基于面部视频分析的生命体征检测
2020-11-07陈辉郑秀娟倪宗军张昀杨晓梅
陈辉,郑秀娟,*,倪宗军,张昀,杨晓梅
(1.四川大学 电气工程学院,成都 610065; 2.西安交通大学 电子与信息学院,西安 710049)
近年来视频监控技术快速发展,针对监控视频的智能分析需求深入到公共空间和私人生活的各个方面,涉及了如交通监控、犯罪预防、人群监控、身份认证以及居家监护等多种不同应用场景[1]。由于视频中的人脸包含有最为丰富的个人特征信息,因此针对面部视频的智能分析方法也受到广泛的关注。早在20世纪60年代Bledsoe就提出了基于人脸的几何特征的人脸识别方法[2];He等也在2015年提出了一种基于局部二值模式(Local Binary Patterns,LBP)关键面部区域中的表情特征融合方法进行面部表情识别[3];2004年,Ahonen等利用LBP人脸单个特征直方图实现人脸识别[4];2016年,Lenc和Král提出利用一组Gabor滤波器实现对基准点的自动选择,解决了在使用LBP进行人脸识别时的基准点的位置和数量是固定的问题[5]。随着计算机视觉理论和技术的发展,人脸检测与识别技术日臻完善。在面部视频分析领域中,之前的许多研究都围绕人脸结构特征展开了深入研究,但忽略了隐含于视频中的与生命体征相关的生理信号。近年来,越来越多的研究开始关注对视频及图像序列中的生命体征相关生理信号的提取和分析工作[6-7],这将为充分利用监控视频中隐含的人体信息进行活体识别以及智能行为分析提供思路,有助于丰富监控视频智能分析的应用场景。
2000年,Wu等提出成像式光电容积描记法(imaging Photoplethysmography,iPPG)及其技术框架实现了从视频中获得人体的心率参数估计[8]。iPPG技术是根据面部视频中的皮下浅层血管血流灌注变化导致的皮肤颜色轻微变化,从而通过分离血容量脉冲(Blood Volume Pulse,BVP)信号来得到相应的生命体征估计。此后,多项研究均以iPPG技术为基础实现基于视频的远距离生命体征参数检测工作[9-10]。然而由于视频中隐含的BVP信号成分十分微弱,且容易受到环境光照和运动的影响,产生低频基线漂移与高频噪声污染[11],从而使得iPPG方法进行生命体征检测的精准度不稳定。
为抑制噪声对iPPG技术的干扰,2010年Poh等使用独立成分分析法(Independent Component Analysis,ICA)处理面部视频中RGB三通道信号,来获取视频中0.5~2 Hz之间的频率成分,之后重构BVP信号,进而获得心率的估计[12]。随着现代信号处理技术的发展,2009年,雷恒波等采用经验模态分解(Empirical Mode Decomposition,EMD)来自适应处理非平稳信号,将原始信号分解成一系列不同频率成分的本征模态函数(Intrinsic Mode Functions,IMF),从而重建纯净的BVP信号并用于检测相应的生命体征[13-14];2018年,Zhao等提出使用改进的EMD方法(Comp lete Ensemble Empirical Mode Decomposition,CEEMD)来重建纯净的BVP信号[15]。2019年,Favilla等提出使用带通滤波器来获取高帧率视频,并且使用快速ICA方法将BVP信号与噪声分离,从而得到准确的生命体征的估计值[16]。
这些信号处理方法都主要解决消除或减弱由运动或光照影响造成的伪影误差,但当视频存在人脸丢失,或者无法准确识别人脸感兴趣区域(Region of Interest,ROI)时,仍会使获取的BVP信号质量下降,从而影响到生命体征估计的准确率。
由此本文以面部视频中人脸检测为基础,提出了一种新型面部视频分析方法实现自适应非接触生命体征检测。该方法可在面部视频分析时,对存在环境光影响和人头部运动的面部视频给出较为精确的心率与呼吸频率的估计。
1 本文方法
本文以人脸检测为基础,使用集合经验模态分解(Ensemble Empirical Mode Decomposition,EEMD)算法[17]与信号质量检测提高基于面部视频的生命体征检测方法的准确性。本文提出的联合集合经验模态分解算法和信号质量检测的面部视频分析方法由5个主要步骤构成,流程如图1所示。

图1 本文方法流程Fig.1 Flowchart of proposed method
1.1 基于人脸检测的感兴趣区域获取
为了更好地检测并跟踪视频中的人脸,本文使用具有3个深层卷积网络的级联架构MTCNN(Multi-Task Convolutional Neural Networks)[18]和非极大值抑制策略[19]得到人脸识别框与面部标签,同时实现人脸检测与对齐。在确定人脸的范围之后,调用Dlib库[20]定位人面部特征点。根据面部特征点定位鼻子及额头区域的最大内接矩形可以跟随头部运动实现面部感兴趣区域的自适应获取,如图2所示。图中:实心点为68个特征点(粗略ROI);矩形框为精细ROI,包括鼻子和前额区域。
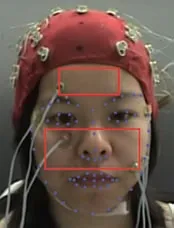
图2 面部ROI选择Fig.2 Facial ROI selection
1.2 初始BVP信号提取
在确定面部ROI后,对ROI内像素点进行灰度归一化处理,再进行瑞利分布匹配,去除灰度值落在瑞利分布之外的像素点从而抑制噪声干扰。接着采用CHROM 模型[17]构建ROI像素点色彩模型以降低运动带来的噪声影响,即将RGB三通道的信号进行线性组合得到初始BVP信号。
1.3 集合经验模态分解
为了避免EMD算法的模态混合问题,本文采用EEMD算法[21]将初始BVP信号分解为真实的IMF函数组合。
因此初始BVP信号先由EMD算法分解为N个IMF函数,所有的IMF函数和残差r(t)可以重构输入信号x(t)。
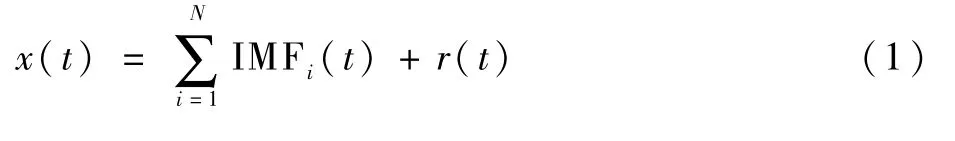
根据EEMD算法原理,初始BVP信号x(t)分解步骤如下:
步骤1在原始信号x(t)中加入均值为0、标准差为原始信号标准差0.2倍的高斯白噪声w(j),即x(j)=x(t)+aw(j)(j=1,2,…,N),其中的白噪声的幅度大小为a=0.2。
步骤2计算x(j)(j=1,2,…,N)的EMD算法得到本征模态,其中k=1,2,…,K为模态。
步骤3将作为x(t)的第k阶模态均值,通过将相应的求平均得到。

当得到所有的IMF函数后,应该舍去与噪声相关的IMF函数。由人体血流循环可知,BVP信号主要受心肺频率的调制,而呼吸成分频率范围为0.1~0.5Hz,心率成分频率范围为0.7~4 Hz。为了去除伪影,计算各IMF函数的频谱并确定其主频率,即获得最大幅度的频率。根据各IMF函数的主频率将其归入对应的心肺信号频率范围,即将IMF函数分为心率组和呼吸频率组。为最终从BVP信号中得到准确的心率和呼吸频率等生命体征的估计,将心率组和呼吸频率组的IMF函数通过正交变换,将存在相关性的IMF函数转换为一些线性不相关的变量,即为主成分(Principal Component signal,PCs)。将主成分进行排序,第一主成分含有所选IMF函数中存在的大部分变化。因此,在心率组中的IMF函数上得到的第一主成分对应着心率,同样,呼吸组中的第一主成分对应着呼吸频率,如图3所示。
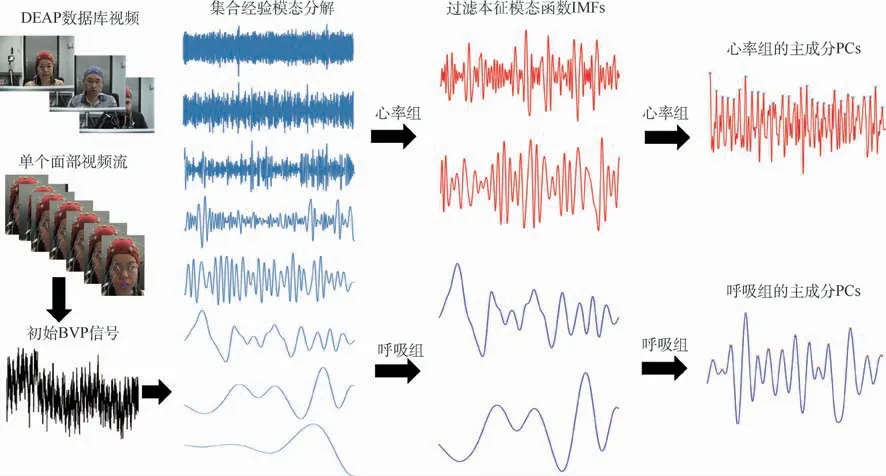
图3 用EEMD-PCA技术从BVP信号中提取心率和呼吸频率的主成分的步骤Fig.3 Steps of using EEMD-PCA technique to extract principal component signal of heart rate and respiratory rate from BVP signals
1.4 基于方差特征序列的信号质量检测
在实际的面部视频分析中,初始BVP信号质量往往受到诸多外界因素的干扰,即使经过EEMD分解后获得的主成分也会存在信号质量不高的问题。因此,在得到心率主成分Xhr(t)和呼吸频率主成分Xbr(t)后,需要检测主成分信号质量来提高生命体征检测的准确性。本文采用方差特征序列(Variance Characterization series,VCs)[22]进行主成分信号的频谱质量检测,以处理心率主成分Xhr(t)为例(呼吸频率主成分Xbr(t)处理方法同理),具体步骤如下:
步骤1根据峰值检测算法挑选出Xhr(t)所有局部最大值Mi(i=1,2,…)以及局部最小值mi(i=1,2,…)。
步骤2将每个局部最大值Mi和后续的7个局部最大值进行方差计算,记为σMi。以相同方法处理局部最小值,得到方差记为σmi。当计算最后7个局部值的方差时,以最后1个数复制填充至8个再进行计算。
步骤3计算方差特征序列:
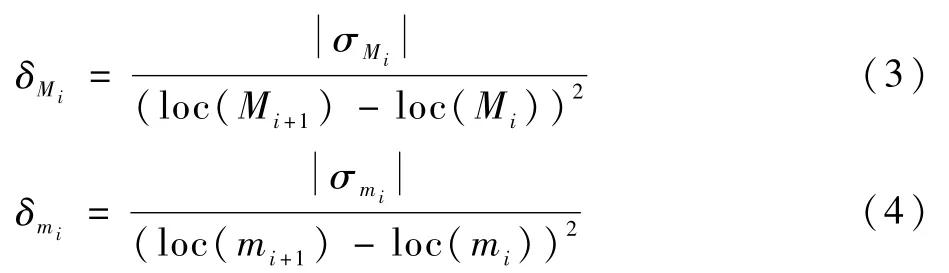
式中:δMi和δmi分别为局部最大值下的方差特征序列和局部最小值下的方差特征序列;loc(*),*∈(Mi,Mi+1,mi,mi+1)为在时间序列Xhr(t)中的局部最大值和局部最小值对应的索引值。
设定的8个局部值计算方差有利于减少基线漂移,由式(3)、式(4)可以得到Xhr(t)的2个方差特征序列。原始主成分信号以及对应的方差特征序列如图4所示。图中:三角表示主成分信号的局部最大值(无单位),圆点表示主成分信号的局部最小值(无单位)。可以看到,当不同主成分的波形变化时,方差特征序列的变化情况。
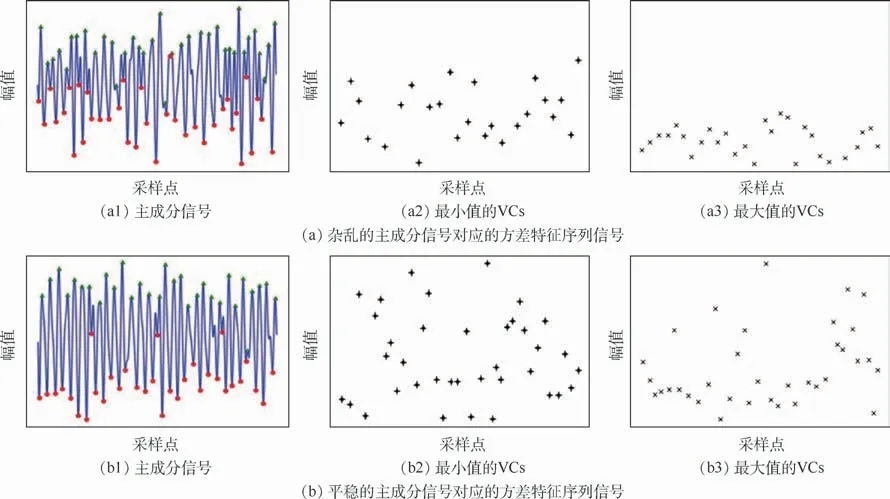
图4 原始主成分信号及对应的方差特征序列表示Fig.4 Original principal component signals and corresponding variance characterization series representation
根据获得的方差特征序列,基于2个准则来判断Xhr(t)质量:
1)δMi的值远大于阈值T。
2)第i+4个最大值和第i个最大值之间的距离远小于D1或者第i+2的最大值和第i的最大值之间的距离D2。
上述准则中,阈值T由先验的无干扰BVP信号计算给定,且D1和D2则由前一时间窗估计的心率(Hpre)和采样频率ρ给定,即

式中:Hpre为按照上述同样方法在前一个时间窗的计算值,180 bpm与60 bpm分别为人体在静坐情况下的心率上限值与下限值。
1.5 自适应生命体征估计
若根据1.4节计算得出对应的主成分信号质量为不合格,即说明在频谱分析时,会出现大量不符合生理特征区间的频谱高峰值,此时对经过1.3节处理之后的主成分信号Xhr(t)与Xbr(t)使用频谱跟踪算法来获取生命体征的估计值,如图5所示,仍以处理Xhr(t)为例(Xbr(t)同理),其具体的步骤如下:
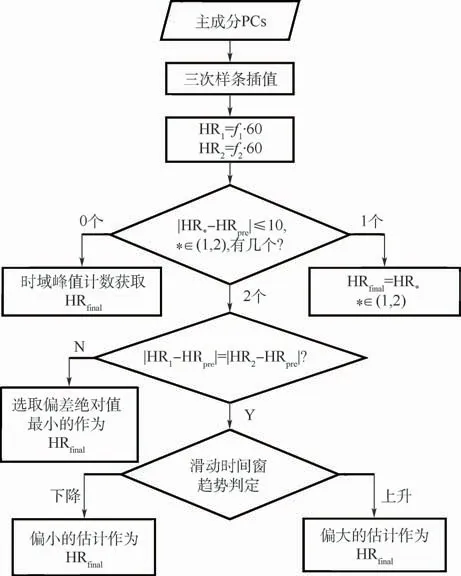
图5 频谱跟踪算法流程图Fig.5 Flowchart of spectrum tracking algorithm
步骤1使用三次样条插值平滑处理,以及对主成分信号Xhr(t)进行三阶的巴特沃斯带通滤波提取相应的频率成分,进一步消除因为环境光照变化和头部运动带来的噪声。
步骤2计算将平滑后的主成分Xhr(t)频谱,选取前2个最大的频率值f1、f2,并且计算对应心率数值为HR1和HR2。
步骤3将这2个数值HR1和HR2与上一个时间窗估计的频率fpre对应的心率HRpre作对比。
1)当2个估计值与HRpre差值均控制在10 bpm之内,且与HRpre差值的绝对值均不相等,即选取最为接近HRpre的心率估计值作为此次的最终的心率估计值HRfinal。
2)当2个心率估计值与HRpre差值均相等且控制在10 bpm之内,将时间窗缩短计算各个时间窗之内的数值,依次判断心率变化的趋势。当心率为上升趋势时选取比较大的心率估计数值作为HRfinal,反之,则选取较小的心率估计值作为HRfinal。
3)当2个估计值与HRpre差值,一个小于10 bpm,另一个大于10 bpm,那么,即选取小于10 bpm对应的估计值作为HRfinal。
4)若2个心率估计值与HRpre的差值均大于10 bpm,即说明该主成分信号质量不高,不能使用频谱分析,则改为使用时域计数方式获取的心率估计值作为最终的心率估计值HRfinal。
如果方差特征序列满足1.4节中2个基本准则,代表此时获得的主成分信号Xhr(t)与Xbr(t)质量合格,受到的干扰少,可以直接使用巴特沃斯带通滤波后进行频谱分析,即可得到相应的心肺频率fhr、fbr,通过式(7)和式(8)获得最终心率和呼吸频率的估计值。

至此完成了根据主成分信号不同质量情况的自适应生命体征估计。
2 实验结果及分析
2.1 实验数据集
为控制实验变量的单一性,本文使用公开的多模态数据库DEAP数据集[23]进行对比实验。DEAP数据集中包含有32名受试者(年龄分布为19~37岁)在观看情绪激发视频时的1分钟面部视频以及同步多通道生理信号,其中由呼吸带测得的呼吸频率和指尖PPG信号测得的心率将作为本文生命体征估计的标准值。
2.2 实验结果对比
为了验证本文方法的心率和呼吸频率检测的准确率,使用估计误差的平均绝对误差(Mean Absolute Error,MAE)、平均误差百分比(Mean Error Percentage,MEP)以及P相关系数(Pearson correlation coefficient)这些统计指标进行验证分析。选取较早研究中常用的信号处理方法ICA[24](2011年)、AR[25](2014年)和近年提出的改进方法CEEMD[15](2018年)、FastICA[16](2019年)进行对比实验,验证本文方法性能的有效性。
所有方法都基于同一个实验数据进行,视频预处理方法保持一致,所有的预处理参数保持一致,面部视频时间窗宽30 s。对比方法保留已报道的参数设定值,ICA[24]选择的独立成分数为3,AR[26]使用的回归参数设定为3,CEEMD[15]不用设置其他参量。本文方法中使用的EEMD算法也不用特别进行参量设置。
表1列出了本文方法与4种比较方法在心率估计的准确度比较结果(面部视频时间窗宽为30 s)。与ICA、AR、CEEMD、FastICA 4种方法做比较时,本文方法的心率估计结果MAE最小,控制在3 bpm之内,同时MEP控制在4%左右,P相关系数大于0.9。表2列出了本文方法与4种比较方法在呼吸频率估计的准确度比较结果(面部视频时间窗宽为30 s)。与其他方法相比,本文方法获得了最低的呼吸频率估计MEP,约为7.8%,同时MAE约为3 bpm,P相关系数达到0.8以上。由上述结果可见,由面部视频获得的呼吸频率的准确度低于心率的准确度,其原因为呼吸相关信号通常为低频成分,更容易受到外界因素干扰,不容易从视频中将其精确分离。
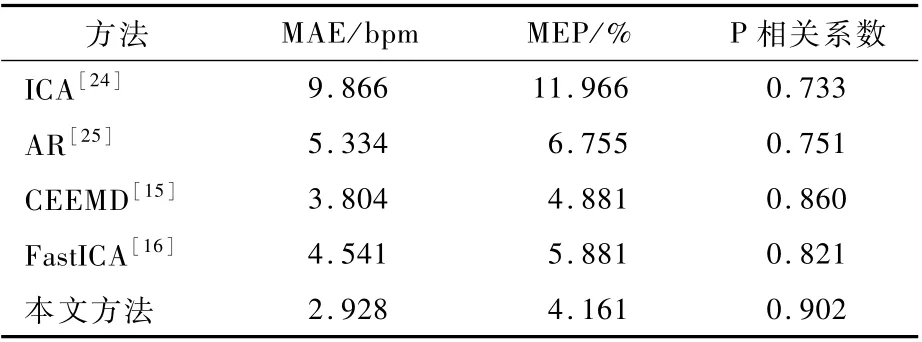
表1 不同方法的心率比较Table 1 Com parison of heart rate am ong differentm ethods
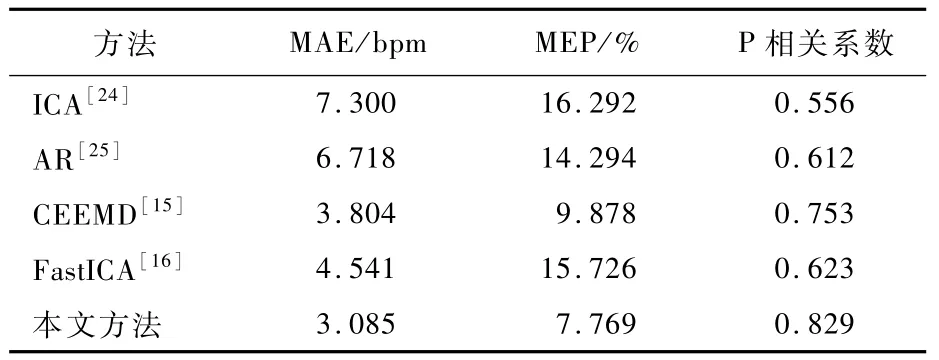
表2 不同方法的呼吸频率比较Tab le 2 Com parison of respiratory rate am ong differentm ethods
2.3 结果讨论
当从面部视频中获取的生理信号足够稳定,使用以傅里叶变换为基础的频谱分析获得的生命体征估计具有较高精确度。然而,通常得到的视频信号,尤其是监控视频,常常受到诸多外界因素的干扰,如环境光变化、人体运动等。这些都会给面部视频中隐含的生理信号带来强烈的噪声。因此使用ICA和时域滤波相结合的方法可以在一定程度上抑制外界干扰引入视频的噪声,但使用ICA方法进行信号盲源分离,设定的盲源数量为3。而监控视频中存在的光源和运动噪声源的数量难以确定,因此在实际应用中该方法所获得的生命体征检测结果也不理想。
AR模型常用于时间序列的分析,但要求信号平稳,因此即使引入了背景兴趣区作为环境光噪声参考来提高该方法对光照变化的稳定性,但仍然无法抑制运动噪声干扰。因此,在对比实验中AR[25]方法相较于ICA[24]方法所得到的生命体征估计结果的准确度有所提高,但低于CEEMD[15]和FastICA[16]方法获得的估计精确度。
使用基于EMD方法以及该类型的拓展方法,如EEMD和CEEMD[15]方法,其优势在于不需要考虑盲源数量,也无需设定任何基函数,便可以将复杂信号分解为有限个IMF组合,并且各IMF分别包含了原信号的不同时间尺度下的局部特征信号。但同一时间尺度成分由EMD分解成不同的IMF时,会产生模态混叠这一现象。EEMD 与CEEMD都是通过改变极值点的分布抑制模态混叠问题,采用的是在原信号中加入白噪声来使真实信号分量在分解的过程逐步显现。使用EEMD时,剩余噪声会随着集成平均的次数逐渐减少,而在使用CEEMD时的剩余噪声一直维持在一个较小的程度,在保证了较小的剩余噪声干扰的情况下,能够节省计算时间。在针对面部视频分析时,本文使用EEMD方法无需针对复杂的干扰情况预先设定视频中噪声源数量。同时,本文方法使用信号质量检测和频谱跟踪算法,可以有效处理视频中面部数据缺失或质量降低的问题,来提高生命体征估计的准确度。
最后,本文方法仍然无法高效地抑制剧烈运动干扰的影响。因此,在未来的工作中,需要提高本文方法的泛化能力,进一步针对监控视频特点提高视频中生命体征检测的准确度。
3 结 论
本文基于面部视频分析给出了一种人体生命体征检测方法,并通过公开数据集的对比实验验证得出如下结论。
1)为了提高视频中生命体征检测的准确度,抑制外界环境光及头部运动的干扰,提出以人脸检测与跟踪为基础,联合EEMD算法与信号质量检测方法进行面部视频分析,并给出了心率和呼吸频率检测的具体流程与算法。
2)通过公开数据集验证了所提方法从面部视频中获得心率和呼吸频率的准确度,所得估计值与标准值的相关系数分别高于0.9和0.8。
3)所提方法不仅为实时活体检测提供了思路,而且也有助于丰富监控视频的智能分析的应用场景。
