基于高置信局部特征的车辆重识别优化算法
2020-11-07窦鑫泽盛浩吕凯刘洋张洋吴玉彬柯韦
窦鑫泽,盛浩,*,吕凯,刘洋,张洋,吴玉彬,柯韦
(1.北京航空航天大学 计算机学院 软件开发环境国家重点实验室,北京 100083;2.北京航空航天大学 大数据与脑机智能高精尖创新中心,北京 100083;3.澳门理工学院 应用科学高等学校,澳门 999078)
随着监控系统智能化需求[1-2]的发展,重识别问题获得了越来越多的关注[3]。车辆重识别算法能够应用在车辆识别、追踪和定位等众多难点问题上,进一步提升公安监控系统的安全性和可靠性。车辆重识别所针对的问题是:如何在一个图片集合中快速、准确地找到与给定车辆图片中完全相同的车辆。车辆的角度、光照、环境、遮挡物等许多因素给车辆重识别带来了巨大的挑战。
车辆重识别在国内视频监控研究领域受到了较大关注。基于车辆的定位和照片的时间戳等信息的方法[4]能够利用额外的信息来优化车辆的重识别结果。基于重要局部特征的方法[5]能够为不同的局部设计权重,来影响最后拼接的特征向量。关注车辆方向差异的方法[6]能够在车辆图片计算距离时,根据具体的方向选择对应的全局特征。基于部件融合特征的方法[7]能够检测车窗和车脸区域,并将提取出的特征进行融合,利用融合后的特征计算距离,用来进行车辆的分类识别。基于特征融合和度量学习的方法[8]从降低车辆所处环境影响的角度出发,对图片进行特征表示,通过计算马氏距离来重识别车辆。基于特征融合的方法[9]可以对融合后的特征矩阵进行奇异值分解,提取特征值,并利用自适应调整算法来优化神经网络,提升算法鲁棒性。
在国外,针对车辆重识别问题也有很多有意义的研究工作。基于无监督的注意力方法[10]能够在重识别的过程中自动获得车辆的重要局部区域。在多相机系统中,以车辆三维检测结果为基础的方法[11]能够准确检测出车辆形状、颜色和方向等信息,用于改善车辆的特征。类似地,根据车辆不同的方向来确定关键点的位置[12],提取车辆的细节特征,并结合全局特征,能够提升模型的识别准确率。此外,多任务同步学习算法[13]能够在提取车辆特征的同时关注车辆车型和方向等信息,借助学习到的额外信息来改善识别结果。
车辆重识别问题的主要难点在于:在交通监控视频中,汽车数量庞大,而车辆种类有限,必然会有很多外形极为相似的车辆,区分难度较高。然而,在人类视觉中,高置信局部特征可以为相似车辆分类提供重要线索。参考类人视觉的原理,本文选取车标扩散区域作为提取特征的高置信局部区域,车标及其周边区域是车辆重要的高置信特征,几乎所有出现在交通监控视频中的车辆都可以捕获到车标信息。因此,通过提取车标扩散区域特征,可以有效增强不同车辆之间的区分度。
本文利用车辆不同区域置信度不同,提出了基于高置信局部特征的车辆重识别优化(High Confidence Local Features for Vehicle Re-Identification Optim ization,HCLO)算法。首先,利用卷积神经网络提取车辆的高置信局部特征,通过车辆关键点选取带有具体局部标记的车辆图片检测车标扩散区域,并训练好特征提取模型,对具体的高置信局部特征进行准确分割。然后,在局部区域检测阶段,与车标扩散区域一同检测的还有车窗和车灯区域,这些局部区域作为辅助局部特征,利用在特征图上截取特征张量的方式,辅助训练全局特征。通过高置信局部特征对计算得到的全局特征向量距离进行优化。最后,设计验证集,确定预测结果的最优权重参数,根据局部特征预测结果来增强目标车辆间的区分度,通过这种方式优化全局特征向量之间的距离,提升识别准确率。
本文的主要贡献如下:
1)以车辆关键点检测算法为基础,设计了车辆高置信局部区域提取算法,能够精确提取车辆的高置信局部特征。
2)训练阶段,利用车辆关键点检测算法分割出车辆关键的局部区域,辅助训练全局特征。
3)测试阶段,利用高置信局部特征的识别结果,对图片全局特征的距离进行改善,提升车辆重识别的准确率。
1 车辆高置信局部特征
1.1 高置信局部特征定义
高置信局部特征是车辆重识别的重要线索,能够作为依据精准地区分外形相似的车辆,能够作为高置信特征的局部区域需要满足2个条件:特征提取的可行性和具有区分车辆的判别能力。本文选取车标扩散区域作为高置信局部特征提取区域。
车标是车标扩散区域的核心特征,作为汽车品牌标志几乎存在于所有的交通车辆上,并且位置相对固定,一般是车头和车尾相对靠下的中央区域。在设计车标扩散区域时,为了突出品牌独特性,使消费者能够容易地与其他汽车品牌进行区分,往往会设计风格迥异的车标。此外,车标扩散区域的组成比较简单,大部分由简洁的银白色线条和图案组成,少部分使用了鲜明颜色。图1展示了部分常见的车标扩散区域。车辆品牌不同,设计风格具有明显的差异,因此,车标扩散区域成为了车辆重识别一个重要的局部特征。上述先决条件使得卷积神经网络算法能够比较容易地提取区域特征,为基于高置信局部特征区域提升区分度提供了可行性的依据。

图1 常见的车标扩散区域Fig.1 Popular vehicle brand extension regions
虽然汽车制造商的设计理念差异很大,但设计的具体汽车却有很多极为相似的车型,甚至有很多贴牌生产的车型。此外,城市监控摄像头所拍摄的图片角度比较固定,甚至无法清晰地捕捉车辆各个角度的细节。本文提取车标扩散区域特征作为高置信局部特征,提升相似车辆区分度,提高识别准确率。图2展示了测试数据集中车标扩散区域不同、外形却很相似的车辆图片,白色轿车的拍摄角度完全一致,外形也极其相似,但根据矩形框中的车标扩散区域却可以进行区分。

图2 不同车标扩散区域的相似车型Fig.2 Similar vehiclemodels with different vehicle brand extension regions
1.2 高置信局部特征区域检测
通过提取高置信局部特征优化识别结果,前提条件是要能够准确定位高置信局部特征区域,即车标扩散区域的位置信息。车辆关键点检测算法能够检测到车辆的关键点,如前后车灯、4个车轮、左右倒车镜、车窗顶点等重要位置,利用关键点坐标,可以准确定位车标扩散区域。本文利用Stacked Hourglass网络[14]获取车辆关键点,进而检测并提取高置信局部特征区域。
Stacked Hourglass网络最初被用来识别行人的姿势,为了准确地捕捉局部信息,利用漏斗形的网络在每一层都提取特征。通过这种漏斗形状结构的堆积来实现关键点的获取。本文通过改进Stacked Hourglass网络,用于车辆关键点检测。图3展示了车辆关键点的检测结果,一共检测36个关键点,对称地分布在车身两侧,用线条将相关的关键点连接,能够准确分割车辆的表面区域,进而获取车标扩散区域。其中,红色线条表示由车体左侧关键点连接所形成的车体轮廓,绿色线条表示由车体右侧关键点连接所形成的车体轮廓,蓝色线条由对称的2个关键点连接形成。
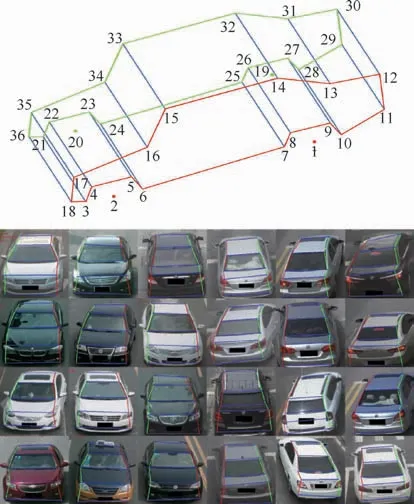
图3 车辆关键点检测结果Fig.3 Vehicle key points detection results
1.3 高置信局部特征提取
完成一致化后,利用卷积神经网络提取矩形车标扩散区域的高置信局部特征。在本文所采用的数据集中,车辆图片的车标扩散区域几乎包括了常见车辆的所有车标,对其从0开始标记序号,高置信局部特征最后会转化成具体的预测数值,便于用来计算局部特征识别的准确率。
卷积神经网络在计算机视觉领域得到了广泛应用,在图片分类、目标检测、目标跟踪等问题上具有显著超出传统算法的表现。高置信局部特征提取的网络模型以ResNet50[15]为基础进行设计改进,在网络之后设计了额外的操作。通过ResNet50网络对图片进行处理,每张图片可以得到一个三维的图片张量,维度分别为图片的高度、宽度和通道数。通过车标扩散区域检测算法能够得到车标所在矩形区域的4个顶点坐标。因为卷积后的图片高与宽在分辨率上与原图片并不匹配,所以按照现有高和宽的数值对坐标数据进行近似,使得能够在三维特征张量上切割出表示高置信局部特征的张量。将获取到的张量进行全局平均池化(Global Average Pooling,GAP)操作,该操作在通道的每一维上计算高度和宽度2个维度内的平均值,作为池化后的数值。全局平均池化操作后,张量从三维变到一维,长度与通道数相等。对向量进行1×1卷积操作,其目的是缩短特征向量的维度,减少计算过程中的误差,1×1卷积核的数量等于维度缩减后希望的向量长度。在本文提出的算法中,设置为256维。
通过上述计算步骤,对每一张图片都得到了一个256维的表示向量。此向量并不能表示具体的高置信局部特征提取结果,需添加一层全连接层,将向量的长度转化成训练集中局部特征序号的数量。再做softmax操作,使得向量数值之和等于1。

式中:x为变化前的向量;x′为softmax操作变化后的向量;len为向量的长度。
变化后的向量表示的含义是输入车辆图片高置信局部特征在各个维度上的概率。选取概率最大数值所在的维度序号作为模型所预测的局部特征。训练时,借助局部特征的真实值使用交叉熵损失函数。
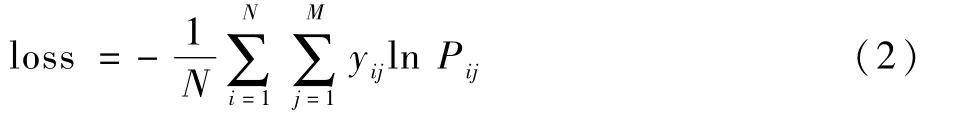
式中:N为所训练的图片数量;M为局部特征的总数;yij表示第i张车辆图片的局部特征是否为j;Pij为模型预测第i张图片的局部特征为j的概率。
在应用于车辆重识别之前,先做单独的局部特征识别准确率测试,用来验证高置信局部特征的准确性。高置信局部特征提取算法的主要计算过程可表示为
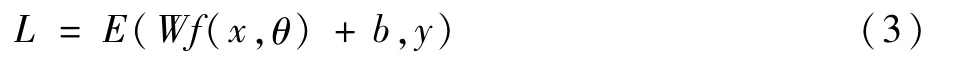
式中:E为交叉熵损失函数;W和b分别为最后全连接层的权重和偏置参数;函数f表示提取高置信局部特征的多层卷积神经网络,其参数为θ;x为原始的图片;y为局部特征的真实值。
2 基于高置信局部特征的车辆重识别优化网络
2.1 网络结构设计
图4为基于高置信局部特征的车辆重识别优化算法的网络结构。网络结构整体上可以分为2个分支:上方的高置信局部特征分支和下方的主分支。输入图片上标注的4个红色虚线矩形框表示根据车辆关键点所截取出的车标、车窗和车灯等关键局部信息,2个分支都使用ResNet50作为基础的特征提取网络,但是并不共享权重,因为主分支关注全局特征,而局部特征分支更关注车标扩散区域特征。高置信局部特征分支负责提取高置信的车标扩散区域特征,ResNet50得到的特征图大小是16×16×2 048,根据关键区域信息对其进行切割操作,得到的车标扩散区域特征图大小为5×5×2 048,再进行全局平均池化操作和1×1卷积操作,高置信局部特征的维度变化为1×1×256;最后经过全连接层,计算损失函数。主分支负责提取车辆图片的全局特征,用来计算目标车辆间的距离,将ResNet50得到的特征图分割成4个部分,在图4中,使用4个颜色不同的长方体表示,分别表示全局、车标、车灯、车窗;每个部分的计算流程与高置信局部特征分支处理车标扩散区域的步骤一致,最后计算4个损失函数。
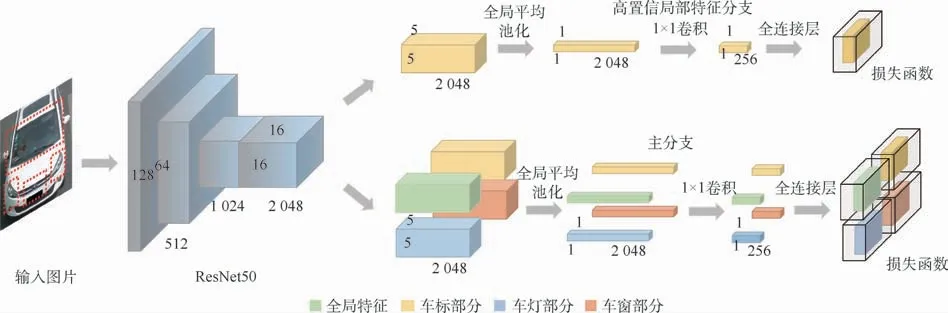
图4 基于高置信局部特征的车辆重识别优化算法网络结构Fig.4 Network structure of vehicle re-identification optimization algorithm based on high-confidence local features
受Part-Regularized网络模型[16]启发,本文算法利用提取局部信息作为辅助局部特征的方式来补充全局特征,使向量的表征能力更强。车辆关键点检测算法除了获取车标扩散区域以外,还获取了车灯区域和车窗区域。在主分支中,车标扩散区域信息被重复利用。与高置信局部特征分支中抽取局部张量类似,提取ResNet50的输出张量能够得到3个局部信息,其中车灯的局部有2个,提取后取平均值。此时,局部特征连同全局特征共得到4组特征张量。对每一组特征都进行全局平均池化操作和1×1卷积操作,将三维的张量转化成一维向量,计算损失函数。
2.2 损失函数
除高置信局部特征分支外,主分支里共需要计算4个损失函数,包括全局特征和辅助局部特征,具体分别为全图特征、车标辅助特征、车窗辅助特征和车灯辅助特征的损失函数。4组特征的真实值都设置为车辆真实ID。在测试过程中,并不将4组特征进行拼接,而是只使用全局特征作为计算距离的向量。所以,在训练过程中,另外3组局部特征只是起到辅助全局特征进行训练的作用。主分支的损失函数与高置信局部特征分支相同,都使用交叉熵损失函数。

式中:r表示4个特征,即全局、车窗、车灯和车标;Wr和br分别为对应的全连接层的权重和偏置参数;fr为提取关键区域特征的函数;yID表示图片对应的真实车辆ID。
所以,主分支的总损失函数为

式中:r根据式(5)选取数值;Lr为对应特征的损失函数。总损失函数为各个损失函数的加总。
2.3 高置信局部特征优化
车辆重识别问题,是在一个图片集合中找到与给定车辆图片完全相同的车辆。给定的图片命名为query集合,要在其中搜索的图片集合命名为gallery集合。对于每张图片,本文算法模型都会得到表征向量和高置信局部特征预测值。为了在gallery图片集合中找到与query图片最相似的图片,相似度的计算方式采用计算全局特征向量之间的欧氏距离:

式中:dist为计算得到的距离;a和b分别为需要计算距离的2个长度相等的向量。
按照gallery集合中每张图片与query图片的距离从小到大,对gallery数据集中的图片按照相似度从高到低进行排序,获得高置信局部特征的相似度度量结果。该结果被用来改善排序后的gallery序列。
在车辆重识别中,车辆完全相同的2张图片,局部特征必然一致。高置信局部特征不同的图片,则表示确定的不相同车辆。根据这一点,可以根据局部特征的相似度度量结果来改善图片间距离,通过添加权重参数的方式使得局部特征预测2张相同图片的距离适当缩短。

式中:wij为施加在第i张query图片和第j张gallery图片距离上的权重参数;λ为一个小于1的正实数常量;pred函数表示预测高置信局部特征的神经网络,其输出是一个具体的局部特征相似度数值。
获得的权重参数与原始的向量距离相乘,可以获得更新后的向量距离:

式中:distij为第i张query图片和第j张gallery图片向量的原始欧氏距离;为更新后的距离。
如果对于2张图片算法预测的高置信局部特征相同,因为参数λ是小于1的,所有向量距离会缩短,图片的相似度提高,在排序后的gallery序列中更靠前。若预测的局部特征不同,则距离保持不变。通过这种方式,利用高置信局部特征实现了图片的区分度优化。此外,为了设置一个合适的λ值,需要额外设计验证数据集以获得一个合适的数值。
2.4 算法流程
在主分支和高置信局部特征分支的基础上,本文算法的流程如图5所示,步骤如下:

图5 本文算法流程Fig.5 Proposed algorithm flowchart
步骤1划分高置信局部特征训练和测试的数据集,对局部特征进行排序,标记训练集中所有车辆的局部区域。
步骤2训练模型中的高置信局部特征分支,对于每张输入图片都能得到预测的具体局部特征,并将训练好的模型在单独的数据集上做测试,使其能获得较好的识别表现,否则重新训练。
步骤3划分车辆重识别训练和测试的数据集,检测所有车辆图片的关键点坐标,划分需要的局部区域,将得到的区域坐标信息以图片名称为索引全部保存到一个文件中。
步骤4读入车辆图片和相关的局部区域坐标,训练车辆重识别的主分支。
步骤5引入高置信局部特征结果,在公开数据集中,寻找没有参与模型训练和测试的图片,设计验证集。在验证集上以不同的参数λ不断地进行测试,记录每个数值的识别表现结果,选取最优的λ数值。
步骤6在车辆重识别测试集上评估本文算法模型的表现,计算性能量化评估指标。整理其他车辆重识别算法的结果,最后进行结果的对比和分析。
3 实 验
3.1 实验数据集
实验所采用的数据集是 VehicleID 数据集[17]。VehicleID数据集是使用最频繁、关注度最高的车辆重识别数据集之一,并且有着丰富的车辆信息标注。训练集共有图片110 178张,车辆ID的数量为13 164。因为测试的图片很多,所以数据集作者设计了3个大小的测试集,分别命名为small、medium和large,其中所具有的车辆ID数量分别为800个、1 600个和2 400个。在3个测试集中,不对query集合和gallery集合进行划分,在测试时,需要在每个ID的几张图片中,随机抽取一张图片加入gallery集合当中,剩余图片自动并入到query集合中。所以,各个尺寸的测试集中,gallery集合大小与车辆ID数量相等,对于每一张query图片,gallery中只有一张相同车辆图片。VehicleID数据集的具体信息可参见表1。
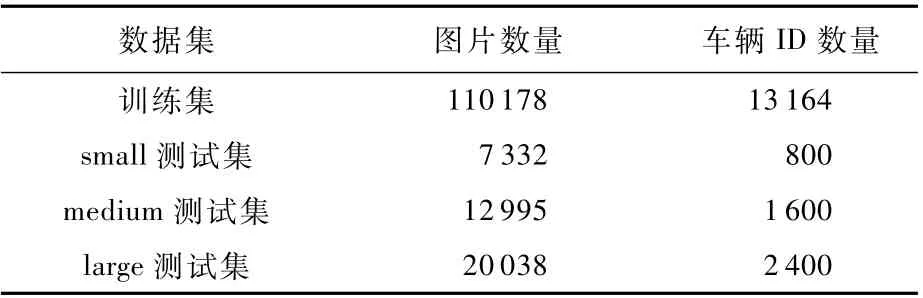
表1 VehicleID 数据集信息Table 1 VehicleID dataset inform ation
此外,VehicleID数据集还有一个重要特点:所有车辆都是正面或背面图像。尽管一小部分车辆图片存在轻微歪斜,但正面车头车窗或者背面车尾信息并无丢失。基于高置信局部特征优化距离的方法所需车标扩散区域都存在于车辆正面或背面,因此,VehicleID数据集这一特点满足本文算法模型所需条件。在训练全局特征向量时,需使用的车灯、车窗等辅助局部信息也可以比较容易地获得。
3.2 评估指标
在排序后的gallery图片序列中,只有一张图片是真实值。实验使用top-K作为重识别结果的评估指标,表示在排序后的gallery序列里前K张图片里包括真实值图片的概率,K常见的取值有1、5和10。具体的计算公式为

式中:Q为query数据集的图片数量;gij为第i张query图片和第j张图片所代表的车辆是否相同,若相同,其值为1,否则,其值为0。
3.3 实验参数设置
车辆关键点检测算法以Stacked Hourglass网络为基础,共标记36个关键点。每个batch的大小设置为4,共有200个epoch,每个epoch设置了1 000次迭代,初始的学习率设置为2.5×10-4。训练过程中,当准确率连续5次处于平稳状态时,下降学习率,当前的学习率变为0.96倍。
多层卷积神经网络的训练条件十分繁杂,相同的网络结构、不同的训练条件,模型会有截然不同的表现。在本文实验中,主分支的训练使用梯度下降法修改权重参数的值,迭代次数为240次。训练过程中,参数的学习率对模型表现有很大影响,本文实验中,学习率初始值设置为0.1,在150次迭代时学习率下降到0.01,在220次迭代时学习率再下降到0.001。当学习率不变时,训练的损失下降到一定程度后不再继续下降,在一定范围内振荡。采用学习率衰减的策略进行训练可以避免这一情况的发生,让模型训练更充分。batch大小设置为64。输入图片全部将大小一致化为256×256像素,以增强数据。
在本文模型使用的ResNet50网络中,最后一层降采样过程里,原始步长(stride)设置为2。降采样的目的是为了缩小特征图的空间尺寸,便于后续操作。但图片分辨率越高,容纳信息也就越多。为了提高特征图的表示能力,本文算法将ResNet50最后降采样的步长设置为1,通过传递更多信息的方式来提升模型表现。
此外,随机消除(Random Erasing)[18]也是一种数据增强策略。为了模拟图片中存在遮挡物的现象,对于部分图片可以随机选择一个矩形区域消除掉所有的像素值。对于每一张图片,设使用随机消除的概率为pre,本文实验中设置为0.5。随机选取一个点的坐标(p,q),再随机选取一个矩形的长length和宽width;如果(p+legnth,q+width)所表示的点不在图片之中,则重新随机;直到(p+legnth,q+width)在图片之中为止。这样就得到了一个矩形对角线的2个顶点,在该随机过程中,将矩形的纵横比限制在一定范围内,矩形面积与整张图片面积的比例设置为0.02~0.3之间。所选矩形内的像素并不全部清除,而是设置为各个像素点的平均值。通过这种方式,每张输入图片都有0.5的概率会有一个矩形区域覆盖掉,模拟了实际中存在遮挡物的情形,增强了模型的泛化能力。
3.4 高置信局部特征模型的训练分析
高置信局部特征分支需要在主分支训练和测试之前进行训练,才能将局部预测结果应用到主分支当中。VehicleID数据集中标记了一部分图片的车型,车型总数共计250个,对这些车型按照是否具有相同车标这一标准进行聚类,可以得到46种不同的车标扩散区域。对于高置信局部特征模型的训练,一共选取50 000张图片,其中40 000张图片用来训练,10 000张图片用来测试车标扩散区域识别的准确率。计算识别准确率的公式为
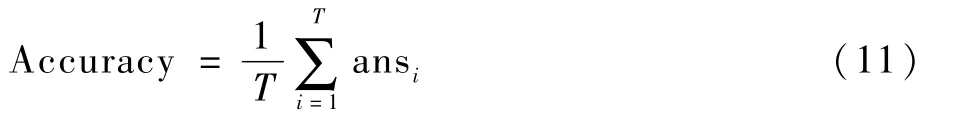
式中:T为车标扩散区域识别测试集中的图片数量;ansi为第i张图片的局部特征预测结果,若预测正确,其值为1,预测错误,其值为0。
在实际实验中发现,虽然标注了车型的图片和用于重识别问题的图片都来自于同一数据集,但是二者本身存在较大差异:前者的图片一般比较清晰,分辨率较高,细节特征很突出,可以借助这些信息标注车辆的具体车型;而后者大部分图片不够清晰,分辨率较低,存在遮挡,光照条件也不尽相同。为了解决这一问题,尽可能地消除或降低2类图片的差异,本文实验在高置信局部特征提取的训练集中,加入了重识别训练集中标注车标扩散区域的部分图片,使得新的高置信局部特征训练集的车标扩散区域总数增加到了93个,图片总数为44 024张。车标扩散区域种类的具体分布可参见图6,因为部分车标非常常见,对于这样的图片只选择2 000张加入训练集中,确保每种车标的扩散区域至少有一张图片。

图6 车标图片分布Fig.6 Image distribution of vehicle brands
训练过程中的每次迭代只训练93张图片,即每次迭代中每种车标都会被训练,迭代次数为6000次,学习率初始值设置为0.1,3 000次迭代后学习率下降为0.01,5000次迭代后学习率下降到0.001。虽然迭代次数很多,但每次迭代训练的图片很少,所以全部的训练过程只需要5~6 h就可以完成。在测试集上的高置信局部特征准确率为98.4%,这充分说明了局部特征识别结果的可信程度,为后续局部特征识别结果的应用创造了前提条件。
为了将车标扩散区域的识别结果应用到车辆重识别问题中,需要确定权重参数λ。因为VehicleID数据集中有大量可用于测试的车辆图片,标准测试集只是抽取了一部分,所以可以选择一部分没有用到的图片作为验证集,来确定参数最优值。本文实验选取了400个车辆ID,共计3 136张图片做验证集,并划分验证集的query集合和gallery集合。在验证集上的测试,权重参数λ从1开始,以0.01为跨度逐渐减小。实验结果如图7所示,横坐标为权重参数λ,纵坐标为验证集在该条件下top1的识别准确率。
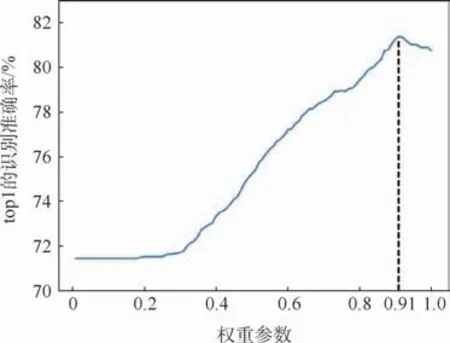
图7 验证集上的实验结果Fig.7 Experimental results on validation set
当权重参数λ刚开始下降时,top1的识别准确率逐渐上升,在权重参数λ为0.91时达到峰值。此后,随着权重参数λ的下降,top1的识别准确率略有下降。因此,本文实验中,权重参数λ的最优值取0.91。在后续车辆重识别的实验中,也将权重参数λ设置为0.91。
3.5 实验结果与分析
本文算法与各算法在VehicleID数据集上的对比可参见表2。OIFE模型针对不同方向的车辆图片,能够将提取得到的特征转化为一个方向无关的向量,以尽可能消除或降低车辆方向差异带来的影响。NuFACT模型能够根据车辆的不同方向来提取特征,同时为了保证模型运行的效率,还对特征向量进行一定程度的降维。VAMI模型也重点关注图片中车辆的不同方向问题。C2F模型设计了coarse-to-fine损失函数,将相同车辆的图片尽可能拉近,将不同车辆的图片拉远。RAM模型从局部区域抽取特征,重要的局部区域会包含可以分辨相似车辆的重要细节。根据表2的对比结果显示,本文算法在VehicleID数据集的top1识别准确率上均好于其他算法。
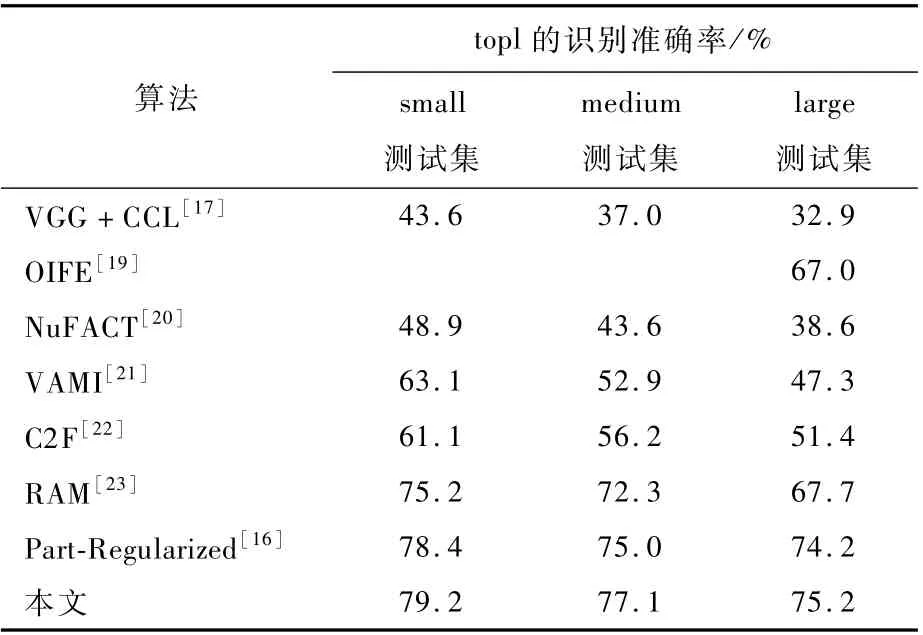
表2 不同算法top1的识别准确率对比结果Tab le 2 Top1 recognition accuracy results of d ifferen tm ethods
本文算法模型以Part-Regularized网络模型为基础进行改进,使用车辆关键点检测算法来获取车灯、车窗和车标等关键的局部区域。同时检测车标扩散区域,在重识别的测试阶段,将高置信局部特征预测的结果添加到向量距离计算的过程中,使得局部特征识别相同的车辆的向量距离更近。实验结果表明,在VehicleID的3个测试集中,top1的识别准确率均有明显提升,分别提升了0.8%、2.1%和1.0%,证明了本文算法模型的有效性。
单独使用一个分支的车辆重识别准确率结果可参见表3。仅使用主分支,VehicleID的3个测试集的重识别准确率分别为78.4%、75.9%和74.4%。仅使用高置信局部特征分支,准确率分别为24.1%、18.9%和15.5%。2个分支都使用本文算法。结果显示,2个分支均使用的情况能够获得最高的重识别准确率,并且比只使用一个分支均有明显提升。

表3 top1的识别准确率消融对比结果Tab le 3 Ab lation com parison resu lts of top1 recognition accuracy
4 结 论
本文提出了一种基于高置信局部特征的车辆重识别优化算法,具有以下特点:
1)具有提取高置信局部特征的分支,能够准确检测并识别车标扩散区域,识别准确率高达98.4%。
2)重点关注车辆的辅助局部信息,利用车辆关键点检测算法,检测车辆的车灯、车标和车窗区域,以Part-Regularized网络为基础,利用局部信息来辅助训练全局特征。
3)将高置信局部特征引入到图片间距离计算的过程中,通过设置验证集确定具体的权重参数。实验表明,本文算法的重识别top1的识别准确率有明显提升。
