大数据背景下基于网络搜索数据商品零售价格指数预测研究
2020-11-04刘立新唐晓彬张斌儒
张 瑞,刘立新,唐晓彬,张斌儒
(1.成都理工大学 管理科学学院,四川 成都 610059;2.对外经济贸易大学 统计学院,北京 100029;3.长江师范学院 财经学院,重庆 408100)
一、引 言
商品零售价格指数(Retail Price Index,RPI)是衡量宏观经济运行状况的重要指标之一,反映一定时期内商品零售价格变动趋势和变动程度。RPI的调整变动不但影响到各地区居民的生活支出、消费与积累的比例;同时,还会对国家财政收支、市场供需平衡产生巨大影响。各地区RPI也是地方政府进行经济分析、经济核算及经济决策等重要参考指标,其调整变动关系到地方宏观经济调控措施的制定和实施效果。因此,实时监测、预测RPI走势对地方宏观经济健康运行具有重要意义。虽然,中国商品零售价格指数的合成以抽样调查方法为基础,数据具有较强的真实性和权威性,但同时存在一定的局限性:首先,RPI数据的发布存在明显的时间滞后性,当月数据在下月中下旬才能发布,使该指标在反映地方宏观经济运转状况时具有时滞性;其次,在有关RPI预测研究中,研究者较难全面获取与其相关的经济指标数据,影响到预测效果和精度。预测效果与精度不仅取决于预测模型合理构建,还取决于预测变量的恰当选取,然而引起RPI趋势变化的因素众多,不仅有商品供求关系的经济因素,还涉及诸如“税收”“利率”“汇率”等经济环境因素,这导致该指数呈现出复杂的非线性特征,而传统的预测数据及方法无法有效地拟合其变化特点。在大数据时代背景下,基于网络产生了海量有价值的网络搜索数据,这为指数预测研究提供了新的数据来源。网络搜索数据(如百度指数)常以日度关键词搜索量与该词衍生词总搜索量的比值为统计对象,具有较强的时效性,数据涉及内容全面覆盖面广,包含着丰富的价值信息。同时,伴随人工智能技术的不断完善,非线性预测技术取得了长足的发展,本文拟借助机器学习方法,结合网络搜索数据,探求一种有效的预测技术,对宏观经济指标商品零售价格指数进行预测相关研究,以期弥补RPI发布滞后等不足。
随着智联互联网时代到来,互联网搜索数据成为提高预测精度的积极补充,广泛应用于社会和经济等相关研究中。网络使用者通过网络搜索行为满足对所关注经济变量信息需求,从而做出相应行动决策,其决策行为又对经济变量产生一定影响,因此网络搜寻数据的变化实则为所关注经济变量在互联网上的一种映射和呈现。一些学者聚焦于网络搜索与经济变量的相关性分析和探讨,如网络搜索与失业率、通货膨胀、石油价格、股票收益率等等[1-2]。研究显示,网络搜寻关键词与大量经济变量间存在相关性,这为经济变量预测研究中预测变量选取和预测输入集构建奠定了基础。在基于网络搜索数据经济变量预测研究中,一部分文献针对指标类预测,利用与房地产相关搜索数据构造预测集,预测城市房价指数,以期弥补传统房价指数不足等[3]。另一部分文献针对非指标类预测,如将搜索关键词用于股票市场走势、旅游客流量、酒店入住率等方面预测[4-5]。相关研究显示,网络搜索数据的引入能显著提高预测模型的预测性能,预测结果呈现出较强的时效性,同时网络数据的即时性能够很好地弥补传统的监测方法的滞后,具有更强的时效性。虽然,这些研究在实证上取得了一定突破,但仍存在一些不足之处:首先,在内在机理方面挖掘得不够充分,也未形成系统的理论框架,特别是对网络搜索数据与研究对象之间的内在机理尚未进行深入的研究;其次,网络搜索数据本身存在较大噪声,如何从海量数据中提取有预测价值的相关搜索关键词,这一数据预处理方法还有待完善。
在宏观经济指标走势预测技术选择中,主要预测技术大多集中于传统ARIMA时间序列模型、BP神经网络模型、灰色预测模型及马尔科夫状态转移模型等。宏观经济指标走势变化具有非线性特征,常规线性预测模型对其变化趋势不能精确刻画; ARIMA模型与BP神经网络预测虽具有一定的非线性预测能力,但ARIMA模型长期预测效果差,样本外推能力较弱,BP模型存在收敛速度较慢、易陷入局部最优等缺陷;而灰色预测模型普遍存在预测精度偏度的问题。张玲玲等和Vapnik在统计理论的基础上建立支持向量回归模型SVR,该模型表现出优良的非线性预测性能,在解决小样本及高维模型识别问题中显著优于其他模型[6-7]。但是,在运用SVR预测分析时,其预测精度较大程度依赖于模型的参数合理优化和选择。目前,SVR参数寻优主要有遗传算法(GA)、粒子群算法(PSO)和蝙蝠算法(BA)。GA参数寻优主要根据概率而定,参数设置较为复杂,其预测结果缺乏一定的稳定性;BA算法也存在收敛精度不高、易陷入局部极值点等缺陷[8];然而PSO在参数寻优过程中表现出优良的特性,调节参数少、收敛速度快、简单易行,较大提升了模型的预测精度。已有学者将支持向量回归参数优化算法应用于旅游客流量、房价指数等方面预测研究,均取得了较好的预测效果[9],但是在宏观经济指标商品零售价格指数预测研究中鲜有涉及。
为了弥补传统预测变量和预测技术的缺陷与不足,本文结合网络搜寻数据和政府统计数据,构建PSO-SVR&US混合模型对宏观经济指标上海商品零售价格指数进行预测。采用PSO优化SVR模型参数,以2010年1月至2019年9月百度网络搜索数据作为模型输入集。同时,为比较构建模型的有效性,文中引入GA-SVR&US(遗传算法优化模型)、BA-SVR&US(蝙蝠算法优化模型)、SVR&US(未做参数优化的SVR模型)、PSO-SVR(仅利用RPI历史数据作为输入集)作为基准模型进行预测效果对比分析。
二、理论基础与逻辑框架
价格指数反映总体商品价格水平升降程度,均衡价格理论认为商品价格不仅取决于供求关系,同时经济环境因素又对供求关系产生影响,尤其财政和金融货币等宏观因素为影响商品价格重要的因素。如政府税收变动通常会引起商品生产成本的增减,影响商品供求进而导致物价的波动;过度的政府负债将会导致资金流动性稀缺,使得经营者和居民的资金流动性偏少,对整个商品供求造成冲击,引起物价的变动[10];在货币政策实施过程中,常采用调整准备金率、利率、公开市场业务等方式调节货币资本的存量和流量,对资产的相对价格造成影响,改变市场参与各方经济行为,如企业、居民投融资及生产消费行为等,最终使货币政策措施作用于实体经济,从而调节市场商品供求,引起商品物价动态变化[11-12]。随着经济全球化进程加快,国际汇率和国际贸易波动也会对本国货币流通、商品进出口、物价波动产生影响。国际贸易和汇率的波动直接影响到商品的进出口额,对国内市场商品供需平衡造成一定的冲击影响,引起商品价格的起伏,进而通过价格传导于物价指数[13]。此外,经济增长、通货膨胀、就业率、失业率等均会对市场整体商品的供求产生影响,引起物价指数的波动。
在信息传播高度发达的今天,一旦商品价格发生波动、宏观经济环境产生变化,其相关信息会通过报纸、电视、互联网平台等媒介迅速传播。商品信息关注者面对媒介传递的信息可能呈现两种相异状态:确定性接受所得信息状态或不确定性认知状态[2]。确定性认知状态下信息接收个体通常不再通过信息搜索来确认已知信息;而不确定性认知状态的个体可能会进一步采用信息搜索去消除其不确定性。在大数据时代背景,网络搜索引擎成为大众获取所需信息的重要入口,网络搜索已然成为消除不确定性最普遍便捷的方式,同时网络搜索行为产生了海量的有价值的即时性搜索数据[14]。商品信息需求者基于确定信息或通过网络搜索掌握商品及商品有关(如宏观经济环境)充分信息后,常会调整其行为决策以期获得最佳效益;如商品的生产者和消费者基于商品相关信息形成的生产决策与消费决策,这种供需决策将影响到商品供求,作用于商品的价格,引起商品价格的波动。
当市场整体商品价格和宏观环境因素发生大幅变化时,常会引起商品及商品相关信息在媒介中传播频率越高且传播范围越广,其信息受众越多,处于确定性接受所得信息状态或不确定性认知状态人群数量相应增加,从而通过互联网搜索消除信息不确定性搜索行为也随之增加,同时商品信息需求者基于商品及商品相关信息做出的有关商品行为决策对商品价格波动影响也就越大。因此,作为衡量宏观经济运行状况的重要指标,反映一定时期内商品零售价格变动趋势和变动程度的零售价格指数RPI,与网络搜索存在一定关联性,即表现为指数RPI与某些搜索数据在时间趋势上相关性。
据此,本文基本研究思路:选取与商品零售价格指数相关网络搜索关键词,采用人工智能中支持向量回归预测技术,结合多种仿生优化学习算法,对宏观经济指标商品零售价格指数进行预测相关研究。
三、预测技术设计
(一)支持向量回归(SVR)
Vapnik在统计理论的基础上建立支持向量回归模型SVR[7],该模型具有较好的非线性预测能力,基本原理叙述见下:
给定存在N个样本点的训练数据集{(x1,y1),(x2,y2),…,(xN,yN)}⊂Rn×R,其中Rn为n维输入空间,R表示输出空间。通过非线性映射Ø将输入向量xi映射到特征空间F,在F上定义线性函数f(x)为:
f(x)=〈ω,Ø(x)〉+b,
Ø:Rn→F,x∈Rn,ω∈F
(1)
引入结构风险函数:
(2)
其中,‖ω‖2为Euclidean范数,控制模型的复杂度;C为大于零的常数,称为调节参数,调节模型复杂程度与经验风险;|yi-f(xi)|为ε不敏感损失函数,控制估计偏差,使得估计结果具有较好的鲁棒性,定义形式为:
|y-f(x)|ε=
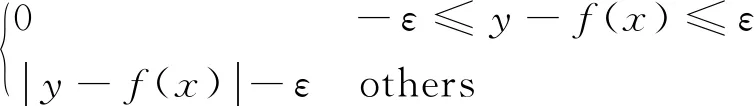
(3)
于是将上述问题归结为带约束的优化模型,等价转换形式为:
(4)

(5)
其中,β和β*为拉格朗日乘子。利用核函数K(xi,x)=〈Ø(xi),Ø(x)〉将变换空间内积转化为原空间内积的某一函数进而计算。本文选取高斯径向核函数,最终回归函数形式为:
(6)
综上,求解SVR模型过程实质上为求解惩罚系数C、不敏感系数ε和带宽σ的三维优化问题,即优化SVR模型中有关参数(C,ε,σ)。其中,正则化参数C调节模型的复杂度与误差精度;ε取值大小影响回归模型的精度;σ反映了训练集分布特征,进而决定局部领域的带宽。
(二)粒子算法(PSO)
James和Eberhart基于鸟群觅食行为提出了粒子群优化算法(Particle Swarm Optimization,PSO)[15]。PSO基本原理概括如下:
PSO算法寻优过程中,每个潜在解被看成一个“粒子”,引入适应度函数以确定每个粒子对应的适应值。粒子移动方向及距离由粒子速度所决定,基于粒子本身及不同粒子移动经验粒子速度进行相应动态调整,进而获得个体在可解空间内的最优。PSO算法首先对粒子与粒子速度进行随机初始化,粒子个数称为种群规模m,在n维空间中粒子i的位置为一个矢量,基于SVR模型中有关优化参数为(C,ε,σ),所以第i个粒子在n维空间中位置、飞行速度、当前时刻最优位置及所有粒子全局最优解分别由式(7)~(10)表示:
x(k)i=(x(k)i1,x(k)i2,…,x(k)in)
(7)
v(k)i=(v(k)i1,v(k)i2,…,v(k)in)
(8)
p(k)i=(p(k)i1,p(k)i2,…,p(k)in)
(9)
p(k)g=(p(k)g1,p(k)g2,…,p(k)gn)
(10)
其中,k=C,ε,σ,i=1,2,…,N,每个粒子速度及位置更新方程为:
v(k)i(t+1)=ϖv(k)i(t)+c1r1(p(k)i-x(k)i(t))+c2r2(p(k)g-x(k)i(t))
(11)
x(k)i(t+1)=x(k)i(t)+v(k)i(t+1)
(12)
其中,ϖ为惯性权重因子,调节前期飞行速度对当期飞行速度的影响;r1、r2为在[0,1]区间上均匀分布的随机数;c1、c2为加速因子,为避免粒子产生盲目搜索行为,通常将速度和位置分别限制在[-vmax,vmax]与[-xmax,xmax]区间上。适应值函数的选择能影响到PSO优劣,本研究采用均方误差MSE作为适应值函数:
(13)
(三)算法流程
模型的具体算法步骤如下:
step1:确立训练集和测试集。将网络搜索数据综合标准化处理,根据皮尔逊Pearson交叉相关分析选取潜在变量,然后采用逐步回归(Stepwise)确定最终预测变量进而构建实验数据集,确立训练集和测试集。
step2:设定种群规模及迭代次数;初始化设定种群的粒子对(Ci,εi,σi),相应的初始位置及速度为(xci,xεi,xσi)、(vci,vεi,vσi)。
step3:采用适应值函数fitness计算所有离子对适应值,将各粒子最优适应值fbesti和最优位置(pci,pεi,pσi)设置为其初始适应值和初始位置。将粒子群最优位置(pcg,pεg,pσg)和最优适应值fgbesti设置为其最优初始粒子对位置和位置。
step4:根据式(11)、(12)对每个粒子对位置和速度进行迭代更新。
step5:比较每个粒子对当前适应值和fbesti,若当前适应值较优,则用当前位置和实验值更新前期位置和适应值。
step6:为了避免模型过拟合,在训练集上采用k折交叉验证(k-CV)法获取最优适应值,进而决定整个种群的最优粒子对。若其适应值优于fgbesti,那么位置(pcg,pεg,pσg)和其适应值更新为当前最优位置和当前适应值。考虑到本文研究的样本容量,取k=5。
step7:如果达到停止迭代准则,则获得最优位置(pcg,pεg,pσg)及适应值fgbesti,否则返回step4。经如上步骤在训练集上获取SVR最优参数集,其后在测试集上对参数优化后的SVR实施预测验证。
四、实证研究
(一)数据来源
上海作为中国经济、金融、贸易、科技创新等中心,是中国与世界交流的重要窗口。上海地区的商品物价指数不仅反映居民生活成本和购买力,而且关系到国家财政收支和市场供需平衡状态。本文的被预测变量为上海市统计局发布的商品零售价格指数,用符号yt表示,数据来源于上海市统计局网站(http:∥tjj.sh.gov.cn),时间范围为2010年1月至2019年9月。预测变量为与上海商品零售价格指数有关的网络搜索关键词,数据来源于百度搜索指数(http:∥index.baidu.com),选取2010年1月至2019年9月日度CP趋势数据,加总平均整理成月度平均数据。由于网络搜索数据自身存在一定噪声,并不是所有关键词均能作为预测变量,所以通过统计相关性分析甄别出具有良好预测性能的关键词显得尤为重要。本文将通过三个步骤选取出最终预测变量:
1.初始网络搜索关键词的确定。本文运用百度推荐与文献查阅方式,分别从宏观与微观视角出发,在财政、货币金融、供求、其他四个方面选取与上海商品零售价格指数有关的74个基准关键词,采用网络爬虫技术获取关键词对应时序数据。基准关键词如表1所示。

表1 初始网络搜索关键词词库
2.潜在预测变量选取。皮尔逊交叉相关分析是基于统计理论的一种直观算法,能够识别不同滞后期时间序列间的相关影响,进而确保获得与上海商品零售价格指数RPI最具相关性的预测变量。取阈值为±0.6,采用皮尔逊Pearson交叉相关分析选取出六个具有潜在预测能力的关键词。
3.预测变量的确定。因为网络关键词对预测模型的边际效应有限,在构建模型的输入集时,并不是所有潜在预测变量都能进入预测模型输入集。为获取最佳预测变量,本文采用逐步回归方法(Stepwise)进行甄别和选取,通过设定显著性水平为0.05,获得了最佳预测能力的四个搜索关键词,结果见表2。
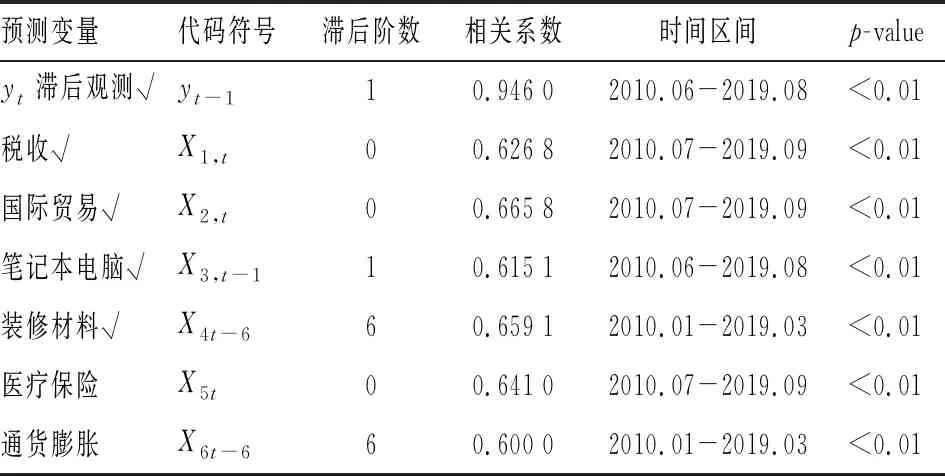
表2 预测变量与商品零售价格指数yt相关性分析
(二)模型输入集构造
从表2可知,上海商品零售价格指数与自身1阶滞后项之间存在显著的正相关,相关系数高达 0.946 0,为提高模型预测性能,故yt的1阶滞后被纳入了预测变量;在商品交换的过程中存在税负转嫁,即纳税人通过提高销售价格或压低购进价格的方法,将税负转移给消费者或供应者,税负转嫁与物价变动存在直接联系,关键词“税收”与商品零售价格指数表现出显著的正相关;国际贸易波动直接影响到商品的进出口额,进而对国内市场商品供需平衡造成一定的冲击,造成地方商品价格的起伏,通过价格传导于物价指数,相关分析发现,关键词“国际贸易”与被预测变量存在显著正相关性;智能互联时代,电脑已经成为现代家庭工作生活中不可或缺的物品,购买电脑支出也是生活成本支出一部分;装修材料价格的高低影响到居民的居住成本,居住成本高低又涉及到居民生活成本,进而对物价产生影响。表中显示,关键词“笔记本电脑”和“装修材料”与RPI存在显著的滞后相关性。
最终预测变量为“税收”“国际贸易”“笔记本电脑”“装修材料”,分别用x1,t、x2,t、x3,t-1、x4,t-6表示,其滞后阶数分别为0期、0期、滞后1期及滞后6期,实验数据集可表为:{yt-1,x1,t,x2,t,x3,t-1,x4,t-6:yt},模型的输入集为{yt-1,x1,t,x2,t,x3,t-1,x4,t-6},yt为模型的输出变量,样本容量总共111个。进一步分析可知,输入集中采用商品零售价格指数RPI滞后一阶的数据(即RPI上月数据,标记为yt-1)及搜索关键词当期及滞后期数据预测RPI当月指数值,而官方RPI当月数据需在下月中下旬才能获得,显然基于最优模型的商品零售价格指数月度预测值比官方数据公布领先半月左右,其预测结果较强的时效性,一定程度上弥补了RPI数据发布滞后缺陷。
在模型数据输入中,为了减少异常值和输入变量不同量级对模型预测能力的干扰和影响,对数据归一化处理,公式如下:
(14)
其中,xi为变量X第i个样本点,xmin与xmax分别为变量X在样本区间内最小值及最大值。数据归一化后其值落入[0,1]区间内。数据归一化处理一定程度可提升模型预测性能。预测结束后,其预测结果再通过逆变换N-1(xi)获得对应实际预测值。考虑到样本容量和预测实验可行性,本文将实验数据划分成训练集和测试集两个部分,前95个数据点用于模型训练,后16个数据点用于预测检验。
(三)模型预测性能度量指标
为对比模型的预测性能,本文采用了相关系数R、平均绝对误差比MAPE、均方根误差RMSE三种指标进行模型预测性能评价。相关性能指标定义如下:
(15)
(16)
(17)
(四)实证结果与评测
通过比较各模型对上海商品零售价格指数预测的性能和效果,将有助于甄别和选取最优预测模型,表3列示了不同模型在测试集上的预测值。
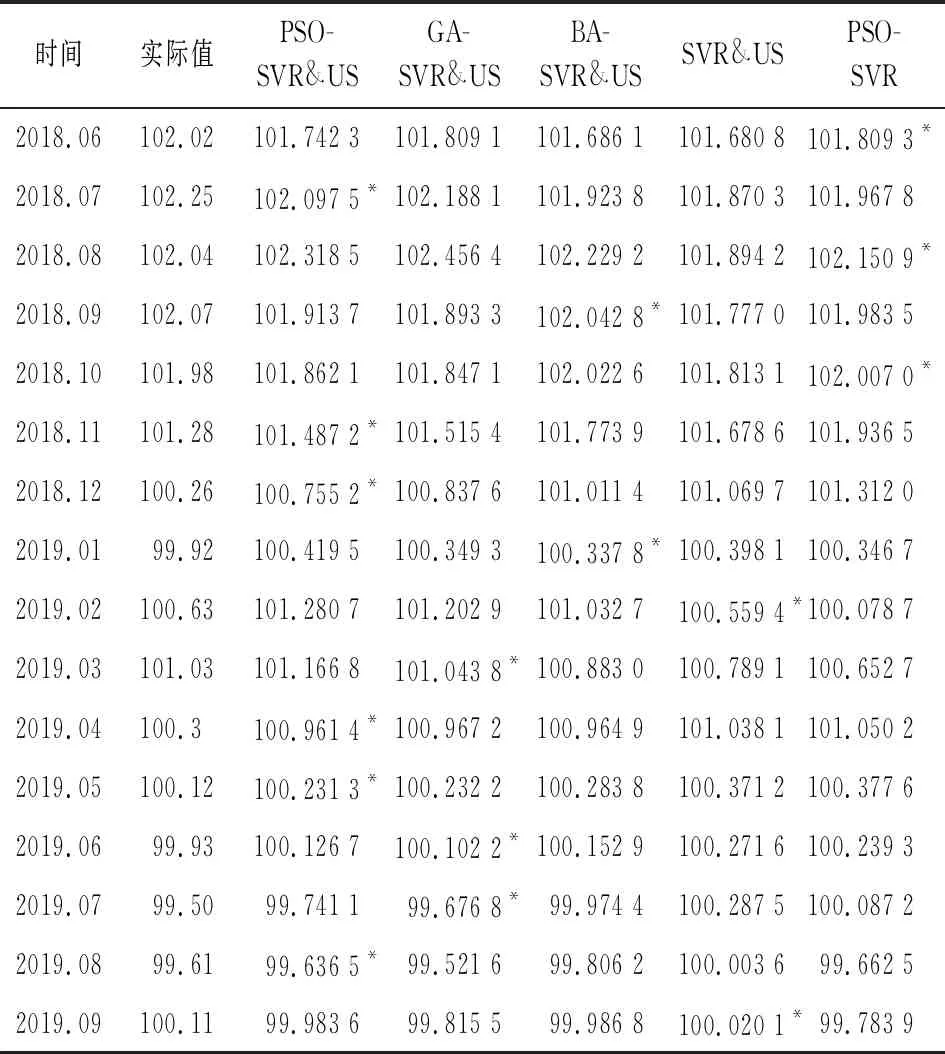
表3 不同模型对上海商品零售价格指数预测结果对比
表3所示,五种预测模型16期预测结果显示,PSO-SVR&US、PSO-SVR、GA-SVR&US、BA-SVR&US、SVR&US最优预测值分别为6个、3个、3个、2个和2个。预测结果直观显示,在上海商品零售指数预测研究中,预测结果的优良不仅取决于网络搜索数据的引入,还依赖于模型的选择,其中参数优化的SVR模型预测效果好于未参数优化的SVR模型,本文所构建的PSO-SVR&US混合模型预测效果最优。
然而,各模型预测性能是否存在一定的差异,我们还需要对统计性指标进行比较验证。基于不同模型预测值的三个统计度量指标值如表4所示。综合看,三个预测性能统计指标结果显示PSO-SVR&US模型预测性能最优,其次为GA-SVR&US模型,输入集中未纳入网络搜索数据的PSO-SVR模型其预测性能表现较差。这进一步印证了上海商品零售价格指数预测中,网络搜索数据有助于商品零售价格指数的预测研究,预测效果好坏和预测精度高低还依赖于最优模型的选取,同时参数智能优化算法的引入提升了支持向量回归模型的预测性能。具体而言,从各个均等系数R角度看,PSO-SVR&US模型R值最大,预测值和真实值相关性最强,而PSO-SVR表现最差;对比五个模型的绝对误差百分比MAPE,PSO-SVR&US模型的值为0.269 1%,其值最小。这说明实际值与预测值误差程度最小,模型具有较高的预测精度。进一步,比较统计性能指标RMSE,PSO-SVR&US值为0.331 6,小于其他模型对应值,这意味着相比于五种模型,PSO-SVR&US预测值和实际值具有最小偏差,拥有较好预测性能。
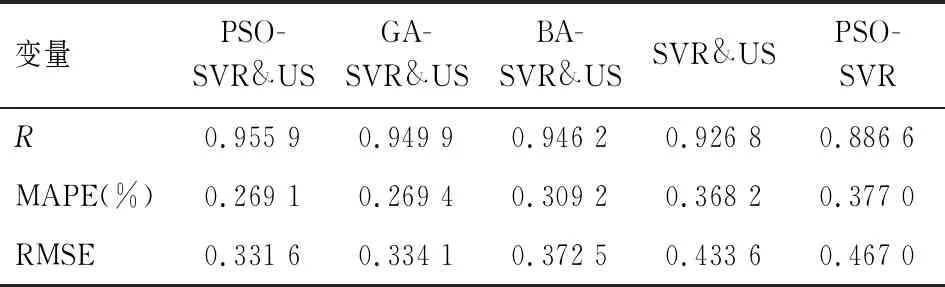
表4 不同预测模型统计性能指标对比
在基于PSO-SVR&US混合模型上海商品零售价格指数预测研究中,根据预测流程,初始化模型参数后,结合训练集数据采用PSO对支持向量回归模型进行训练以获取模型SVR最优参数设置,随后在测试集上使用最优参数模型展开预测实验。运用MATLAB 软件进行实验,训练所获得PSO-SVR&US模型最优参数为:C=99.998,ε=0.383 3,σ=0.01。为了进一步直观呈现模型预测效果,图1给出了训练后模型在样本区间内的拟合曲线。
图1中实际值和拟合值曲线趋势特征直观体现了PSO-SVR&US混合模型拥有较好的拟合效果,预测值和实际值变化趋势较为一致,说明了所选最优模型具有良好的预测性能。泛化能力是指机器学习方法训练出的模型,在训练集预测性能表现良好,同时在测试集上也表现出良好的预测性能,也即是指机器学习算法对新鲜样本的适应能力。通常采用平均绝对误差比(MAPE%)来反映模型的预测精度,当MAPE%<10时,其预测精度较高,其值越小模型的拟合程度越高[16]。经计算,平均绝对误差比(MAPE%)在训练集与测试集上分别为 0.219 9 和 0.269 1,其值远小于10,这表明PSO-SVR&US混合模型在训练集和测试集上具有良好的预测性能,模型的泛化能力较好。
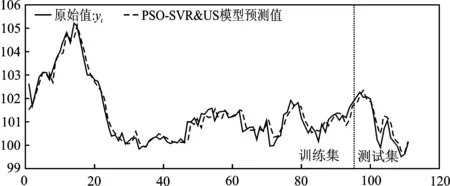
图1 训练集和测试集PSO-SVR&US模型拟合效果图
(五)稳健性分析
在上述上海商品零售价格指数预测研究关于最优模型的选择比较过程中,各模型均将实验数据中前95个数据划为训练集,后16个数据作为测试集。但当测试集和训练集样本容量发生改变时,所选择的最优模型是否仍然在测试集上具有良好的预测精度和预测效果是验证模型预测性能与模型稳健性的依据。为了检验本文构建的混合模型稳健性,如下改变训练集和测试集样本容量,将实验数据前100期做为训练集,数据的后11期作为测试集。在测试集上不同模型预测结果和性能指标比较分别见表5与表6。
表中结果显示,最优模型PSO-SVR&US预测性能仍优于基准比较模型,从统计性能指标看,MAPE(%) 和RMSE分别为0.318 2和0.370 6,表4中预测值MAPE(%) 和RMSE分别为 0.269 1 和 0.331 6,对比可看出,在训练集和测试集两种不同划分下,统计指标值变差别较小,预测性能稳定。综上可知,关于上海商品零售价格指数RPI预测研究中,网络搜索数据有助于商品零售价格指数的预测研究,并且预测效果好坏和预测精度高低还依赖于最优模型的选取;最优模型PSO-SVR&US模型呈现出良好的预测性能归因为:首先,支持向量回归模型SVR在解决非线性、小样本预测问题时拥有优良的特性。因为SVR是基于结构风险最小化原则,故具有较好分类稳定性;其次,在SVR模型参数选择和优化过程中,PSO具有结构简单、快速收敛、稳健性等特征,较大程度上提升了SVR预测性能,保证了PSO-SVR&US模型良好泛化性。
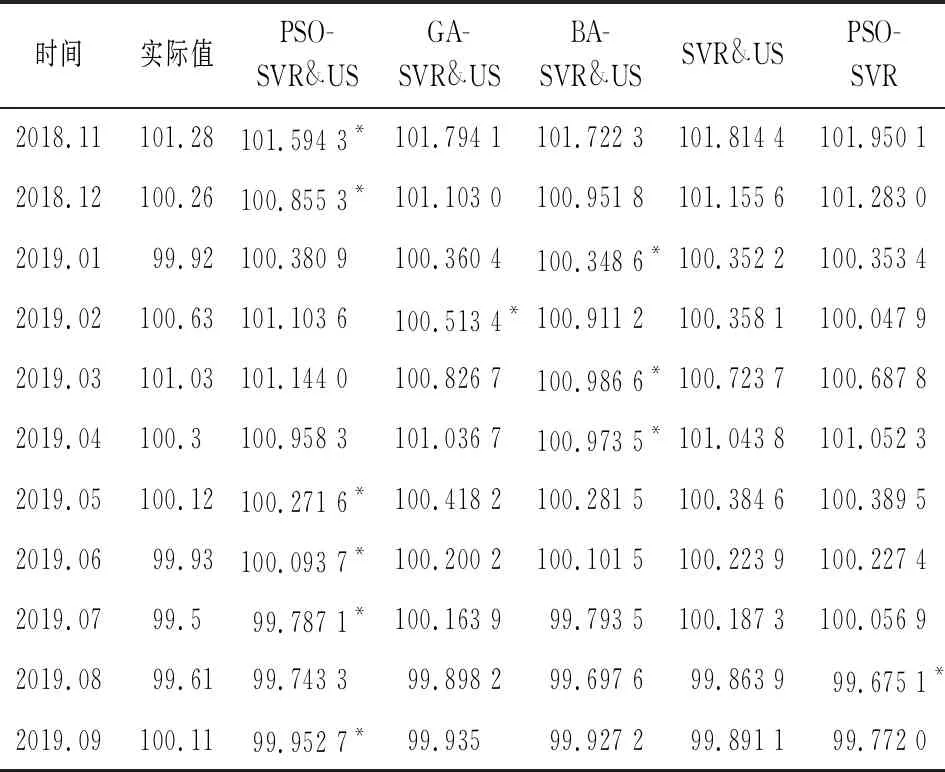
表5 不同模型对商品零售价格指数(RPI)预测结果对比(2018.11—2019.09)
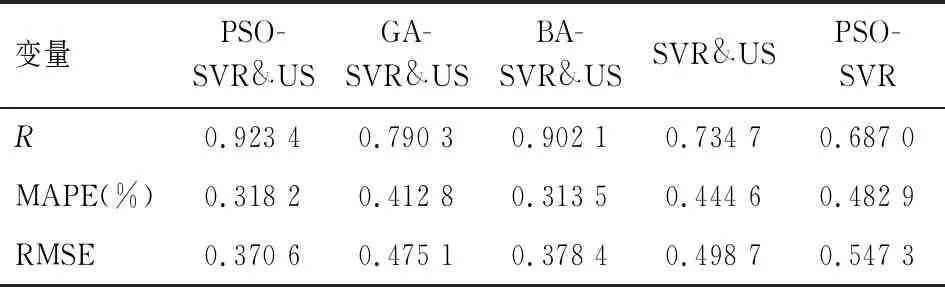
表6 不同预测模型统计性能指标对比(预测11期)
五、结 论
在大数据时代背景下,广大互联网用户利用搜索引擎获取更多的私密咨询,大量的搜索数据为研究者提供了更具时效、反映用户真实意愿的信息。在一定程度上对传统统计数据提供了必要的补充和完善,弥补了传统数据获取成本高、滞后性长等不足,为宏观经济指标趋势预测提供了一种崭新的视角。本文针对宏观经济指标上海商品零售价格指数非线性变化特征,结合网络搜索数据,引入支持向量回归SVR多种参数优化模型对商品零售价格指数进行预测研究。在网络搜索数据的筛选和最终预测变量确定过程中,模型输入集中采用商品零售价格指数RPI滞后一阶的数据及搜索关键词当期及滞后期数据预测RPI当月指数值,其预测结果比官方数据公布领先半月左右,网络搜索数据的引入使预测结果具有较强的时效性。在最优模型的比较和选取中,通过预测结果性能指标对比显示,网络搜索数据有助于商品零售价格指数的预测研究,并且预测效果好坏和预测精度高低还依赖于最优模型的选取。同时,也验证了PSO-SVR&US模型是一种合适的上海商品零售价格指数良好预测方法,基于最优模型的预测值可为及时监测商品零售价格指数变动和经济宏观调控提供有价值的参考。
