基于到达时间的行为模式挖掘∗
2020-11-02李克华刘志锋周从华
李克华 刘志锋 周从华
(江苏大学计算机科学与通信工程学院 镇江 212013)
1 引言
随着GPS 定位技术的不断发展与智能移动设备的普及,轨迹数据的获取不再困难。比如通过开启智能收集中的定位服务,可以记录用户的位置,所有这些位置记录组成了该用户的原始轨迹,从这些轨迹中推断出用户的日常行为习惯。针对这一相关应用的需求逐渐增多,在个性化服务中,帮助服务供应商了解用户的生活规律,预测用户的行驶路径,实现商品或路径推荐;或者在推荐系统中,通过用户分享的轨迹数据,发现用户的生活方式、兴趣爱好等,推荐趣味相投的朋友;因此,近年来不少学者开始关注移动用户轨迹模式的研究。
移动用户轨迹模式的挖掘分为两类:基于地理位置的轨迹模式挖掘和基于语义信息的轨迹模式挖掘。前者主要关注的是位置特征,即GPS类型的移动数据,后者主要关注的是语义信息,这类数据有些需要从GPS轨迹中计算得到语义信息,有些则是已经标注好语义的数据;同传统的轨迹挖掘算法相比,语义轨迹行为模式挖掘计算量大大减小,并且能更好地反映用户平常的行为模式与生活习惯。
在语义轨迹模式挖掘技术方面,目前缺乏一种能够处理用户在基于语义点到达时间下的高准确性的轨迹模式挖掘方法。为了解决这一问题,本文提出了一种基于到达时间的语义行为模式挖掘方法。将原始的语义轨迹转化成具有代表性的语义轨迹模式,并根据语义轨迹模式进行用户相似度的度量。该方法的优势在于1)能够提高不同语义行为模式之间的区分度;2)能够发现具有相似生活方式或行为习惯的移动对象群体。
2 相关工作
本节首先介绍了语义轨迹频繁模式挖掘方法,然后概括了现有的语义轨迹相似度度量方法。
Zheng Yu 等提出了将地理轨迹转化为语义轨迹的方法,基于移动对象在某个区域范围内停留的时间来判定停留点,一系列的停留点便形成了语义轨迹[1]。Furtado 等将原始的轨迹序列转换成一系列的子序列片段,然后按照网格轨迹序列的形状相似程度和空间上的远近程度对分段后的子轨迹进行重组,进而通过应用子树结构和技术来找出频繁的路径模式[9]。Huang 等通过定义距离公式,将轨迹进行聚类,轨迹在不同聚类转移的模式即为轨迹的频繁模式,但该方法不适用于语义轨迹[2]。Liu等提出了基于地理位置的语义轨迹频繁模式挖掘方法。该方法采用STP-tree 对语义轨迹的模式按照地点的先后顺序进行索引,每条路径代表一个模式,遍历STP-tree找到所有符合给定频繁阈值的模式即可得到语义轨迹频繁模式[3]。Ying 等将轨迹经过的地点作为轨迹的语义点,并基于这些语义点建立T-pattern Tree,其结构类似STP-Tree,只是T-pattern Tree 的每一条边记录了语义轨迹从一个地点转移到另一个地点所需要的时间,同样的,遍历T-pattern Tree 找到所有符合给定阈值的模式即可得到语义轨迹频繁模式挖掘[4]。上述方法中,只有文献[4]考虑了语义轨迹中的时间因素,但只考虑了语义点之间的转移时间,没有考虑到达时间。
文献[1,5,7]讨论并研究了语义轨迹的相似性。文献将轨迹转换成语义轨迹,然后通过移动对象之间的相似性进行用户推荐,文献[1]依据用户之间轨迹模式的相似性定义用户之间的相似性,文献[5]通过层次树状结构计算相似性。基于地理特征信息的相似性度量方法只能处理轨迹的位置信息,而基于语义信息的相似性度量方法没有考虑到达时间的影响,因此现有的相似性度量方法不能解决基于到达时间的语义轨迹相似性问题。
为了解决上述问题,本文提出了一种基于到达时间的行为模式挖掘方法。
3 问题定义
本节给出语义行为模式相关的定义
定义1语义点语义点S定义为
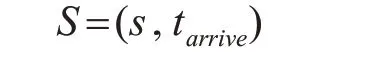
其中,s是用户的停留点,tarrive是用户在语义点S的到达时间。
定义2语义轨迹
语义轨迹是一个由n个语义点组成的序列。

对任意的si和si+1,有ti≤ti+1。语义轨迹长度即为所包含的语义点的数量,记为|ST|=n。所有语义轨迹组成的集合称为语义轨迹集,记为R,轨迹的数量为 |R|。
定义3用户语义行为模式 给定用户语义轨迹集合R和最小支持度sup,用户行为语义模式即从轨迹中挖掘出频繁语义行为模式P=,满足条件:
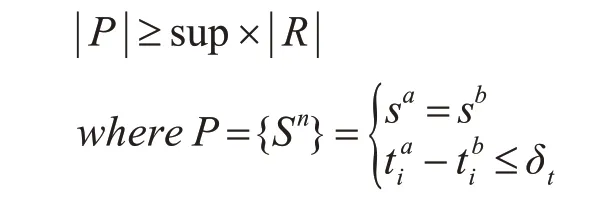
最后,给出本文问题描述:基于到达时间的语义行为模式挖掘是指给定用户语义轨迹集合R,最小支持度sup 和时间阈值δt,依据sup 和δt,从语义轨迹集合中进行用户语义轨迹频繁模式的提取,得到可以反映用户生活习惯的语义行为模式。
4 语义轨迹频繁模式挖掘
本节介绍了用户的语义行为模式挖掘方法。在行为模式挖掘之前,先对原始数据进行语义轨迹的转换,关于地理数据转换为语义轨迹数据的研究较为丰富[8],本节不再详细描述,然后针对每一个用户,挖掘出他的频繁语义模式。这里以在校大学生的数据集为例进行说明。整合大学生的智能卡使用信息以及校园内各个地点的门禁日志可以得到学生的语义轨迹。对每个学生,以天为单位从其个人记录中提取出若干条包含时间的语义轨迹,如表格1所示。

表1 语义轨迹集示例
语义轨迹代表了学生在某一天的时空行为,语义轨迹频繁模式挖掘是从许多语义轨迹中找出行为模式。每个用户的语义轨迹随着用户移动地点及时间的不同呈现多样化形式,但是可以通过行为模式挖掘分析出不同用户的行为习惯。我们基于prefix-span算法的思想来构建频繁模式挖掘算法。
定义4投影数据库 给定语义轨迹集合R,α的投影数据库R(α)=,tuple定义为
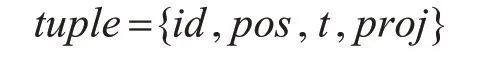
其中,id轨迹在语义轨迹集中的标识号,pos是α中最后的语义点在语义轨迹中的位置,t是最后一个语义点的到达时间,proj是pos以α为前缀的子序列。
算法1:行为模式挖掘算法
输入:语义轨迹集R,时间间隔δt,
最小支持度θ
输出:频繁语义模式FP
1.S1←frequent(R(P))
2.for β in S1do
3. P'←P⊕β
4. R(P)←∅
5. for p in R(P)do
6. S ←R(p.id)
7. for i:i >p.pos Si=β do
8. R(P')←R(P')∪<p.id,i,Si.t,p.proj⊕β >
9. end for
10. end for
11. for p'in R(P')do
12. T ←SET(R(P'),p',δt)
13. if |T |≥θ× |R |th en
14. Pnew←getPattern(P',T)
15. P ←P ∪Pnew
16. end if
17. end for
18.end for
19.return P
算法中函数SET()计算到达时间差额在δt范围内的项目集,假设与p'等价的到达时间范围G,的等价到达时间范围G=[p'.t-δt,p'.t+δt]。
函数getPattern()根据集合T中的平均到达时间构建β的到达时间,最终返回频繁语义行为模式P'=P(β,tβ) 。
在行为模式挖掘算法中,首先找出语义轨迹集中长度为1 的语义符号项集S1,将P与S1中的语义点β进行拓展,并在语义轨迹集合R中构造投影数据库(行1-10),然后递归构建频繁语义行为模式。对每一个项集p',调用函数SET()返回行为模式中与其等价的语义集轨迹合T,经判断,若为频繁模式,调用函数getPattern()构建频繁语义行为模式。
5 语义模式相似度
本节介绍了语义行为模式相似度的度量。研究表明,语义行为模式之间的相似度取决于两个模式之间的公共子序列。当两种行为模式之间的公共子序列越长,我们认为两种行为模式越相似。
MSTP-similarity算法计算的是每个用户最长的语义轨迹模式之间的相似度。语义轨迹的长度越长,它所产生的子序列数目越多。模式的所有子序列都会参与到用户的相似度计算中,为了避免重复计算带来的误差问题该方法只使用最长语义轨迹模式表示用户的频繁行为习惯。计算方式如下:

在上一节中我们已经对用户语义轨迹进行了频繁语义轨迹模式的提取,得到的结果代表了用户的行为模式,无需另选最长语义轨迹。但是原算法在计算行为模式相似度的时候存在一个问题:只基于两个序列的符号的等同性来进行相似性的计算。由于本文的语义行为模式序列中还具有时间信息,这些信息对于计算两个行为模式的相似度具有重要的作用。所以,本节基于原来的MSTP-simi⁃larity 做了改进,使其可以将用户对语义点的到达时间考虑到相似度计算中。首先,给出基于到达时间的最长公共子序列定义:
定义5最长公共子序列给定两个用户语义行为模式P和Q,最长公共子序列满足条件:
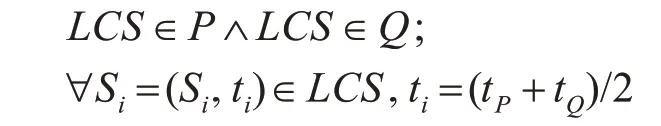
为了突出到达时间对用户语义行为模式的影响,给出了时间因子的定义。
定义6时间因子 给定用户语义行为模式P,Q,当其子序列元素一致时,元素对相似度的贡献值通过时间因子来表达,定义如下:
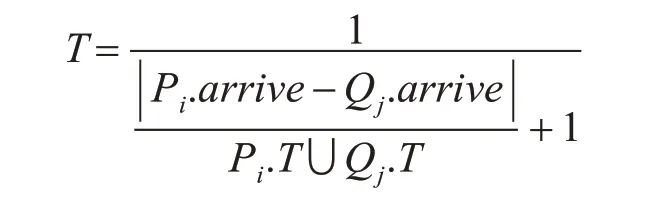
定义7用户行为模式相似度 给定用户语义行为模式P,Q及公共子串,P,Q之间的相似度定义为
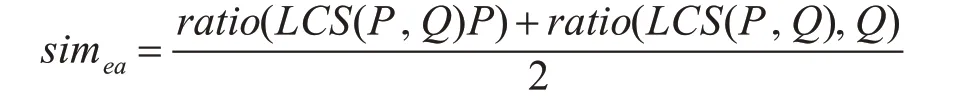
给定语义轨迹模式,当公共子序列越多、时间因子越大时,两个模式越相似。由于寻找公共子序列的过程十分耗时,本文采用动态规划法来寻找。动态规划方法采用二维数组标识中间计算结果,避免了重复计算而提高了效率。相似度计算算法如下。

算法中,我们采用动态规划算法逐步计算了P,Q之间的相似度,矩阵分别存储了P_ratio,Q_ratio以及公共子序列的长度count。首先对矩阵初始化,第一行第一列皆为0;然后依据count变化逐步计算P_ratio,Q_ratio。比如,矩阵的第一个元素count加1,然后P_ratio增加,Q_ratio增加(1/| {dor,lib}|)*T13,通过这种方式,逐步处理得到矩阵中的值。最后,根据定义计算两个用户的相似度。
6 实验结果与分析
6.1 数据集及实验环境
实验数据:某大学经过脱敏处理过后的9475名学生的校园语义轨迹。原始数据集示例如图1。

图1 数据集概览
实验环境:编译软件/python 3.6.0,操作系统/Windows10/CPU/Intel(R)CORE(TM)i5-2450M,主频2.50GHz,内存8G。
6.2 数据预处理
我们以天为单位将学生的“数字足迹”转化为语义轨迹轨迹,处理后的数据详情如表2所示。

表2 预处理后数据
6.3 语义轨迹频繁模式挖掘实验
首先对实验的有效性进行验证,即考虑到达时间后挖掘出的语义轨迹模式是否比没有考虑到达时间时更具有代表性,更能表现用户行为习惯,部分用户语义行为模式挖掘结果如下。

表3 基于到达时间的语义模式
由于考虑了用户在每个语义点的时间因素,挖掘出的行为模式更能体现每个学生的行为习惯,比如学生8和学生37,若不考虑时间约束下的行为模式挖掘,二者的校园语义轨迹近似相同,容易造成二人的生活习惯也类似的错觉,从而不利于后续相似度的计算。但是引入了到达时间之后发现,学生8 的生活习惯倾向于早起去食堂吃早饭并喜欢去图书馆,白天的大部分时间不会在宿舍;而学生37则是基本不吃早饭而且经常到中午才会离开宿舍,二者呈现出的行为模式完全不同。
本节模拟了100 个用户,依据每个用户的行为模式生成了1000 条语义轨迹,20%条随机生成,80%条语义轨迹依据4 中用户行为习惯生成,为了更精确的评估挖掘算法的准确率,定义如下:

其中,ηcorrect是正确的语义行为模式个数,ηall是语义行为模式的个数。参数设置如下:num=100,trj=1000,Lpat=6,Npc=20 。
图2 展示了不同时间阈值、不同支持度得到的行为模式准确度。当频繁模式支持度偏小时,得到的结果在不同时间阈值下没有明显的增加减小,因为支持度过小时,挖掘到的行为模式并非主流结果,不能有效代表一个用户的行为模式。当支持度在0.1以上时,挖掘到的语义模式更具代表性,随着时间阈值的增加,准确率也不断提高。值得注意的是,当时间阈值在40min~50min 以上时,准确率没有改善,还有下降趋势,这是因为随着时间差增大,导致不同模式之间的区分度降低,从而影响了挖掘效果。
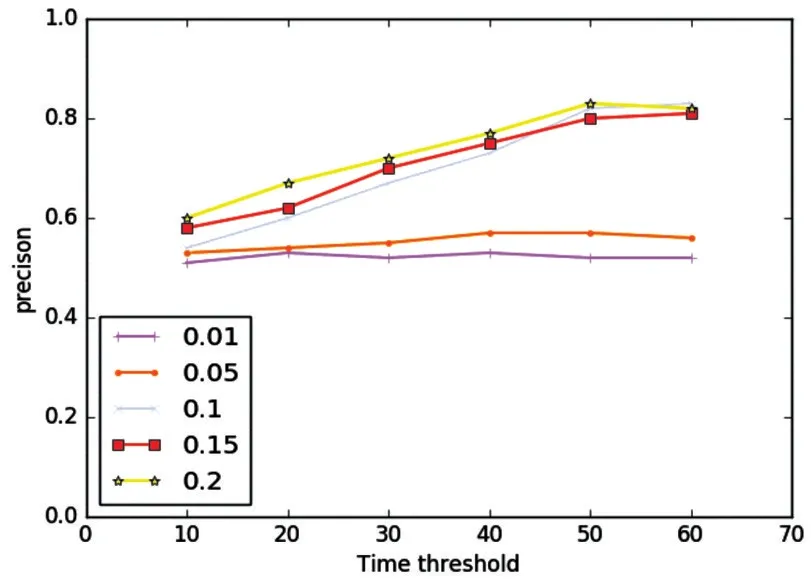
图2 准确性评估
6.4 相似度度量实验
行为模式可以展现用户的生活习惯和行为规律,经济能力相似的用户通常具有类似的行为模式,为了验证这一假设,对基于行为模式的用户相似度度量方法辨别不同背景(经济能力)的用户的效果进行探索。
实验中,首先基于行为模式计算每个学生对的相似度,然后基于学生间相似度矩阵采用k-means算法对所有学生进行聚类。对于每一类学生,在4个聚类中寻找其主导聚类。采用两个指标评价该聚类效果:主导内聚度(Iadr)和主导外聚度(Io⁃dr)。主导内聚度指主导聚类中具有指定助学金人数和主导聚类中总人数的比例,主导外聚度指主导聚类中含有指定助学金的人数和该助学金获得的总人数的比例。另外,为了考察引入到达时间后在本节方法中的效果,基于上述相同的实验设置,在不考虑时间因素的情况下提取行为模式并计算相似度,然后重新进行用户聚类。主导内聚度和主导外聚度相较于未考虑时间因素下得到的结果均显著增大,这说明了基于时间对用户行为模式进行挖掘得到的结果更能反映用户生活习惯相似性。

图3 基于学生相似度的聚类效果
7 结语
针对语义轨迹模式挖掘中没有考虑到达时间的问题,本文提出了基于到达时间的行为模式挖掘方法,首先对包含时间信息的语义轨迹进行频繁模式提取,然后基于挖掘到的频繁模式对用户计算相似度,并在真实数据集上验证了该方法的有效性和正确性。本文提出的方法在路径预测、朋友推荐以及不同用户群体区分等方面具有广泛的应用前景。未来可将其与地理轨迹特征结合起来处理,以达到更好的实用效果。
