一种识别用户实际访问网址的算法设计
2020-10-27王刚翟欣虎秦益飞
王刚 翟欣虎 秦益飞
一.引言
随着互联网技术的飞速发展,使用终端接入运营商服务器并访问互联网网站的用户数量快速增长。通常情况下运营商都需要对所接入用户的上网行为进行审计,而该审计需要准确的识别出用户实际的访问网址。通常情况下记录用户访问的网址最准确的设备是用户使用的终端设备的浏览器,但运营商无法通过简单方法拿到用户使用的终端设备上的数据,所以最实际可行的方法是通过用户接入运营商服务器后,通过服务器所产生的用户访问日志来进行分析。
但实际中,对于用户使用终端设备上的浏览器访问某个互联网网站的某个页面时,浏览器向网站发出的请求的数量远大于用户在浏览器中输入的或者点击某个链接产生的那一条请求。通常情况下用户访问一个网站页面,浏览器会发出几十乃至上百条数量不等的请求给网站服务器,比如用户实际只打开某个新闻页面,而瀏览器实际会额外请求若干张网页上的图片,若干段广告文本,甚至音乐,动画等。对于用户接入的运营商的服务器(网关代理等),服务器会把每一条请求都记录成一条日志,服务器只是处理记录这些请求,其本身是无法区分出用户实际访问的那个链接请求的。表1列出当某个用户访问百度首页时实际产生的部分访问请求。

基于上述情况,运营商在每时每刻产生的海量访问记录面前,对用户上网行为的审计将会产生较大偏差,用户实际访问的网址被掩埋在大多数没有价值的数据中。所以相对准确的识别出用户实际访问的网址将对运营商的用户行为审计产生关键的作用。
从海量访问日志中识别出用户实际访问最常见的是过滤合并方法,该方法将访问日志中的URL字段中包含jpeg、mp3、js、css等关键字的日志过滤掉,将剩下的日志中相邻的且URL字段相同的多条日志合并为一条,最终将这些日志的URL识别为用户实际访问的网址。但是,因为非用户实际访问的网址也就是浏览器根据网页情况自动发送的请求,这些请求中除了一些可以被简单通过关键字过滤掉的以外,还有很大一部分是和用户实际访问的网址从结构来看没有区别,无法区分。这种情况下通过简单过滤合并的结果会多出大量的误报日志,严重影响后续审计的准确性。
二.识别用户实际访问网址的算法设计
(一)识别算法总体流程设计
当一个用户使用浏览器访问某个互联网网站时,该用户每一次访问操作(例如在浏览器地址栏输入网站地址,或者点击了某个网站上的某个链接)都会被为其服务的网络服务运营商(例如中国电信)的网关服务器处理并记录下来,通常情况下每一次访问操作都会包含数量不等的若干条请求,每一个请求都会被至少包含如下字段的日志所记录下来,一个典型的请求日志至少包含如下字段,如表2所示。

通常情况下,网关服务器每时每刻都会收到从不同用户设备发往不同互联网网站的海量请求,网关服务器将这些请求生成的日志发往本发明所述的装置,本识别算法收到这些日志后,按如下流程处理:
步骤1,算法首先需要定期收集由运营商服务器所产生的上述用户访问日志,每次收集的周期不宜太长,例如可以将收集周期定位1分钟。收集的方式没有特定的要求,例如可以通过将日志作为消息逐条发送给本算法,也可以通过将一段时间的若干条日志以文件的方式传送到本算法。
步骤2,将收到的日志按用户标识字段进行分组,即每一组内的日志都包含相同的用户标识。
步骤3,将每一组的日志按访问时间字段的先后顺序重新排序。
步骤4,将已经排好序的每一组日志按相邻两条日志的访问时间的时间间隔的长短进行合并,当一小段时间间隔内存在大于等于设定阈值的日志条数时,则将这些日志归并为该用户一次访问所产生的请求日志,所采用的归并方法可以有多种,例如可以采用无监督聚类方法中的基于层次聚类的ROCK,基于密度聚类的Dbscan,基于神经网络聚类的SOM,基于统计学聚类的COBWeb等,经过分析发现基于密度聚类的DBScan最适合上述场景。
步骤5,对于已经分好的一次访问产生的若干条日志按URL和Referer字段构建多叉树,其中将URL字段的内容作为子节点,Referer字段的内容作为父节点,如此遍历这些日志,将构建出1颗或者多颗多叉树。
步骤6,统计上述1颗或者多颗多叉树的叶子节点的数量,选出其中叶子节点最多的树的根节点作为该用户当时实际访问的网站地址。
如此反复上述步骤,即可识别出用户实际访问的网址。
(二)访问行为时间划分算法设计
DBScan是一种基于密度的无监督聚类算法,可以接受一维或多维待聚类样本数据作为输入源,其基本思想是先计算所有样本两两之间的欧式距离,然后规定在扫描半径 (eps)内存至少存在最小包含点数(minPts)个欧式距离小于eps的样本,则这些样本将被聚为同一类,反之则作为噪声样本。即,包含在圆内的样本聚为同一类,而圆外的样本则当成噪声。
本识别算法在获取到同一用户产生的一小段时间内连续的访问记录,将记录的时间作为DBScan一维样本输入源,通过算法将样本分为若干类,每一类中的记录则作为该用户一次访问所产生的所有请求。根据后续URL识别需要,将时间上两两相邻的类之间可能存在的噪声样本归属到时间靠后的一类中。
(三)实际访问网址识别算法设计
根据HTTP协议规范,当某用户访问的页面发生跳转,或同一个页面中的请求自动请求其他资源,HTTP请求头中的Referer字段将记录下发生跳转前页面或上一级请求的URL。据此,一次访问行为的所有请求可构建成一颗或多颗多叉树。
从构建的一颗或多颗多叉树中,选出叶子节点最多的树,该树的根节点对应的URL可以识别为用户实际访问的网址。
三.识别用户实际访问网址的算法验证
(一)验证数据建立
搭建一个包含60台PC的小型局域网,这60台PC设备由60名普通用户操作进行办公及互联网访问活动,所有PC均接入局域网出口网关,由网关服务器负责处理并记录所有用户的互联网访问请求。
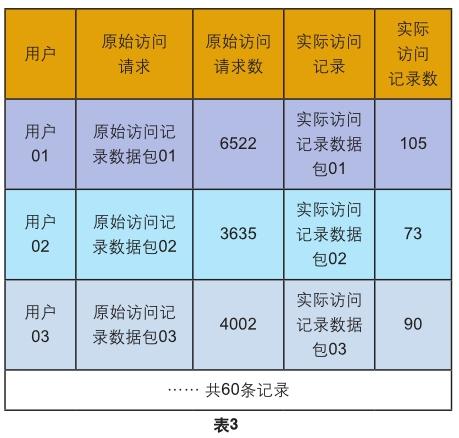
让60名用户在一天内进行任意互联网访问活动,从网关服务器收集一天内所有的原始访问请求记录约50万条作为待检测样本。同时收集该60名用户使用的PC浏览器记录下的当天互联网实际访问记录共约1万条作为标签,同时记录标签和用户的对应关系,如表3。
(二)验证方法及结果分析
从3个指标评估算法的性能:
准确率:正确识别出的网址数 / 实际访问的网址总数
漏报率:( 实际访问的网址总数 - 正确识别出的网址数 ) / 实际访问的网址总数
误报率:( 识别出的网址总数 - 正确识别出的网址数) / 实际访问的网址总数
将使用本文所述算法得出的识别结果作为实验组数据,将使用传统过滤合并法(见引言部分所述)得出的识别结果作为对照组数据,其中针对实验组分别计算上述3个评估指标,而针对对照组只计算误报率这1个评估指标(因为过滤合并法只会去掉明显不可能是实際访问的网址记录,导致该方法的准备率几乎是100%,同理漏报率几乎是0%,所以对过滤合并法计算准确率和漏报率不具备统计学意义)。验证结果如表4.
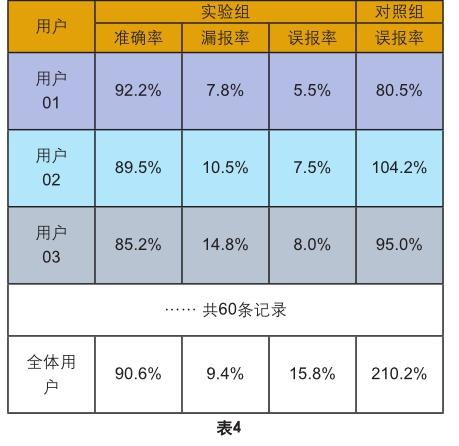
结果表明,传统过滤合并法只是简单的将所有原始记录中明显可排除的记录去除,除此以外并无法区分实际访问的记录和非实际访问的记录,所以其识别的结果会产生非常高的误报率,甚至可以达到实际访问网址数量的数倍乃至数十倍,故在这种情况下即使是100%的准确率也并不具备实用价值。而本文所述算法得出结果的准确率和误报率两者相对平衡,相比传统方法更具备实用价值。
四.结束语
上述针对用户实际访问网址的识别算法,采用了传统数理统计以及无监督机器学习相结合的思路,从时间和内容两个维度预测识别实际访问的网址,相比于传统简单过滤合并的方法大幅降低了误报率,更加具备实用价值。
作者单位:江苏易安联网络技术有限公司
