一种改进的残差网络的人脸识别方法∗
2020-11-02唐风高伍雪冬
唐风高 伍雪冬
(江苏科技大学电子信息学院 镇江 212000)
1 引言
人脸识别作为非入侵式的生物特征识别方法,在国防安全、视频监控、人机交互等方面具有广泛的应用。虽然在过去几十年中人脸识别研究取得了较大成果,但是随着训练样本的不断增加,传统的基于浅层机器学习人脸识别算法已经满足不了人们的需求。当今时代迫切需要一种新的技术来弥补这一空缺,而深度学习的出现让人脸识别的研究进入了新的时代,也对模式识别、人工智能、计算机视觉等多个领域产生了重要影响[1]。
2 国内外研究现状
针对人脸识别的研究,国外学者提出了许多可行有效的算法。Taigman 等[2]提出了DeepFace 网络,首次应用深度学习来进行人脸识别,使用了3D对齐方法来解决传统2D对齐不能解决的面外旋转(out-of-plane rotations)问题,取得了97.25%的准确率,首次接近了人类肉眼水平,但是网络计算量大,容易陷入过拟合,因此Christian Szegedy等[3]提出了“inception”的深度卷积神经网络结构,该结构优化了网络内部计算资源的利用率,它既能保持稀疏的网络结构,又能有高性能密集矩阵的计算能力,从而极大地避免了人脸训练中容易陷入过拟合的情况;通过引入改进的监督惩罚L2范数,Angshul Ma⁃jumdar 等[4]提出了一种基于类稀疏的监督自编码器算法,有效地提高了人脸识别率;Iacopo Masi等[5]提出了解决人脸大姿态变化的算法,该算法使用多特点姿态模型和渲染人脸图像来解决人脸姿态变化而造成准确度降低的问题;Schroff 等[6]提出了FaceNet 人脸识别算法,该算法使用三元组损失函数来进行网络训练,通过空间的距离代表了人脸图像的相似性的特点直接将人脸图像映射到欧几里得空间,在LFW上取得了99.63%的精度。
国内学者对人脸识别也做了大量研究。张凯鹏等[7]提出一个深度级联的多任务框架(MTCNN),通过级联三个深度卷积网络来对人脸进行检测和对齐,实现了人脸对齐更高的准确度;孙祎等[8]提出DeepID网络结构,与DeepFace不同的是,该网络先对图片进行切分,然后对每一个patch 进行训练最后融合成整体人脸图像的特征向量,在LFW 的准确度为97.45%;温研东等[9]提出Center Loss 损失函数,能够增大类间距离,对新数据有着良好的泛化能力;刘维扬等[10]提出大裕量损失函数(Large-Margin Softmax Loss),可以有效地指导网络学习类内距离较小、类间距离较大的特征,并且能够避免过拟合;刘金托等[11]提出了一种两步学习算法,首先利用multi-path 深度CNN 网络在人脸不同区域进行特征提取,然后利用深度度量学习(Deep Metric Learning)将前一阶段学到的特征向量降到128 维,在LFW 数据集上取得了99.17%的准确率;张亚楠等[12]构造了多分支CNN 来通过patch 策略学习每个裁剪图片的特征,更好地利用了模型中全局和局部特征之间的相互作用。栗科峰等[13]通过提取人脸高维特征应用最大间距准则减小最小二乘估计产生的重建误差,提出了融合深度学习与最大间距准则的人脸识别方法,实现有效的面部识别分类。
近几年,随着深度卷积网络在人脸识别中取得的重大突破,人们热衷于深度神经网络的设计,从最初的Alexnet[14]、VGGnet[15],再到Googlenet,网络层数从当初十几层到二十几层,人脸识别的精确度也越来越高,但是过深的网络不仅会造成梯度爆炸或者消失,而且也会造成训练误差的增大,而ResNet[16]残差神经网络很好地解决了这些问题。这种网络比以前的网络层数更深,网络每层输入通过学习残差函数,而不是学习未知的函数,因此网络的深度虽然增加了,但它仍具有较低的复杂度。但是以传统的Softmax 函数来对样本进行分类,样本的决策面不明显,分类效果不理想,本文提出一种改进的ResNet 残差网络的人脸识别算法,用An⁃gular Softmax(A-Softmax)Loss 来代替传统Softmax Loss损失层,利用A-Softmax具有良好的决策边界,能够最小化类内距离并且最大化类间距离。
3 残差网络基本原理
残差网络(ResNet)的提出是深度网络的一场革命,是何凯明等[16]于ILSVRC(ImageNet Large Scale Visual Recognition Competition)2015上提出并且将神经网络层数提升到152 层,并且证明了它的有效性。ResNet 的出现意味着神经网络模型开始往深度方面发展。
在深度神经网络结构中,假如想以增加网络的深度来提高准确度,那么会出现网络梯度消失或爆炸和准确率下降的问题。针对梯度消失或爆炸问题,采取BatchNorm[17]可以得以缓解;对于准确率退化问题,何凯明等人提出通过残差学习来解决。
一般情况下,构造更深层次的网络模型的措施之一就是对所增加的网络层采用恒等映射(Identi⁃ty Mapping),而对原来的网络层则采用已经学习好的网络模型。这种方法的意义在于加深后的网络模型训练误差应低于其浅层网络模型,但是这种构造方法通常情况下很难找到。因此何凯明等人提出一种深度残差学习框架,应用多层网络拟合一个残差映射解决了准确率退化的难题。如果用H(x)来代表所期望得到的实际映射,即利用堆叠的多层非线性网络来表示映射关系的拟合,那么这个多层网络可以逐渐逼近某个复杂函数的假设可以等价于它可以渐进地逼近残差函数F(x):
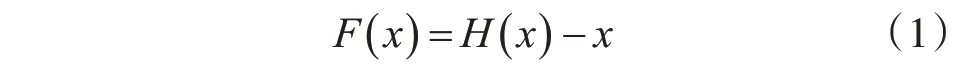
其中x为这些层中第一层的输入,F(x)表示残差函数。那么实际映射关系可以表示为
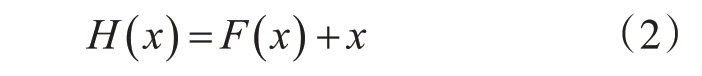
假如目前有一个工作状况很好的网络X,但是现在需要一个比它更深的网络Y,只要将Y的前一部分与X完全相同,只要后面一部分实现一个恒等映射,这样理论上Y的性能与X相当,而且不至于更差。深度残差学习的思想也由此产生,由于Y较X后面不同部分完成的是恒等映射,那就可以在训练网络模型的时候加上这一先验,于是构造网络的时候加入了捷径连接(shortcut connec⁃tions),式(2)可以通过添加捷径连接的前向神经网络实现,即每层的输出不是传统神经网络当中输入的映射,而是映射和输入的叠加,如图1所示。
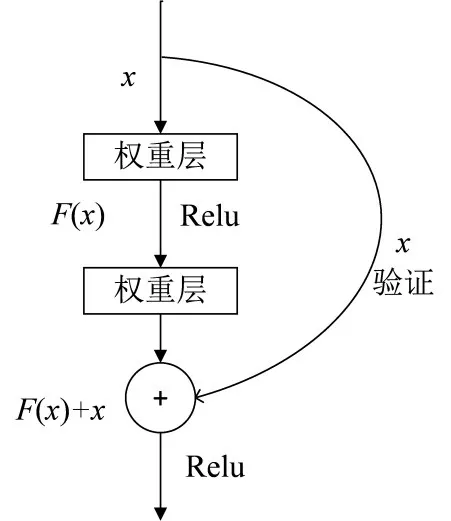
图1 残差网络结构
4 改进的Softmax函数和余弦相似度
4.1 改进的Softmax函数
4.1.1 Softmax函数
卷积神经网络在经过卷积池化等处理会将特征送入全连接层,人们往往会把特征从多维转换成一维,这样不仅能够简便计算,而且还有助于网络的分类。Softmax 就是将多个神经元的输出,映射到( 0,1) 区间内,从而来进行多分类,以二分类的Softmax为例,二分类下的Softmax的后验概率为
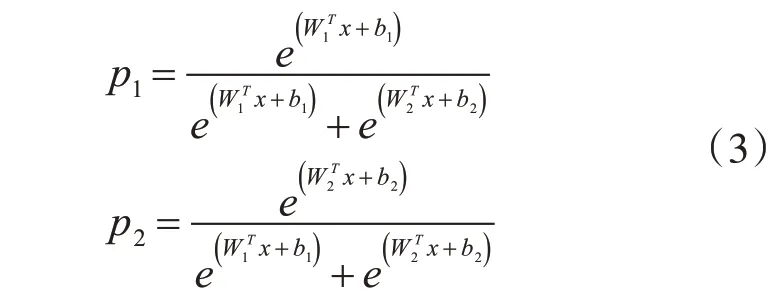
其决策边界是当p1=p2时,所以决策界面是(W1-W2)x+b1-b2,如果p1>p2,则输入数据属于类别1,反之属于类别2。对于输入xi,Softmax Loss可以定义为
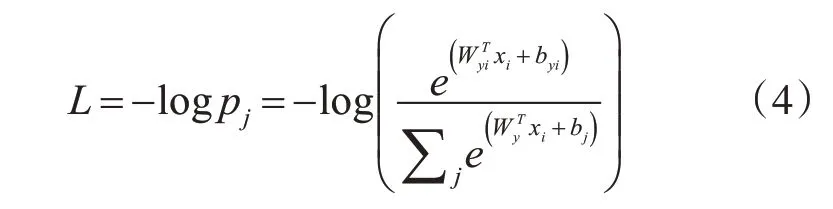
4.1.2 A-Softmax函数
A-Softmax 就是将传统的Softmax 函数引入角度 函 数 , 可 以 把+bi表 示 成cos(θi)+bi,其中θi为Wi与xi的夹角,则二分类下修改后的Softmax后验概率可以表示为

对于输入xi,损失函数为

cos(θyi,i)是样本特征与类中心的余弦值,它的值越大,样本特征与类中心的角度越小,值越小损失函数值越大,即对偏离优化目标的惩罚越大。对于特征xi,该损失函数优化的方向是使得其向该类别yi中心靠近,并且远离其他的类别中心;二分类决策界面为,则它只取决于角度。
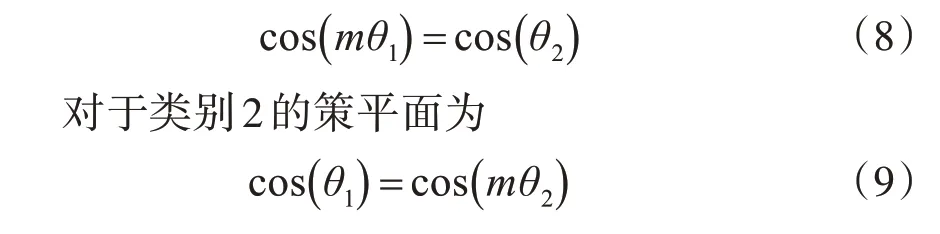
其中m≥2,m∈N。m≥2 表明该决策平面与该分类的最大夹角要比其它类的最小夹角还要小m倍。如果m=1,那么类别1 与类别2 的决策平面是属于同一个平面,如果m≥2,那么类别1 与类别2 则具有两个决策平面。则A-Softmax Loss可以由修改后的损失函数得出:
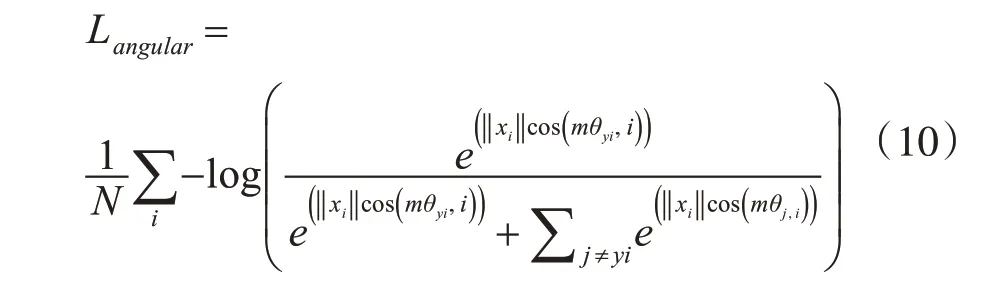

超参m控制着惩罚力度,m越大,惩罚力度越大。
4.2 余弦相似度
余弦相似度度量主要是让特征在特征空间中分布的更加合理,使得相同类别类内距离更小,同时不同类别类间距离更大,这样样本的类别才能够更好地区分。余弦相似度度量方法遵循这样的相似度准则:以特征样本对之间的余弦距离作为相似度准则。两个向量的余弦距离公式定义如式(13)所示:
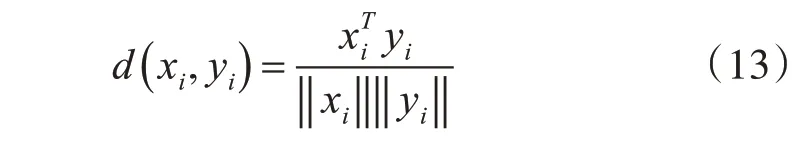
根据Nguyen 等[18]提出的余弦相似度度量学习方法,假设xi和yi的类别标签为li,并且li∈0,1,需要一个空间变换矩阵A,使得在经过空间变换之后的子空间内xi和yi特征向量满足类别标签为li这样的关系。具体的相似度度量公式为
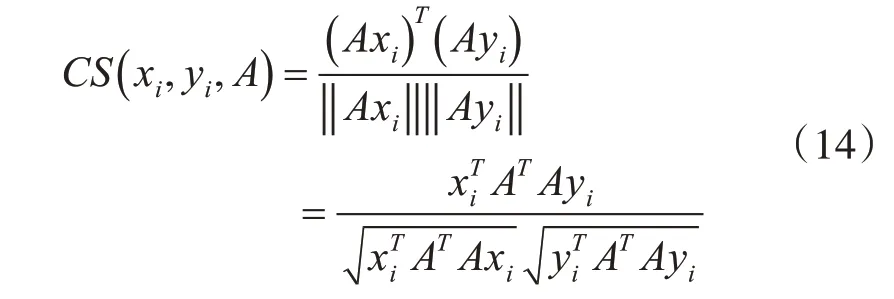
基于式(14),我们需要求得空间变换矩阵A使得样本误差最小化,定义目标函数如式(15)所示:

其中α和β是两个系数,且满足α≥0,β≥0,A0是任意初始化的变换矩阵。
4.3 算法实现流程
该算法首先对人脸图像检测并且对齐,然后将图像进行卷积等处理,在全连接层得到人脸特征,再将图像特征送入到A-Softmax Loss 层根据图像标签计算训练误差,最后得到训练模型;测试阶段首先对测试图像进行特征提取、验证得出准确度,网络模型如表1所示。

表1 网络模型结构表
其中,Conv1.x,Conv2.x,Conv3.x,Conv4.x 表示卷积单元,其包含多个卷积单元和残差单元,[3×3,64]×2 表示卷积层包含2 组具有64 个卷积核大小为3×3的滤波器,S2表示步长为2,FC1为全连接层。
算法流程如图2所示。
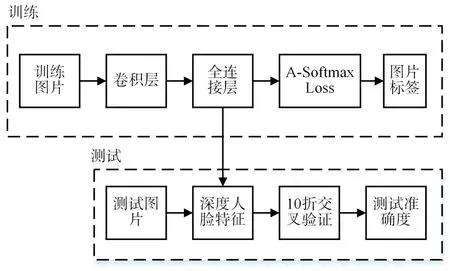
图2 算法流程图
5 实验结果及分析
本文用到CASIA-WebFace 和LFW 人脸库,其中CASIA-WebFace人脸库包含10575个人,每个人的图片数量从几十到几百不等,总共494414 张人脸图像;LFW 人脸库包含5749 个人,总共13233 张人脸图像。首先对CASIA-WebFace和LFW人脸数据库的图像进行检测对齐,得到112×96 的图像,接着将对齐好的CASIA-WebFace 人脸库图像送到改进后的残差网络进行训练直至收敛得到训练模型,然后根据LFW 的view2 协议:测试的人脸图像分为10 组,每组600 人,每组300 组正样例,300 组负样例,总共6000 人,将测试图像送入训练好的模型进行特征提取,归一化,应用10折交叉验证,9组图像作为训练集,1组作为测试集,分别取得9次的测试精度,最后取其平均作为最终的准确度。
本文还在Youtube Face(YTF)数据集进行了测试,Youtube Face(YTF)数据集含有1595 个不同身份下的3425 个视频序列,平均每个人有2.15 个视频,使用不限制额外数据协议来测试,该协议使用了5000 对视频,其中2500 对视频来自同一个人,2500 对视频来自不同人,每对视频都可以计算得到一个相似度,最终的识别率就由这5000 个相似度计算得来。
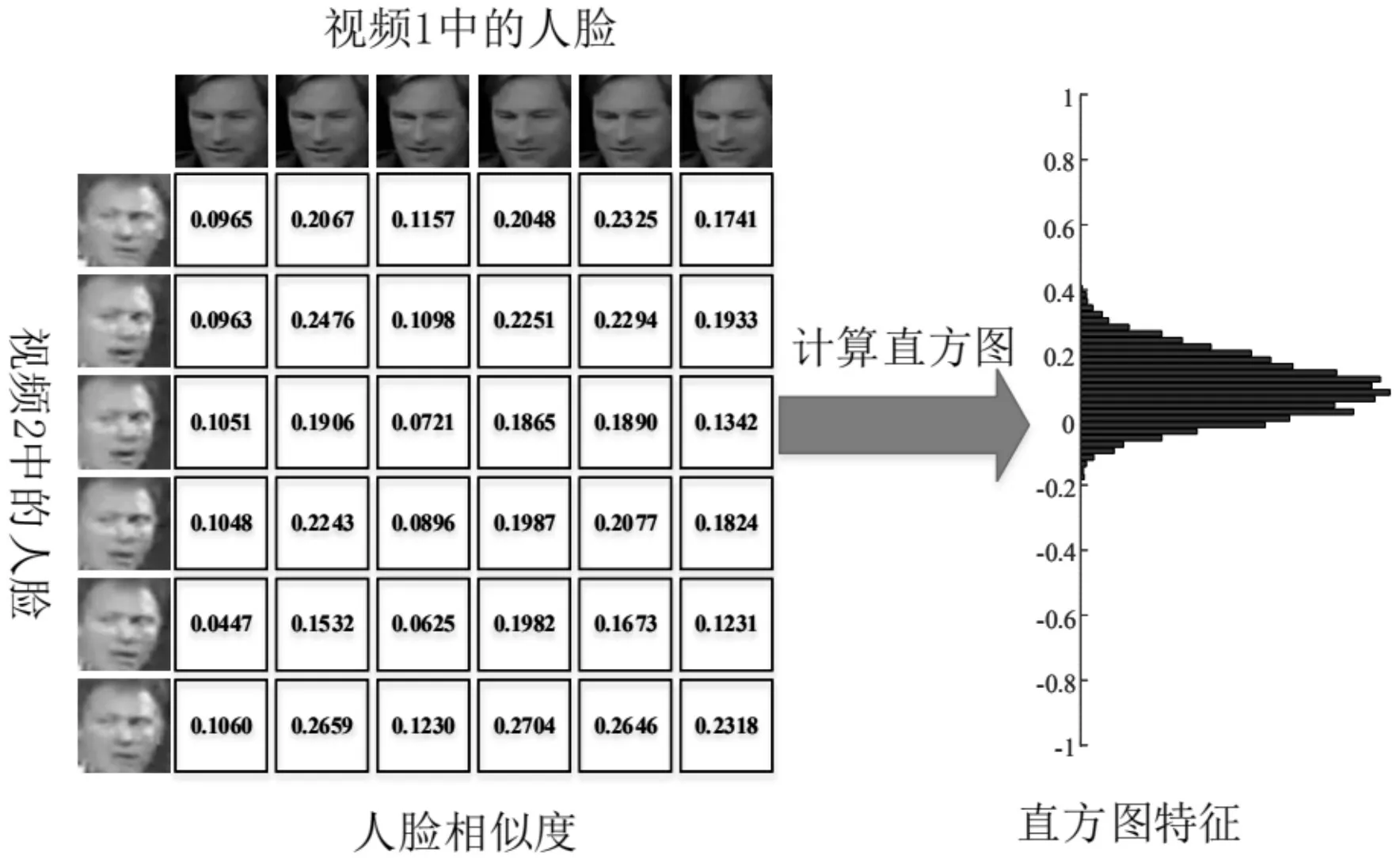
图3 从两组视频中得到相似度直方图特征的示意图
本文算法是在深度学习框架Caffe(Convolu⁃tional Architecture for Fast Feature Embedding)上进行,batchsize 设置为192,基础学习率为0.1,在迭代16000 和24000 次处学习率分别下降10 倍,总共迭代28000次,其训练误差曲线如图4所示。
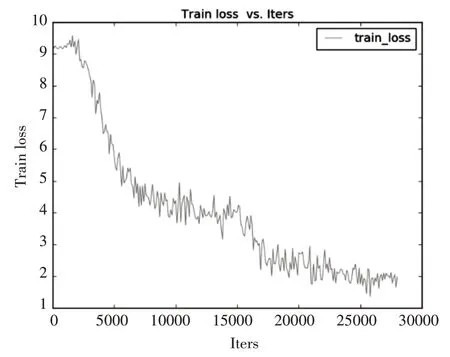
图4 训练误差与迭代次数曲线
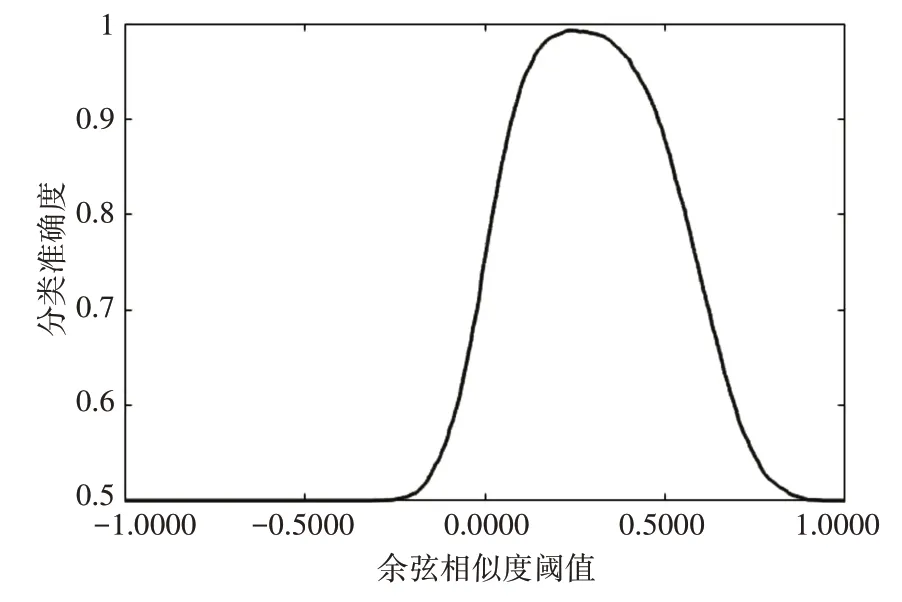
图5 余弦相似度阈值对准确度的影响
本实验应用余弦相似度来表示两张图像的相似度,阈值的选定决定着分类的准确度,在[-1,1]出选定20000 个值,分别来计算准确度,如图5 所示。
由图5 可知,当阈值在0.2365 处分类效果最好;当模型收敛,将测试图像输入到模型进行测试,通过10折交叉验证,其准确率如表2所示。
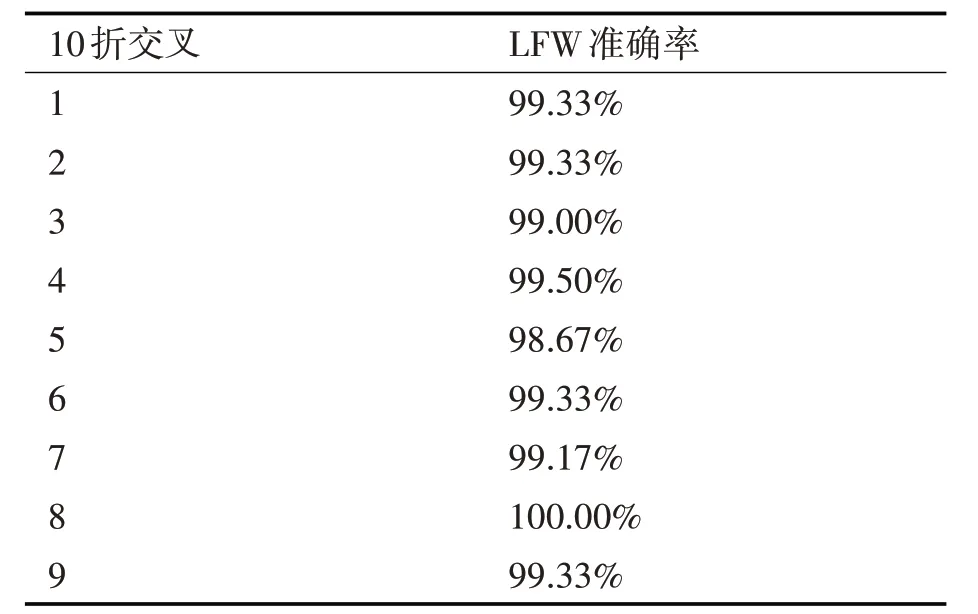
表2 10折交叉验证
最后得出准确率为:99.27%。与文献[2]、[6][8~10]实验结果对比如表3所示。

表3 各算法在LFW的识别率
由表3 可得出:改进的残差网络不但能使网络更深,而且提取的角度特征更具区分性,在LFW 和YTF人脸库上取得了更好的效果。
6 结语
针对普通卷积神经网络会随着网络层数加深而造成训练精度退化,本文提出了一种改进的残差网络人脸识别算法。在残差网络的基础上,利用A-Softmax 具有良好的角度分辨特征解决了Soft⁃max层分类效果不理想的问题,在LFW和YTF人脸库上取得了比较好的效果。超参m虽然能够控制分类决策间隔,但是随着m的增大,模型也变得难以训练,这些方面还需有待进一步深入研究。
