面向个体人员特征的跨模态目标跟踪算法
2020-11-07周千里张文靖赵路平田乃倩王蓉
周千里,张文靖,赵路平,田乃倩,王蓉,3,*
(1.中国人民公安大学 警务信息工程与网络安全学院,北京 1 0 0 0 3 8; 2.北京市公安局,北京 100740;3.安全防范技术与风险评估公安部重点实验室,北京 100038)
个体人员的跨模态目标跟踪在视频智能分析、无人驾驶、自主系统导航等各个领域都有着广泛应用,特别是在公安视频监控信息深度挖掘分析方面。传统目标跟踪对象非常多样,包括动物、人、物品、车辆、飞机等一切可以移动的对象,而在实际应用或某一领域内,重点关注的往往是某一类别的对象,如交通领域关注的主要是机动车、物流领域关注的是物品等,针对特定类别对象目标跟踪开展研究能够为具体应用提供更具针对性的模型和方法,有很强的实用价值。
本文将跟踪目标聚焦在个体人员上,主要有如下考虑:①在复杂场景下对个体人员开展跟踪具有较强的技术挑战性,特别是在自然环境下多个人员同时出现时,类内干扰是制约跟踪性能的主要问题,主要原因在于当前跟踪器主干网络的预训练基于图片分类任务,对于对象类别不敏感,单纯依靠视觉特征进行区分难度较大,如何利用多维度信息解决这类问题具有学术研究价值。②个体人员的跟踪问题在多个领域有着广泛的应用,如公共安全智能视频监控、无人驾驶对道路行人检测、机器人导航避障、个体生物特征步态识别等,都需要对人员目标进行跟踪,而目前针对具体对象的跟踪算法研究比较缺乏,对这些问题开展研究具有很强的实用价值和应用前景。③将语言先验知识与视觉任务进行结合的研究方法具有很强的研究意义。单纯以数据驱动的深度学习模型在可解释性、鲁棒性、稳定性上都存在一定的局限性,实际应用中用户都有任务意图,如何将这种意图反映到算法中实现真正的任务驱动具有非常重要的现实意义,而利用先验知识协同视觉模型完成跟踪任务实现了知识驱动与数据驱动的结合,将能够在多个方面提升算法能力,且能够应用在多种视觉任务上。
综上,本文提出了跨模态的个体人员目标跟踪框架,该框架结合了自然语言特征和视觉特征,增强了个体人员跟踪的鲁棒性,有效降低了类内干扰给跟踪性能带来的影响。为保证训练和检验本文算法的有效性,构建了基于个体人员特征的专用目标跟踪数据集,并进行了仿真验证,本文算法在专用数据集上的表现也超过了现有主流算法模型。
1 关键技术
1.1 视觉单目标跟踪
目前,从目标跟踪算法上来说,单目标跟踪算法可以分为基于检测和基于模板匹配两大类。基于检测的目标跟踪算法以相关滤波跟踪为主,将待搜索图片输入相关滤波器,计算与目标区域的相关响应,根据相关性计算得分来区分前景和背景,此类算法在跟踪速度和准确性上都取得了很好的效果。随着深度神经网络的不断演进发展,基于模板匹配的目标跟踪算法开始引入相关模块,孪生匹配网络首先被应用于目标跟踪任务中[1],在此基础上利用区域推荐网络[2]、注意力机制[3]、更深更宽的主干网络[4-5]、数据增强训练[6]、强化学习[7]、模板更新[8]等方法,能够进一步提升性能。但是目前性能最好的跟踪器,在对外表特征相似的同类对象区分上也存在不足,这种情况在针对个体人员的跟踪上尤为突出。
1.2 视觉引用表达
近年来,将自然语言处理应用于计算机视觉中的研究得到了广泛关注[9]。本文重点关注的视觉引用表达(Referring Expression 或 Visual Grounding),其是指在接收一张图片和一个语言指令或描述之后,定位出图片当中与语言描述相关的目标。文献[10]利用卷积神经网络(CNN)和长短时记忆单元网络(LSTM)分别从图片和语言描述中抽取特征拼接后训练,完成图像的分割任务,如图1所示,左图为原图,中图为分割标准,右图为预测结果,语言描述为:man in blue shirt in the right side。文献[11]提出了利用语言进行目标跟踪的3种模型。MAttNet[12]将语言描述划分为主语、位置和关系3个部分,并用不同模块与图像进行联合处理训练获得图像分割。近期的一些研究着眼于将最新的BERT架构引入视觉与自然语言融合处理的领域,在视觉应用表达上也取得了不错的效果[13-14]。

图1 视觉引用表达图像分割示意Fig.1 Image segmentation of visual referring expression
1.3 目标跟踪数据集
数据集是用来对模型算法进行训练、评估和测试的基础工具,目前目标跟踪领域的数据集非常丰富。OTB(Object Tracking Benchmark)[15-16]在2013年和2015年分别推出了包含50个和100个视频的数据和标注;2013年推出的VOT(Visual Object Tracking)包含16个短视频序列,而后每年进 行 更 新;2017 年 发 布 的 NFS(Need for Speed)[17]包含100个高帧率视频;TrackingNet[18]包含30 132个视频;GOT-10k[19]包含10 000段视频;LaSOT[20]包含了70类1 400段高密度标注的视频。但是还没有专门针对个体人员跟踪的数据集,要想训练出适应于复杂场景下跨模态的跟踪模型,需要有定制的专用数据集。
2 跨模态目标跟踪模型
本文提出利用语言先验知识对个体人员目标跟踪进行监督和引导,充分利用非视觉信息,辅助视频信息的分析处理,提高特定人员目标跟踪的精确性,提升目标的发现和追踪能力,为视频数据与其他异构数据和知识进行关联融合提供一种新的思路和方法。
2.1 整体框架
该框架主要分为3个模块(见图2):基于Siamese孪生架构的视觉跟踪模块、基于递归神经网络(RNN)的语言引导模块、基于IoU交并比优化的融合判别模块。模型从数据集中第1帧图像的标注(Ground Truth)获得跟踪目标特征,与要跟踪的后续视频帧一起作为输入送入视觉跟踪分支进行视觉判别;语言引导分支将语言描述和被搜索视频帧作为输入,通过语言模型处理在图片中描述确定要跟踪目标的位置和范围,形成注意力蒙版;将视觉分支和语言分支输出的结果分别送入融合判别模块,根据视觉跟踪模块输出的分类置信度与基于交并比IoU的位置置信度选出最佳目标框,再通过位置框优化,最终输出结果。

图2 跨模态目标跟踪整体框架Fig.2 Cross-modal object tracking framework
2.2 基于Siam ese孪生架构的视觉跟踪模块
视觉跟踪模块基于SiamMask模 型[21],将ResNet-50[22]作为视觉特征抽取主干网络,输出256维的目标跟踪对象和搜索帧的特征图;再对特征图进行深度交叉相关运算,得到多通道响应图,该响应图是对目标跟踪对象和搜索帧视觉相似度的编码;基于该编码通过区域推荐网络(RPN)[2]生成目标候选区域(分类置信度),并通过回归优化更准确地定位目标区域(位置置信度)。Siam-Mask采用最高分类得分值选出最终目标框,本文将采用位置置信度和分类置信度相结合的方式获得更加准确的结果。
2.3 基于RNN的语言引导模块
语言引导模块借鉴DMN[23]的网络结构,分别使用CNN和RNN来提取每帧图片和描述语言的特征。利用LSTM 的升级版SRU模块处理词嵌入et后的句子隐含状态ht,再将其与词嵌入进行拼接得到状态语言特征rt。

借鉴文献[11]的思想,利用动态滤波器处理rt后得到fk,t,与视觉特征IN进行卷积获得Ft,将语言特征、视觉特征和位置特征进行拼接后用1×1卷积得到特征响应图Mt。
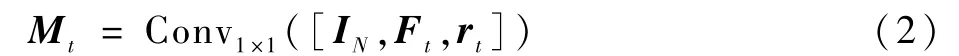
用双插值进行上采样后,获得与原始图片尺寸一致的蒙版响应图,用最小封闭矩形框(MER)计算得到基于位置的目标框。为了确保该模块对人员特征的提取有效性,利用专用数据集进行了针对性训练,使该模型对类内干扰、人员移动、遮挡、模糊等问题具有更强的判定识别能力。
2.4 基于IoU交并比优化的融合判别模块
在获得视觉特征推荐和语言引导的定位后,该融合判别模块负责利用位置置信度和分类置信度获得最佳目标框。首先,将视觉跟踪模块推荐分类得分最高的50个候选框提出,再计算它们与语言引导模块所得目标框的重叠率IoU,根据IoU得分的高低来确定最佳目标框。受IoU guided NMS[24]启发,临近的候选框对于精确定位仍有价值,因此基于位置得分最高的候选框,找出分数排名前20的其他候选框,用IoU值作为权重,计算得到需要微调的位置坐标。然后,对位置得分最高的候选框进行微调处理,获得最终回归的目标框。融合判别模块有2个功能:①基于位置置信度和分类置信度选择最佳的候选框;②基于相邻众多候选框,对最佳候选框进行微调优化,获得最终目标框结果,如图3所示,粉色框为SiamMask分类最高分的框,蓝色框为语言引导模块生成的框,绿色框是利用位置置信度和分类置信度获得的结果。语言描述为:man walking along the street。

图3 多模块回归预测结果Fig.3 Results ofmultiplemodules predicted regression
3 专用数据集构建及技术实现
3.1 专用数据集构建
本文旨在研究个体人员特征的目标跟踪任务,现有数据集无法满足需求,需要构建针对个体人员专用数据集进行训练。①目前通用数据集中没有专门针对人员个体跟踪的数据集,通用数据集都有部分个体的视频数据片段和标注,需要将这类数据进行汇集整合,供模型训练、评估和测试用;②目前的单目标数据集中除LaSOT和lingual OTB99[11]外,都没有提供自然语言的描述标注,因此在引入语言引导模块时,没有语言描述数据可用,需要构建专用数据集支持这类模型。基于此,本文构建了PerTrack专用数据集,从多个数据集中收集了以人员为跟踪目标的视频数据,按照固定格式对数据标注和语言描述进行整理,对没有语言描述的数据进行补充。从GOT-10k获取了58个视频,从LaSOT获取了20个视频,从OTB获取了25个视频,视频片段都与人员相关,类别包含跳舞、短跑、路人、歌手、滑冰、马拉松等与人相关的场景。另外,按照7∶1∶2的比例,对人员目标跟踪数据进行训练集(Train)、评估集(Trainval)和测试集(Test)的分类。每个具体的视频文件夹下,除了每个视频帧的图片外,提供了标注Ground Truth(GT);还提供了自然语言的描述文本和根据Ground Truth生成的双值目标分割蒙版,用于为DMN模型提供训练。经过前期工作,目前从不同渠道收集到针对人员的视频数据103段,共90 926帧:73段用于训练,共63 818帧;10段用于评估,共8292帧;20段用于测试,共18816帧。
3.2 技术实现
为使视觉跟踪模块和语言引导模块分支保持非相关性,进行了独立的训练。前者采用Siam-Mask的预训练模型,后者使用专门数据集进行训练和优化,最后在决策层进行融合。
在数据预处理阶段,将专用数据集中的标注Ground Truth转化为二值蒙版供训练使用,由于跟踪数据集标注的Ground Truth提供了左上角坐标cx、cy和目标框宽度w,高度h,需要将其转化为二值蒙版供语言引导模块使用。将目标框内的值设为255,目标框外的值设为0,就形成训练数据。
在语言引导模块的参数优化和微调阶段,将DMN模型的预训练权重作为参考。DMN的预训练模型参数是基于ReferIt[25]进行训练的,ReferIt针对具有19 894张图片和130 525个语言描述开展训练,但适应跟踪的模型参数有所不同。针对人员特征的目标跟踪任务,需要用到本文构建的训练数据集进行训练。因此在本文实验中,分别将模型在低分辨率和高分辨率下训练7个和5个epoch,获得最终的模型参数。
在测试阶段,将DMN网络输出的蒙版利用最小封闭矩形框进行变换后输出结果,如图4所示,右图为通过语言引导模块输出的结果,通过最小封闭矩形框获得目标框,左图为在视频某帧上的对应展示,语言描述为:girl in yellow shirt with purple pants,与视觉跟踪模块输出进行融合。

图4 最小封闭矩形框生成图Fig.4 Illustration ofm inimum enclosing rectangle
4 实验与结果分析
利用自建的数据集对模型进行训练,得到实验需要用到的参数。主要完成3组实验:①对语言引导模型在执行跟踪数据训练前后的效果进行对比评估;②选用部分主流跟踪算法在自建数据集上测试评估,与本文算法的性能作对比;③在不给出第1帧跟踪目标的情况下,直接用语言引导模型检测被跟踪对象测试结果的评估。
4.1 语言引导模块评估
所有参数训练都是基于DMN在ReferIt数据集预训练的基础上开展的,针对不同的训练数据生成不同参数,对比测试评估不同数据集训练后的模型参数对人员个体目标检测任务的效果。测试效果用平均交并比m IoU来评估,其是衡量图像分割精度的重要指标。计算平均真实值和预测值的交集和并集之比,即在每个类别上计算IoU值,再在所有类别上求平均即得m IoU。表1中,参数0表示只在ReferIt数据集训练的结果,参数1表示在参数0的基础上,在lingual OTB99上做微调的结果,参数2表示在参数0的基础上,在lingual OTB99和LaSOT上做微调的结果,优化参数表示在参数0的基础上,在专用数据集Per-Track的训练集上的结果。

表1 语言引导模块评估结果对比Tab le 1 Com parison resu lts of language guided m odu le
从表1分析对比看出,不同数据集对语言引导模块效果有着直接影响。lingual OTB和LaSOT都是不分类别的目标跟踪数据集,而本文采用的是针对人员类别的数据集,因此在针对人员跟踪检测的评估集上的测试结果上来看,效果有了大幅度提升。
另外,利用语言引导模型还对lingual OTB99的评测结果进行了对比实验,目的是评估针对特定跟踪目标类别训练后的参数对通用数据集的影响。
从图5结果进行分析,对比的跟踪器为主流孪生网络跟踪器,包括SiamMask[21]、SiamRPN[2]和Siam FC[1],其中LangTrack为用通用数据集训练的模型参数,取得了最优效果,PerTrack为用行人专用数据集训练的结果,效果比利用纯视觉信息的主流跟踪器的效果差。结果说明,在通用目标跟踪任务中采用专用数据集训练,会使模型具有对专用目标的偏向性,导致整体效果欠佳,说明模型是具有类别敏感性的。
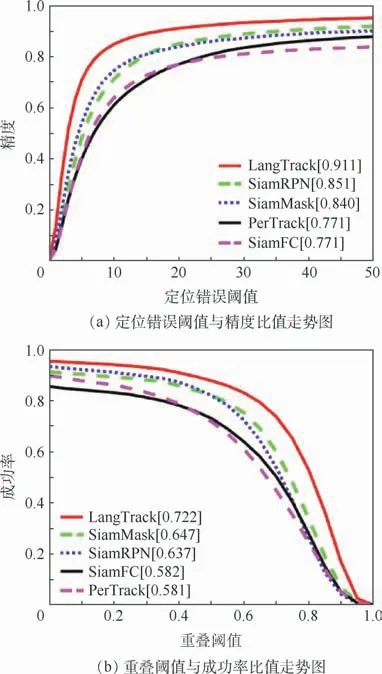
图5 主流跟踪器的结果比较Fig.5 Comparative results among mainstream trackers
4.2 跟踪任务评估
为了将本文设计的模型与主流跟踪算法在行人跟踪专用数据集上的表现做比较,对当前最新的单目标跟踪算法进行了测试,结果如表2和图6所示。相比于原有纯视觉模型,增加语言引导模块有效提升了算法的准确性和鲁棒性,同时也超越了现有主流跟踪算法的性能,但跟踪速度只能达到4帧/s,低于现有主流跟踪算法,原因在于语言引导模型的运行影响了跟踪处理速度。算法性能的提升主要得益于专用数据集的训练和语言先验知识的监督。本文采用一遍成功率(One-Pass Evaluation,OPE)作为评估指标,即运行一次跟踪算法,获取每一帧跟踪目标的位置和大小,由平均精度和成功率对其进行评分。
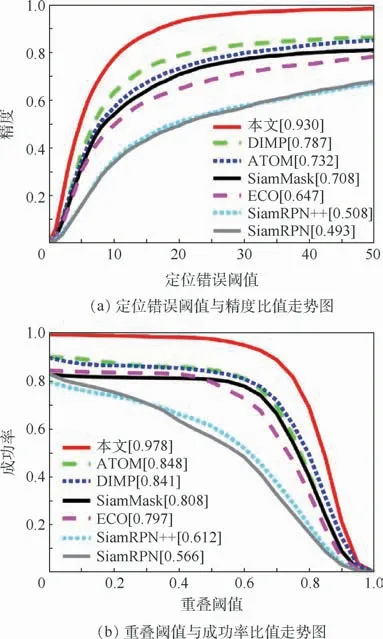
图6 本文模型与主流跟踪算法的OPE评估结果Fig.6 OPE evaluation results between proposed model and mainstream tracking algorithms
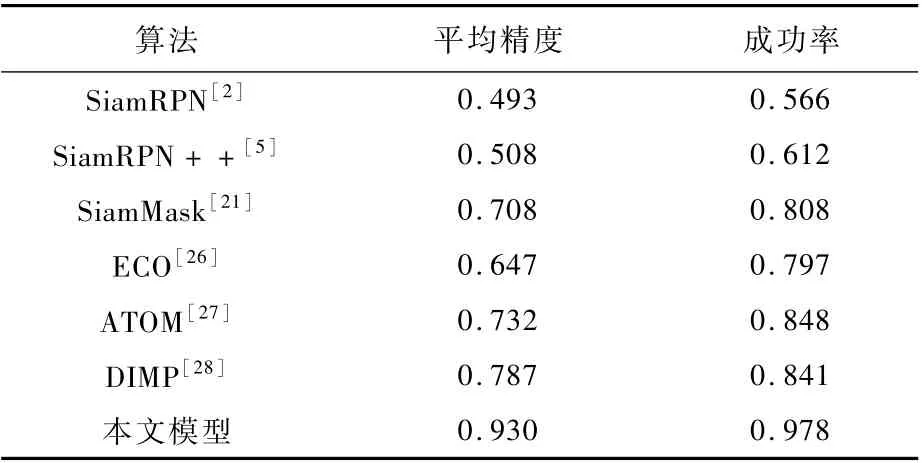
表2 本文模型与主流跟踪算法评估结果对比Tab le 2 Com parative resu lts between p roposed m odel and m ainstream tracking algorithm s
本文还对不同主流跟踪器效果进行了可视化。如图7所示,其中红色框为SiamRPN++,绿色框为SiamRPN,蓝色框为ATOM,黑色框为DIMP,粉色框为ECO,青色框为SiamMask,灰色框为本文模型。

图7 不同跟踪器效果可视化Fig.7 Results visualization of different trackers
4.3 语言检测跟踪评估
传统跟踪任务是给定第1帧对象后开展视觉跟踪,但在实际公安视频应用中,大部分场景能够获取对目标对象的语言描述,因此,利用模型完成先检测目标后跟踪的任务更具有实用价值。如图8所示,pertrack_DMN表示原模型的结果,pertrack_GTfree表示没有给定目标框,仅靠语言检测后进行跟踪的结果,pertrack_SiamMask表示Siam-Mask跟踪模型的结果,数据集用PerTrack的测试集。实验表明,在不给定第1帧目标框情况下,仅用语言先验检测出目标再进行跟踪的结果也优于纯视觉跟踪,但由于没有视觉信息的辅助,整体性能略低于原模型。

图8 语言检测跟踪评估Fig.8 Tracking assessment of language detection
4.4 结果分析
通过上述3组实验,得出如下结论:
1)将语言先验引入面向人员特征的目标跟踪任务能有效提升跟踪精度和鲁棒性,特别是在多人干扰的场景下,语言描述能够很好地定位被跟踪人员位置,提升算法跟踪抗类内干扰的能力。
2)语言引导模型具有目标类别敏感性,用于针对行人跟踪的模型不能用于通用目标跟踪,否则对纯视觉模型造成干扰,因此,在应用时需要对某类对象进行针对性训练和微调。
3)语言描述不适用所有跟踪场景。不是所有场景都能够用语言来描述目标对象,而且某一帧适用的描述随着场景变化,在后面的帧中不一定适用,因此,部分复杂场景应用中可以考虑用语言进行目标检测后,用纯视觉进行跟踪。
5 结束语
针对个体人员特征目标跟踪中存在的类内干扰问题,提出了一种引入语言先验知识引导的人员目标跟踪算法,并设计了由视觉跟踪模块、语言引导模块和融合判别模块组成的跨模态目标跟踪框架,同时为保证训练和测试模型的有效性,构建了专用的跨模态个人目标跟踪数据集。实验结果表明本文提出的模型与现有主流跟踪模型相比具有更好的精度和鲁棒性。
本文将数据驱动的视觉深度学习模型与语言先验知识相结合,为公安领域视频监控信息的深度挖掘和关联等提供了一种新的思路,下一步的研究可以将语言先验知识的引导拓展到多目标跟踪、行人再识别、图像分类等其他视觉任务中。另外,利用本文提供的专用数据集,可以提升跨模态人员跟踪的精度,如果能够进一步丰富该数据集的内容,将更多真实公安场景下的数据和标注补充到数据集中,将能够训练出更多适应不同场景可复制、可重用的算法模型,或者为不同机构提供的算法进行测评,这些工作将有利于进一步提升公安视频监控的应用效能。
