基于集成神经网络的剩余寿命预测
2020-11-03张永峰陆志强
张永峰,陆志强
同济大学机械与能源工程学院,上海 201804
机器与设备的健康管理与故障诊断一直工业界与学术界关注与研究的热点,而剩余寿命预测(RUL)恰恰是设备健康管理与故障诊断(Prognostics and health management, PHM)的一个核心技术[1]. 并且,准确的RUL预测还可以为设备或部件制定相应的维护策略提供重要的信息[2-3]. 已经有多名学者提出了关于RUL预测的各种模型与方法,主要分为2大类:基于物理模型的预测方法[4]和基于数据驱动[5]的预测方法. 但是由于设备和部件的结构日益复杂,再加上各种环境的影响,很难用物理模型去准确地预测RUL[6]. 而且,随着大数据时代的到来,我们获取机器的大量数据日益简单,再加上计算机技术的不断发展,使用数据驱动的模型去预测RUL已成为主流的方法了.
Long等[7]建立一个以遗传算法来优化的ARMA(Autoregressive moving average model)模型用来预测RUL. Wu等[8]提出了一种ARIMA(Autoregressive Integrated Moving Average model)模型预测未来的机器状态,从而实现故障诊断和RUL预测,并且通过改进的预测策略和自动预测算法提高了其准确度. Zhou与Huang[9]提出了一种经验模态分解和ARIMA模型的锂电池的RUL预测模型.Tian[10]建立了一个人工神经网络(Artificial neural networks, ANN)用来预测设备的RUL. 该网络以设备的役龄以及当前和过去的检测点的多状态检测数据的为输入,以设备的生命周期百分比作为输出. Mosallam等[11]提出了分两阶段来预测RUL:先利用无监督方式筛选出蕴含大量退化信息的变量,然后利用这些变量进行离线训练来建立不同的健康指标曲线:然后在线利用K近邻算法寻找与离线库中最相似的HI来进行RUL预测. Khelif等[12]通过支持向量回归直接对感应器和健康状态建立直接关系来预测RUL,减少了设备健康状态曲线拟合与失效阈值设立的步骤. Miao等[13]利用改进的粒子滤波器—无迹离子滤波器来预测锂电池的RUL. Tobon-Mejia等[14]提出了一种基于小波包分解技术和混合高斯隐马尔科夫来预测RUL的模型. Li等[15]为了使RUL预测更加准确,提出了一种考虑机器退化对于预测RUL的影响的集成学习模型,该模型分配给每个学习器一个优化过的与退化相关的权重来使所有学习器对RUL的预测权重之和更大. Heimes[16]采用循环神经网络(Recurrent neural network, RNN)对设备的RUL进行了预测,并在竞赛中取得了不错的成绩. Babu等[17]采用深度卷积神经网络先通过原始数据进行卷积,池化等操作提取特征,而后进行RUL预测.Yuan等[18]提出了针对飞机发动机在复杂操作和多重故障以及噪声干扰情况下的基于LSTM网络的RUL预测模型. Zhang等[19]也提出了LSTM网络对锂电池的RUL做出预测. Ordóñez等[20]提出了一种ARIMA和支持向量机(Support vector machine, SVM)相结合的对于飞机发动机的RUL进行预测的模型,并与VARMA(Vector auto-regressive moving average)模型进行了比较.
上述文献中所提的大多RUL预测中,一般包含3个步骤,一是对原始数据提取特征,二是建立设备健康曲线,三是进行RUL的预测[21]. 由于现代机器设备复杂度高,一般有多个传感器同时监测一个设备的健康状态,其监测数据维度较大,样本量大;传统的数据驱动RUL预测方法往往需要人工提取某些特征,再进行筛选和融合,而人工提取特征需要一定的经验与知识,并且相同特征在不同设备RUL预测上差异可能较大,模型泛化性能较差;目前许多基于数据驱动的RUL预测模型未考虑到传感器信号的时序相关特征,而忽略时间点的时间关系可能丢失重要的信息,导致模型预测性能降低. 这些因素均导致了传统预测模型预测精度不高. 针对以上问题,本文运用卷积神经网络(Convolutional neural network, CNN)强大的特征提取能力,避免了人工提取特征,减少了人工工作量与操作难度,提高了模型的泛化能力. CNN一般用于处理图像数据,而本文采用的一维CNN常用于处理时间序列数据. 相比于长短期记忆(Long short-term memory, LSTM)只能访问每个特定的时间步骤,双向LSTM不仅能实现数据的长期记忆,还能够从正反两个方向同时处理数据,为序列中数据提供过去和未来的信息,发现更多时间序列的特征,有助于提升RUL预测的准确度.而集成学习则是利用多个学习器结合来提升整体的学习性能,在机器学习领域被广泛应用. 因此,基于前人的研究基础上,本文提出一种集成一维CNN与双向LSTM的网络模型来对RUL进行预测.
1 模型算法描述
卷积神经网络作为深度学习的一种经典结构,其已经在图像识别,物体检测,人脸识别,自然语言处理等方面有巨大的发展与广泛的应用. 本文所采用的是一维CNN结构,其常用于处理文本与时间序列数据,一维CNN的卷积操作如图1所示.
LSTM网络是RNN的一种特殊形式,是为了解决RNN的长期依赖问题和训练过程会出现梯度消失以及梯度爆炸等问题所提出的一种神经网络结构[22-23]. 其示意图如图2所示.
LSTM单元可用如下公式进行描述:

对于输入X=(x1,x2,···,xt),LSTM网络仅利用前向输入数据,即到的时间序列,而对于到的反向时间序列并没有利用. 而双向LSTM可以同时利用到和到的双向时间序列,可以更好地挖掘出时间序列的内部特征. 双向LSTM的结构如图3所示.
集成学习是一种重要的机器学习算法,主要利用多个学习器的集成来解决分类或回归问题,能够提升整体学习系统的准确性. 但是集成学习算法比较依赖数据集的特性以及产生差异性的方法. 同样,CNN和双向LSTM也有一定的弊端,如需要调参数,需要大量样本来训练,其训练时间一般长于机器学习算法;CNN卷积层提取到的特征物理含义不明确,且神经网络本身就是一种难以解释的“黑箱模型”.
双向LSTM以其独特结构:输入门,输出门,遗忘门以及双向输入结构,可将时间序列数据做自适应地回归预测,其在处理时序数据的性能优于一般深度学习模型. 考虑到用于剩余寿命预测的传感器数据维度多,数量大,通过人工提取特征往往不准确,泛化能力差. 而一维卷积神经网络通过多通道和多种非线性转换、方程的处理,具有自适应提取时间序列上的特征,其多个卷积核也有利于提取各种维度的时域特征. 相比于直接应用双向LSTM进行预测,通过将一维卷积神经自适应提取到的时域特征数据输入到双向LSTM网络中,可剔除原始数据中的不必要信息,从而有利于提高双向LSTM的预测准确性. 基于以上描述,本文构建的预测模型如图4所示,同时采用bagging的方式来获得不同数据组,并对不同结果求平均值来得到最终的RUL.
2 实验数据处理与模型构建
2.1 数据介绍

图1 一维CNN的操作示意图Fig.1 Illustration of the one-dimensional convolutional neural network operation
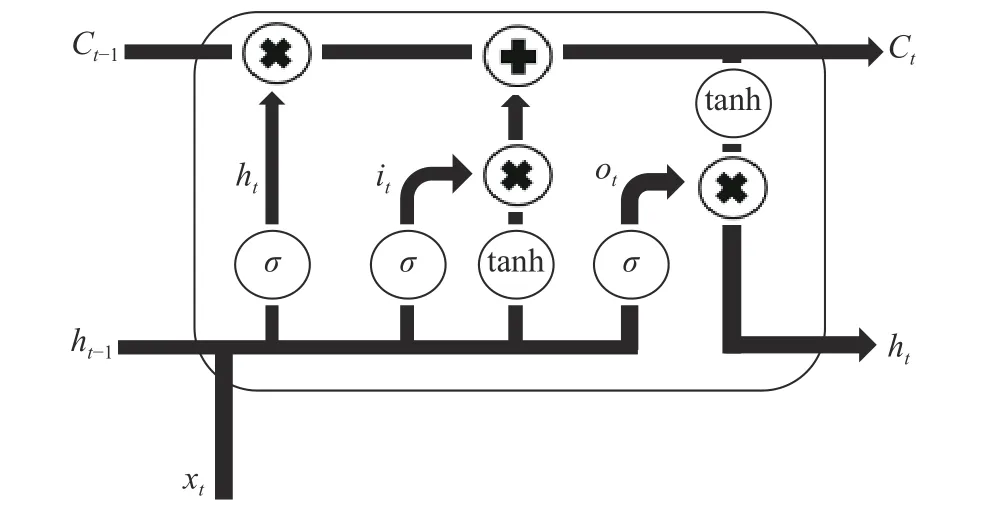
图2 LSTM单元结构示意图Fig.2 Diagram of the LSTM cell
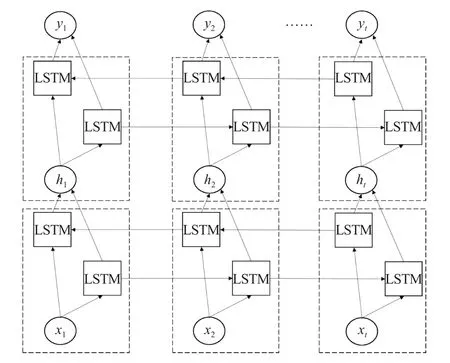
图3 双向LSTM操作示意图Fig.3 Diagram of the bidirectional LSTM network
本篇文章所提的网络是在NASA公开数据集上验证的. 该数据集被广泛用于测试寿命预测算法或模型的有效性. 本文所选的数据是一个航空发动机的退化过程的一些数据. 该数据包含4种不同型号的飞机发动机,构成了4个子数据集. 每个子数据集包含27维的数据,其中前3维表示发动机的运行环境,后21维表示发动机上不同传感器的数据记录(记为s1~s21). 本文选取第一种型号的发动机(FD0001)的数据进行验证. 这个数据集给出了训练集和测试集,其中,训练集的数据记录了发动机从刚开始的健康状态一直到最后完全失效时的一些数据,测试集则记录100台发动机完全失效前的一部分数据. 而我们的任务就是如何更加准确地预测测试集中这100台发动机的剩余寿命.
2.2 数据的预处理
虽然训练集与测试集中共记录了21维发动机传感器的数据,但是其中有一部分传感器的方差为0或者极小[20]. 也就是说,这部分数据对于发动机剩余寿命的预测不能起到作用. 因此,本文只选取其中的14维方差较大的传感器的数据作为原始数据的输入.
由于传感器的数据中是带有噪声的,所以如果直接利用这些数据来进行预测的话,势必会使得其特征不易被神经网络学习到. 因此,有必要对原始数据进行降噪处理,本文采用卡尔曼滤波对原始数据进行降噪处理.
接下来就是数据的标准化处理. 数据标准化的处理方法常见的有2种:Max-min和Z-score. 式(6)和式(7)分别表示Max-min和Z-score标准化公式. 本文采取Z-score对每列的数据进行标准化处理.


图4 模型框架Fig.4 Model framework

然后是训练数据RUL标签的处理. 一般的方法是将RUL处理成随时间的变化而线性衰减的.对于RUL标签的设置,许多学者进行了大量的实验,他们最后得到的结论是:对于一个系统的初期来说,其健康状况良好,不太容易从初期的数据来判断其剩余寿命. 因此,他们认为,假设RUL在初期的一段时间内是不变的,而后开始线性衰退,这样可以使得准确度有所上升[16-17]. 而对系统初期的RUL常数的确定,不同的学者也有不同的结论.本文也采用分段线性RUL,并设置130作为初期RUL的定值,如图5所示.
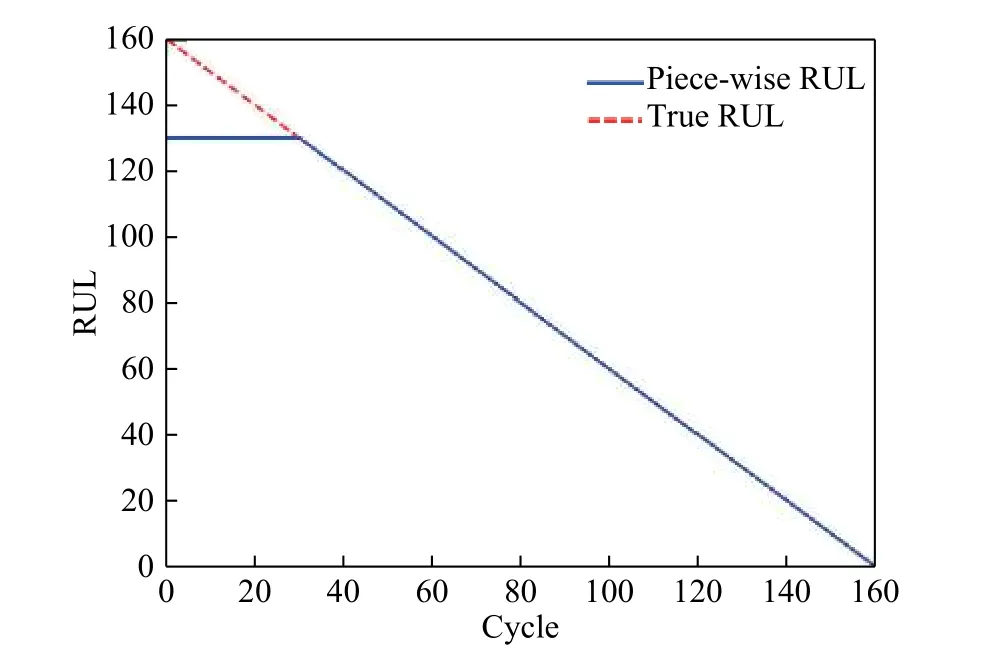
图5 不同的RUL标签对比Fig.5 Comparison of different RUL labels
接下来就是时间窗口大小的选择. 时间窗口的选择是很有必要的,因为我们对测试集中发动机的RUL的预测就是基于不同时间长度的传感器的数据. 选择一个合适大小的时间窗口,这将有利于我们更好地预测RUL. 而且训练集也是基于一定大小的时间窗口来对其进行拆分,拆分成许多长度为时间窗口大小的重叠序列来进行训练. 比如,时间窗口大小为30,发动机的总生命周期是100,那么1~30个周期组成第一组序列,2~31个周期组成第二个序列······,71~100个周期组成最后一个序列,这样总共组成71个训练序列. 然后以每个训练序列作为输入,输出则是每个训练序列的最后一个周期的RUL. 这样使得当我们需要预测某个时间节点的发动机的剩余寿命的时候,我们仅需要一个长度为时间窗口大小的数据. 但是,如果时间窗口太小,则表现在时间序列上的特征就不是很明显,如果时间窗口太大,则训练的样本数量会大大减少. 因此,选择一个合适的时间窗口大小对剩余寿命的预测是十分重要的.
预处理前后的数据如图6所示.
2.3 网络模型参数设置
本文采用集成一维CNN与双向LSTM结合的神经网络模型. 常见的集成学习方式有bagging,boosting,stacking,其中boosting, stacking方式常用于串行学习器,即学习器之间存在着强依赖关系.鉴于本文学习器之间不存在强依赖关系,所以采用bagging生成多组数据的并行集成方式. Bagging是通过对训练集随机采样来让不同学习器的训练样本产生差异性,从而降低模型方差,达到提高模型预测效果. 本文首先通过bagging的方式生成多组数据对,然后用基学习器对这些数据组的学习分别得到各自的预测结果,最后通过求这些结果平均值来得到RUL.

图6 预处理前后的传感器数据. (a,c)s12传感器;(b,d) s2传感器Fig.6 Sensor data before and after preprocessing: (a,c) Sensor 12; (b,d) Sensor 2
因为本数据选取的时间序列窗口大小最终为30,所以第一个卷积核的长度设置最大为30,最小为1,本文设置为10. 其中,在第一个卷积层,卷积核的数目是8,卷积神经网络中的卷积核数目一般以2倍增加,即第二层为16,第三层为32,以此类推. 为了保证训练的稳定性,CNN层的卷积核长度逐步减少. 另外,所有卷积核的滑动步长均设置为1. 对于卷积层数目的设置,训练前初始化卷积层的权重呈均值为0,标准差为0.1的正态分布. 训练过程中卷积层的权值不断变化,因此可以查看训练后权值的变化情况来判断所需卷积层的数目. 图7为4个卷积层训练100次后的各卷积层权值分布图,图8为不同卷积层数目对RMSE(Root-meansquare error)的影响. 可以看到第4层的权值分布接近于原始的正态分布,并且训练误差不再减少,说明该层对于训练模型的准确度贡献不高,因此设置卷积层的数目为3. 所有卷积层的激活函数均采用“Relu”函数. CNN中的池化操作一方面降低了数据特征图的分辨率,简化了计算,但另一方面在一定程度上也使得原始数据的信息量减少. 鉴于本文所使用的数据量不是特别大,本文在所提的网络结构中不使用池化层.
为了使双向LSTM更好地回归预测,一般采用增加层数或增加每层神经元个数. 因为本文的训练样本与维数不是很大,所以采取固定的单层双向LSTM,神经元数目最终确定为128. 将一维CNN提取到的抽象特征进行处理来做回归预测.为了防止过拟合的产生,在双向LSTM层后接一个Dropout函数,并设置其参数为0.5. 该函数会随机地使一部分神经元无效,从而在一定程度上防止过拟合的产生.
最后的输出层是一个神经元,其激活函数是“Relu”函数,用来输出设备的RUL预测值. 基学习器的网络结构如表1所示. 本模型采用RMSProp优化算法来训练该模型,学习率设为0.001. 代价函数选择为“MSE”函数,并设置训练批次大小为256. 其中,激活函数、训练批次大小以及学习率值的设置,均采用测试效果较好时的参数,其他参数均采用默认设置. 网络结构的具体参数设置需根据不同的数据集的特点来进行调整.
3 实验结果
3.1 实验评价指标
对于本数据集,常见的评价指标有2个:Score和RMSE. 式(8)和式(9)分别表示Score和RMSE的计算方式. 其中,di表示预测RUL与真实RUL的偏差.
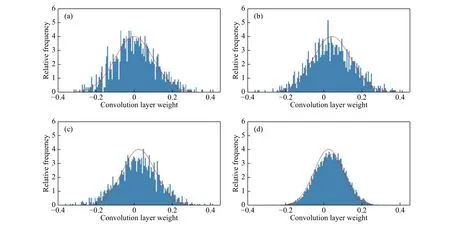
图7 卷积层权值分布. (a)第1个卷积层;(b)第2个卷积层;(c)第3个卷积层;(d)第4个卷积层Fig.7 Convolutional layer weight distribution: (a) the first convolutional layer; (b) the second convolutional layer; (c) the third convolutional layer;(d) the fourth convolutional layer

图8 卷积层数目对RMSE的影响Fig.8 Effect of the number of convolution layers on the rootmean-square error
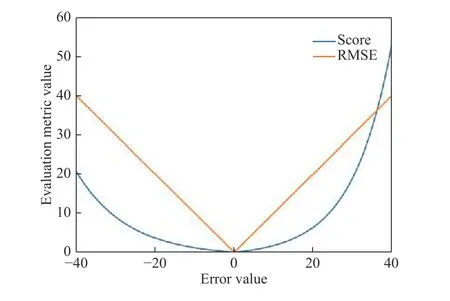
图9 不同评价函数的对比Fig.9 Comparison of different evaluation functions

表1 基学习器网络层次表Table 1 Network hierarchy table of the base learner
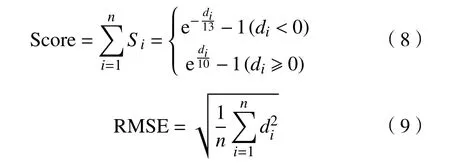
Score评价函数对提前预测RUL的真实值比滞后预测RUL的惩罚程度要小. 这是因为在实际中,相比于滞后预测,我们宁愿提前预测以便及早地发现问题以及采取措施. 而RMSE对提前或者滞后的RUL预测具有相同的惩罚. 这2个评价函数对于关于预测误差的函数图像如图9所示.
3.2 实验结果与评价
表2中编号1到8为其他文献中相同数据集的结果,编号9和10是本文所做实验结果. 从表中数据可以看出,本文所提的集成CNN+BD-LSTM模型在评价指标RMSE和Score上均优于其他机器学习和深度学习的方法与模型. 9和10对比,说明了基于CNN+BD-LSTM的集成模型是有利于准确度的提升的. 本文所提的集成CNN+BD-LSTM进一步提高了RUL的预测精度,这主要得益于集成CNN+BD-LSTM有效地利用一维CNN强大的提取特征的能力,并利用BD-LSTM学习历史与未来数据的依赖关系.
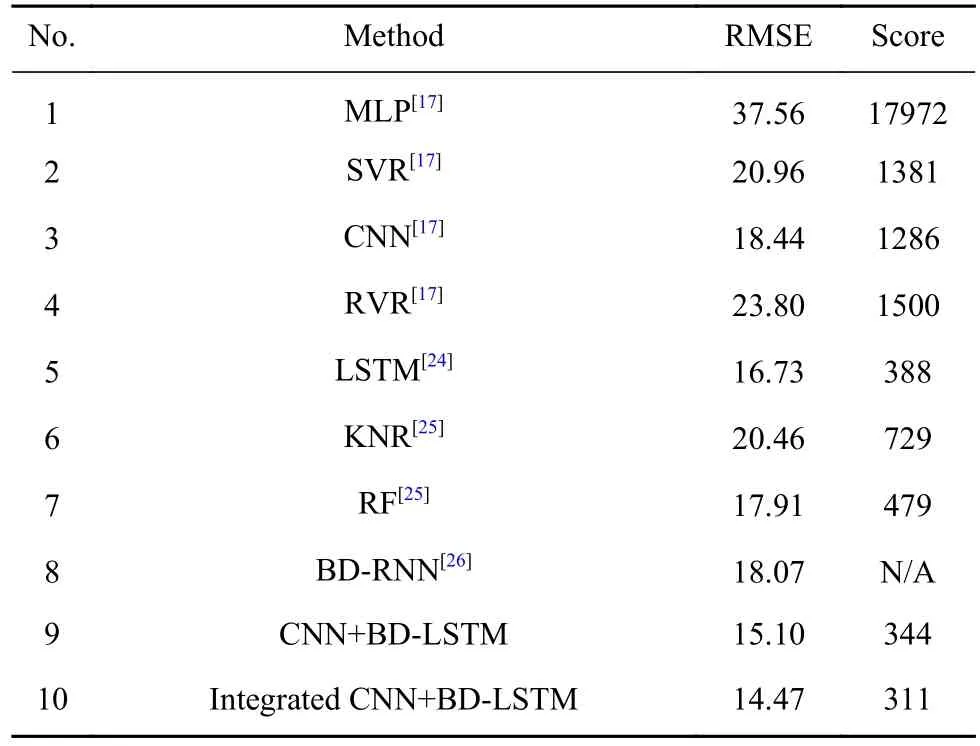
表 2 各种方法结果的对比Table 2 Comparison of the results of various methods
训练集中取1%的样本作为验证集,训练过程中的MSE如图10所示. 基于已经构造好的卷积层外,本文还分析了BD-LSTM层数的神经元的个数对于模型评价指标的影响,如图11所示.

图10 训练过程的loss变化Fig.10 Loss changes during the training process
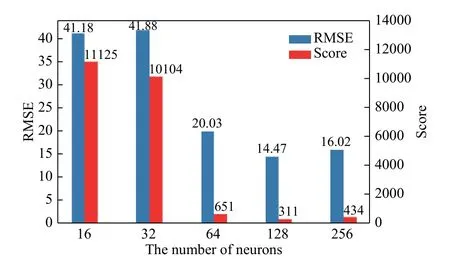
图11 神经元个数对评价指标的影响Fig.11 Influence of the number of neurons on the evaluation metric
从图中可以看到,当神经元个数较少(16~32)时,其评价指标较大,这可能是因为其拟合能力不足. 而当神经元数目达到256时,相比于数目为128,运算时间增加,准确率也没有提升,这可能是由于过拟合的原因. 这说明了选择合适的神经元数目对模型尤为重要.
在已建立的CNN的基础上,时间窗口大小对评价指标的影响如图12所示.
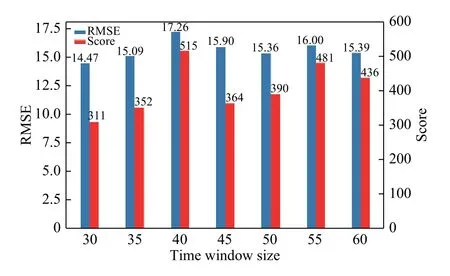
图12 时间窗口大小对评价指标的影响Fig.12 Influence of the time window size on the evaluation metric
从图中可以看出,相比于神经元个数,时间窗口大小对评价指标的影响不是很大. 测试集100个样本的真实RUL与用本模型预测的RUL如图13所示.

图13 测试集真实RUL与预测RUL的对比Fig.13 Comparison of real and predicted RUL in the test set
4 结论
(1)本文提出了集成一维CNN和BD-LSTM相结合的神经网络模型来进行RUL预测. 其中,一维CNN用于提取时间序列的特征,BD-LSTM用来回归预测,并采用bagging的方式对该网络进行集成. 模型在NASA的数据集上进行验证,评价指标均优于其他机器学习或深度学习的模型,验证了一维CNN提取特征和集成算法模型的有效性.
(2)更加准确的RUL预测将为设备或部件制定相应的维护策略提供重要而有效的信息,同时也使得设备的故障诊断与健康管理更加方便和经济.
