基于联合正则化策略的人脸表情识别方法
2020-11-07兰凌强李欣刘淇缘卢树华
兰凌强,李欣,刘淇缘,卢树华
(中国人民公安大学 警务信息工程与网络安全学院,北京 102600)
人类表达情感的方式多种多样,但是最为直观的即是人脸的面部表情。在人与人的日常交流中,人们可以通过他人的表情,判断其心理状态,加深相互间的理解,故人脸表情识别一直受到学者的较多关注。此外,自动人脸表情识别在智能控制、安全防范、辅助医疗、自动驾驶和商业推广等人机交互领域得到了广泛的应用,成为计算机视觉领域较为活跃的研究课题。近年来,随着计算能力的不断提升以及神经网络的兴起,深度学习技术广泛应用于人脸表情识别研究,取得了显著的进展,特别是各种卷积神经网络的应用,大大提高了识别的准确率[1-3]。文献[1-3]都引入了卷积神经网络用于提取更加有效的特征,相对于传统方法[4]如LBP(Local Binary Pattern)[5]提取底层特征送入SVM(Support Vector Machine)进行分类来说,准确率有大幅度的提升。然而深度学习模型的训练需要大量的数据样本和较高的算力,使得自动人脸表情识别的准确率和实时性仍需进一步提高,因此研究加速模型训练和提高模型性能的方法成为学者关注的热点之一。
目前,大多神经网络架构在训练和测试时使用了批量正则化(Batch Normalization,BN)[6]、实例正则化(Instance Normalization,IN)[7]和组正则化(Group Normalization,GN)[8]或过滤器响应正则化(Filter Response Normalization,FRN)[9]等方法,实践表明这些方法可以加速模型训练,防止过拟合和提高模型性能。但是不同的方法仍面临一定的局限性,例如,BN方法对于batch size数值较为敏感,在其数值较大时,训练和测试结果较为理想,但是在复杂背景下或输入图片像素较大时,由于GPU(Graphics Processing Unit)显存有限,只能降低batch size,而其数值较小时,模型性能并不理想,为克服此类问题,IN和GN等方法相继提出,最近,Singh和Krishnan[9]提出FRN方法,克服BN方法的batch size依赖,但是该方法的方差对输出通道大小较为敏感。
因此,本文提出了FRN+BN、IN+GN、BN+GN等联合正则化策略,弥补单一优化带来的不足,尽可能使网络保留有效的特征信息,改善数据分布,提高模型性能。以ResNet18作为基本框架,在标准公开数据库(FER2013[10]数据集和CK+[11]数据集)上运行实验,取得了较高的准确率,实验结果表明所提方法能够提高经典网络结构性能,具有较好的鲁棒性。
1 相关工作
传统的基于图片的表情识别通常是使用手工设计并提取底层特征,例如LBP、HOG(Histogram of Oriented Gradient)[12]、SIFT (Scale-Invariant Feature Transform)[13]等,在早期,这些方法在一些数据集上都取得了较好的结果[11,14-15]。随着ILSVRC2013(Large Scale Visual Recognition Challenge 2013)的落幕,深度神经网络得以迅速的发展,并逐步应用到人脸表情识别中。深度神经网络特别是深度卷积神经网络(Convolutional Neural Networks,CNN)是提升机器视觉任务方面(例如人脸识别[16]、属性识别[17-18]和表情识别[19-20]等)重要方法。卷积神经网络可进行人脸表情深层特征提取和分类,对于各种干扰更加具有鲁棒性,因此更适合分类,使识别准确率得到显著提高。以下从人脸表情识别的神经网络架构和数据正则化两方面简要介绍。
卷积神经网络的结构受到学者较多关注。Yu和Salzmann[21]提出了新的网络,在经过卷积后的特征图中提取协方差矩阵,计算矩阵参数的二阶变换,对矩阵进行参数向量化,由此二阶统计特征也开始运用到识别上。Gao等[22]运用全局二阶统计特征提出了Gsop(Global second-order pooling)网络,可以捕获沿通道尺寸或位置维度的全局二阶统计量,充分利用图像中的上下文信息并且内存和计算复杂度都减小。Huang和Luc[23]提出了新颖的黎曼网络架构,为黎曼流形上的对称正定矩阵(Symmetric Positive Definite,SPD)深度非线性学习开辟了新的方向,且把Riemannian结构并入深度网络体系结构以压缩数据空间和权重空间。随着SPD网络的提出,Acharya等[24]把SPD网络与VGG网络相结合,把得到的卷积特征图先展开计算其协方差矩阵,再把协方差矩阵送入SPD网络中进行运算。Hamester等[25]提出了一种多通道卷积神经网络,通过结合卷积神经网络和自动编码器的信息来识别面部表情。Mollahosseini等[26]等提出具有Inception层的网络架构,把Inception运用在人脸表情识别上面,结合面部动作进行表情分析。Chen和Hu[27]提出类间关系学习网络,同时输入两张不同表情的图片经过几个Inception层得到特征图进行融合学习不同表情之间的关系,再用注意力机制送入分类器。Liu等[28]提出了一种具有可变动作部分约束的3D卷积神经网络,该网络可以检测到特定的面部部分动作并且获取到易区分的表征特征。Nguyen等[29]提出了一个基于残差网络为基础的多特征水平的融合方法,利用底层特征和高层特征的融合来辅助提高其准确率。
深度学习模型的加速和优化发展迅速,2015年,Ioffe和Szegedy[6]提出批量正则化,对经过卷积层之后的数据进行标准化,加速网络的处理速度,但是批量正则化对于批处理的大小敏感,导致批处理越小其效果越差。2017年,Ulyanov等[7]提出实例正则化,对单个图片进行处理保留图像中颜色、风格,虚拟的或现实的不敏感的特征,其效果在图像风格迁移,高分辨重组等方面具有良好表现。Wu和He[8]在2018年为克服批量正则化的局限提出了组正则化,提高了在批处理较小时的效果,但是在批处理大时并没有批量正则化的效果好。2019年,谷歌团队[9]提出了过滤器响应正则化,对于组正则化来说又是进一步的提升,其保留了组正则化的优点,同时保留了批量正则化在批处理大时的效果。
2 基本原理
正则化的基本原理是改善神经网络学习模型的数据分布情况,若没有做正则化处理,那么每一批次训练数据的分布都不一样,由于每层输入数据分布都在不断的变化,这会导致网络难以收敛。而正则化主要是对输入的数据进行标准化以提高代码的处理速度[30],防止过拟合,进而增强其泛化能力。在深度神经网络中常用的几种正则化方法有:批量正则化、实例正则化、组正则化和过滤器响应正则化。然而每一种正则化都应用在不同的领域上,批量正则化主要用于图像分类和识别问题上;实例正则化主要用于风格迁移、图像超分辨率上;而组正则化是弥补了批量正则化在批处理过小时表现效果较差而提出,在一些极端条件下可以等价于实例正则化;过滤器响应正则化不仅仅弥补批量正则化对于批处理过小时表现差同时还保持了批量正则化对于批处理大时的效果。
2.1 批量正则化
批量正则化是最早提出,也是效果最好的一种正则化的方式,其主要是通过式(1)计算其均值,再利用式(2)对每个通道进行正则化[6]。
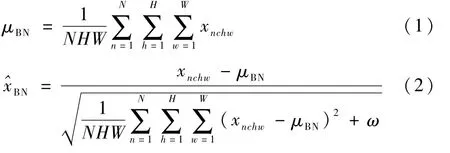
式中:xnhwc为特征张量元素值,x=[N,C,H,W]为特征张量,N为批处理的大小,C为通道数,H和W分别为特征图的高和宽;μBN为计算后特征图的均值;ω为常数;^xBN为特征经过正则化操作后的值。
批量正则化主要是针对每一个神经元,使数据在进入激活函数之前,沿着通道计算批处理的均值、方差,强制使得数据保持在均值为0,方差为1的正态分布,减少训练卷积神经网络时内部协变量的偏移,避免梯度消失,提高学习速度并且加快收敛速度,这使得批量正则化成为了一些主流的卷积神经网络架构的一部分,例如ResNeXt[31]、Inception[32]、Dense Net[33]等,批 正 则 化 也 有 一 定 的 缺点,因为均值和方差是根据训练集预先计算得出,运行通常使用平均值,因此在测试阶段没有进行正则化,当目标数据分布发生变化,训练计算出的结果也可能会产生变化,这些问题会导致在训练和测试时产生矛盾。此外,批处理的大小对于合理估计训练数据的均值和方差有较大大的影响。
2.2 实例正则化
与批量正则化不同的是,批量正则化注重每一次批处理的大小进行正则化,保证数据分布一致,因为判别模型中结果决于数据整体的分布情况。然而实例正则化是对每个批次中的单个图片进行正则化,所以实例正则化的信息都来自于自身的图片,相当于对全局信息做了一次整合和调整,但是对于各个通道之间没有信息的交流,其主要是通过式(3)计算其均值,接着利用式(4)对单个特征图进行正则化[7]。
式中:μIN为计算后特征图的均值;^xIN为特征经过正则化操作后的值。
实例正则化主要用于风格迁移和类似的任务上,因为它可以从内容中过滤出特定实例的对比信息。但是把实例正则化主要用于图像分类的问题上,相比批量正则化的结果来说稍差[34]。
2.3 组正则化
组正则化是为了解决批量正则化中批处理的大小过于小而提出的,组正则化是将通道分成组,并在每组内计算正则化的均值和方差。组正则化的计算与批量大小无关,所以其准确率在各种批量大小下都很稳定,组正则化首先是通过式(5)计算分组的均值,接着通过式(6)对分组进行正则化操作,G为对通道数C的分组大小[8]。

式中:G为通道分组数量;μGN为计算后特征图的均值;为特征经过正则化操作后的值;g为通道分组后的组标。
2.4 过滤器响应正则化
过滤器响应正则化和实例正则化是在同一个维度进行操作,对每一个样本的每一个通道:
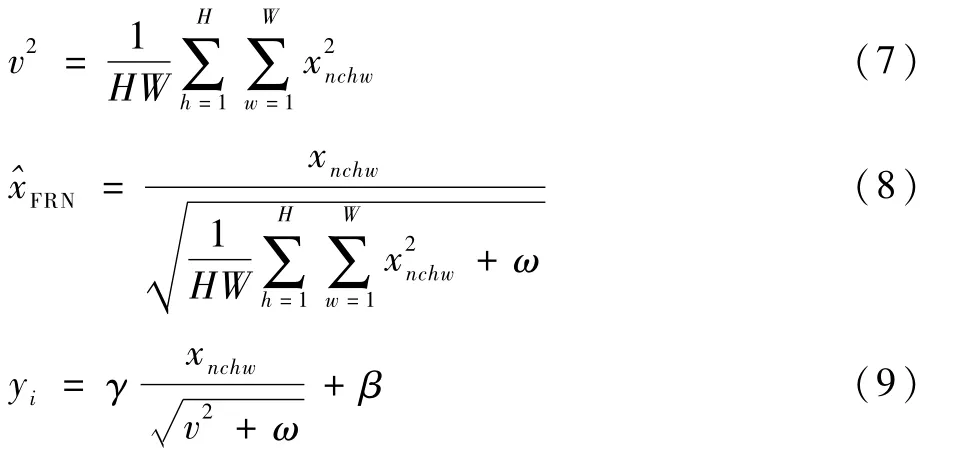
式中:γ和β为可学习的参数,通过网络的训练学习得到;v2为特征图的二次范数的平均值;为正则化后特征取值;yi为特征经过正则化操作后网络输出的值。
2.5 联合正则化
目前,绝大多数的深度网络使用的都是单一的正则化策略,该策略只能够保留其自身的优势,同时也会带来一定不足。联合正则化策略,使用了两种正则化相结合的优化方法,保存了两种正则化策略的优点,还互补了两者的不足。就4种正则化策略来说,批量正则化和组正则化保留了各个样本之间的区别,但是也使得卷积神经网络容易受到外观变换的影响。实例正则化消除了个体的对比,但是同时消减了有用的信息,过滤器响应正则化弥补了批量正则化的缺点,同时还保持了批量正则化的优点,但是不适用于非卷积运算,并且过滤器响应正则化的方差对输出通道大小敏感。上述方法都有着各自的局限性,综上考虑,提出联合正则化策略引入到网络结构中以保留各自的优势,并形成互补性。借鉴文献[35]思路,对ResNet18残差网络的基本模块进行改善,在通过第一个卷积产生64个通道后,将64个通道分成两个32通道,把这两个32通道分别送到不同正则化函数如FRN+BN、IN+GN 以 及BN+GN 再 分 别 通 过式(10)~式(12)进行正则化处理,接着把正则化过后的两个32通道拼接在一起,送到下一个卷积。
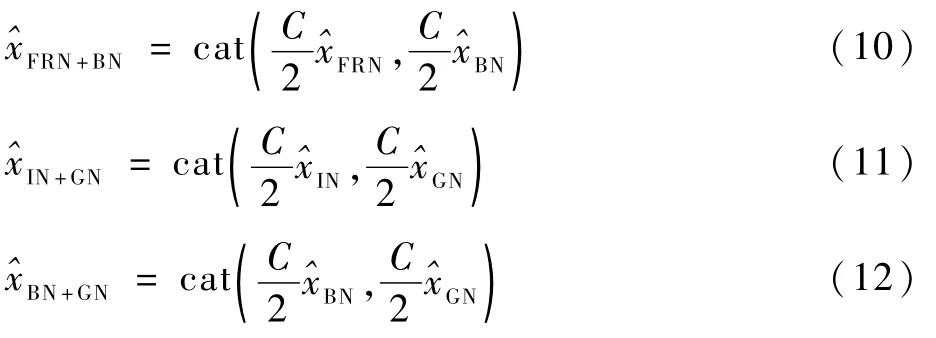
3 实 验
3.1 数据集
为评估所提出的联合正则化方法的效果和泛化性,本文在2 个典型的国际公开数据集(FER2013和CK+)上进行了实验。以下将简要介绍一下这2个数据集。
3.1.1 FER2013数据集
该数据集是由ICML(International Conference on Machine Learning)2013[10]挑战产生,是表情识别数据集中比较大的数据集,这些图片都是从谷歌图片中获取并且每张图片是在非限制条件下拍摄,所以这些图片可能带有噪声或者是质量相对较差。所有的图片都经过预处理过并且裁剪为48×48。包含了28 709张训练图片,3589张验证图片和3589张测试图片都带有7种表情标签,即生气、厌恶、害怕、高兴、伤心、惊讶和中性。这7种表情分类是基于心理学家Ekman与Friesen[36]对表情做出了定义,将表情分为6种(生气、厌恶、害怕、高兴、伤心和惊讶)适用于不同种族和文化差异的基础上,后期又添加了中性表情与其中一共构成7 种表情。图1(a)展示了FER2013各个表情分类的示例,图1(b)给出了FER2013各个表情数量的分布情况。3.1.2 CK+数据集

图1 FER2013数据集表情分类示例及表情数量分布Fig.1 Samp les of FER2013 dataset for facial expression and distribution of number of each facial expression
扩展CK+数据集用于评估人脸识别系统最广泛的实验室控制数据集。CK+包含了从123个对象中提取的593视频序列。这些序列持续时间从10帧到60帧不等,展示了从中性脸表情到高峰表情的转变。在这些视频中来自118个对象的327个序列带有7个基础表情标签(生气、蔑视、厌恶、害怕、高兴、伤心和惊讶)都是基于面部运动编码系统。与FER2013不同,CK+中用了蔑视代替中性表情并且CK+没有提供专门的训练集、验证集、测试集,所以算法的评估并没有统一。基于静态的图片方法,大多数人使用的是提取最后1~3帧具有高峰表情的帧和每个序列的第1帧(中性面),然后把这些数据分为n组,进行n倍的交叉验证实验,一般n取5、8、10。图2(a)展示了CK+表情分类的示例,图2(b)给出了CK+各个表情数量的分布情况。
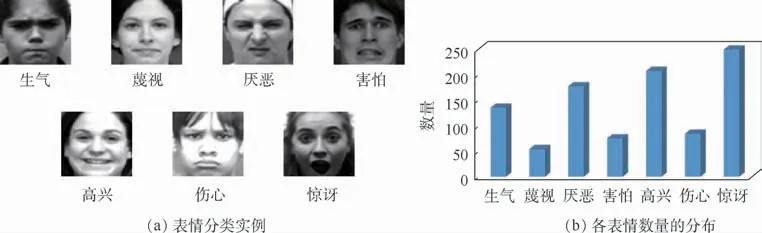
图2 CK+数据集表情分类示例及表情数量分布Fig.2 Samples of CK+dataset for facial expression and distribution of number of each facial expression
3.2 网络结构及其训练
基于ResNet18网络架构基础,提出3种联合正则化模型对网络进行优化,并用于表情识别中,把过滤器响应正则化与批量正则化、实例正则化与组正则化、组正则化和批量正则化分别组合。ResNet18包含了4个残差块,如图3中(a)表示使用了单一正则化策略(BN、FRN、GN和IN)作为基础模块。笔者把残差网络第1层卷积7×7用3×3卷积替代,因为FER2013和CK+都是灰度图像,于是把这2个数据集的图片复制成3份使得残差网络的输入为3通道,在最后一个卷积层和全连接层之间加入了丢弃层为了防止过拟合,并且在网络的最后只加了一个带有分类器的全连接层,减少了计算量。仅将所提的3种组合优化方式添加到残差网络中的前3个残差块中,最后一个残差块保留不动。对于每一个残差块,在第一个卷积层后面的批量正则化改成3种组合模式进行优化,如图3中(b)、(c)、(d)所示。
之所以不在残差网络的恒等路径上加入优化函数,是基于文献[37]中提出的对于残差网络来说不需要对恒等路径做过多的处理,否则会导致残差网络的效率降低。也不在第2个卷积层后加入组合的优化策略是为了避免匹配的问题,这样的设计是对模型容量大小来考虑,另一方面可以使用不同优化函数的优点相互结合,具有互补性。如图3中(b)所示,把过滤器响应正则化与批量正则化相结合,弥补了批量正则化的缺点,同时还继承了过滤器响应正则化优点。如图3中(c)所示,把实例正则化和组正则化相结合,这样可以利用实例正则化学习到对形状变换,比如颜色,风格,虚拟的或现实的不敏感的特征,利用组正则化对于批处理大小的不敏感性来弥补批量正则化的不足,保留其纹理信息。如图3中(d)所示,把组正则化与批量正则化相结合,用组正则化来弥补批量正则化对批处理大小敏感问题,利用批量正则化来进行各通道信息交流。
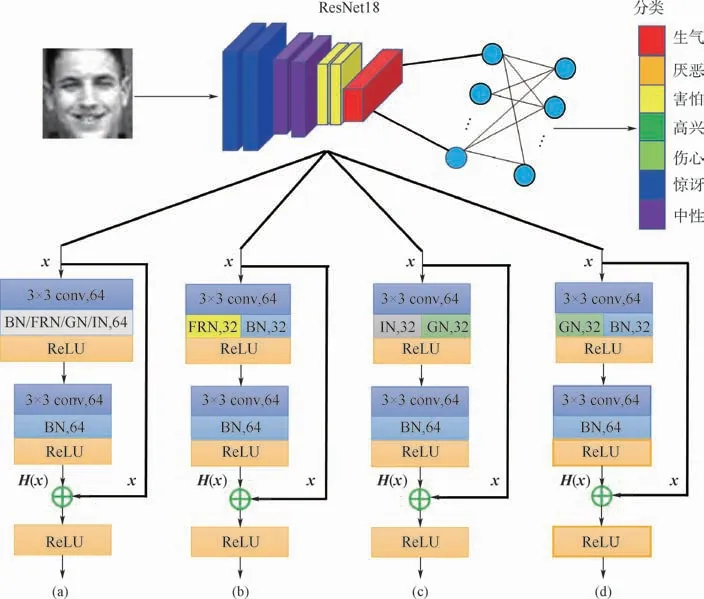
图3 网络架构Fig.3 Network architecture
实验是在Ubuntu16.04系统下利用Pytorch 0.4.1运行并且使用了Nvidia RTX 2070 GPU进行训练,权重更新使用了随机梯度下降将其设置动量为0.9,权重衰减为0.000 5。初始的学习率设置为0.01,迭代次数设置为350并且在80次迭代后开始衰减。在训练过程中,首先对面部表情分类器进行了微调,为了防止过拟合提高其准确率,其次对数据集都采取了数据增强的策略,对每一张数据集的图片随机创建了10张大小为44×44的裁剪图片。此外,还收集了每个面部表情的10张处理过的图像,通过裁剪图片的右上角、左上角以及中心等区域来测试,最后通过对这10张处理过后的图片取平均误差减少分类错误,做出判断。
在实验中,运用了所提出的3种联合正则化方案的基本框架是采用了文献[37]中的Res-Net18网络,其中的ResNet18使用单一的批量正则化进行优化。对所提出的每一种正则化方案进行了命名,将FRN+BN联合正则化称为Model1;IN+GN联合正则化称为Model2;BN+GN联合正则化称为Model3。
4 结果与讨论
4.1 FER2013数据集实验结果
表1展示了所提出的联合正则化方法及基础框架在数据集FER2013上私有测试集的性能比较,从表1可以看出,本文所提出的3种联合正则化策略相较于文献[38]中的残差网络框架的准确率都有一定的提高,其中Model1取得了最优的效果。

表1 基础框架以及添加联合正则化策略后的实验结果Table 1 Experim ental results of basic fram ework and adding join t norm alization strategies
为了比较不同数量的联合正则化对于Res-Net18的效果,在数据集FER2013上进行了测试,结果如表2所示。其中,残差网络具有4个残差块,0表示不加入联合正则化,1-2、1-3以及1-4分别表示在前2个残差块、前3个残差块以及全部残差块都加入了联合正则化。从实验结果得出,Model1、Model2和Model3加入联合正则化在浅层时能够提高网络性能,其中在前3个残差块中使用Model1取得了最优的效果,可能源于在底层中使用联合正则化能够最大可能保留了有效特征,辅助提高了准确率。但是加入在最后一个残差块时3种联合正则化模型的性能都开始下降,表明在高层中使用BN保留其抽象信息可能更为重要。
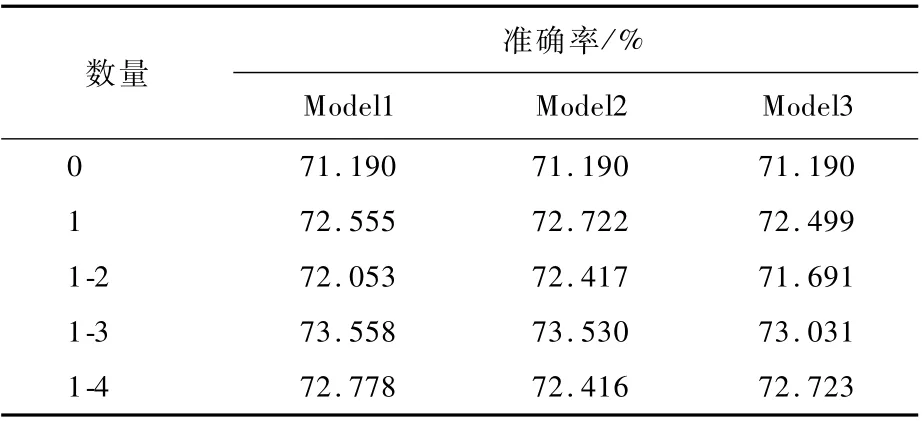
表2 残差网络添加联合正则化数量的效果比较Table 2 Com parison of im pact of adding num ber of join t norm alization based on residual network
此外,笔者对单一优化以及联合正则化进行了对比,通过对不同数量的联合正则化的效果实验,采用前3个残差块加入联合正则化(ResNet18(1-3)),为了进行对比实验,将联合正则化部分替换成单一优化,具体实验结果如表3所示。从表3可以看出,仅单一使用FRN优化的准确率为72.276%,但是Model1(FRN+BN)联合正则化达到了73.558%,与单一使用FRN相比效果有较为明显提升。仅使用IN优化与Model2相比,Model2(IN+GN)的效果提升了0.362%,Model2与Model3中都使用了GN与其他正则化函数的结合,其结果与仅使用GN的效果相比也有一定的提高。可见,联合正则化策略能够融合2种正则化方法的优点,提高网络性能。

表3 单一正则化与联合正则化(在前3个残差块中使用)的比较Tab le 3 Com parison between individual norm alization and joint norm alization(used in the first three residual blocks)
为进一步研究所提正则化策略的性能,将本文Model1、Model2以及Model3与目前已有比较新的几种方法(SHCNN[39]、文献[40]、IcRL[27]和文献[41])在FER2013数据集上进行了比较,结果如表4所示。SHCNN[39]提出了一个3个卷积层(5×5,3×3,5×5)的浅层网络,为了防止过拟合以及梯度爆炸的问题。在文献[40]中,对于基础的Softmax函数进行了研究并进行了改善,通过控制余弦值和输入特征图的大小来分析和提高Softmax函数,从而获得更加具有区分力的特征,以助于提高表情识别的准确率。文献[27]提出了一个新的网络架构(IcRL),同时从两个不同表情的图像中提取特征,然后将两个提取的特征以随机比率进行整合,从而获得混合特征。还提出了一个关注模块,为混合特征的每个像素分配权重。最后,将加权后的混合特征输入到后续的分类模块中。整个网络训练的目的是输出每个表达式的正确比例,从而学习不同类别的表情之间的相互关系,并扩大类间距离与类内距离之比。文献[41]是在类感知余量和对人脸表情识别三元组损失具有异常值抑制的基础上提出了一个新的Triplet损失函数,对于每一对表情例如高兴和害怕都分配了自适应的余量参数,并且根据特征距离分布抛弃异常的 Triplet。这些方法都在FER2013数据集上都取得了良好的效果。相比较而言,本文所提Model1取得了最高的准确率,至少提高了约1%。图4展示了Model1在FER2013上私有测试集和公有测试集的混淆矩阵。
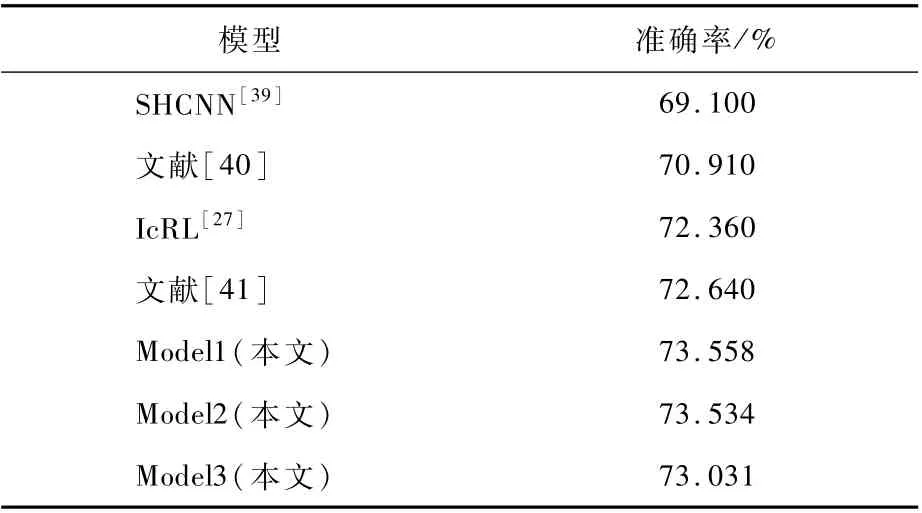
表4 本文方法与目前较新的方法在FER2013数据集上准确率比较Table 4 Com parison of accuracy rate between proposed method and state-of-the-artmethods on FER2013 dataset

图4 FER2013私有和公有测试集混淆矩阵Fig.4 Confusion matrix for FER2013 private and public test sets
4.2 CK+数据集实验结果
为了研究所提正则化策略在其他数据集上的性能,选取CK+数据集进行了实验,并与一些方法的结果进行了比较,具体内容如表5所示。对于CK+数据集使用了十倍交叉验证法进行验证。从表5中可以得出,对于CK+数据集来说,所提出的联合正则化模型相对于文献[38]的基本框架来说准确率有较为明显的提高,最多提高了5.6%。此外本文展示了Model1在CK+数据集上的混淆矩阵,如图5所示。但是其中7种表情中,蔑视使用的训练样本只有54张图片,数量较少导致其识别准确率较低,只有78%,从而影响了平均准确率。从结果可以看出所提出的正则化策略性能较好,优于部分所比较的方法,表明了联合正则化具有一定的优越性。

表5 本文方法与目前较新的方法在CK+数据集上准确率比较Tab le 5 Com parison of accuracy rate between p roposed m ethod and state-of-the-art m ethods on CK+dataset

图5 CK+数据集混淆矩阵Fig.5 Confusion matrix for CK+dataset
4.3 结果讨论
从4.1节、4.2节结果可以看出,相对于无正则化和单一正则化方法,所提出的联合正则化策略在非限制条件下和限制条件下两种数据集上表现较好,表明将联合正则化引入卷积神经网络中,可使网络既能利用单一正则化的优点,又能保留与表情相关的有效特征,从而提高网络的性能。由于没有增加通道数量,故联合正则化策略并没有增加计算量。
Model1采用FRN+BN策略,FRN弥补了BN批处理大小的问题,同时消除尺度带来的问题,而BN保留纹理相关的特征,两者结合尽可能地保留了与表情相关的有效特征,提高了识别准确率。Model2采用IN+GN策略,在底层使用IN保留例如颜色、风格等不敏感的特征,同时结合GN保留纹理信息消除对批处理大小的依赖,改善单一正则化的弱点。Model3采用BN+GN策略,表明对于单一使用BN不如使用BN和GN联合正则化的效果,在同时使用GN和BN的过程中,部分的特征图使用了GN消减了仅使用BN时对于批处理大小的过度依赖,提高了其准确率。
此外,使用联合正则化在底层保留部分除纹理以外的特征能够辅助提高分类准确率,但在高层,相关内容信息可能更为重要,因此,在底层使用不同的正则化策略利用各自的优点存储不同的特征能够更好地提高模型性能。
5 结 论
1)本文提出了3种联合正则化策略,将过滤器响应正则化与批量正则化、实例正则化和组正则化、组正则化和批量正则化两两结合,弥补单一正则化所带来的不足,尽可能保留有效的特征信息,提高网络分类的准确性。
2)Model1在国际公开数据集FER2013取得73.558%的准确率,CK+上取得了94.9%的准确率,表现效果比Model2和Model3更好并且优于诸多当前人脸表情识别方法。
3)联合正则化策略,可以尝试嵌入到绝大多数的网络框架中,加速模型训练,辅助提高其效果以及泛化能力。
