基于局部语义特征不变性的跨域行人重识别
2020-11-07张晓伟吕明强李慧
张晓伟,吕明强,李慧
(青岛大学 计算机科学技术学院,青岛 266071)
行人重识别(Person Re-identification)也称行人再识别,是利用计算机视觉技术判断图像或者视频序列中是否存在某一特定行人的图像识别技术,其在智能化的公共安全领域扮演着重要角色。跨域行人重识别也被认为是图像检索的一个子问题,旨在弥补单一、固定摄像头的视觉局限,可与行人检测、行人跟踪技术相结合,检索跨摄像机设备下的同一标识的行人图像,被广泛应用于智能视频监控、智能安保等领域,具有重要的研究意义和应用价值。
近年来,伴随深度卷积神经网络的发展,行人重识别在同一场景(单域)数据集下取得了巨大的进展[1-2]。行人重识别技术从基于深度卷积神经网络的全局特征开始向更细粒度的局部特征方向发展。基于全局特征的行人重识别主要基于深度卷积神经网络结构输出的整体行人区域作为行人图像的重识别特征,研究如何基于全局特征设计更为合理的网络损失函数。其中,为解决行人检测对行人重识别的影响,Han等[3]开发了一个可区分的ROI变换层,将行人检测器产生的边界框从原始图像中转换出来生成更可靠的边界框。在损失函数的设计方面,主要有对比损失(Contrastive Loss)[4]、三元组损失(Trip let Loss)[5]、四元 组 损 失(Quadruplet Loss)[6]和 中 心 聚 类 损 失(Center Loss)[7]等。
由于全局特征不具有细粒度的区分能力,在光照条件、背景、人体姿势和成像视角的变化下,同一ID标识的行人在不同视图之间的特征辨识度明显降低。因此,基于局部特征的行人重识别受到研究者的日益重视。基于行人局部区域划分方式的不同,行人语义部件模型可以分为人体语义分块和物理切割分块。近年来,人体姿势估计技术取得了较大的进展[8-11],基于人体语义分块方法[12-14]通过借鉴人体姿态估计的结果用于行人区域划分来进行行人重识别。但姿势估计和行人重识别之间的数据集标注偏差仍然是阻碍行人重识别图像语义划分的障碍。不同于人体语义分块方法需要对行人的强语义标注,物理切割分块不需要行人每个部件区域的训练标签,受到了研究者们的重视[15]。其中,可见部件感知模型(VPM)[16]聚焦在2幅行人图像共同可见的部件区域上学习细粒度的区域特性,以解决行人部件与行人整体图像间的空间位置错位问题,显著地改善了特征表征的学习能力。Sun等[17]提出了基于行人局部特征的部件卷积池化方法,以增强行人重识别中行人部件区域的语义一致性。在行人重识别模型中引入基于深度学习的注意力机制[18-19],自动地给每一幅行人图像赋予一个权重,也进一步推动了行人重识别的性能。Chen等[20]通过卷积神经网络特征通道聚合和空间位置感知提出了一种基于双重注意力机制的行人重识别模型,其集成了注意力模块和多样性正则化,以学习具有代表性、健壮性和更具区分性的特征。
上述基于监督学习的行人重识别方法[4,21-23]依靠丰富的标记数据和深度网络[24-26]在单域数据集上取得了巨大的成功。在闭合的单域行人重识别上,其源域数据集和目标域数据集具有完全相同的标识类别,但在跨域的无标签数据集上,由于跨域的数据集偏移问题导致行人重识别性能出现显著下降。为了解决这个问题,研究者们提出使用带有标记的源域数据来提取行人特征学习初始阶段的行人重识别模型。在此基础上,通过在目标域上进行无监督聚类[27]或学习度量[28]来改进Re-ID模型,然而这种方法在源域到目标域的特征迁移过程中并没有有效利用带有标记的源域数据作为有效监督信息。为了克服这一问题,目前跨域行人重识别方法主要是基于图像级行人图像整体特征风格[29-31]和行人局部属性语义特征[32-33]进行数据集之间的跨域迁移。
在图像级特征风格迁移方面,Zhong等[34]提出了相机不变性以缓解跨域行人重识别的跨域偏移问题。Yu等[35]提出一种基于无监督多标签学习的MAR模型,开发未标记目标对的多标签视觉特征的相似一致性,基于强化学习增强不同相机视图之间的跨视角一致性。Chen等[36]提出了一个对偶条件生成对抗网络,利用大量未标记的目标域行人实例作为生成图像的上下文指导,将源域目标转移到目标域上下文中,通过迁移丰富的上下文信息来增强行人再识别的辨别力。在行人局部属性语义特征方面,EANet模型[37]利用行人的关键点将行人进行分块和对准,在此基础上进行跨域迁移学习。但是,这些方法却忽略了在目标域内同一标识行人存在的视觉差异,这种同一标识行人的类内差异将对无监督的域自适应问题产生重要的影响。对此,本文联合相机不变性和行人图像局部语义特征不变性将目标域中每个ID标识局部语义对齐的行人特征存储于特征模板池中,对目标域行人进行不变性约束,更好地发挥跨域特征不变性的作用。
综上所述,本文提出一种基于局部语义特征不变性的跨域行人重识别方法,其主要贡献如下:
1)根据行人图像在源域与目标域上语义特征的一致性,基于弱标注的源域行人图像提出一种行人局部特征语义对齐方法,以迁移源域行人局部语义特征到无标注的目标域,增强跨域行人重识别的特征表达能力。
2)针对同一ID标识行人图像存在的表观特征变化,通过估计目标域图像之间的相似性,采用特征模板池存储并更新目标域中行人图像的全局与局部特征,将跨域不变性加入到深度网络中提高对跨域特征不变性的学习。
3)鉴于行人重识别在源域与目标域上的特征差异,基于行人局部特征语义对齐和行人特征模板池提出了一种联合实例不变性、相机不变性和类别(标识)不变性的损失函数,无监督地学习跨域不变性特征,提高行人重识别的跨域适应能力。
1 局部语义特征不变性网络
1.1 网络框架
本文提出的基于局部语义特征不变性的网络结构框架如图1所示。基础骨干网络采用ImageNet[38]上预训练的ResNet-50[25]网络,其将带标签的源域数据和无标签的目标域数据输入到网络中获取行人实例的特征表示。本文保留ResNet-50的Pooling-5层及之前的网络结构,深度特征的提取分为全局特征模块和局部特征模块。在全局特征模块中添加全局平均池化(Global Average Pooling,GAP)层以获得全局特征,使用交叉熵损失函数与三元组损失函数来优化模型。在局部特征模块添加自适应平均池化层,将行人图像提取到的三维特征张量T分成P个部分,并降维到256维,分别为每个部分添加分类器来进行训练,使用交叉熵损失函数来优化模型。在目标域中,引入特征模板池保存每个行人样本的全局与局部特征,通过估计小批量的目标样本与特征模板池中的特征的相似性,计算无标签目标域的不变性损失。
1.2 基于语义对齐的全局与局部特征
1.2.1 全局特征
本文在ResNet-50的Pooling-5层之后,采用GLAD模型[14]的全局平均池化来提取全局特征,之后再经过Softmax分类器预测行人样本的标识,使用交叉熵损失函数Ls和三元组损失函数Lt来共同计算源域全局损失Lsrc1,其计算公式为

式中:η1和η2为损失函数平衡因子,本文取值为η=[0.96,1]。
1.2.2 基于语义对齐的局部特征
本文行人局部特征的提取以PCB模型[3]为基础,将行人图像从上到下均匀划分为6个部件区域,如图2(a)所示。为了实现行人部件的语义对齐,本节基于行人局部部件的内部特征,把每个局部部件分成4×8的特征块f,每副行人图像被分为6个语义部件,共包含24×8个特征块f,如图2(b)所示。首先,在源域数据集上,将基于行人图像划分的6个部件区域进行训练学习,形成行人部件分类器Wi。然后,对每个特征块f使用线性分类Softmax函数进行动态分类:
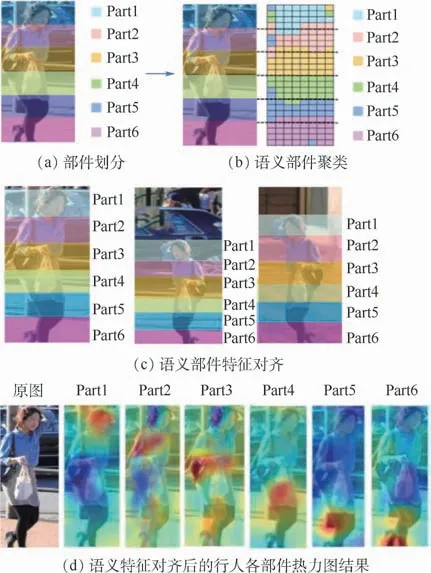
图2 基于语义特征的行人部件示意图Fig.2 Schematic diagram of person parts based on semantic features
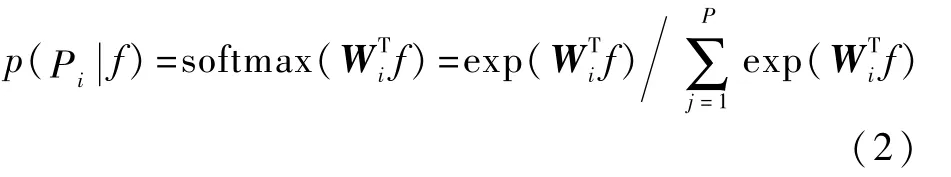
式中:p(Pi|f)为属于Pi部件的预测概率;P为预定义行人部件的数量(即P=6);W 为部件分类器的可训练权重矩阵。
为保证部件分类的准确性,为每个部件分类器的预测结果设立一个阈值。经过此分类,每个f得到P个预测概率p(Pi|f),取其中的最大值p(Pi|f),并且p(Pi|f)要大于阈值Ti,满足该条件就把f分为Pi部件中,经过这步处理可以筛选出属于各个部件的f;之后,对每幅行人图像中分类预测为同一部件类别的f做局部平均池化,获取行人各个部件的特征表示。
为对齐行人部件区域,采用成对样本对计算最小总距离[39],形成2幅图像的最短路径。假定待查询行人图像和搜索库中的某一图像经式(2)提取的局部特征分别为F={h1,h2,…,hP}和G={g1,g2,…,gP},则2幅行人图像成对部件元素之间的距离规范化为式中:di,j为待查询行人图像的第i个部件和搜索库中某一行人图像的第j部件之间的距离,其取值范围为[0,1]。

本文基于P×P个距离di,j(i,j∈(1,2,…,P))形成的距离矩阵D中的最短路径来对齐待查询行人图像与搜索库中行人图像的语义局部区域。其中,2张行人图像相似性距离Si,j是通过动态规划计算距离矩阵D中每行或每列对应最短路径的总距离,即为经过行人部件划分和语义特征对齐后的部件区域如图2(c)所示,每个部件区域的局部特征注意力位于行人的不同部位,如图2(d)所示。基于语义对齐后的行人部件局部特征,其行人重识别源域局部损失Lsrc2为
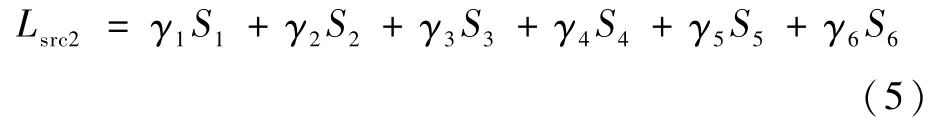
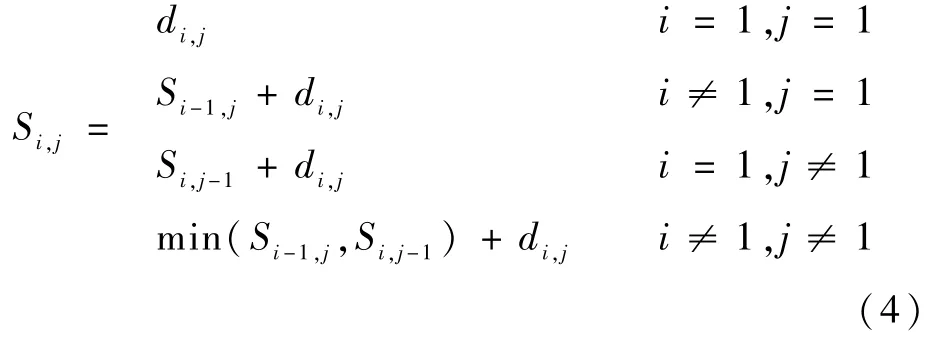
式中:Si为部件Pi的交叉熵损失;权重向量γ的取值,通过实验分析分别取[0.18,0.15,0.15,0.17,0.16,0.19]重识别性能最佳。
1.3 特征模板池
为了提高网络在目标测试集上的泛化能力,提出通过估计目标图像之间的相似性来增强网络的特征不变性。为此,构造了一个具有键值结构用于存储所有目标域图像的全局与局部特征的特征模板池,其具有键池(K)和值池(V)。其中,键池存放在行人图像经ResNet-50全连接后L2规范化的特征,包括语义对齐后全局特征和局部特征的串联聚合特征,分别为1×4 096维和6×256维;值池存储行人图像的标签。
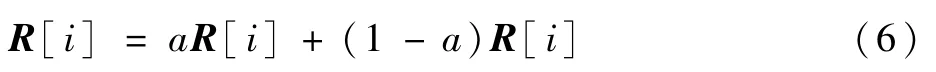
式中:R[i]为图像xt,i的特征模板池中键池存放的特征,i为标签;超参数a∈[0,1]控制更新速率。
1.4 特征不变性学习
鉴于仅使用源域的监督学习得到的深度Re-ID模型对目标域内的变化较为敏感,考虑目标域内的差异变化,研究了3个跨域特征不变性,即实例不变性、相机不变性、类别不变性。
1)实例不变性。在行人重识别中,即使是同一ID标识的图像间也会有差距,为了学习每一张图像都有别于其他图像,本文在Re-ID模型中增加实例不变性。将nt个目标域图像看做nt个独立不同的类别,计算某一给定目标图像特征h(xt,i)与已保存在特征模板池中的特征之间的余弦相似度,并使用Softmax函数预测其归属类别:

式中:β∈(0,1]为平衡因子。
实例不变性的目标是使目标域上训练图像的负对数似然最小化:

式中:Lei为实例不变性损失。
2)相机不变性。相机风格的变化是影响行人图像识别的一个重要因素,尤其是在源域与目标域之间往往存在迥异的相机风格。因此,本文基于相机不变性拉近同一ID标识的行人图像与其经过相机风格变换后的距离。假设每个图像的摄像机ID是已知的,将每台摄像机视为一个相机域,利用starGAN[40]来训练一个相机风格转换模型[34],利用学习到的相机风格转换Re-ID模型。假设C为目标域中相机风格的数量,一张行人图像则可以得到C-1张其他相机风格的图像,且这C张图片属于同一行人ID,相机不变性的损失函数为
2.3 MAIT细胞和IL-22水平相关性分析 Pearson相关分析结果显示TB患者外周血MAIT细胞和IL-22水平呈正相关 (r=0.427,P<0.05),见图1。

式中:Lci为相机不变性的损失;¯xt,i为xt,i及其C-1张生成图像的集合中随机选取的一张图像,拉近目标域行人图像集中具有同一标识、不同相机风格的行人图像。
3)类别不变性。基于目标域中属于同一ID标识的行人图像样本集拉近彼此间的距离克服目标域中的变化,以提高Re-ID模型的稳定性。先计算图像特征h(xt,i)与其特征模板池中键池的余弦相似性。在特征模板池中找到与行人图像xt,ik邻近的行人图像索引,定义为M(xt,i,k)。本文提出的类别不变性是假定目标域行人图像xt,i的ID标识应该隶属于k邻近图像索引M(xt,i,k)的候选类。因此,将目标域行人图像xt,i属于某一ID标识j的概率权重赋值为

类别不变性的损失函数为

式中:Lni为类别不变性损失。
基于上述实例不变性、相机不变性、类别不变性,跨域特征不变性学习的总体损失可以写为

合并源域和目标域的特征不变性网络的损失函数为

式中:λ为平衡源域与目标域损失的权重系数,本文取值为0.3。
2 实验结果分析
2.1 数据集与实验设置
本文在国际公开的行人重识别(Re-ID)基准数 据 集 Market-1501[41]、DukeMTMC-reID[6,42]和MSMT17[30]上评估了本文方法。本文采用Res-Net-50[25]作为模型的骨干网络,并使用在ImageNet[43]上预先训练的参数初始化模型,输入图像的大小采样到384×128。在前40次epoch迭代训练阶段中,使用0.01的学习率对ResNet-50的基础网络层进行训练,在接下来的20次epoch迭代中,学习率每个阶段都以除以10的比例缩放。源域行人图像和目标域行人图像的批量大小都设置为128,网络模型学习更新率α初始化为0.01,并随着训练次数的增加而线性增大,α =0.01×epoch。本文设置行人部件P=6,每个部件的权重向量γ依次设为[0.18,0.15,0.15,0.17,0.16,0.19],参数β=0.05,特征模板池候选正性样本数k=6,损失权重λ=0.3。在测试中,提取Pooling-5层的L2规范化输出作为图像特征,并采用欧几里德距离度量查询图像与图库图像的相似度。
2.2 消融实验
2.2.1 基于语义对齐的特征不变性分析
针对目标域提出的语义部件特征对齐与跨域特征不变性学习的有效性,本文在Market-1501和DukeMTMC-reID 数据集上开展了验证实验。R-k为返回置信度最高的k张行人图像具有正确结果的概率,mAP为平均准确率。将全局特征作为实验基线,记为GAP,基于语义部件对齐的局部特征记为PAF(Part Aligned Feature),跨域特征不变性记为Inv(Invariance)。在表1由DukeMTMC-reID→Market-1501数据集的跨域行人重识别实验中,联合语义部件对齐后的局部特征和全局特征(GAP+PAF)较全局特征基线(GAP)mAP提高1.6%,R-1提高1.5%。而且无论对全局特征还是局部特征,加入跨域特征不变性(Inv)均提高了行人重识别的性能,其平均准确率mAP分别提高13.1%和23.8%,R-1的性能分别提高了20.6%和29.8%。实验发现,联合全局与局部特征和特征不变性取得了最优的行人重识别性能,其R-1和mAP分别达到了77.6%和45.0%。同样的实验结论在Market-1501→DukeMTMC-reID数据集的跨域行人重识别中得到了验证。

表1 在M arket-1501和DukeM TMC-reID 数据集上的跨域行人重识别消融实验Table 1 Ablation experim ent of cross-dom ain person re-identification on M arket-1501 and DukeM TMC-reID datasets
值得注意的是,相对于单域行人重识别,跨域行人重识别的性能均出现了显著下降。从表1中可以观察到,在Market-1501单域上本文行人重识别方法的平均准确率mAP为67.0%,R-1为88.2%;但是在跨域DukeMTMC-reID作为源域,Market-1501作为目标域,行人重识别的平均准确率mAP下降到45.0%,R-1下降到77.6%。同理,Market-1501作为源域,DukeMTMC-reID作为目标域,行人重识别的平均准确率mAP也显现出大幅性能下降。由此可以看出,跨域行人重识别仍然是一个重大挑战。
2.2.2 特征模板池的重要性分析
为验证本文提出的特征模板池对跨域行人重识别的有效性,在全局与局部特征不变性的基础上检验特征模板池的作用。从表2中可以看出,添加特征模板池的方法优于基于小批量的跨域行人重识别方法,其在R-1和mAP分别提高近11%和8.8%。但是,使用特征模板池的缺点是会增加有限的额外训练时间和GPU内存的开销。

表2 特征模板池与M ini-batch的比较Tab le 2 Com parison of featu re tem p late pooling m em ory and M ini-batch
2.3 对比实验
为横向比较本文提出的基于局部语义特征不变性的跨域行人重识别有效性,在Market-1501、DukeMTMC-reID和MSMT17数据集上开展跨域行人重识别性能的对比验证。在Market-1501→MSMT17跨数据集的行人重识别实验中,表3显示了本文方法相较于当前一流的行人重识别方法ECN[44],R-1提高0.3%,R-5提高0.8%,R-10提高1.2%,mAP提高0.4%。在DukeMTMC-reID→MSMT17跨数据集的实验中,本文方法相较于行人重识别方法ECN[44],R-1提高0.4%,R-5提高0.3%,R-10提高0.8%,mAP提高0.5%。从表4中可以看到,在DukeMTMC-reID →Market-1501的跨数据集行人重识别实验中,行人重识别的性能R-1为77.6%,R-5为88.7%,R-10为92.0%,mAP为45.0%,相较于当前一流的跨域行人重识别方法ECN[44]均有较为明显的性能提升,分别提高2.5%、1.1%、0.4%和2.0%。在跨数据集Market-1501→DukeMTMC-reID的实验中,本文方法相较于行人重识别方法ECN[44],R-1提高2.2%,R-5提高1.8%,R-10提高0.7%,mAP提高2.4%。由此可以看出,本文基于局部语义特征不变性的跨域行人重识别方法有效地提高了跨域行人重识别的性能。
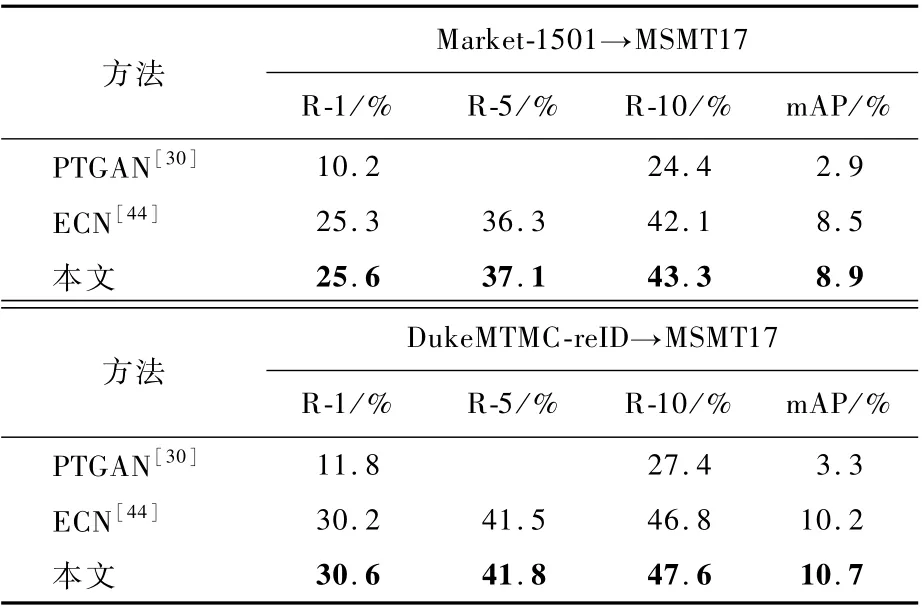
表3 在M arket-1501和DukeM TM C-reID到M SM T17跨域数据集上与当前先进方法的实验比较Tab le 3 Experim ental com parison w ith other advanced m ethods from M arket-1501 and DukeM TM C-reID to M SM T17 cross-dom ain datasets

表4 在M arket-1501和DukeM TM C-reID跨域数据集上与当前先进方法的实验比较Tab le 4 Experim en tal com parison w ith other advanced m ethods on M arket-1501 and DukeM TM C-reID cross-dom ain datasets
3 结束语
本文通过弱监督学习方式对齐行人语义特征,并结合局部特征与全局特征提高了行人的表征能力;联合跨域不变性损失函数约束行人表观特征的不变性提高了行人重识别的跨域适应能力。但是,相较于单域行人重识别,由于源域与目标域行人图像存在的特征分布差异导致跨域行人重识别仍然具有较大的挑战性。
