基于时间序列支持向量机的信用额度预测
2020-11-04屈新怀马文强丁必荣
屈新怀, 马文强, 丁必荣, 牛 乾
(合肥工业大学 机械工程学院,安徽 合肥 230009)
0 引 言
经销商销售渠道是整车营销的核心环节之一。由于大部分经销商属于中小企业,汽车整车厂商对于汽车的销售主要采取信用赊销的形式。因此建立经销商的信用模型,对汽车整车厂商减小应收账款风险、保证信贷资金安全具有重要的现实意义[1]。
在信用评价模型方面,传统的信用评价模型常使用统计学方面的知识。文献[2-3]使用层次分析法和模糊评价法的组合模型;文献[4]通过将统计抽样理论中分层思想与逻辑回归模型相结合,构造基于分层逻辑回归的小企业信用评价模型。随着智能算法的发展,决策树、神经网络、支持向量机等算法逐渐运用于信用评价领域。文献[5]使用反向传播(back-propagation,BP)神经网络建立信用度的基本概率分配函数,为信用风险的决策提供依据;文献[6]提出了一种结合遗传规划(genetic programming,GP)和BP神经网络的信用评估模型,对受评目标的信用分类具有较高的准确度;文献[7]使用正交支持向量机解决信用评分中数据维度灾难问题。针对信用数据的连续性、信用状态的动态性情况,文献[8-9]基于多维时间序列数据观察受评目标信用等级的状态趋势及“波动”情况,但未从定量的角度考虑受评目标的信用情况。
考虑到经销商信用数据样本少以及数据的连续性特点,本文从受评经销商的历史业务数据出发,使用多维时间序列数据建立支持向量回归(support vector regression,SVR)模型,动态地预测经销商对应的信用额度,为更好地管理经销商提供一定的依据。
1 多维时间序列的SVR预测模型
1.1 多维时间序列相空间重构
(1) 相空间重构原理。记有m维时间序列{X1,X2,…,Xm},其中Xi=[xi,1xi,2…xi,n],i=1,2,…,m,变量n为时间序列的长度,m为时间序列的个数。
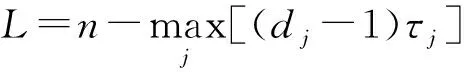
Vi=[v1,iv2,i…vm,i]
(1)
其中,i=1,2,…,L;j=1,2,…,m;vj, i=[xj,ixj,i+τj…xj,i+(dj-1)τj],τj、dj分别为第j个变量时间序列的延迟时间和嵌入维数,xj,i为数据序列中第j个变量在序列中第i个位置上的数值。
(2) 延迟时间和嵌入维数的确定。选择延迟时间τ一般使用自相关法,即通过计算变量的自相关函数,选择自相关函数第1次为0时所对应的τ为相空间重构的延迟时间。确定嵌入维数使用饱和关联维数法,且嵌入维数d和饱和关联维数D满足d≥2D+1。
关联维数Dd定义为:
(2)
(3)
其中,‖Xi-Xj‖为两时间序列向量的欧氏距离;r为介于欧氏距离最大值和最小值之间的变量;H(x)为:
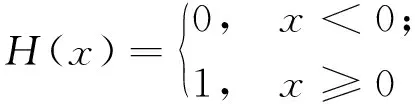
(4)
通过适当调整r,可计算出一组lnr、lnC(r)的值,从而根据(2)式计算关联维数Dd。随着嵌入维数d增加到一定程度,关联维数Dd趋于稳定。取饱和值D作为饱和关联维数,根据公式d≥2D+1确定合适的相空间嵌入维数d。
1.2 SVR预测模型
(1) SVR原理。SVR是从建立在统计理论的VC维理论和结构风险最小理论的基础上发展的分类支持向量机拓展而来的[11]。对n维空间Rn上线性数据回归的基本思路如下:给定一组训练数据集D={(x1,y1),(x2,y2),…,(xn,yn)},在数据集中xi∈Rn,yi∈R,求解Rn中的超平面线性函数为g(x)=ω·x+b,使用函数y=g(x)对任一输入x预估对应的输出值y。
根据对偶理论并引入Lagrange函数,对于线性ε-支持向量回归机,使回归问题转化为凸二次规划问题,即
(5)
i=1,2,…,n
(6)
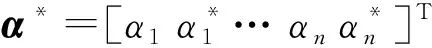
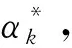
(7)
从而构造的决策函数如下:
(8)
对非线性数据,SVR处理的基本思路是通过引入核函数代替(8)式中的内积运算,即将样本空间中非线性低维数据映射为特征空间中的高维线性数据,即
(9)
其中,K(xi,x)为核函数。
(2) 预测方法。从整车厂商的经销商管理系统(dealer management system,DMS)中获取有关数据:① 按月份汇总数据,整理成多维时间序列的形式;② 根据1.1节所述对经销商多维时间序列信用数据进行相空间重构,对于确定的经销商信用数据序列,其相空间重构的参数一般比较稳定,不必每次预测都进行更新计算,可以根据实际应用需要按照季度进行更新;③ 选取相空间中的相点与对应的信用额度组成SVR模型的训练样本,进行SVR模型参数的寻优;④ 选取剩余的相点与对应的信用额度组成预测样本,利用训练好的SVR模型进行预测;⑤ 根据预测数据和实际数据的均方根误差ERMES来评价模型的预测效果。
均方根误差形式如下:
(10)
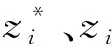
预测流程如图1所示。
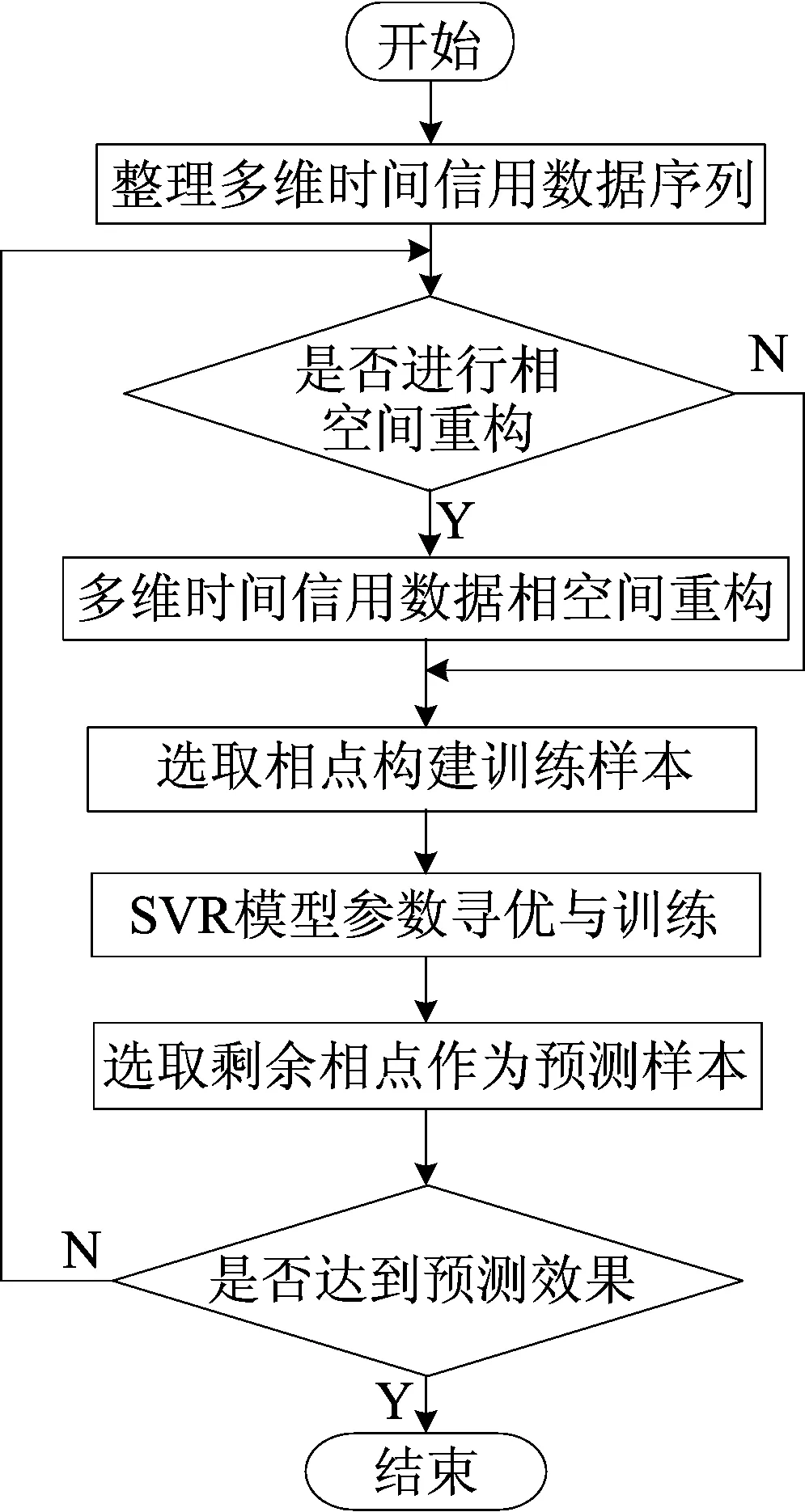
图1 信用额度预测流程
2 经销商信用额度预测分析
2.1 多维时间序列数据的构造
本文选取某经销商业务数据中影响信用额度较大的2个变量,即开票金额和回款金额。根据其业务情况,选取2013—2017年的记录数据,时间间隔为1个月,共计60个月,即n=60。
现给出某经销商在2017年的业务数据以及整车厂商给予经销商的信用额度数值,具体见表1所列。

表1 某经销商2017年业务数据与信用额度 万元
因为不同月份间的数据变化较大,为减少误差,分别对原数据的各变量进行0-1归一化处理,即
(11)
其中,X*为映射后的数据;x为原始数据;xmax、xmin为原始数据中的最大值和最小值。经过预处理后的数据将作为相空间重构的来源。
2.2 相空间重构
开票金额与回款金额的相关系数计算公式为:
ρ=
(12)
其中,n为序列的长度,n=60;xi、yi分别为归一化后信用数据序列中第i点的开票金额和回款金额。
计算得到ρ=0.892 5,表明2个变量具有极强的相关性,因此考虑2个变量在重构相空间时拥有相同的延迟时间与嵌入维数。
在确定合适的延迟时间τ时,若τ过大,则会导致相空间中两相邻时刻的动力学形态变化剧烈,使系统信号失真,产生不相关误差,因此本文结合经销商信用数据情况,选择2个变量的延迟时间τ1=τ2=1。
根据1.1节介绍的饱和关联维数G-P法,依据经销商的回款数据计算出在不同维数下lnr、lnC(r)的值,绘制嵌入维数d为2~12情况下的曲线,如图2所示。图2中曲线从左至右对应的维数为2~12。
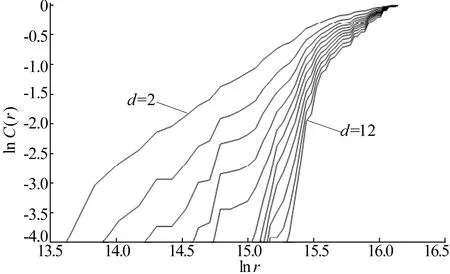
图2 某经销商回款数据ln r -ln C(r)关系曲线
求取每条曲线所包含的直线区域斜率,作为各嵌入维数对应的关联维数,结果见表2所列。
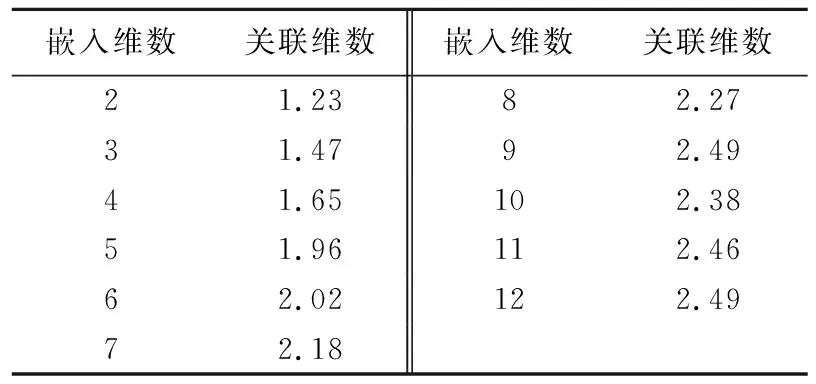
表2 嵌入维数与关联维数的关系数值

Vi=[xixi+1…xi+5yiyi+1…yi+5]
(13)
其中,i=1,2,…,55;xi、yi分别为信用时间序列中第i点的开票金额和回款金额。
对应的额度输出Z=[z1z2…z60],zi为第i个月的信用额度。根据嵌入维数及实际预测情况,本文构建的数据集为{(V1,z7),(V2,z8),…,(V54,z60)}。
2.3 SVR预测比较
选取数据集中的前40个点作为SVR模型的训练数据集{(V1,z7),(V2,z8),…,(V40,z46)},在本例SVR预测模型中选用高斯径向基核函数(radial basis function,RBF),其核函数形式如下:
(14)
使用网格搜索和交叉验证法对(6)式中惩罚参数C和(14)式中核参数σ进行寻优,计算得到C=0.353 5,σ=2.828 4。数据集的后14个点组成预测数据集{(V41,z47),…,(V54,z60)}。
使用预测数据集对模型进行效果分析,并采用Matlab进行算法仿真,计算的归一化后均方根误差ERMSE=0.91%,预测曲线如图3所示。

图3 多维时间序列SVR预测模型的预测效果
为了验证构建的时间序列信用数据在经销商信用额度预测中的有效性,使用该经销商在孤立时间点上的信用数据进行SVR预测信用额度,经过同样的归一化预处理和SVR预测后,计算得到均方根误差ERMSE=4.98%。通过对比均方根误差ERMSE可知,使用多维时间序列数据进行的预测效果较好。
3 结 论
针对整车厂商授予经销商信用额度的问题,本文提出了一种基于多维时间序列支持向量机的预测方法,从时间序列的角度考察经销商信用额度的变化趋势,并运用SVR算法对经销商信用额度进行预测。
本文使用预测值与实际值的均方根误差作为评估标准,将结果与孤立时间下的多维变量信用额度预测结果相比较,验证了本文方法具有较高的预测精度。
