Kafka中Broker节点磁盘问题的故障处理方法
2020-11-06汪涛


摘 要:Apache Kafka作为一种分布式的消息队列中间件,由于其具有高可靠性、高吞吐量、可持久化、可扩展性好等特点。在大数据项目中,如日志聚合、流数据处理等应用场景中被广泛使用。由于Kafka的消息需要持久化到磁盘中,磁盘故障会影响Kafka的使用,严重时会造成数据丢失。所以基于Kafka的存储特性,通过复盘和分析由于磁盘问题导致的Kafka集群故障,提出了一系列的磁盘故障处理方法,从而缩短Kafka集群故障的恢复时间。
关键词:Kafka;分布式;消息队列;磁盘故障;处理方法
中图分类号:TQ587.22;TP309.3 文献标识码:A 文章编号:2096-4706(2020)13-0148-03
Abstract:Apache Kafka is a distributed middleware used for message queue. It has merits of high reliability,high throughput,data persistence,good scalability,and therefore has be widely used in big data project such as log aggregation,streaming data processing and so on. The messages of Kafka are persisted to disk,so Kafka is not work when its disk malfunction. Some severe cases may result in subsequent loss of data. Therefore,based on the storage characteristics of Kafka,this paper proposes a series of methods to deal with the failure of Kafka cluster through the re-disk and analysis of Kafka cluster failure caused by disk problems,so as to shorten the recovery time of Kafka cluster failure.
Keywords:Kafka;distributed;message queue;disk malfunction;solution
0 引 言
Apache Kafka[1],最初由LinkedIn公司開发,并于2011年开源[2]。2012年被孵化成为Apache软件基金会顶级项目。如今,Kafka应用于众多大数据项目中,很多互联网公司也在自己的生产环境中将Kafka作为消息中间件使用。
1 Kafka组件及架构
Kafka作为一种分布式的消息队列中间件,部署多采用若干节点构成集群的方式。在这个Kafka集群中,每个节点被称作Broker,可以理解为Kafka提供服务的一个实例。在消息(message)队列系统中,通常都会有生产者(Producer)发送消息,消费者(Consumer)消费消息,这样就构成了一个消息“流水线”的上下游,如图1所示。每条被Producer发布到Kafka集群的消息都属于一个Topic。
2 Kafka中的文件存储介绍
Topic经过Producer发布到Kafka集群中,这条Topic会根据配置被划分为多个分区(Partition),这些分区又会被均匀地分布到Kafka集群所有的Broker节点上。这样做可以通过增加分区的数量来横向增加Topic的存储数据量,并且均匀分布也可以起到负载均衡的作用。
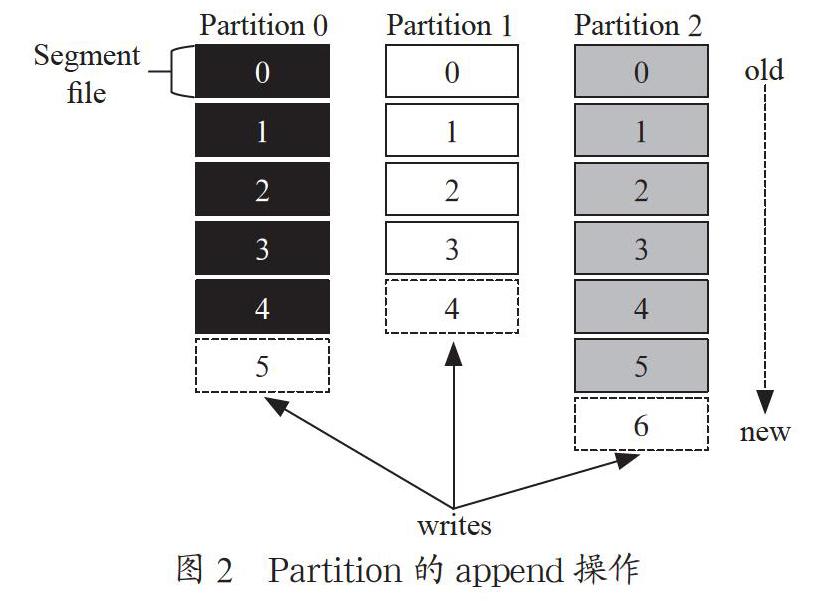
在存储层面,任何发布到此分区的消息都会被追加(append)到数据文件的尾部,文件以“.log”为后缀。消息被追加到分区中因为是顺序写入(write)磁盘的,因此效率非常高。如图2所示,图中不同颜色的数据文件对应的是不同的分区数据,append操作正在写入对应虚线数据文件。
除了log文件,分区中还有一个以“.index”为后缀的索引文件,它们共同组成段(Segment)文件。在分区中会存在多个段文件,它们大小相等,但其中包含的消息数不一定相等。这种特性方便旧的段文件可以被快速删除,这样可以清理空间供新的消息进行存储,提高磁盘利用率。
作为分布式系统,Kafka在设计上也充分考虑了高可用,从Broker的多节点到Topic的多副本。Topic的副本机制则是通过分区的副本实现的,被称为Replica,即在另一个或多个Broker节点上存在这个分区的副本。
3 故障复盘与分析
在公司某生产环境里的Kafka集群中,一个Broker节点的磁盘发生故障,导致这个Broker节点的进程退出[3],进而影响了Kafka中的某一个Topic的正常使用。
如果启用副本,Kafka至少不会因为单个节点不能对外服务而发生Topic不能正常使用的情况,这就是Topic的高可用性。本次故障影响使用的主要原因就是Topic没有设置副本,采用系统默认值1。在Broker节点发生磁盘故障停止服务时,由于这个Topic在故障Broker的分区没有可以使用的副本,导致了此Topic不能正常写入和消费数据的问题。
当发生磁盘故障,通常快速恢复Kafka服务的方法就是修改Kafka的server.properties配置中log.dirs参数,将故障磁盘从配置中删除,Broker就可以启动了。Broker启动之后,节点上故障磁盘的分区会在此Broker的其他磁盘中创建。但对于这次的Kafka故障还遇到了下文提到的两种意外情况。
3.1 启动时触发了特定版本Kafka的bug
启动Broker时,日志出现异常报错,显示读取index文件损坏,不能启动,如图3所示。遇到这种问题时一般是删除抛出异常的index文件。
index文件存放的元数据指向对应的log文件中消息的物理偏移地址,如图4所示。
那为什么index会发生损坏呢?这是因为index文件是一个索引文件映射,它不会对每条消息都建立索引,而是间隔indexIntervalBytes大小之后才写入一条索引条目,所以是一个稀疏文件。Kafka运行时会创建一个log.index.size.max.bytes大小的index文件,向其中写入稀疏索引,内容达到阈值后会进行滚动覆盖。根据社区jira的内容[4],在Kafka非正常退出后会出现index损坏的情况,而在0.8及以前版本,Kafka在读取这个损坏的index文件后会出现报错退出无法启动的问题,在0.9版本中对此问题进行了修复[5],处理的逻辑是自动清理这个文件后重建,不抛出异常。
3.2 转移的分区将磁盘空间写满
将故障磁盘从配置文件中删除后重新启动Broker,故障磁盘中所有Topic的分区副本会在剩余磁盘中重新创建,并同步消息数据,此时出现了多个大数据量的分区副本被放入同一个磁盘中,导致磁盘空间被迅速写满。这种情况下,就不能再使用剔除磁盘的方法了。紧急处理时可以采取缩短Topic的保存时间,从物理上减小Topic数据大小,然后分阶段删除磁盘中过期数据,最后重启Broker節点恢复。
4 实验验证
对于磁盘故障这类服务器常见问题,如何能将故障对Kafka集群的影响减少至最低是研究的重点。对此总结了如下的恢复步骤,并通过实验进行了验证,可供参考使用。
4.1 紧急恢复故障时可以剔除故障磁盘后重启
Step1:删除Kafka配置文件config/server.properties中损坏的磁盘(例如data2为故障磁盘,原配置为:“log.dirs=/data0/Kafka-logs,/data1/Kafka-logs,/data2/Kafka-logs,/data3/Kafka-logs...”,更改后配置为:“log.dirs=/data0/Kafka-logs,/ data1/Kafka-logs,/data3/Kafka-logs...”)。
Step2:重启Kafka进程。
结果:原“/data2/Kafka-logs,”目录下的分区会被重新分配到当前Broker的其他磁盘上。
影响:会产生数据倾斜的情况,大数据量的分区叠加到同一个磁盘,可能造成个别磁盘被写满。
4.2 最小化影响恢复故障
集群可允许一个Broker下线时,可暂不重启Kafka进程,待磁盘更换完成后直接重启Kafka进程。
如果当前Broker有多余的一块磁盘作备盘。当Kafka进程下线时,修改配置文件config/server.properties(例如data2为故障磁盘,data9为备盘,原配置为:“log.dirs=/data0/Kafka-logs,/data1/Kafka-logs,/data2/Kafka-logs,/data3/Kafka-logs...”,替换后配置为:“log.dirs=/data0/Kafka-logs,/data1/Kafka-logs,/data9/Kafka-logs,/data3/Kafka-logs...”,用data9替换data2),直接启动Kafka进程。之后在最近的系统维护周期时间点更换坏盘。
4.3 具体实验验证过程
环境:测试集群共3个Broker(Broker1至Broker3),每个主机上挂载5块磁盘(data0至data4)。Kafka配置文件config/server.properties配置了4块磁盘,即data0、data1、data2、data3,data4作为备盘。
Step1:新建测试Topic为testKafka,配置分区为12,副本数为2。此时分区均匀分布,每个Broker中8个分区。
Step2:测试Topic testKafka,进行正常的信息生产和消费,此时查看Broker3中data3目录下面文件,存在2个分区,如图5所示。
Step3:直接删除data3目录,模拟磁盘故障,Kafka进程退出。此时,修改Kafka配置文件config/server.properties,将data3换成data4,即四块磁盘变成了data0、data1、data2、data4。
Step4:上述步骤完成后,重启Broker3服务,此时会发现消费Topic数据时会有短暂告警打印,后续恢复正常。
结果:磁盘data3中的2个分区转移到备用磁盘data4中,如图6所示。
5 结 论
本文描述了在磁盘损坏后导致Kafka集群出现的几种异常情况,提出了在这些情况下的几种故障处理方法,并通过实验进行模拟验证。这些方法可以应用于日常运维Kafka集群的工作中,有效提高了Kafka集群可用性,为避免数据丢失提供了参考方案。
参考文献:
[1] KREPS J,NARKHEDE N,RAOJ.Kafka:Adistributied messaging system for log processing [C]//Proceedings of the NetDB11.[S.l.:s.n.],2012:129-140.
[2] GOODHOPE K,KOSHY J,KREPS J,et a1. Building LinkedIns Real—time Activity Data Pipeline [J].Data Engineering,2012,35:33-45.
[3] ASF JIRA. Shutdown Kafka when there is any disk IO error [EB/OL].(2011-07-19).https://issues.apache.org/jira/browse/KAFKA-55.
[4] ACHANTA V S. Corrupt index after safe shutdown and restart [EB/OL].(2014-11-20).https://issues.apache.org/jira/browse/KAFKA-1791.
[5] PALINO T. Broker should automatically handle corrupt index files [EB/OL].(2015-03-09).https://issues.apache.org/jira/browse/KAFKA-2012.
作者简介:汪涛(1990—),男,汉族,江西九江人,工程师,硕士,研究方向:系统运维。
