基于BERT在税务公文系统中实现纠错功能
2020-11-06袁野朱荣钊
袁野 朱荣钊

摘 要:税务公文作为社会政治的产物,具有鲜明的政治性。而撰制公文是一项严肃的工作,必须保持准确、严肃的文体特点。为减轻撰制者和审核者的负担,该实验针对税务系统,利用基于BERT-BiLSTM-CRF的序列标注模型和BERT掩码语言模型的特点,对公文句子中常见的单个字错误进行了检错、纠错实验。准确率、召回率和F1值相比传统的纠错方法有着明显的提升。结果表明,基于BERT-BiLSTM-CRF的序列标注模型和BERT掩码语言模型在税务公文检错纠错应用中具有较大价值。
关键词:税务公文;BERT掩码语言模型;BERT-BiLSTM-CRF;序列标注
中图分类号:TP391.1 文献标识码:A 文章编号:2096-4706(2020)13-0019-03
Abstract:As a product of social politics,tax official documents have a distinct political nature. Writing official documents is a serious work,and it must maintain accurate and serious style characteristics. In order to reduce the burden of writers and reviewers,this experiment is aimed at the tax system and uses the advantages of the BERT-BiLSTM-CRF-based sequence labeling and BERT mask language model to detect and correct single word errors in official document sentences. Compared with traditional error correction methods,the accuracy rate,recall rate and F1 value are significantly improved. The results show that the BERT-BiLSTM-CRF-based sequence labeling and BERT mask language model have great value in the error detection and correction of tax administrative documents.
Keywords:tax administrative documents;BERT mask language model;BERT-BiLSTM-CRF;sequence labeling
0 引 言
随着对外开放规模的扩大和社会主义市场经济的发展,税收在国民经济中的地位和作用日益增强。税务单位为了加强对税务工作的管理,税务公文的数量规模有了较大的增长。一份税务公文的形成需要经过多个环节,主要包括构思准备、撰写、修改、定稿、清样的打印、清样的校对以及最后的定版印刷等。这些环节中,每一项都很重要。其中在公文成型过程中反复的修改和校对工作更是重中之重,是把好质量关的有效手段,也是避免产生纰漏的有效措施。
从税务公文起草到定版印刷过程中,总是会因为各种疏忽出现这样或那样的错误。如快速打字过程中会出现的错字、多余字、缺漏字等以及错误隐藏较深的同音异义字(“实事求是”写成“实是求是”以及“的”“地”“得”等字的不当使用)等,这些错误在降低了公文质量的同时,也影响到了税务公文所面向群体对政策地理解,从而在某种程度上影响了发文单位的权威性和公信力。因此针对税务工作人员在写作过程中的修改检查和公文打印前的校对这两个环节,本文提出了用自然语言处理技术中的文本纠错来辅助完成上述任务的方法。该方法能够让计算机自动分析文本中的语义信息并对句子中常见冗余,少字,错字,字序颠倒[1]等错误加以纠正,从而帮助工作人员及时发现文本错误并改正,提高工作效率。
1 相关研究
常见的文本检错方法大致可以分为三类,基于规则的方法、基于统计的方法和基于深度学习的方法。基于规则的方法通常依赖于切词工具和足够大的混淆字典;基于统计的方法,通常使用N-gram得出每个字或词的条件概率,计算句子的困惑度,判断句子是否错误。也使用统计机器翻译把检错与纠错过程当作机器翻译任务,在检错的同时,給出修改建议;基于深度学习的方法常用的技术则有以RNN和Self-Attention为基础的深度语言模型等。
近年来,已有大量的深度语言模型用于中文文本纠错,在NLPCC 2018的shared task2上,有道团队把错误分为低级错误和高级错误,低级错误使用相识字音表和N-gram解决,高级错误使用字级、词级Transfomer加以解决,最后再用统计语言模型对候选句子进行通顺度检查,选择困惑度最低的句子完成句子的检错、纠错任务。阿里团队则采用了smt+BeamSearch与Encoder-Decoder(各2层LSTM)+Attention的方法,生成候选句子并结合最小编辑距离和语言模型评分挑选最终结果[2]。
2 基于BERT的检错纠错模型
传统词向量方法如word2vec,glove等单层神经网络为基础的语言模型,不能很好的结合上下文,且一个字或一个词只能用同一词向量表示,在一词多义的情况下无法进行建模,模型深度不够,不能有效提取出语法、语义特征;而ELMo虽然解决了一词多义的问题和模型深度问题[3],但由于BiLSTM不能百分之百解决梯度消失或爆炸的问题,在捕捉长程依赖的方面依然存在问题。
BERT则完全摒弃了时序语言模型的结构[4],采用了多层Transfomer的结构,能够从较深的网络中提取出足够的特征,也能够通过Self-Attention机制和位置编码的方式有效的考虑到上下文信息和字的位置信息,即使是在相同的字不同意思的情况下,也能够充分考虑以上因素得出不同且有效的向量编码。
本模型针对税务公文中常见的错误,将纠错过程分两个阶段,检错阶段与纠错阶段,检错阶段是基于BERT-BiLSTM- CRF的序列标注模型,用以标注出句子中的出错位置。纠错阶段是基于BERT掩码语言模型,用以预测出错位置的字符,从而完成纠错功能。
2.1 检错阶段
检错阶段分别训练了4个针对不同单个字错误类型(冗余、少字、错字、字序颠倒)的序列标注模型,序列标注模型第一层为谷歌预训练好的BERT模型,用以提取句子的深层语义信息并输出词向量(X);第二层为BiLSTM。由于BERT中的Self-Attention机制削弱了序列消息,因此用BiLSTM接收BERT传过来的词向量信息,并为之后的输出增加前向和后向的序列信息(H);第三层为CRF,用来考虑标签间的依赖关系,为预测的标签添加一些约束来保证预测标签的合法性(P)。序列标注模型如图1所示,图中O为正确字符的标注,W为错误字符的标注。
2.2 纠错阶段
通过序列标注模型预测出句子每个字所对应的标签后,针对冗余错误,直接删除被标注成冗余的字;字序颠倒的错误,将带有标注成字序颠倒的字调换过来即可;少字和错字则在对应的标注少字和错字的位置增加和替换“[MASK]”标签后,输入BERT掩码语言模型,通过该模型预测,得到对应位置的字,从而完成纠错。冗余和少字纠错过程如图2所示。
3 实验语料及标注方式
考虑到税务公文的常见出错特点,作者在搜集的税务公文正文语料中,随机选取了各类单字错误的语料共4 000条,其中2/3作为训练集,1/3作为测试集,另外推理时测试集还加入了相同数量的正确句子。针对冗余、少字、错字、字序错误不同错误类型,错误示例与标注方式如表1所示。
4 实验经过
本文模型建立在Tensorflow框架上,BERT模型加载的是谷歌训练好的chinese_L-12_H-768_A-12检查点。训练阶段只对序列标注中的BiLSTM-CRF层进行参数调优。在预测阶段,将每一个测试集的句子分别由4个序列标注模型独立预测,并按如下公式来判断句子是否出错。
其中,n为序列标注模型数量,Wn为每个模型预测对应的权重,Mn为每个模型对句子的判断,正确为1,错误为0。如果Score大于0.5则判断句子是正确的,否则,则判定句子是错误的。
之后对预测为错误的句子,按上述纠错阶段的方法进行纠错,得到4个纠错后的句子以及错字和少字预测结果各5个候选句子,再计算每个句子的困惑度,将句子困惑度最小的句子作为最后预测结果。
5 评价标准及实验结果
本实验检错纠错的评价指标有精确率(P)、召回率(R)、和F1值。具体计算公式为:
其中,Tp为错误句子被模型指出或纠正正确的数量,Fn为错误句子被预测成正确句子的数量,Fp为模型认为句子有错但判断错误的数量,包括两种情况:(1)句子正确,模型认为有错;(2)句子有错,但模型预测的错误与句子实际错误不同。
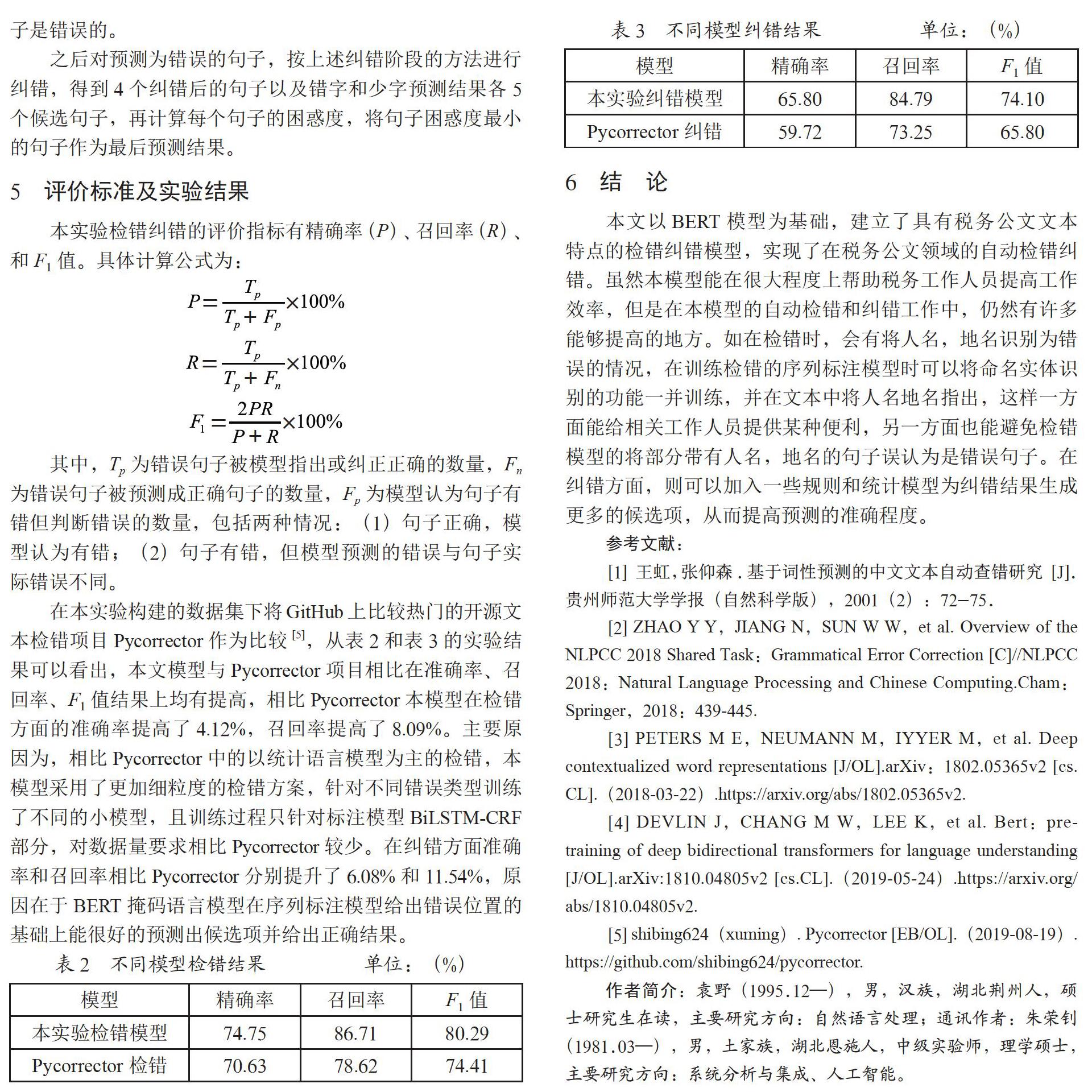
在本实验构建的数据集下将GitHub上比较热门的开源文本检错项目Pycorrector作为比较[5],从表2和表3的实验结果可以看出,本文模型与Pycorrector项目相比在准确率、召回率、F1值结果上均有提高,相比Pycorrector本模型在检错方面的准确率提高了4.12%,召回率提高了8.09%。主要原因为,相比Pycorrector中的以统计语言模型为主的检错,本模型采用了更加细粒度的检错方案,针对不同错误类型训练了不同的小模型,且训练过程只针对标注模型BiLSTM-CRF部分,对数据量要求相比Pycorrector较少。在纠错方面准确率和召回率相比Pycorrector分别提升了6.08%和11.54%,原因在于BERT掩码语言模型在序列标注模型给出错误位置的基础上能很好的预测出候选项并给出正确结果。
6 结 论
本文以BERT模型为基础,建立了具有税务公文文本特点的检错纠错模型,实现了在税务公文领域的自动检错纠错。虽然本模型能在很大程度上帮助税务工作人员提高工作效率,但是在本模型的自动检错和纠错工作中,仍然有许多能够提高的地方。如在检错时,会有将人名,地名识别为错误的情况,在训练检错的序列标注模型时可以将命名实体识别的功能一并训练,并在文本中将人名地名指出,这样一方面能给相关工作人员提供某种便利,另一方面也能避免检错模型的将部分带有人名,地名的句子误认为是错误句子。在纠错方面,则可以加入一些规则和统计模型为纠错结果生成更多的候选项,从而提高预测的准确程度。
参考文献:
[1] 王虹,张仰森.基于词性预测的中文文本自动查错研究 [J].贵州师范大学学报(自然科学版),2001(2):72-75.
[2] ZHAO Y Y,JIANG N,SUN W W,et al. Overview of the NLPCC 2018 Shared Task:Grammatical Error Correction [C]//NLPCC 2018:Natural Language Processing and Chinese Computing.Cham:Springer,2018:439-445.
[3] PETERS M E,NEUMANN M,IYYER M,et al. Deep contextualized word representations [J/OL].arXiv:1802.05365v2 [cs.CL].(2018-03-22).https://arxiv.org/abs/1802.05365v2.
[4] DEVLIN J,CHANG M W,LEE K,et al. Bert:pre-training of deep bidirectional transformers for language understanding [J/OL].arXiv:1810.04805v2 [cs.CL].(2019-05-24).https://arxiv.org/abs/1810.04805v2.
[5] shibing624(xuming). Pycorrector [EB/OL].(2019-08-19).https://github.com/shibing624/pycorrector.
作者簡介:袁野(1995.12—),男,汉族,湖北荆州人,硕士研究生在读,主要研究方向:自然语言处理;通讯作者:朱荣钊(1981.03—),男,土家族,湖北恩施人,中级实验师,理学硕士,主要研究方向:系统分析与集成、人工智能。
