基于EMD-ELM 模型的农产品价格预测研究
2020-11-03刘合兵韩晶晶马新明
刘合兵 韩晶晶 马新明 席 磊*
(1.河南农业大学信息与管理科学学院,郑州 450002;2.农田监测与控制河南省工程实验室,郑州 450002)
1 引言
维持农产品价格的稳定,对于保障国计民生具有重要的现实意义。农产品价格的剧烈波动会对农产品市场带来不利的影响。对于这一问题,政府部门曾多次在“中央一号文件”及政府的报告中提及应该加强农产品市场的监测管理,建立健全农产品市场调控制度。在一个成熟的农产品市场中,所有的市场参与者都没有操控市场的能力,农产品价格是市场自由交易的产物。农产品价格的预测属于时间序列预测的范畴,同时农产品又兼具高度易腐的特殊性,必须满足供需平衡,这使得农产品价格的预测又不同于一般商品的价格预测。现实中,气候变化、经济波动、特殊节假日等诸多外生因素都会对农产品价格产生影响,从而使得农产品价格表现出高度的随机波动性。这也就使得高准确率的农产品价格预测颇具挑战性。通过对农产品的未来价格进行短期预测,可以为相关从业人员提供前瞻性信息,生产者可以及时调整生产方案,经营者可以及时调整销售思路,提高市场风险规避能力,减少异常波动带来的损失。价格预测也可以为相关政府部门出台稳定农产品市场供需和价格相关政策提供决策参考,也为消费者进行日常饮食消费选择提供参考。
农产品的生产过程受到气候的限制和影响,农产品价格主要受市场供需影响,所以农产品价格序列表现出季节性,趋势性及随机波动性,呈现典型的非线性特征。国内外对于价格的预测方法主要分为4 种:计量经济预测法、数理统计预测法、智能分析法和组合模型法[1]。计量经济学以揭示经济现象中的因果关系为目的,在农产品市场价格预测中,最常用的方法是回归分析法,一般都是根据自变量和因变量的函数关系建立线性或非线性回归模型,然后对相应的农产品价格进行预测[2-3]。但是在对农产品价格进行预测时,影响价格变动的因素较多,我们在预测时并不能一一例举,且个别影响因素并不能量化,这就对价格预测工作带来很多不便。统计预测是统计学的一个重要功能,是预测领域的一个重要方法。在农产品市场价格预测中,应用最广泛的是传统的时间序列预测方法,其主要包括季节指数法[4]、移动平均法[5]、指数平滑法[6]等。以上这些方法在对具有线性特征的时间序列预测时表现较好,但农产品市场随着时间的变化,逐步向复杂化、不规则化发展时,传统的时间序列在对这些价格进行预测时,为模型参数调整带来较大困难,反映出一定的局限性。随着信息技术、智能技术在各领域的广泛应用,农产品价格预测也应用这些新技术进行了有意义的实践。在农产品市场价格预测中应用的智能分析方法主要有神经网络预测法[7-9]、灰色预测法[10]、支持向量机[11]等。智能分析方法具有很强的非线性映射能力和柔性的网络结构,能够使样本预测误差逼近最小。组合模型法是将不同的方法组合起来形成的一种新的预测方法。它有两种基本的形式,一是将不同的预测方法所得的结果进行等权或不等权的组合[12-13];二是在用一种预测方法进行预测前,先通过辅助方法进行处理以使其后面预测方法预测精度更佳的组合[14-15]。这些建立组合预测模型的结果证实比单一预测模型的精度高,随即也成为预测领域的潮流。
极限学习机是Huang 等[16]于2006 年提出的一种机器学习方法,它可以最大限度的提高网络的泛化能力和学习速度,性能优良且具有较强的非线性拟合能力。现如今极限学习机已经在股票价格[17]、网络流量[18]、风速预测[19]等方面得到广泛应用。它虽然可以很好的拟合农产品价格序列的非线性部分,但是价格的非平稳部分会对预测精度产生较大影响。为了降低农产品价格的非平稳性,文章引入经验模态分解,它可以将一个复杂的非平稳性信号分解为不同的具有局部时变特征的信号,从而有效降低序列的非平稳性。因此,文章先用经验模态分解方法对农产品价格序列进行预处理,将处理后的分量作为极限学习机的输入变量分别建立预测模型,并将预测结果进行组合获得最终农产品价格的预测值。本文选取2014 年至2019 年河南省批发市场马铃薯的月均价格进行应用研究,验证EMD-ELM 组合预测模型的可行性和精确性。
2 研究方法
2.1 经验模态分解
经验模态分解(Empirical Mode Decomposition,EMD)是Hilber-Huang 变换中的一种适用于非线性、非平稳时间序列的信号分解方法。它依据信号自身的时间尺度特征对信号进行分解,无需预先设定任何基函数。它可以将原始序列分解为若干个具有不同尺度、平稳性和周期性波动特征的本征模态函数(Intrinsic Mode Function,IMF)和一个剩余分量。其中每个IMF必须满足两个条件:1.在一个完整的时间序列信号上,极值点的个数和过零点的个数相差不大于1;2.在任意时刻点处,局部最大值的包络线和局部最小值的包络线均值为0。
经验模态分解步骤如下:
1.取序列x(t)的所有极大值和极小值。
3.计算x(t)与m1(t)之差,记为h1(t),h1(t)=x(t)-m1(t),如果h1(t)满足IMF 的两个条件,则记为c1(t)=h1(t),c1(t)就是第一个IMF 分量;如果h1(t)不是IMF,则将h1(t)视为新的信号x(t),重复以上步骤直到h1(t)是一个IMF,记为c1(t)。
通过将剩余部分r1(t)=x(t)-c1(t)视为新的信号并重复上述步骤,即可提取其余的IMF和一个余项。原始数据x(t)可表示为本征模态函数与余项之和,即因此,一个时间信号都可分解为n个本征模态函数分量与一个余项之和。
2.2 极限学习机
极限学习机(Extreme Learning Machine,ELM)是一种新型的单隐层前馈神经网络。由于它的结构简单,其初始权重和偏置是随机生成的且不需要迭代调整,在训练过程中只需要设置隐含层神经元的个数即可。极限学习机所得解是唯一最优解,保证了网络泛化能力,还能克服局部最优化的不足且具有学习速度快等优点,在保证较高的精度和预测效果的前提下,其卓越的训练速度为其自身与其他方法结合提供便利,越来越引起各个领域的高度关注和深入研究。
2.3 EMD-ELM组合预测模型设计
现今研究农产品价格预测中,一般都会涉及预测模型各种参数的反复调整问题,因此提出一种EMDELM 组合预测模型,其方法在运用时具有简易快捷的优势。因为EMD-ELM 组合预测模型充分利用了经验模态分解方法可以根据将要预测序列其自身的时间尺度自行分解出各个本征模态函数和一个余项,其本征模态函数的数量是根据原始序列的特征特定产生的,不同的原始序列可能产生的本征模态函数的数量不同。极限学习机解决了传统神经网络需要设置大量网络参数问题,在运用过程中只需要设置好隐含层神经元的个数即可对序列进行学习预测。
EMD-ELM 组合预测模型具体内容如图1 所示,首先利用经验模态分解方法,根据农产品价格其自身的时间尺度进行分解,得出若干个本征模态函数分量和一个余项分量。对分解出的若干个本征模态函数分量和一个余项分量分别运用极限学习机方法进行预测,每个分量根据其自身特性通过设置不同的参数值,得到不同的预测结果。最后将其各个分量的预测结果进行累加组合得到最终的农产品价格预测值。
3 EMD-ELM组合预测模型应用实例
3.1 数据样本选择
农贸市场是城乡居民对农副产品进行交易买卖的固定地点市场,本研究所采用的实验数据来源于河南省农产品信息监测系统(http://ncpprice.agridoor.com.cn/login.asp),考虑样本的可获得性和连续性选择某个农贸市场马铃薯的月均价格数据。作为全球第四大重要的粮食作物,马铃薯是具有发展前景的高产作物之一,同时也是十大热门营养健康食品之一。实验选取72 个连续的月度价格数据样本,数据周期是从2014 年1 月至2019 年12 月。从图2 中可以看出,马铃薯的价格大多时间都在1 元/kg 和3 元/kg 内波动,只有个别月份高于3元/kg,整体来看,其价格具有不稳定、不规则波动特征。实验过程中,选择2014年1 月至2018 年12 月的60 个样本作为训练集,2019年的12 个月的样本作为测试集,对EMD-ELM 组合预测模型进行应用验证。
3.2 评价标准
选择平均绝对误差(MAE)、平均百分比误差(MAPE)与均方根误差(RMSE)三个指标来评估EMD-ELM 组合预测模型的预测效果,计算公式如下:
公式中,n为价格样本数量,y为第i个月的月均价格。
3.3 EMD-ELM组合预测模型应用
从马铃薯的价格走势图中可以看出其序列具有不稳定、非线性的特征,因此可利用经验模态分解方法进行分解,实验过程用Matlab R2014b 软件编程实现,该方法依据马铃薯价格数据信号不断的分离出高频分量,直到所有的频率成分都被分离开,得到了4个本征模态函数分量,然后用原始数据减去各本征模态函数分量得到1个线性趋势余量。分解结果如图3所示,图中第一曲线图为马铃薯的原始序列图,中间4 个为本征模态函数分量图,最后一个为余量图,从图中可以看出,IMF1 和IMF2 分量波动周期较短,波动较为频繁,IMF3 和IMF4 波动较为平缓,且波动周期较长,余量与原价格序列整体趋势一致,反映了价格序列的线性趋势。用极限学习机分别对分解出来的5 个分量进行预测,为了实现较高的预测精度,在预测过程中首先对价格数据进行归一化处理,分解出来的2014年至2018年月均连续价格作为模型的训练集,分解出的2019 年的月均连续价格作为测试集。设置神经网络时用当前6 个月的价格和上一年同月份的价格共7 个数据作为输入层数据进行提前一步的价格预测,其输入输出的构成如图4 所示。在隐含层神经元个数的设定时,考虑到所研究的价格序列的长度,构建了从3 到20 的隐含层节点的模型,对每个极限学习机模型在预测样本上重复训练15 次,然后保存预测结果计算每次的平均绝对误差,选取平均绝对误差最小的预测模型。由于各个分量的波动特征不同,经过实践选取了不同的隐含层节点数值。对输出数据进行反归一化处理,还原为价格数据,最后对各个分量的预测值进行累加组合得到最后的预测值。极限学习机的建模实验由Matlab R2104b 编程实现。
3.4 实验结果分析与对比
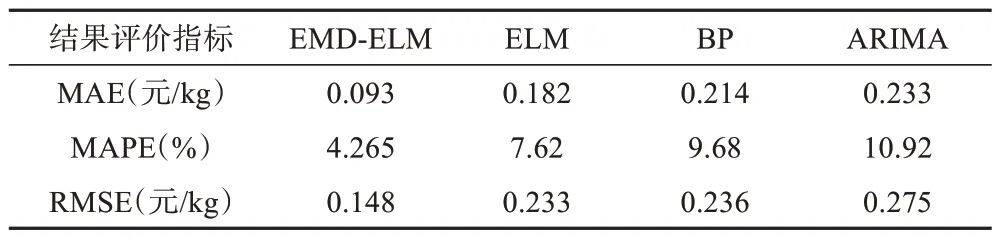
表1 不同模型预测误差比较Table 1 Comparison of prediction errors of different models
为了比较预测性能,分别采用单一的极限学习机、BP神经网络和ARIMA模型对相同的数据集进行建模预测。其中BP神经网络和极限学习机的输入数据集与EMD-ELM 组合预测模型的预测设置一致,同为当前6个月的价格和上一年同月价格共7个数据作为输入数据集。从图5 和表1 可以看出,EMD-ELM组合预测模型的预测精度与单一的极限学习机、BP神经网络和ARIMA 模型的预测结果有了较大的提高,原因在于EMD-ELM 组合预测模型对原始的农产品价格序列用经验模态分解方法进行分解的各个分量,降低了后续预测过程的复杂度。具体从精度评价指标看,EMD-ELM 组合预测模型的MAE 最低,为0.093 元/kg,而单一极限学习机、BP 神经网络和ARIMA 模型的MAE 分别为0.182 元/kg、0.214 元/kg 和0.233 元/kg。且从MAPE 相比较,EMD-ELM 组合预测模型的MAPE最低,为4.265%,单一的极限学习机、BP 神经网络和ARIMA 模型的MAPE 分别为7.62%、9.68%、10.92%。从RMSE相比较,EMD-ELM 组合预测模型的预测结果同样表现最好,RMSE 最低,为0.148,单一极限学习机、BP 神经网络和ARIMA 模型的RMSE分别为0.233、0.236和0.275。
相对于单一极限学习机、BP 神经网络和ARIMA模型,EMD-ELM 组合预测模型有着更为突出的优势。首先,ELM、BP、ARIMA 此类单一模型在进行价格预测时并未对价格数据进行预处理,无法很好的拟合价格的波动频率和波动幅度,因而在最终的价格预测中存在较大的误差。因此,对价格数据进行经验模态分解,分离数据的波动频率,降低数据的波动幅度对于建立良好的预测模型是非常重要的。其次,在对比的3个模型中,ARIMA模型在3个评价指标中表现最差,原因在于ARIMA 模型是典型的数理统计预测模型,对于线性的预测表现较好,而针对具有非线性特征的价格数据会产生较大的误差。极限学习机和BP神经网络是典型的智能预测模型,从结果来看,其预测效果比ARIMA 模型表现好,但不如组合模型。其中可以看出单一的极限学习机预测结果比BP神经网络表现好。由此可以得出在EMD-ELM 组合预测模型中,经验模态分解可以很好的降低原始序列的非平稳性,有利于提高农产品价格的预测精度。
4 结论
针对农产品价格的具体波动形态,采用经验模态分解方法能够有效地分离出原始价格序列中的不同特征分量,有效地降低了各分量的非平稳性。本文提出了一种EMD-ELM 组合预测模型,实验结果表明该方法较之单一极限学习机、BP神经网络和ARIMA模型具有更好的预测能力,为非线性的农产品价格预测提供一种新的思路。通过对农产品的未来价格做出提前预测,这对农产品从业人员及相关政府部门具有重要的现实意义。由于在对EMD-ELM 组合预测模型的应用中仅对马铃薯价格进行了研究,结果表明能够很好的拟合价格的波动特征验证EMD-ELM 组合预测模型的可行性,但并未对其他农产品种类进行应用,后期可以针对此方法进行多个农产品种类的预测。极限学习机的隐含层神经元个数是通过设定区间反复实践调参取最佳值确定的,比较消耗时间,如何快速有效的确定极限学习机隐含层神经元的个数是下一阶段的研究目标。
