微表情特征画像在公安人像识别系统中的应用研究
2020-10-27王扶尧郑坤泉
王扶尧, 郑坤泉
( 1.中国刑事警察学院视频侦查系, 辽宁沈阳 110854; 2.漳州市公安局巡特警支队, 福建漳州 363000)
0 引言
在当今大数据时代,视频摄像头遍布城市街道各个角落,这种先进的科技手段,让犯罪无处遁形。而传统的刑侦模拟画像,只能作为在没有视频、照片、面部遮挡等情况下的辅助破案手段。但这并不意味着模拟画像这门古老的传统刑侦技艺过时或被淘汰,尽管科技手段在不断地发展和完善,但制约案件侦破的诸多不利因素依然存在。
比如有硬件的因素,视频监控的像素太低、分布不均匀、出现死角、盲区等;有天气的因素,如雷雨天气、雾霾天气等。尽管现在已经有了模糊图像处理的相关软件,但还无法确保所有的模糊图像都能处理清晰。同时,由于犯罪分子具有越来越强的反侦察能力,如戴帽子、口罩、面具等对面部进行遮挡或事先破坏摄像头等,都会给案件的侦破带来极大的困扰。另外,我国幅员广阔,无论人口和土地面积,和城市比起来,农村都占有绝对大的比例。不可能每个村镇都安有足够多的摄像头。所以,在这些情况下,模拟画像就成为案件侦破中不可或缺的技术手段。
如1988年至2002年甘肃白银大案,14年间连续杀害11名女性。由于当时并没有像今日这样,视频探头遍布街道角落,最终还是由公安部特邀刑侦画像专家张欣(已故),仅凭一张人像素描模拟画像将隐匿了28年的犯罪嫌疑人被指认出来。还有1996年沈阳的3.8大案,也是通过一幅刑侦画像(中国刑警学院赵成文教授的合成人像),将其抓捕归案。
本文在人像刑侦模拟画像的基础上融入人物表情及面部特征,可使疑犯画像不再是传统的呆板的一幅素描头像,画像将更加具有辨识度。同时,再利用当前前沿人像生物识别技术原理及算法,将微表情特征画像导入软件中,进行人像识别比对。
1 理论依据
人类对人像的研究从未停歇,从我国春秋时期的《左传》,汉代的《汉书·艺文志·相人》中便有关于相面的记载,再到国外的查尔斯·贝尔表情的剖析与哲学、达奇恩博士人像的机制研究、达尔文对人类和动物的表情研究等,直到今天人们开始利用计算机对人像识别生物工程递进式研究,都在潜移默化的证明着人像的重要性、不可替代性。当前大数据、5G、智慧城市等前沿技术的兴起,使得安全领域的专家及公安机关开启了对计算机人脸识别技术的应用研究,它如同指纹、虹膜一样,具有特定性的生物特征。
目前,计算机对人像面部的识别和分析主要从两个方面进行,一是固定的面部特征分析。基于人像面部整体的研究进行计算识别的方法,主要包括Eigenface方法、SVD分解法、局部二进制编码直方图、隐马尔可夫模型(Hidden Markov Model,HMM)方法及神经网络方法等;二是对运动的面部特征进行分析。将人像基准点的相对比率和其他描述人像面部特征的形状参数或类别参数等一起构成识别特征向量[1]。
目前我国从事刑侦画像专家人员极度稀缺,全国从事刑侦画像的警员已不足30人。因此,模拟画像人才培养迫在眉睫。
2 微表情画像是传统刑侦画像的延伸
2.1 融入微表情特征的刑侦模拟画像
除手绘外,刑侦模拟画像通常使用的软件有PHOTOSHOP和PAINTER两种,由于PHOTOSHOP对图像修改十分方便,因此画像专家会直接选择在PHOTOSHOP中画像。在画像时,根据公安机关提供的视频资料,从中选择关键帧画面后,截取疑犯面部进行放大并导入PHOTOSHOP中。此时画面呈现的是一幅模糊或者呆板的疑犯面部。经过模拟画像专家的精心修改,可以使犯罪嫌疑人的面部一点点清晰起来。但是,仅仅有一个清晰的面部还不能完全接近犯罪嫌疑人的本来相貌,这就需要在画像中融入人物的微表情特征,使刑侦模拟画像更接近犯罪分子的本来面目。
在人们的日常生活中,表情无处不在。不但人们在面对面时可以看到和感受到,即便在虚拟世界中,如微博、QQ、微信等,人们也常常在使用表情。
微表情画像就是如此,它是传统模拟画像的拓展和延伸,通过目击者对犯罪嫌疑人的描述和公安机关提供的模糊不清的录像资料,将微表情这个重要元素融入到数字模拟画像中去,使犯罪嫌疑人的画像更接近其本人。
2.2 人像微表情的生物特征
人是由猿进化而来的,人的表情有其生物根源。正如英国生物学家达尔文在《人类和动物的表情》一书中所指出的那样,人类的表情和姿势是人类祖先表情动作的遗迹。所以,人的许多最基本情绪,如:喜、怒、哀、乐等原始表情是具有全人类的共性[6]。
笔者找到一名实验对象,通过聊天并对其面部进行采录,后期通过暂停采集到了实验对象(图1)的4组照片共20张不同的表情。由此可见被实验者的表情十分丰富,甚至可以感受到被实验者对话题的喜爱以及憎恶。如果将这种表情画成模拟画像,将会更加接近人物的犯罪瞬间心理感受,为案件侦破提供更多有价值的信息,如图1所示。

图1 表情示意图
现代科学技术以惊人的速度发展,尤其是机器人,已经在很多领域取代了人的工作,但是一个难以突破的瓶颈就是人的表情。现代医学研究表明,人体肌肉有639块,面部肌肉有43块。然而,就是这43块面部肌肉,便可以组合成10 000多种不同的表情,其中表达情感的有3 000余种。
医学研究告诉我们,人的面部表情肌可分为5个部分:口、鼻、眶、耳、颅顶。比如口,口的周围肌群分为上下两组,上组分为笑肌、颧肌、上唇方肌、尖牙肌4种;下组分为三角肌、下唇方肌、颏肌 、口轮匝肌 、颊肌5种。所以,我们说的人的面部肌肉之复杂,仅从口周围肌群便可略见一斑,如图2所示。
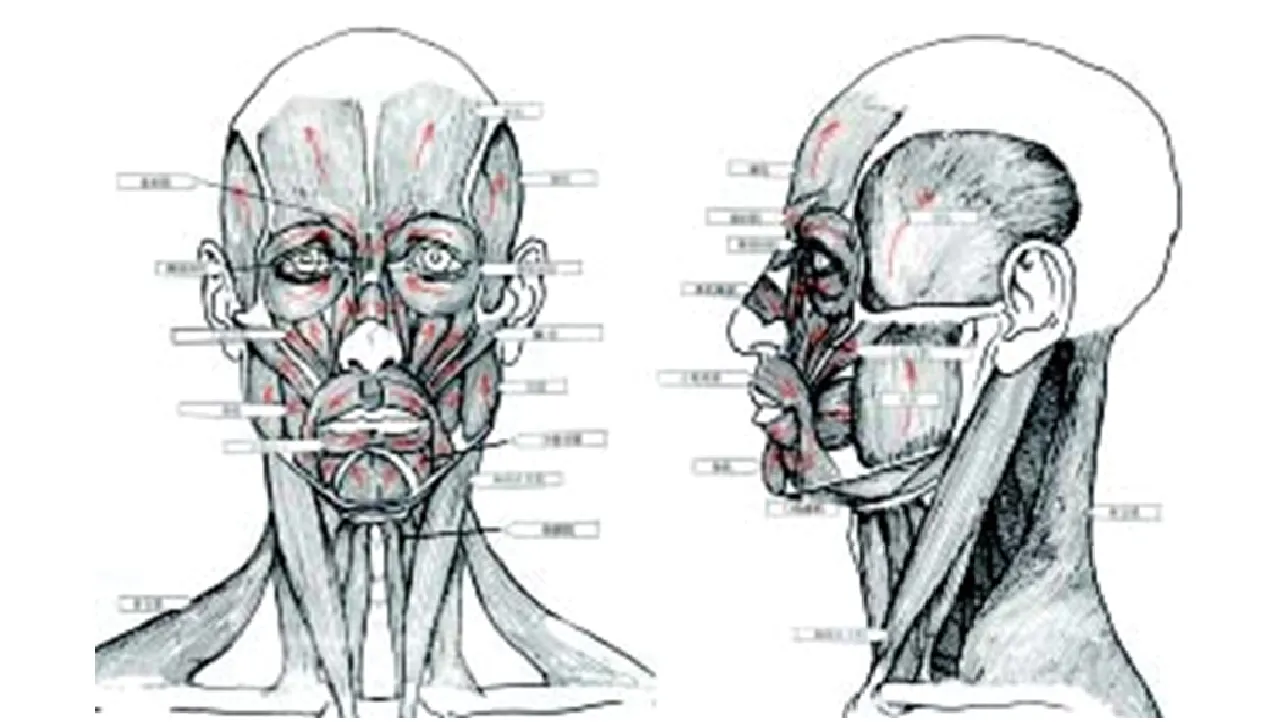
图2 面部肌肉示意图
由此可见,人的相貌并不仅仅是由“耳、眉、眼、鼻、口”这五官决定的,同时也是由人的面部表情所决定的。
2.3 画像中微表情的瞬间捕捉
微表情画像与传统模拟画像相比,其难度就在于对微表情的瞬间捕捉上。意大利著名画家达芬奇的名作《蒙娜丽莎》,500年来,那神秘的微笑倾倒了无数的人。蒙娜丽莎极富个性的微表情,时隐时现,给人一种神秘感。
美国神经科专家玛格丽特·利文斯通博士认为,蒙娜丽莎的微笑之所以时隐时现,充满神秘感,是由于观看者不断改变观看的位置,与画中人的表情无关。她认为,人们在观看一张脸的时候,主要注视对方的眼睛。也就是说,当人们的中央视觉落在蒙娜丽莎的双眼时,外围视觉便会落在她的嘴巴上,而外围视觉常常会有误差。而且,人们在观看这幅画像时,角度和目光也在不断地移动。这样,蒙娜丽莎的颧骨部位的阴影就会随之突出,笑容弧度也会显得加大,于是,蒙娜丽莎的笑容便若隐若现了。
利文斯通博士的研究成果告诉我们,移动的目光观看一个静止的画面,画面会出现不同的变化[2]。那么,移动的状态去观察移动的画面,看到画面肯定也是有变化的。
犯罪嫌疑人在作案现场不是静止的,而是动态的。目击者由于所处角度不同,移动速度不同,看到的犯罪嫌疑人的相貌便会产生差别。这就是为什么面对同一个犯罪嫌疑人,不同的目击者有不同的面孔描述的原因。
2.4 微表情是人心理特征的外部表现
从犯罪嫌疑人角度来说,他的相貌或者说表情,在生活现场和犯罪现场也是有差别的。甚至同是在犯罪现场,比如熟悉的犯罪场地和陌生的犯罪场地、对陌生人实施犯罪和对熟人实施犯罪、蓄谋已久的犯罪和临时起意的犯罪,其面部表情都是会有差别的。
美国心理学家保罗·艾克曼认为:人在遇到危险时,大脑边缘系统会调整我们的行为,其顺序一般是:冻结、逃跑、战斗。而只要有边缘反应,就会有安慰行为,比如触摸颈部、摸脸、玩头发、说个不停、打哈欠、搓腿、叉手、拉松衣领,这就是微反应。这种微反应表现在脸部的时候,比如,犯罪嫌疑人在实施抢劫时,就会出现惊恐的瞬间状态,如眉头紧皱、眉毛上扬、口大张等微表情瞬间[8]。
但微表情画像同样存在难点,特别是一般目击者关注的只是犯罪嫌疑人的轮廓、身高、胖瘦和脸部明显特征等,很难迅速获得准确的犯罪嫌疑人相貌信息。这就需要刑侦模拟画像专家通过目击者的多重描述,通过对视频资料的细心分析,结合犯罪现场情境,运用心理学、医学、艺术学、运动学等多学科知识和办案经验,再运用微表情画像技术,准确地描绘出犯罪嫌疑人的相貌特征。
同时,我们还可以将人类的微表情建立一个数据库,在绘画中将人的每一种表情形态,如眼型、口型、眉型、鼻型、嘴型等与解剖学、心理学、艺术学等结合起来,进行对应信息分析,使其成为破案的关键要素。
3 微表情画像在人像识别中应用的实现
3.1 我国人像识别技术及算法在公安领域的应用
人像识别又称人脸识别,早在上世纪60年代开始,国外就开始对人脸识别技术进行相关的研究。在研究初期,人像识别仅仅作为一般性的模式识别进行研究,尚未单独作为一个研究领域,方法大都是针对人脸几何特征实现的算法。到上世纪90年代,随着计算机处理速度的提高和图形识别算法的改进,也因为社会治安及各领域的需要,人像识别技术脱颖而出,成为单独的一个研究领域。从PCA(Principal Component Analysis,主成分分析法)算法的出现,到“隐马尔可夫”“LBPH”算法;从人脸几何特征实现的算法,到精确像素点的结合,人像识别系统不断地精益求精。
如今,人像识别领域的专家在进行跨维度的换代,二维与三维结合,多种识别模式结合使用,逐渐克服姿势、表情变化、佩戴首饰等因素的影响。特别是在公共安全领域,人像识别系统借助遍布城市各个角落的监控探头进行人像采集,在治安保卫、刑侦破案、卡口安检等领域发挥了重要作用。
3.2 微表情特征画像在人像识别技术中的应用
微表情画像技术与人像识别技术的结合运用,是人像识别技术对拍摄到的照片进行识别比对,并通过测算二维图像人物脸部特征点的距离来实现的。
目前,人像识别领域的研究热点主要集中在人像识别主流算法方面,如PCA、隐马尔可夫模型(HMM-Hidden Markov Model)、局部二进制编码直方图(LBPH-Local Binary Patterns Histograms)及基于深度学习算法。
在常规人像识别研究领域内,PCA算法、隐马尔可夫模型和局部二进制编码直方图方法各具优势,但是在本文研究背景下,由于微表情画像图像中高光部分像素值不包含任何像素亮度变化,同时在组成阴影部分的线条之间包含像素值的突兀过度,这两方面因素都会对LBPH的局部二值化结果造成影响,并导致人像识别准确率下降。在微表情画像用于人像识别过程中,目击者口述信息描述存在信息分布不均匀的特点,受此影响,微表情画像结果中人脸各局部所含细节特征数量存在差异,甚至可能某一局部特征完全缺失,因此造成隐马尔可夫模型隐含变量获取过程困难,甚至导致人脸识别结果错误。
为提高识别准确率,本文选择PCA作为基于微表情画像的人像识别算法,相对于隐马尔可夫模型和局部二进制编码直方图算法而言,PCA在主成分选择过程中充分考虑人像库中人像灰度分布情况,以最大化类间差异为原则确立人像识别过程的主要维度,该主要维度信息不会受到模拟画像阴影线条及高光部分影响,也能一定程度避免模拟画像信息分布不均匀引起的识别率下降问题,因此PCA方法更适合于本文研究背景。另外,本文所述研究背景是基于小样本,样本数量不足以支撑一个深度学习模型的训练过程。因此,本文没有采用深度学习算法。
3.3 人像识别的具体流程
从狭义上来讲,人像识别是对以人脸为主的分析、特征提取和识别。
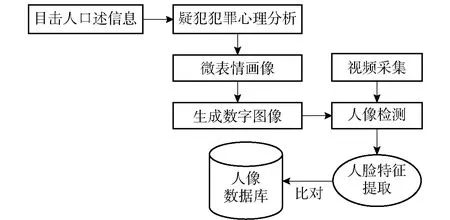
图3 人像识别流程图
人像识别的具体流程可分为:目击者口述信息、疑犯犯罪心理分析、微表情画像、视频采集、人像检测、人脸特征提取、数据关联等几个步骤。
微表情特征画像的建型准确是画像人像的关键。通过引导口述人对目标信息的准确描述,建立人像轮廓五官特征,对目标人像特征加以犯罪分析,呈现出带有表情特征的人像画作后,进行人像检测。
人像识别的具体流程可分为数字绘画图像和视频人像采集两个方面:一是数字绘画人像,画像的准确性是微表情特征画像建模准确的关键。通过引导目击者对目标信息的准确描述,建立人像轮廓五官特征,对目标人像特征加以分析,呈现出带有表情特征的人像画作后,生成数字图像,导入人像检测系统后提取人脸特征,与人像数据库图像进行比对。二是视频人像采集,视频采集是原始图像识别流程的基础。由于视频流具有延续性,链接性,所以将视频的画面定格在某一帧上进行采集,从而获得较为清晰的图像。然后对采集到的图像进行检测,通过检测,判断是否有目标人脸的存在,对检测到的人脸信息图片进行分析,特征提取,最终与人像数据库中信息进行比对,找出相似的数字图像。
3.4 PCA算法在画像中的应用与实现
素描模拟画像是二维的平面画像,而人像识别技术对拍摄到的照片进行识别比对是通过测算二维图像人物脸部特征点的距离来实现的。因此,以犯罪嫌疑人模拟画像替代“二维”照片,通过目击者对犯罪嫌疑人的描述,刻画犯罪嫌疑人的颅骨、脸部肌肉的阴影关系以及特征点、五官等进行犯罪嫌疑人模拟画像,进而将模拟画像导入人像识别系统,利用人像识别系统接入的人像资源库进行自动识别比对,选出与模拟画像最为相似的人员信息。
以下是PCA算法的原理及步骤:
(1)读取训练集下指定数目的图像,将每张图像的像素保存到一个二维矩阵中。然后把这个矩阵按照列排拉伸成为一个新的列向量,每一个列向量表示一张图像的像素信息,然后将所有代表训练图像的列向量整合为一个新的矩阵X,如果有S张人脸图像,每张图像尺寸为m×n,则矩阵X为m×n行,S列;
(2)对X的每一行取得均值,每行的元素减去均值,得到每张人脸与平均人脸的差值,组成新矩阵X′;
(3)计算X′的协方差矩阵C,C的维度为m×n;
(4)计算C的特征值即特征向量,共有m×n个特征值及特征向量;
(5)选择主成分,把特征值从大到小排序,选择前R个特征值使得R个特征值占所有特征值的90%以上,随后将特征向量按行排列,则P=[R,m×n];
(6)将训练集投影到特征空间,Y=PX′=[R,S]。
(7)将测试集也投影到特征空间,假如测试集有K张图像,那么降维后矩阵为[R,K]。
(8)每一张图像[R,1]与特征空间[R,S]用欧氏距离法求出与其最相近的一个图像,识别为该类。所有测试集识别完后,最后求出识别率。
识别结果以两种方式呈现:一是从人像库里面遴选出3张与待检测目标图像最相似的图像;二是显示出目标图像与样本图像相识度值。
通俗地讲,PCA算法是通过测算出待识别图形的特征向量来实现人像识别的。而待识别图像人脸不同的骨骼形状及透视比例等特征是特征向量值计算的主要因素。不同的脸型测算出来的特征向量值不同。
3.5 人像识别PCA算法的不足因素
人像识别作为生物识别技术中一种最新的识别技术并不是完美的,它的优点也决定了它的先天不足。
首先是光线条件影响。笔者认为决定一张照片成像质量的关键因素在于光照条件。不同光照的成像效果有天壤之别。在光照条件不理想的情况下输入待处理的图像,会导致结果误差增大。
其次是受被拍摄者姿态的影响。人脸的拍摄角度可以影响到各类人脸识别算法的效果,这是因为人脸识别的研究基础是人脸数据库,而这个数据库中收集的人脸一般都是正面姿态的人脸,所采集收录的人像信息都是平面的,所以,对其他姿态人脸的容忍度会比较低。
再一个就是头部饰品和脸部遮挡物的影响。如果监控设备采集到的是一个戴着口罩的人,口罩遮住了脸部的大部分特征,那么人像识别系统是无法进行识别比对的。
因此,将模拟画像与人像识别结合起来,取长补短,在人像识别系统无法解决问题时,运用传统的模拟画像技术,发挥出两项技术的优势,更快地锁定犯罪嫌疑人。
4 微表情特征画像在人像识别系统中的实现
根据记忆曲线实验,目击者的记忆质量随着时间的推移而下降。美国FBI曾经做过一个实验,当第一个人对目击者问起目击情况时,目击者能较客观完整地表述自己的记忆。当越来越多的人对目击者问起目击情况后,目击者心理逐渐对所目击的事物产生排斥,会刻意地对目击的事物进行“人为加工”。所以,我们在对目击者进行犯罪嫌疑人模拟画像时,应当距离目击时间越短越好。第一位目击者对犯罪嫌疑人的描述:犯罪嫌疑人个子挺高,180 cm左右,中等身材,25~30岁之间,肤色较黑,头发三七偏分,中短卷发,眼角下垂,椭圆脸型,额头较宽,福建或广东一带口音,重要特征为左边嘴角向上45°倾斜。
根据第一位目击者的描述,对犯罪嫌疑人的面貌进行心理构建:
首先将五官位置、距离确定,画一长方形为基准形状,并将长方形3等分,在长方形上面画个半圆,构成基本的脸型(如图4a所示);长方形3等分后的顶端的第一条线就是作为发际线的位置;第二条线就是眉线;最下端一条线就作为鼻子下半截的位置(如图4b所示)。
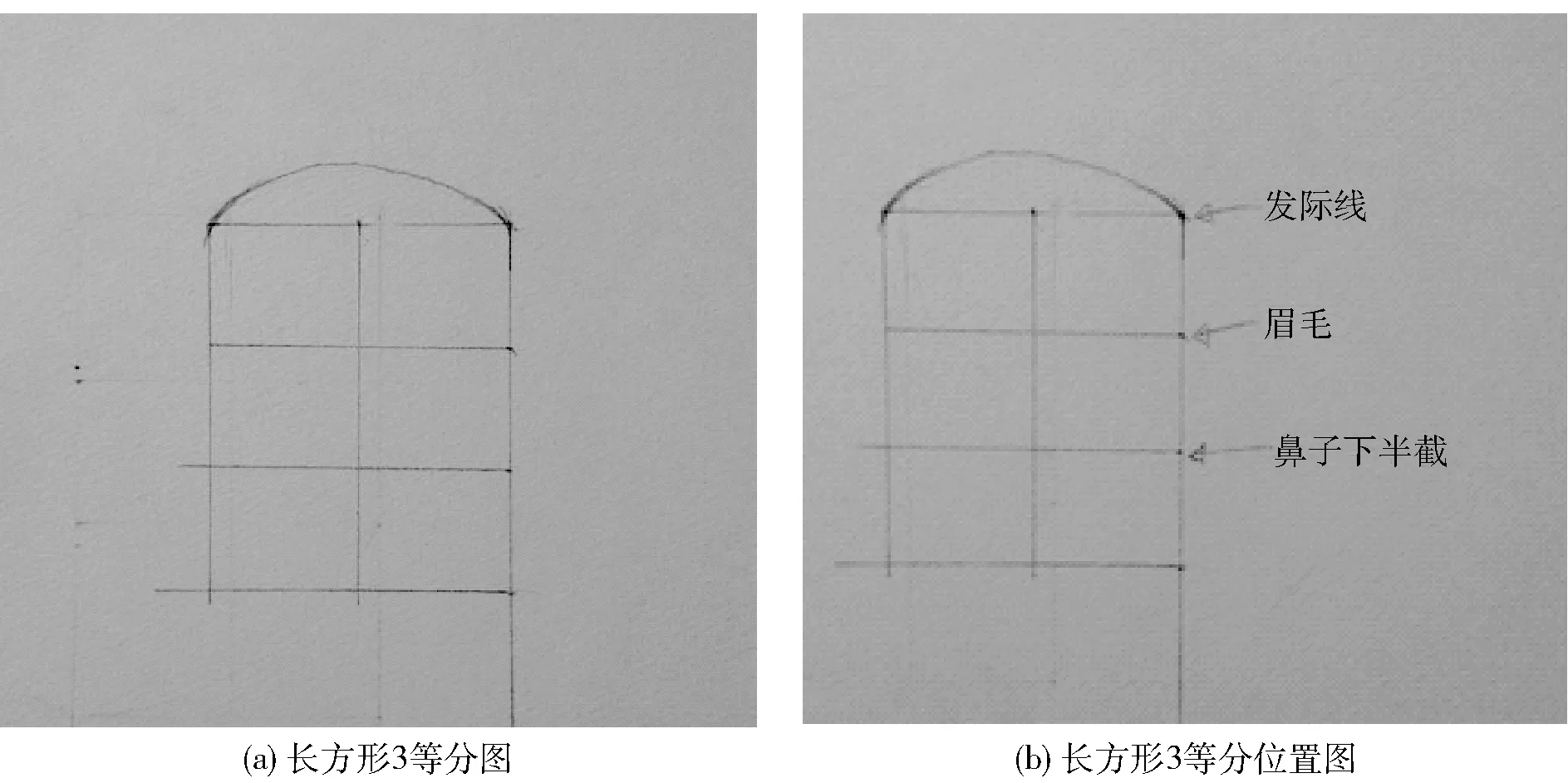
图4 长方形3等分示意图
长方形3等分是为了遵循最传统的“三庭五眼”的标准人脸,不管是什么长相,只要均衡,大多数都是好看和顺眼的。
固定好大概位置之后,就是对犯罪嫌疑人颅骨的刻画。颅骨相当于地基,只有打好了地基,才能往上盖楼。犯罪嫌疑人椭圆形脸、宽额头,说明犯罪嫌疑人额骨较大,颧骨较为突出,下颌角较大,脸型较长。在勾勒脸型框架时,抓住这几个特征点,额头中间部分用笔较轻,左右两边用笔可重一些,突出阴影关系。颧骨处同上,颧骨凸出部分用笔较轻,周围加重,凸出阴影关系;下颌均匀过渡,可先用较细的线条勾勒出基本形状,再加重笔触;在画好额骨、颧骨、下颌骨的基础上,用细线条勾画出犯罪嫌疑人的基本脸型。
犯罪嫌疑人头发特征明显,三七偏分,中短卷发,在作画时着重凸出“三七偏分”,画头发的外缘、鬓角处以及与前额相接时自然过渡,避免生硬。
画眉峰时,注意与犯罪嫌疑人作案时的眼神结合,一般作案时犯罪嫌疑人眼神较为凶狠,顺着眉毛的走向,不能呆板。
画眼时切忌和周围环境分开,眼窝眉弓的凹凸要通过绘画表现出来。犯罪嫌疑人眼角下垂,所画的眼睑线,眼球要把握好朝向,可用较重的笔触,准确表达虚实关系、明暗关系。
在第一位目击者的描述和不断地交流下,笔者画出了嫌犯模拟画像A(如图5所示)。

图5 犯罪嫌疑人模拟画像A
画完第一张犯罪嫌疑人模拟画像后,立即与第二位目击者交流。
第二位目击者的描述:犯罪嫌疑人身高在180~185 cm之间,中等身材,看上去长期从事体力劳动,皮肤较黑,头发偏分,眉峰较粗重,中短卷发,大眼睛双眼皮,眼角下垂,脸型较长,福建或广东一带口音,重点是嘴角向上倾斜,似笑非笑。根据两名目击者的描述,抓住了疑犯的微表情特征,进而对微表情特征刻画。
这里,两位目击者均提到了犯罪嫌疑人“偏分、中短卷发、皮肤较黑、福建或广东一带口音”,尤其是福建或广东一带地区口音及“嘴角倾斜”这一特点,给两位目击者留下了深刻的印象,所以笔者做出了一个假设:犯罪嫌疑人就是福建或广东地区一带的人,嘴像一边倾斜。有了这个假设之后,依据汉族人相貌分布情况规律的知识,福建或广东一带人的相貌特征:较深的眼窝,略高的颧骨,鼻梁比较高,脸型比较长、额头比较窄、以及低眼眶、短鼻头、双眼皮、大眼睛等特点,再结合两位目击者的描述,在第一张模拟画像的基础上,经过不断的修改调整,着重刻画犯罪嫌疑人的嘴角倾斜特征及外眼角向下耷拉等特征后,画出第二张犯罪嫌疑人的模拟画像B(如图6所示)。

图6 犯罪嫌疑人模拟画像B
为了使模拟画像在人像识别软件上有效地进行识别比对,笔者在人像识别软件对待识别图像脸部的特征点进行着重刻画,笔触加重,在第二张模拟画像的基础上,画出了犯罪嫌疑人模拟画像C(如图7所示);然后将犯罪嫌疑人模拟画像C出示给两位目击者,均得到了两位目击者的一致肯定。

图7 犯罪嫌疑人模拟画像C
经过对犯罪嫌疑人进行了两次深入的刻画,为了将其面部特征有效地进行识别比对,选用MATLAB软件作为人像识别程序,该软件是基于PCA算法,即测算二维图像上特征点距离的测算来实现两张图像相似度的比较。其识别原理是将瞳距、眉间距、额宽、眼宽、眼睑距、眼尾距、鼻宽、鼻长、嘴宽下嘴唇到下颌端的距离,颧骨的距离等这些特征点(图8所示)的距离向量化,最后用欧氏距离法从接入的人像资源库中找出与待识别图像特征点距离最相近的一个图像,模拟画像与常用的二维照片在维度上、特征点上具有一致性。
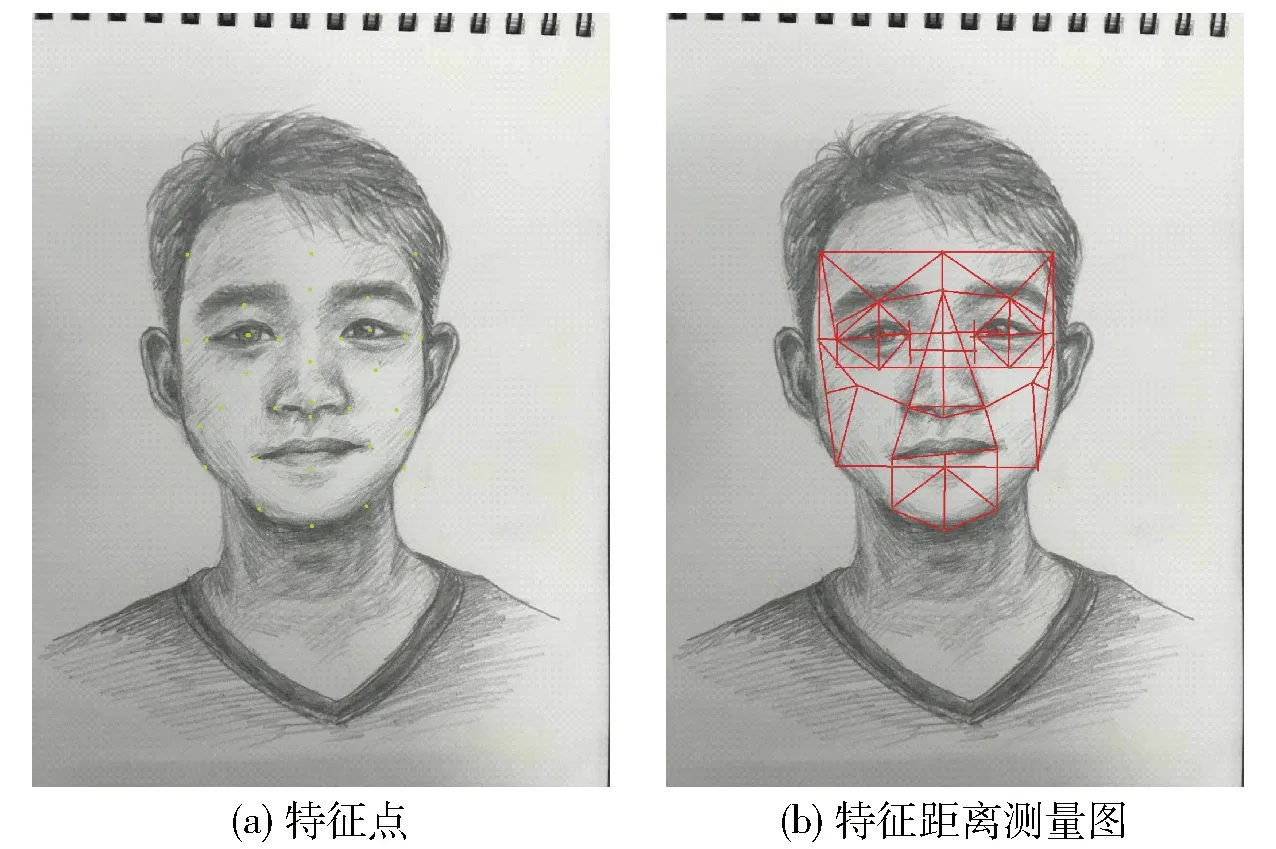
图8 模拟画像比对图
模拟画像与常用的二维照片在维度和特征点上具有一致性。所以将刻画完成犯罪嫌疑人模拟画像B进行翻拍成PGM格式图像文件,运用Photoshop图像处理软件转换成灰度图——将该灰度图像导入MATLAB软件并编号为4作为待识别图像——点击运行,选择4号图像点击打开。软件运行后,通过对待识别图像脸部特征距离的测算,从接入的人像资源库中求出与待识别图像特征点距离最相近的这张图像(如图9所示)。
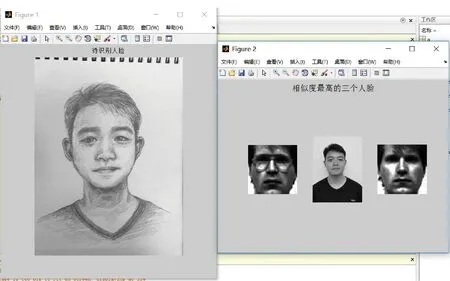
图9 人像识别比对结果图
根据Matlab人像识别系统的比对结果,筛选出相似度最高的3个人,并将3个最相似的比对结果出示给目击者,两名目击者都指出第二张人脸与犯罪嫌疑人有较高的相似度。警方根据这条线索展开案件侦查,为案件侦破奠定基础。
5 结论
本文利用了MATLAB基于PCA算法对微表情特征画像照片进行计算机人脸识别比对,打破了传统利用清晰人像照片在公安人像数据库中进行比对的方法。微表情特征画像的特殊作用就在于抓住了犯罪嫌疑人的习惯性表情或面部特征与作案时瞬间表情的定格,最终所绘画出带有表情特征的画像,再通过心理学加以分析,找到犯罪原由。笔者在作画的同时融入了疑犯面部表情特征进行深入重点刻画,使得犯罪嫌疑人画像更加具有特点,不再呆板。在此基础上,将微表情特征画像作为待检测人像图片导入MATLAB软件中,通过PCA算法对待检测人像中特征点的距离测量完成人像识别比对。
