而言,近红外光谱技术主要应用于产地溯源[12]、品质评价[13]、成分检测[14]等,但关于绿茶品种鉴别方面的相关研究较少,此外有关绿茶物理性状等所造成的光谱干扰消除的研究更是少之又少。为了实现不同品种绿茶样品的无损鉴别,本课题组前期研究中提出了一种基于连续小波变换-标准偏差-相对标准偏差的变量筛选方法[15],发现连续小波变换预处理可消除背景干扰,变量筛选方法可提高鉴别准确性,但该方法需人工选择合适的阈值以及波长数目等参数,且无法实现对不同品种绿茶的100%鉴别。此外,由于绿茶是由新鲜茶叶经过杀青、整形、烘干等工艺制成的卷曲扁形样品,相较于其它粉末状样品,更易受到光散射等干扰。因此,需对多种预处理方法进行筛选,并组合多种预处理以消除光谱中的多种干扰[16]。此外,还需采用合适的建模方法以建立准确的鉴别模型[17-21]。因此,本文旨在通过采取不同的单一以及优化组合预处理方法来消除此类干扰,并结合主成分分析法(Principal component analysis,PCA)与线性判别分析法(Linear discriminant analysis,LDA),筛选出适合绿茶的近红外光谱预处理并建立可靠的鉴别模型,实现对不同品种绿茶的快速无损鉴别分析。
1 实验部分
1.1 仪器与材料
QuasIR 4000近红外光谱仪(美国Galaxy Scientific);光谱预处理与鉴别分析由MATLAB R2010b(The Mathworks,Natick,USA)软件实现。
不同产地的8个不同品种的绿茶样品:分别记为小山茶(a)、大山茶(b)、杨山春绿(c)、九华山毛尖(d)、五云龙潭(e)、蓝天茶(f)、十八盘毛峰(g)、仰天雪绿(h)。每个品种绿茶取10个平行样品(3 g),合计80个样本。
1.2 光谱采集
实验在室温下操作,波数为4 000~12 000 cm-1,最小间隔约4 cm-1,共采集2 098个数据点。为保证光谱测量的准确性,每个样品重复测量3次,取3条平行光谱的平均值作为该样本的原始光谱。
1.3 光谱预处理与鉴别分析
将8种茶叶样品数据按照Kennard-Stone(K-S)以8∶2的比例分组,选取64个样品用于建立模型,16个样品用于验证,采用去偏置、去偏移、标准正态变量变换、最大最小归一化、多元散射校正、一阶导数、二阶导数、连续小波变换8种不同单一预处理方式对绿茶的近红外光谱进行处理,再采用一阶导数+去平移、一阶导数+标准正态变量变换、一阶导数+多元散射校正、连续小波变换+标准正态变量变换、连续小波变换+多元散射校正、标准正态变量变换+一阶导数预处理进一步消除干扰。其中,一阶导数和二阶导数均采用Savitzky-Golay平滑求导,选取窗口参数范围为3~25,结合鉴别率选取最优值为17;连续小波变换预处理的小波基为“haar”,尺度参数为20。最后运用PCA结合不同预处理方法对不同品种茶叶进行鉴别,采用LDA分类方法进一步提高结果准确性,并计算建模集和验证集的鉴别准确率。
2 结果与讨论
2.1 基于单一光谱预处理与主成分分析方法的绿茶品种鉴别
为实现不同品种茶叶的无损鉴别,对收集的8个品种绿茶样品进行近红外光谱采集,图1A为绿茶样品3次测量平均后的原始光谱图,由图可见谱线大致趋势一致,大部分谱线重合,表明具有相同或相似的吸收峰。然而原始光谱存在明显的背景干扰和基线漂移,可能是由于表面存在起伏的呈片状的绿茶样品或仪器自身问题所致。
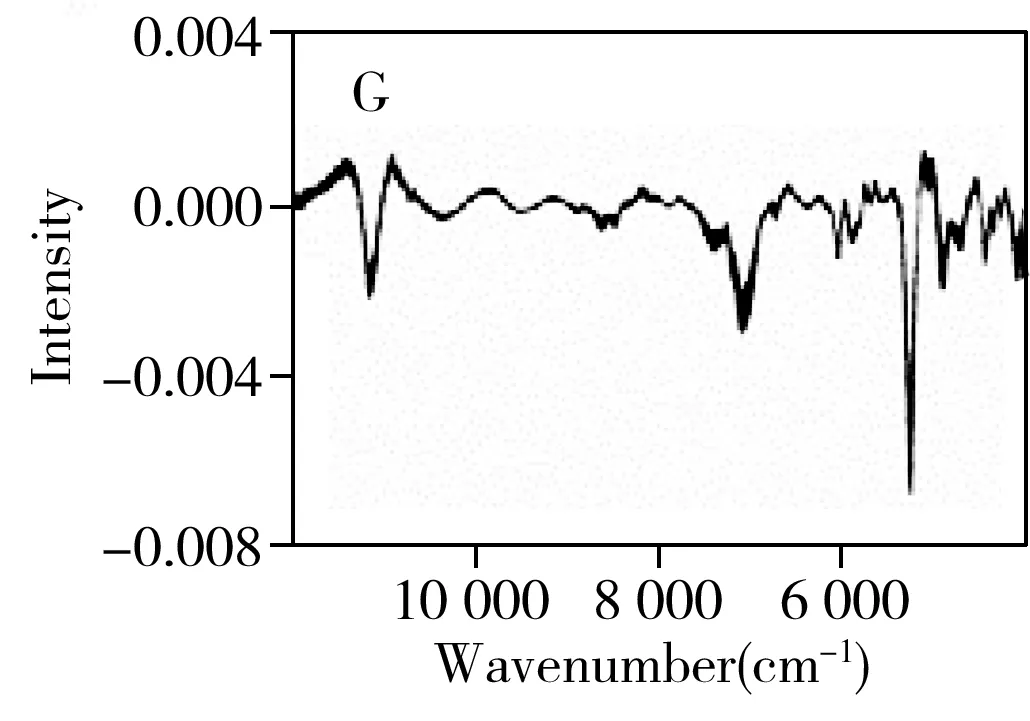
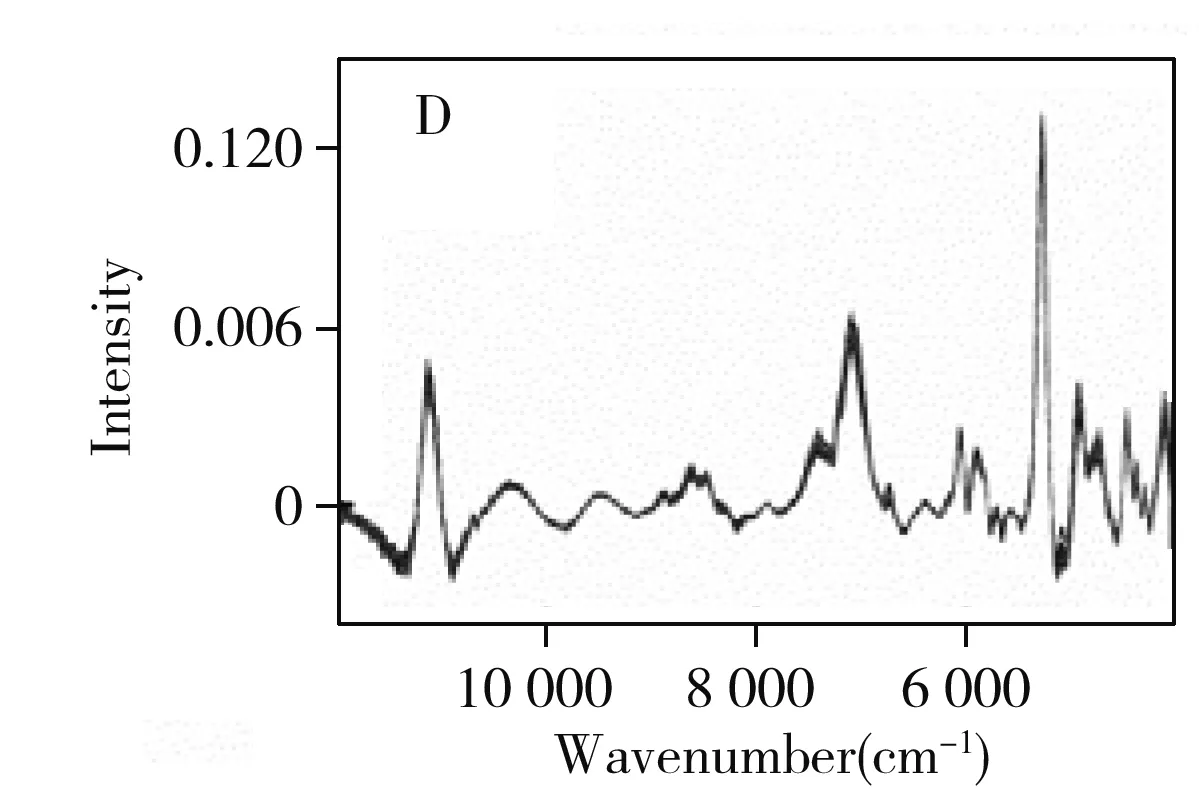
为有效消除背景干扰以及基线漂移现象,对图1A中的绿茶原始光谱数据进行多种单一预处理,分别采用去偏置、去偏移、标准正态变量变换、最大最小归一化、多元散射校正、一阶导数、二阶导数、连续小波变换8种不同单一方法进行预处理(图1),以期能消除光谱存在的不良影响,达到有效提取光谱图中信息的目的。结果显示,背景干扰经过去偏置(图1B)或去偏移(图1C)两种预处理后得到有效消除,但仍存在一定程度的基线漂移现象。而经标准正态变量变换(图1D)、最大最小归一化(图1E)、多元散射校正(图1F)、一阶导数(图1G)、连续小波变换(图1I)预处理后,均在不同程度上消除了光谱散射的影响,背景干扰得到有效消除,基线漂移现象也得到明显改善。然而,经过最大最小归一化预处理后,在6 000~8 000 cm-1处仍存在一定的基线漂移。采用二阶导数(图1H)处理后虽消除了背景干扰,强化了谱带特征,但在10 000~12 000 cm-1处出现了明显的噪声干扰。


为提高聚类分析结果的准确性,实验将不同预处理方式与聚类分析相结合,相应预处理后的PCA图见图2,空心图形表示验证集样本,不同形状的实心图形为不同品种绿茶的校正集样本,椭圆形为不同品种绿茶所构建的置信椭圆。由于前2个主成分(PC1和PC2)的方差贡献率之和在80%以上,因此选其进行PCA分析。表1为不同预处理方法得到的建模集和预测集的鉴别准确率。结果显示,原始光谱的聚类分析中(图2A),8类绿茶样品之间的置信椭圆并无明显区分,几乎完全交织在一起,仅a与b,g与b、c、d、e的置信椭圆未重叠,预测集鉴别准确率仅6.25%,因此,基于原始光谱图的聚类分析完全无法实现不同品种绿茶的鉴别。采用去偏置(图2B)、去偏移(图2C)预处理后的聚类分析图相较于原始光谱的聚类分析并无明显改善,预测集鉴别准确率分别略微提升至25.00%和12.50%。图2D与F谱图相似,仅在主成分上存在一定差异,这是由于多元散射校正与标准正态变量变换在算法层面上基本一致,均能有效消除光谱散射的影响。通过二者图谱可发现e品种绿茶(五云龙潭)能够被有效鉴别,其它品种绿茶中d能与a、c、g、e实现区分,g与b、d、e、h等品种的置信椭圆无重叠,预测集鉴别准确率为43.75%。图2E为经过最大最小归一化预处理后的聚类分析图,可看出g品种的置信椭圆除与c有重叠外,与其它置信椭圆无交叉,a与c、d、e、f、g,c与a、d、e,f与a、g、h的置信椭圆也无重叠,预测集鉴别准确率为50.00%。图2G与I的PCA图谱相似,a、e、g三者与b、c、d、f四者达到有效区分,但e和h置信椭圆相交织,预测集鉴别准确率仅18.75%。由经过二阶导数预处理后的聚类分析图(图2H)可见f、h与a、b、c、g被区分开,其它品种置信椭圆均在不同程度上出现重叠,建模集和预测集鉴别准确率均为0.00%,可能原因是二阶导数在消除干扰影响的同时也消除了不同品种绿茶的差异信息。相较于原始光谱数据聚类分析,除了使用二阶导数预处理方法之外其它单一预处理结果均得到了一定的优化,但鉴别率均不高,因此仅使用单一预处理无法实现8个品种绿茶的鉴别。
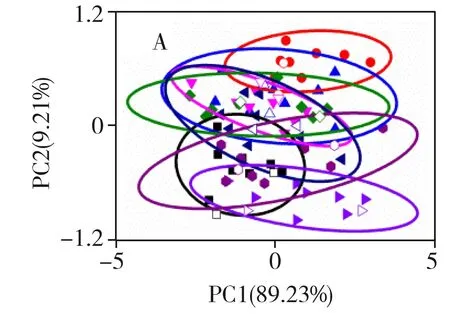

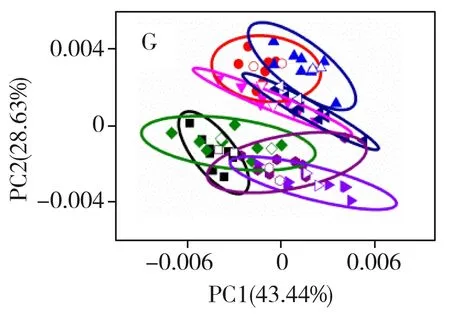

表1 不同预处理方法得到的鉴别准确率Table 1 Classification accuracies by different pretreatments

(续表1)
2.2 基于优化组合光谱预处理与主成分分析方法的绿茶品种鉴别
去平移以及去偏置预处理主要用于消除信号中基线漂移的影响,导数处理和连续小波变换预处理可用于消除信号中背景和基线漂移的干扰,多元散射校正与标准正态变量变换预处理可用于消除固体分布不均匀所造成的光散射影响,为进一步实现8种绿茶品种的准确鉴别,选取组合预处理方法对原始光谱数据进行处理,其中一阶导数+去平移组合(图3A)可实现对信号中背景和基线漂移最大程度的扣除;一阶导数+标准正态变量变换(图3B)、一阶导数+多元散射校正(图3C)、连续小波变换+标准正态变量变换(图3D)、连续小波变换+多元散射校正(图3E)组合方式可同时消除背景和光散射干扰的影响;标准正态变量变换+一阶导数预处理组合方式(图3F)可用于研究预处理组合顺序对结果的影响。结果显示,A、B、C和F的图谱类似,D、E图也基本一致,这可能是因为多元散射校正与标准正态变量变换预处理的相似性,导致其它预处理方法与两者预处理之一相结合时所产生的结果也具有相似性。经过优化组合预处理对原始光谱数据处理,不但继承了单一预处理的优点,且光谱中的背景干扰得以消除,基线漂移现象基本得到扣除,谱图中的有效信息被提取出来。

优化组合预处理方式对原始光谱数据处理后的聚类分析结果见图4,不同组合预处理方法得到的建模集和预测集的鉴别准确率见表1。结果显示,一阶导数结合去平移预处理之后的聚类分析(图4A)结果与单一预处理中的一阶导数与连续小波变换预处理结果相似,同样为f品种与其它品种得到了鉴别,b与e品种实现了鉴别,a与d、e置信椭圆无重叠。预测集鉴别准确率仅为18.75%。这可能是因为去偏移在一定程度上能改善基线漂移现象,而一阶导数以及连续小波变换预处理也具有相似效果。从一阶导数、连续小波变换与多元散射校正、标准正态变量变换的组合预处理后的聚类分析结果(图4B~E)可见,c、e被有效鉴别,a、d、h与b、f、g品种间也得以区分,然而a与h,b与f置信椭圆仍有重叠,预测集鉴别准确率均为56.25%。由标准正态变量变换+一阶导数预处理后的聚类分析结果(图4F)可见,除d与b,f与g品种置信椭圆存在一定重叠外,其它品种均得以有效鉴别,预测集鉴别准确率最佳,达75.00%,这表明标准正态变量变换+一阶导数预处理组合方式比一阶导数+标准正态变量变换预处理组合方式结果略好,由此可见预处理组合顺序对结果有一定影响。以上研究表明:除一阶导数结合去偏移预处理的结果与一阶导数预处理结果相似外,经过优化预处理组合处理过后品种间的鉴别成功率相较单一预处理均得到较大提升,且8类绿茶品种间的预测集鉴别准确率可达75.00%。这可能是因为一阶导数与连续小波变换消除了基线漂移,有效地扣除了背景干扰,而多元散射校正与标准正态变量变换预处理则有效消除了光谱间散射影响,二者的结合有效提升了绿茶品种之间的聚类分析结果。然而,经过组合处理后仍存在d与b,f与g无法实现完全鉴别的现象,可能是由于这两类茶叶在产地或加工技术上存在相似或相同之处,需结合其它聚类分析方法进一步探究。
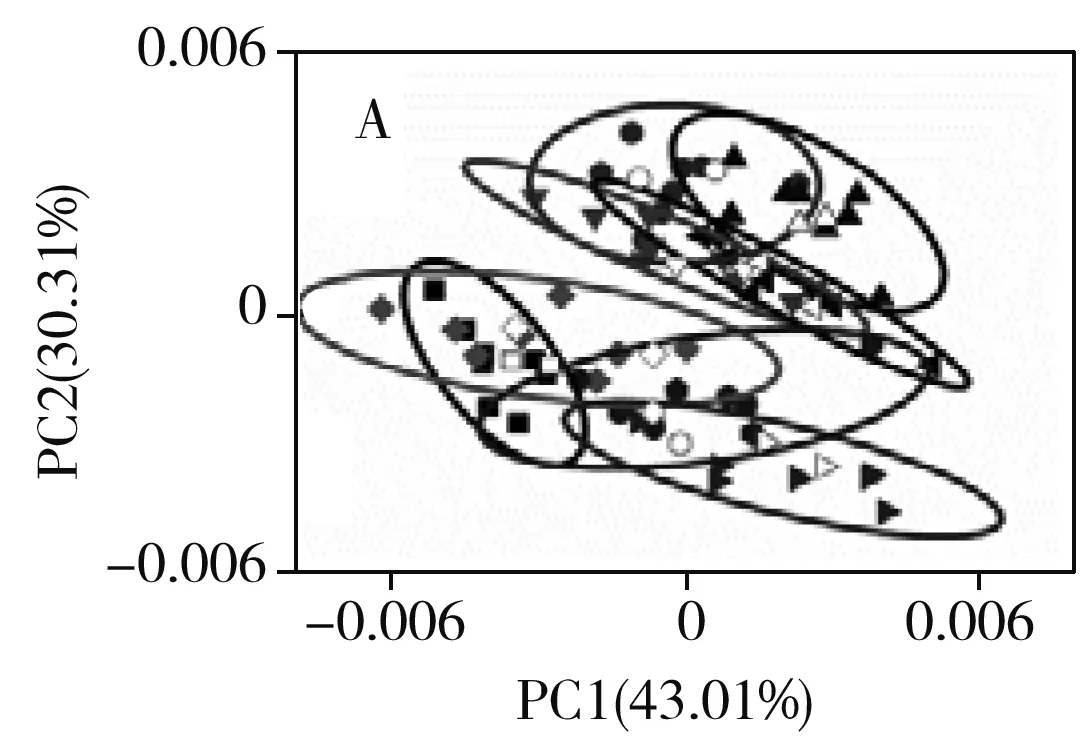
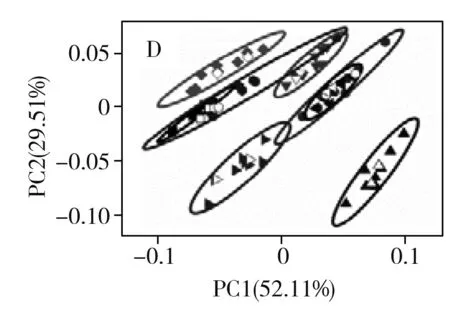

图5 8个品牌绿茶的线性判别结果图Fig.5 Linear discrimination results of 8 brands of green tea samples
2.3 基于线性判别分析方法的绿茶品种鉴别
与无监督的PCA方法不同,基于类别的先验知识的有监督方法具有更强的鉴别能力。LDA是一种常见的监督学习的降维技术,可用于聚类分析。图5为8个品种绿茶的LDA结果。结果表明:有监督模式识别方法的判别准确性高于无监督模式识别方法。在使用LDA方法对茶叶数据进行处理后,8类茶叶均得到良好的区分,鉴别成功率达100%。然而使用该方法时需提供类别的先验知识经验,而像PCA这样的无监督学习则无需类别先验知识即可实现聚类分析。当缺乏校正集的类别信息或者类别先验知识存在错误时,LDA方法往往得不到准确的鉴别结果,因此在利用近红外光谱技术对不同品种绿茶进行无损鉴别分析时,需选择合适的分类方法。
3 结 论
本文通过近红外光谱技术结合不同化学计量学方法对8个不同品种绿茶进行了鉴别分析,比较了单一以及优化组合光谱预处理方法对光谱的影响,利用无监督的主成分分析与有监督的线性判别分析方法分别构建了茶叶品种的鉴别模型。结果表明:绿茶样品本身形态易造成的光谱散射现象在使用多元散射校正以及标准正态变量变换预处理后得以有效消除;同时使用其它光谱预处理方法能改善光谱中存在的背景干扰以及基线漂移现象。这说明预处理可在一定程度上消除样品形态等因素所造成的干扰,组合预处理方式的聚类分析结果明显优于单一预处理方式。组合预处理方式结合无监督的主成分分析法可实现较为准确的绿茶样品鉴别分析,准确率达75.00%;采用有监督模式识别的LDA方法对茶叶原始光谱数据进行处理可实现8类茶叶的快速100%聚类分析,但该方法需提供类别的先验知识。
