基于改进的PBFT 算法的性能模型研究∗
2020-11-02储劲松鲍可进夏纯中
储劲松 鲍可进 夏纯中
(江苏大学计算机科学与通信工程学院 镇江 212001)
1 引言
比特币[1~2]密码货币[3]的成功使人们对区块链技术越来越感兴趣,通过使用区块链[4]中分布式账本[5]来完成交易可以解决一些现实难以解决的问题。区块链是一个加密的分布式数据库交易系统,所有对等网络节点以分散,可信和安全的方式共享信息。在本论文中,我们使用Hyperledger Fabric[6]的1.0的版本作为实验平台,由IBM、DAH等企业于2015 年底提交到社区,它是一个开源的面向企业的分布式账本平台[7],用于在模块化体系结构中运行智能合约,创新地引入了权限管理支持,支持可插拔、可扩展的共识机制。
在像比特币这样的基于POW 和POS 共识机制的公共区块链网络中,任何人和机构都可以加入该网络,这会导致系统网络遭到Sybil攻击[8]的风险变大。比特币网络解决这个问题的方法是,让同等节点使用工作量证明机制(PoW)的共识方法提出新的交易区块,但是这种共识方法的缺点是会消耗特别大的算力资源。虽然加密货币是一个很吸引人的区块链应用项目,但是令人担忧的是其性能问题,比特币系统每次确认交易时间往往将达到10分钟或更久,而且仅能实现每秒7 个交易[9]的最大吞吐量(即7TPS)。在私有区块链网络中,所有参与者节点都被列入白名单,并受到严格合约义务的约束,在表面上所有节点都表示为安全节点,为了避免受到恶意节点的攻击,需要选择使用更有效的共识协议,如拜占庭容错[10]共识机制(PBFT)。PBFT[11]的工作原理是假设只有不到三分之一的节点出现故障(记故障节点数为f),这意味着网络中应该至少包含n=3f+1 个节点,以容忍f 个恶意节点。因此f=(n-1)/3。使用PBFT 共识机制的网络需要至少2f+1个节点达成一致才能完成新区块的创建,这就保证了生成的新交易区块为正确节点所创建。
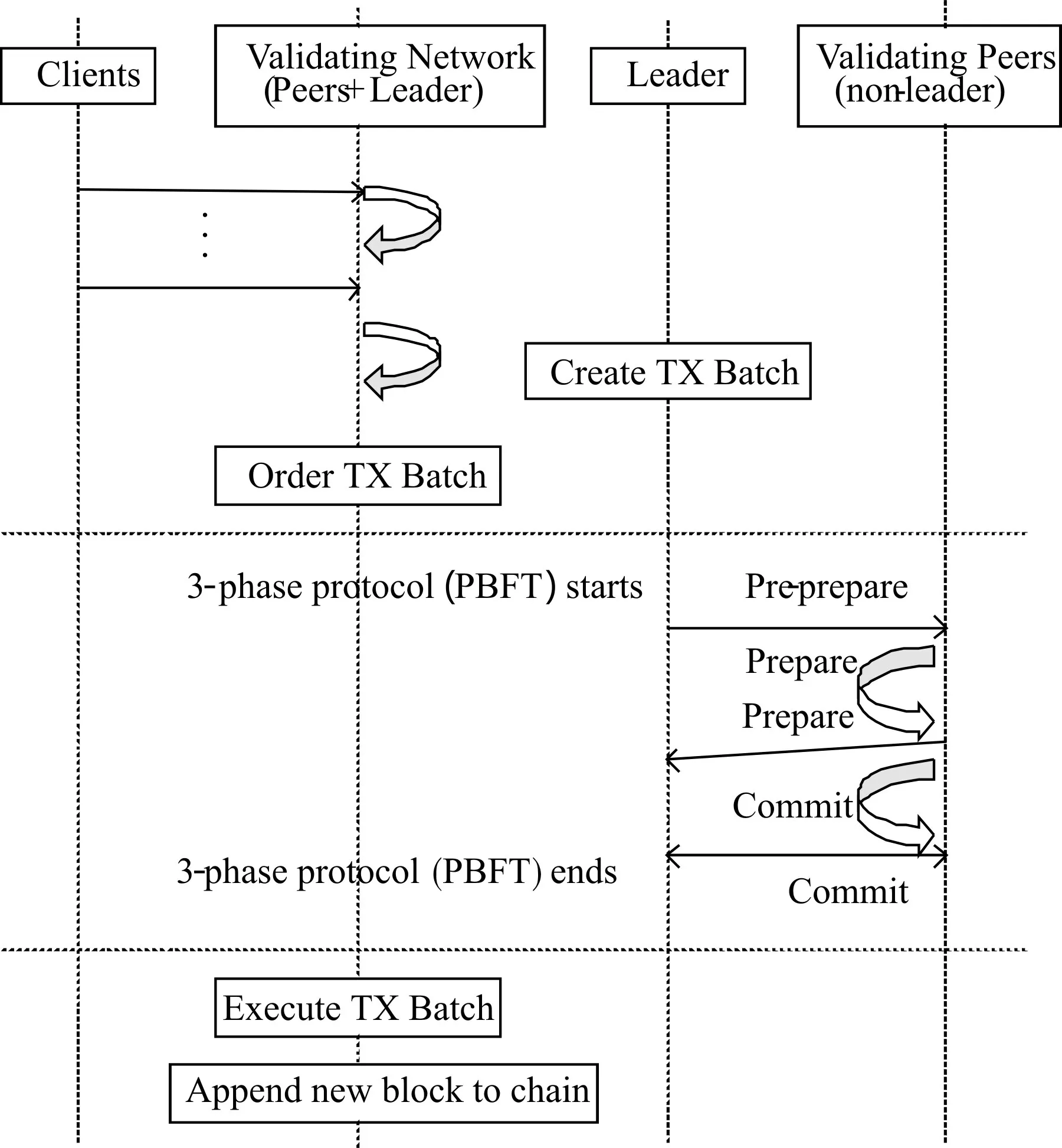
图1 区块链网络交易共识图
图1 显示了一个私有区块链网络的高级视图。每个参与机构都是一个对等节点(VP),在进行共识之前会随机选择一个节点作为领导者(Leader)。进行交易的客户向他们各自所属机构的VP 提出交易请求,VP 确认交易后将其通过广播的形式传播给其他VP。几秒钟后(定义为批处理超时)或交易达到一定数量(定义为批处理大小)之后,Leader 节点创建一个待处理事务的区块,按交易提交的时间对交易进行排序,利用时间戳维护交易秩序。然后它向其他副本节点广播这个可执行的区块,以使用PBFT 获得关于该块的共识结果。如果2f+1 个对等节点同意该区块的创建,则每个VP 执行所有交易并将该块附加为其私人分类账上的下一个区块。每个区块都有一个HASH 地址[12],每一个新区块的地址都是包含前一区块地址的HASH 进行连接而成,形成一个链,从而称为区块链。
2 视图切换协议
PBFT算法在主节点发生故障的时候就需要更换主节点,改变视图,这个协议就称为视图切换协议[13]。PBFT 共识算法机制中详细地介绍了更换视图,改变主节点的过程。整个系统不会在视图切换的过程发生不一致的现象,因此这个过程同样地也需要进行所有节点间的通信。本文采用的视图切换协议,采用对区块链最优区块监听的方式判断主节点是否发生故障,当满足添加区块的条件下,节点没有进行区块的添加则认为主节点发生故障,此时需要进行视图切换。具体算法如下:
算法1 ViewChange()
Input:该节点维护的区块链和交易列表
Output:是否进行视图切换
1:time←CurrentTime
2:Repeat
3: if 交易列表不为空then
4: if BestBlock 的交易信息为空then
5: if CurrentTime-time 大于t then
6: ChangeView
7: else
8: time←BestBlock 的时间戳
9: if CurrentTime-time 大于t then 10:ChangeView
11: else
12: if BestBlock 的交易信息为空then
13: if 下一个区块交易信息为空
14: ViewChange
15: else
16: Thread.Sleep(t)
17: time←CurrentTime
18: else
19: time←BestBlock 的时间戳
20: if CurrentTime-time 大于t then
21: ChangeView
22:Until ViewChange
视图切换的同时会清除证书列表,完成提交交易的操作交由新的主节点进行,并持续地维持系统的稳定运行。上述算法中,在主节点发生故障时,系统会在一定时间内完成视图的切换。这对以普通的分布式系统可能会造成服务中断的问题。而对于基于PBFT 共识算法的联盟链[14]环境,服务并不会停止。其他节点可以将交易存入交易列表中,并由其他节点各自维护的本地数据提供服务。整个视图切换过程在区块链可容忍的延迟的范围,完成主节点的切换,避免了节点间通信,减少了通信的消耗。
3 PBFT共识过程性能模型
本文,针对改进视图切换协议的PBFT算法,利用随机回报网[15](SRN),通过捕捉三个最耗时的步骤对PBFT完成共识一致过程的“平均完成时间”进行建模。这三段时间分别为:对等节点之间消息传输的时间T1(即图中下标为TC 的时间),节点处理传入的一致消息的时间T2(即图中下标DW 的时间),以及为下一个传输阶段准备一致消息的时间T3(即图中下标为RD 的时间)。在这个模型中我们作出以下假设:
1)在生成区块的事务开始之前已经选择了一个主节点,并且在单个块的三阶段共识协议执行过程中,它不会改变;
2)每个副节点的消息处理速率都是一样的;
3)所有对等节点之间的消息传输速率是相同的;
4)在生成单个区块的三阶段共识协议执行过程中,每一个节点在任何时候都不会失败。

图2 四个节点工程过程模型图
在图2 中的四节点的共识过程的性能模型中,使用令牌的形式控制每一个阶段的进行;从主节点已经准备新的信息区块开始到三阶段的共识协议完成,所有节点同意该区块的生成。主节点分别用数字0和其他VP 作分别,其他节点编号分别为1、2和3。该模型直观地显示了PBFT 共识协议的三阶段的每一个步骤,易于跟踪。
对于这个模型有以下约束函数,见表1。

表1 性能模型约束函数表
4 实验分析
实验硬件采用4核8线程的Intel(R)Core(TM)i7-4870HQ 处理器,16 GB 内存的硬件平台。虚拟机8 台,1GB 内存,CPU 共享主机的一个处理器核心,网络连接100Mbit/s LAN。采用50 台虚拟机从4 个节点依次到50 个节点搭建了基于改进PBFT共识机制的区块链网络,这里认为50 台机器的算力是相同的,运行IBM Watson 团队开发的IoT 应用程序。连续运行一周,每小时大约有700 个区块提交,我们从中随机选择50 个区块的日志进行分析。对于这个模型来说,在指定的地方存放令牌的总时间相当于完成创建一个区块的一致性共识的时间。程序运行了接近500 次程序,计算平均时间作为我们的结果,平均时间为4.45ms。由于实验结果中存在异常值,将这个模型估计的平均共识时间与中位数时间进行比较,中位数时间为4.872ms,相对误差约为8.7%,结果具有可比性,模型得到了验证。由于我们的模型检验的是改进PBFT算法的性能,不考虑故障节点的情况即不考虑发生拜占庭容错的情况。
我们对节点数n的生成模型,其中n=4,7,10的故障节点个数分别用f=1,2,3,直到n=49,f =16。我们利用实验验证的参数对模型进行了评估。如图3所示在最多10个网络节点的网络中,我们发现平均共识的时间随着n 的增加而增加,在n=7 时增加的斜率减小。因为每个对等节点在准备阶段和提交阶段都需要2f+1 个一致性消息。在提交验证阶段,n=4 的时候,达成协商一致所需的正确节点的数量是3个,正确节点的比例为75%,到n=7的时候正确节点个数需要5 个,正确节点的比例为71.42%;以此类推最后接近三分二也就是66.667%。但在n=10后,平均共识时间增长的斜率又开始增大。这是由于准备阶段和提交阶段中消息队列延迟随着节点数增加而增加所导致。曲线继续随着n 的增加,略有皱折。最后,n=50 的平均协商时间是n=4的2.14倍。
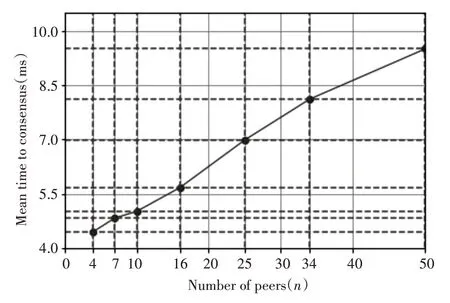
图3 完成共识平均时间结果图
在网络节点设置中,各个节点位于同一机架中。我们考虑一个现实场景,某一节点位于机架中心的区域或者边角区域,发送消息的平均时间要大得多。对网络节点间假设在所有对等节点之间传输消息的平均时间是5.5ms。我们会发现类似的平均时间的走向图,然而,在n=34 的共识时间比n=4的共识时间增长了23%,而此时相对于0.75ms的平均传输消息的时间,平均共识时间增长了134%,但是对于平均延迟更大的网络,这一百分比不会继续增大。因此,如果传输延迟比处理排队消息的时间大一个或两个数量级,平均共识一致的时间不会随着n的增加而显著增加。
由上可知,模型可以根据不同的系统配置和参数来估计性能指标,并对潜在的性能瓶颈提供早期反馈。在正在进行的工作中,我们将在对更多的对等节点以及更广泛更高效的PBFT共识算法的参数和系统配置进行验证。
5 结语
本文针对改进的PBFT 算法进行系统建模,基于IBM 公司的hyperledger composer 平台搭建运行环境,并运行IBM Watson 团队开发的IoT 应用程序测试了改进的PBFT 算法的性能,验证出改进的PBFT 算法能够在至少50 个网络节点的区块链网络中安全有效地进行共识工作;分析其性能影响。后续我们还准备对PBFT 算法进一步的改进,因为三阶段的共识会耗费巨大的网络开销,影响系统的吞吐量,针对这一问题的改进,依然可以尝试利用本文对算法建立性能模型的方式对算法进行进一步的性能测试。然后继续增加网络的节点,对更大规模的网络进行模型测试。
