基于LDA 主题模型和直觉模糊TOPSIS 的农产品在线评论情感分析
2020-10-23王珠美胡彦蓉刘洪久
王珠美,胡彦蓉,刘洪久
(1.浙江农林大学信息工程学院,杭州,311300;2.浙江省林业智能监测与信息技术研究重点实验室,杭州,311300)
引 言
随着互联网与信息技术的迅猛发展,我国的网络购物正在急速发展。根据第45 次《中国互联网络发展状况统计报告》数据统计,截至2020 年3 月,我国网络购物用户数量达到7.10 亿个,互联网普及率达64.5%,即超过一半的中国公民都在通过网络来购物。但由于网络购物的虚拟性和产品的不可触摸性,商品的在线信息成为消费者评判商品的重要依据。根据《2015 年中国网络购物市场研究报告》数据统计,消费者在网上购物时,商品口碑、价格、商家的信誉成为消费者评判商品的主要考虑因素,其中网络口碑的百分比最大,达到77.5%。在线评论作为口碑的主要载体,成为消费者获取信息的主要来源,也是商家了解消费者需求、产品需求改进、促进商品销量的主要渠道。因此,越来越多的学者开始研究评论中包含的隐藏信息,通过挖掘评论的情感信息进一步分析评论中的有效信息。
情感分析又称情感极性分析,它是对文本进行表达出的情绪积极、消极以及不确定的判断。在现阶段,情感分析主要有通过构建情感词典进行分类的方法,也有机器学习方法。通过构建情感词典的方法主要是通过情感词典对文本进行词语分析,计算情感值,然后通过判断情感值确定文本表达的情感倾向。在基于情感词典进行分类的方法方面,Baccianella 等[1]提出一种通过构建情感词典来挖掘情感特征进行情感判断的方法。郭顺利等[2]将用户情感倾向细致划分,通过构建中文图书评论的情感词集,同时结合改进的SO-PMI 算法和同义词词林,提出一种判别词语情感类别的方法。也有很多学者对于特定领域构建情感词典。陈柯宇等[3]提出一种结合扩展的情感词典以及word2vec 工具的情感倾向分析方法。蒋盛益等[4]通过改进的Hevner 情感模型,利用HowNet 中语义相似度计算的思想,构建音乐领域的中文情感词典。通过机器学习分析文本情感倾向的主要思想是将文本情感分析转化为一个分类问题,然后利用算法进行训练得到一个模型,最后通过这个模型进行文本情感判断。在机器学习方法方面,Singh 等[5]运用相同的数据对机器学习方法和基于语义信息的方法进行情感分类实验,实验表明了基于机器学习方法的有效性。赵刚等[6]对餐厅评论情感分析时,通过比较几种经典的机器学习算法,包含了Ada Boosting、Bayes Network、Decision Tree、C4.5 分类树、Naïve Bayes 分类器以及Ripper 等算法,实现了适合于发掘隐含属性、展现商品间关联性和判断客户情感倾向的网上商品评论情感分析模型。然而在机器学习中,文本大多都是通过词袋模型来表示,这样易造成文本中包含的语义信息和情感信息等问题不能很精确地描述出来,而新兴的深度学习方法恰好能够弥补这些缺点。通过神经网络模型,能够计算得到文本中词语的分布式向量,可以用低维且连续的形式来表达词,能够较好地应用到其他深度神经网络模型,利用多层网络的学习,可以更加具体地表达文本特征,提高了模型的准确性和工作效率。近年来,许多学者将卷积神经网络[7](Convolutional neural network, CNN)、长短时记忆网络[8](Long-term memory network,LSTM)、双向长短时记忆网络[9](Bidirectional long-term memory network,BLSTM)等深度学习模型运用到产品在线评论情感分析中去并取得了较好的成果。
但目前的研究存在以下问题:(1)文本属性权重确定方式不精确。在情感分析方法中有多种属性权重计算方式,其中,词频-逆文本频率(Term frequency-inverse document frequency,TF-IDF)是一个被广泛应用数学统计模型,表示在文档中词语的重要程度,如余苗等[10]运用TF-IDF 分类算法挖掘用户兴趣模型,从而实现了情报的按需分发,但该方法的推荐精度还需要进一步提高。(2)文本情感描述不明确。传统的情感分析方法是需要人工标注文本特征后,利用机器学习构建分类模型,判断文本的情感倾向,这样的处理方法对于文本的情感特征描述处理不够客观[11],没有办法准确地描述消费者的情感倾向。
因此,为解决信息的有效提取和分析在线评论与商家绩效之间的关系,本文提出了一种基于潜在狄利克雷分布(Latent Dirichlet allocation,LDA)的主题模型和直觉模糊TOPSIS 的农产品在线评论情感分析方法。该方法的主要特点在于:(1)根据属性出现的次数来确定各个属性的权重。Pang 等[12]研究表明,使用词语的出现次数能够获得比词频-逆文本频率方法更好的实验结果。因此,本文将用属性出现的次数来确定各个属性的权重,避免了人为给定权重的不确定性。(2)利用LDA 主题模型进行主题建模,通过计算混乱度来确定在线评论的最佳主题数。Chiru[13]通过对现有的主题建模算法在处理大量文档和对已识别潜在主题进行解析方面的比较,确定LDA 主题模型具有最高性能。同时根据LDA 模型相关参考文献,混乱度是测量LDA 预测能力的标准方法[14]。通过混乱度计算在线评论的最佳主题数目,保证了文档的聚类效果。(3)采用直觉模糊数来反映消费者不同的情感。针对消费者情感的不确定性,直觉模糊理论可以反映评论中消费者表达的支持、犹豫和反对程度,全面地描述评论中的情感倾向,弥补了只考虑消费者情感极性的不足。
1 基于LDA 主题模型和直觉模糊TOPSIS 的农产品在线评论情感分析算法
1.1 问题描述及解决框架
随着科技的发展,人们对于网上购物的依赖越来越大。在生活中,假设消费者想要购买某种农产品,经过关键字搜索后缩小了条件符合农产品的范围,但搜索结果往往还是呈现了数目较多的农产品,这时候进一步的选购就需要消费者具有一定的筛选能力,由于诸多因素限制,消费者无法有效地得到需要的评论信息,在多种商品之间无法便捷轻松地做出购买决定[15]。本文从产品在线评论信息过载出发,设计基于LDA 主题模型和直觉模糊TOPSIS 的产品在线评论情感分析方法对关键字搜索后的商品进行分析,挖掘在线评论中的有效信息,为消费者挑选商品提供建议,其解决框架如图1 所示。
1.2 LDA 主题模型
统计主题模型近年来得到了学者的广泛应用,它能够在计算机没有完全了解文本结构的情况下,分析出易理解且相对平稳的语言结构,为数据集中的文本寻找一个相对简短的描述[16]。统计主题模型最早来源于隐含语义 检 索(Latent semantic indexing, LSI)[17],重 大 突 破 是Hofmann 提出的PLSI(Probabilistic latent semantic indexing)模型,PLSI 模型主要是通过概率模型来计算文档集中词产生的过程,但是PLSI 对于文本的产生不能用概率来描述,只是简单地对部分文本进行拟合,得到指定文本的主题混合比例[16]。针对这些不足,Blei[18]于2003 年提出的一种生成主题概率模型LDA,在PLSI 的基础上,用一个服从Dirichlet 分布的隐含随机变量表示文档的主题混合比例来模拟文档产生的过程,其模型结构更为完整清晰,采用概率去推断算法处理文本,可以将文本表示的维度大大降低,从而避免维度灾难,因此在文本分类、信息检索等领域取得了非常好的实践效果。
1.2.1 LDA 主题模型
LDA 模型即是3 层贝叶斯概率模型,模型包含词—文档—主题3 层结构,具体如图2 所示,通常用来对大规模文档数据进行建模[19]。文档中某个主题的词汇构成存在一定的概率,且从主题中心选择了某个词语也可以用概率来分析。具体训练过程如下[20]:

图1 农产品在线评论情感分析结构Fig.1 Emotional analysis structure of online agricultural product reviews
(1)评论m包含的特征词数量Nm服从泊松分布,及Nm~泊松(ξ)。
(2) 对 于 评 论m生 成 主 题 分 布 ,其 中m∈{1, 2, …,M}, 即θm~Dirichlet(α),其中M表示数据集评论的总数量,θm表示第m个评论的主题概率分布,α 为每个评论下主题的多项分布的Dirichlet先验参数。
(3)对于主题n生成特征词分布,其中z∈{1,2,…,K},φk~Dirichlet(β),K为总的主题数,β为每个主题下的词多项分布的Dirichlet 先验参数。
(4)评论m中的特征词wm,n(n∈{1,2,…,Nm})的生成过程,Nm为第m个主题包含的特征词①根据主题分 布θm生 成 评 论wm,n的 特 征 词 主 题 ,即zm,n~Multinomial(θm),zm,n表 示 的 是 第m个 评 论 的 第n个 词 的 主题。②根据词项分布φzm,n生成所选词主题词项,即wm,n~Multinomial(φzm,n)。
1.2.2 吉布斯抽样
LDA 模型中变量的联合分布较难理解,对计算隐含变量概率分布难度很大,常见的抽样方法有接受-拒绝抽样、重要性抽样、吉布斯抽样。吉布斯抽样是应用于马尔科夫蒙特卡洛(MCCM)的一种算法,通常用来分析随机样本的多变量概率分布,由于其在混乱度和运行速度等方面优于接受-拒绝抽样和重要性抽样,且易于实现和推广应用,因此本文采用吉布斯抽样来实现对LDA 主题模型进行主题抽取,主要的抽取过程如下:
(1)计算主题-特征词的概率分布

图2 LDA 模型的生成过程Fig.2 LDA model generation process

(2)根据贝叶斯公式和Dirichlet 先验分布,计算Dirichlet 分布期望

式中:θm,k表示数据m中主题k的概率,φk,t表示主题k中特征词t的概率,nm,(k)表示评论m中主题k的特征词汇,nk,(t)表示的是特征词t在主题k中出现的次数。
(3)通过吉布斯抽样得到概率分布

式中:n(k)mε表示数据m中没有分配到主题k的特征词个数,n(t)kε表示特征词没有分配给主题词k的次数。
对于文本数据集来说,LDA 模型的主题挖掘过程就是通过文档主题概率分布θ和文档对应的主题向量z,求出式(4)中的最大超参数α和β的值。在LDA 主题模型中,所有文档以及文本的特征词都是可见变量,但是文本的主题是不可见变量,所以通过已有的数据和文本生成规则,LDA 主题模型可以实现参数估计,分析出文本中不可见主题,有助于进一步分析文本内容[21]。
1.2.3 确定主题数
在文本预处理后获取文本评论,使用LDA 主题模型对其建模,通过吉布斯抽样确定LDA 模型参数。虽然构建好了LDA 模型,但文本的主题数无法由模型直接确定,而主题数对抽取主题分布影响较大。当主题数过大时,会产生很多不具明显分类语义信息的主题;当主题数量过少时,会产生比较粗粒度的主题,这样对分类影响也很大[22]。因此,如何科学地确定主题数量非常重要。本文采用混乱度(Perplexity)来确定最优主题数量值。
混乱度在对文档建模过程中特别有用,它关于测试文档概率单调递减,在代数上等价于所有词概率的几何平均值倒数。其实,混乱度可以理解为对于一篇文章d,所训练出来的模型对文档属于哪个主题有很多的不确定,混乱度就可以用来描述这个不确定的程度。混乱度越小,说明聚类的效果越好。计算公式为
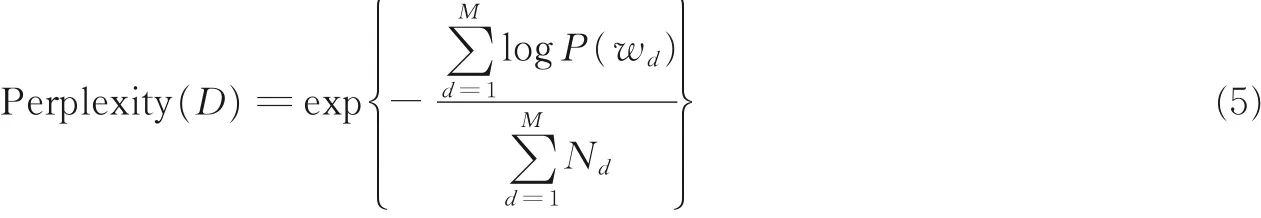
式中:D 为需要测试的文档集,wd为文本d 词汇序列,Nd为文档d 的词汇数量,P(wd)为文档中产生wd的概率。
1.3 产品在线评论情感词典构建
情感分类主要是通过自动分析某种商品评论的文本内容,将其分为正面情感、负面情感和中性情感这3 类。常用情感词语又称极性词、评价词,特指带有情感倾向性的词语。显然,情感词语在情感文本中处于举足轻重的地位,情感词语的抽取和极性判断在情感分析创建开始的时候就引起了极大的兴致[23]。
目前,常用的公共情感词典有知网(HowNet)发布的情感词典、台湾大学自然语言处理实验室提供的中文情感词典(National Taiwan University sentiment dictionary,NTUSD)以及清华大学提供的褒贬义词典。本文的情感词典构建如图3 所示,具体步骤如下:
(1)选用爬取到的评论数据作为数据集,对原始评论数据进行结巴分词以及去停用词。(2)将预处理后的评论数据进行筛选,按词性对数据进行筛选。
(3)按词性不同对HowNet、NTUSD 和中文褒贬义词典进行筛选。
(4)因为中文语法的复杂性,除了基本情感词典外,还需要标点符号词典、连接词词典、短语词典等,本文根据知网情感词典整理出这3 个词典。
(5)按词性的类别合并去重,并且人工对其进行打分,得到本文构建的情感词典,分别如下:副词词典、连接词词典、否定词词典、短语词典、消极词汇词典、积极词汇词典和标点符号词典。

图3 农产品在线评论情感词典构建Fig.3 Build an emotional dictionary for online reviews of agricultural products
1.4 直觉模糊TOPSIS 模型
1.4.1 直觉模糊数的计算
直觉模糊集理论是处理模糊性和犹豫的有用工具,直觉模糊可以同时反映支持、犹豫和反对程度[24]。基于直觉模糊理论,关键字搜索之后的商品在线评论的情感分析可以通过直觉模糊数简单而完整地表示。
qposij表示商品Ai的特征j 评论中积极情感评论数(kposij)的占比,也称为积极评论占比,同理可计算得消极评论占比(qnegij)、中性评论占比(qneuij)。表达式为

因此,根据直觉模糊数的解释,一个直觉模糊Yij=[qposij,qnegij]可被构造用于关键字搜索后商品Ai的特征fj的性能。
1.4.2 TOPSIS 模型
TOPSIS 方法避免了数据的人为主观性,不需要目标函数,能够很好地刻画多个影响指标的综合影响力度。同时对于数据分布及样本量没有严格的要求,既适用于小样本数据,也适用于多评价单元、多指标的大样本数据,适用性较强。该方法基本思想如下:在确定各个属性指标权重的基础上,归一化原始数据矩阵,分别计算关键字搜索后商品与最优方案和最劣方案间的距离,获得各商品与最优方案的相对接近程度,作为评价商品优劣的依据。具体算法步骤如下:
(1)根据关键字搜索之后商品的整体模糊数构造矩阵决策矩阵A=(aij)n*m,其中aij=Aij,表示关键字搜索之后商品Ai的特征fj的直觉模糊数,n 为关键字搜索之后的商品个数,m 为商品的特征数。
(2)为了消除不同属性之间的量纲效应,使每个属性特征都具有同等的表现力,首先对原始数据进行标准化处理。

(3)构成加权规范化矩阵

通过LDA 模型的构建,得到评论-属性的分布情况,统计评论的主题归属情况,用属性出现的次数来计算各个主题的权重W=(w1,w2,…,wm)T。

式中:nj(d)为第j 个属性在商品评论中出现的次数,属性的权重由该属性出现的次数和所有属性出现的次数之和的比重计算而得到[25]。

(4)确定正理想解C+和负理想解C-。正理想解是每个属性评价值最好时的取值,负理想解是每个属性最差时的取值。设正理想解C+的第j 个属性值为c+j,负理想解C-第j 个属性值为cj。
(5)计算各方案到正理想解C+和负理想解C-的距离。关键字搜索之后的商品Ai到正理想解的距离为S+i的计算公式如式(11)所示,同理可以求得S-i。
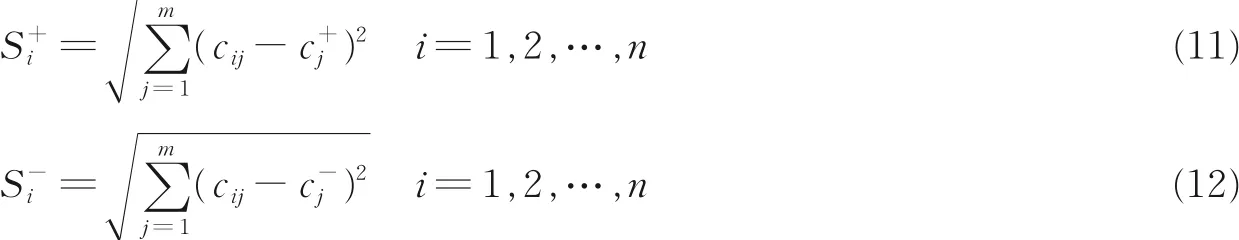
(6)计算每个商品与正理想解的相对贴近度(综合评价值)。商品Ai(i=1,2,…,n)与正理想解C+的相对贴近度定义为

显然,Ci∈[0,1],且Ci越大,则商品Ai越优。
(7)确定商品的优劣排序。综合评价值表示各种商品与正理想解、负理想解的距离进行比较,靠正理想解越近、离负理想解越远的备选方案的综合评价值就越大。可以按照综合评价值从大到小的商品优劣排序,确定其最优商品。
2 实 验
2.1 数据源说明
本文选取天猫商城作为分析数据的来源,关键词设置为西湖龙井,按商品销售量从高到低进行排序,选取排名前200 的商品作为分析对象,通过八爪鱼软件爬取商品评论数据。天猫商城是一个评论自由性较强的平台,消费者评论商品信息比较随意,因此获取的数据中存在很多需要剔除的垃圾评论,例如“哈哈哈哈哈哈”“666”等,经过去除垃圾评论之后一共得到110 824 条评论数据,将这些在线评论作为本文实验的数据内容。
然后,对评论进行数据预处理。具体过程为:用Python 中的Jieba 分词软件包对评论数据进行分词处理;收集四川大学机器智能实验室停用词库、哈工大停用词库、百度停用词列表以及中英文停用词表,合并去重后作为本文实验的停用词表,经过Python 编程对商品评论去除停用词。
最后,筛选评论中的词汇,根据情感词性进行打分,构成情感词典,手动检查词典的正确性,并根据商品的特性对情感词典进行补充。
2.2 基于LDA 主题模型的农产品在线评论情感分析
2.2.1 最优主题数目的确定
使用主题模型建模的过程中,主题数量的最优值采用混乱度来确定,采用Gibbs 抽样,抽样迭代参数值设为3 000。通过设置不同的主题数量对混乱度指标进行分析,获取最小混乱度的最优主题数目,具体结果如图4 所示。从图4 可以看出,当主题数目设置为20 时,训练得到的LDA 主题模型的混乱度最低,之后混乱度逐渐增长。因此,本文最优的主题数目为20。
2.2.2 基于LDA 模型的主题挖掘
基于Python 语言的机器学习包gensim 对评论数据进行LDA 主题建模,本文得到20 个主题及其分布情况。为了展示建模效果,这里只展示其4 个主题,每个主题的前10 个词汇的分布情况,如表1 所示。

图4 LDA 主题模型混乱度随主题数值变化趋势Fig.4 Disorder degree of LDA topic model changes with the trend of topic value
LDA 主题挖掘可以按照语义划分,得到语义相关词表达的若干个隐含主题。例如,Topic 0 的词汇集合描述了主题“茶香”,Topic 1 的词汇集合描述了主题“性价比”,Topic 2 的词汇集合描述了主题“划算”,Topic 3 词汇集合描述了主题“价位”,同理可得其余16 个主题的挖掘结果描述的具体主题,如“服务、分量、促销、外包装、优惠、正宗、信赖、茶叶外观、满意、被推荐、品牌、颜色、图片、评论、上档次、完整”,详细见表2。

表1 主题挖掘结果Table 1 Topic mining results

表2 主题权重Table 2 Theme weight
2.3 基于直觉模糊TOPSIS 的农产品在线评论情感综合评价值计算
2.3.1 属性权重的确定
根据LDA 主题模型得到的评论数据集中评论-主题概率,根据公式(9)得到20 个主题的权重,从表2 中可以看出主题4(服务)的权重最大,权重为0.130,可以看出消费者在挑选茶叶时最关注的是商家的服务;主题13(被推荐)的权重最小,权重为0,可以看出消费者在挑选茶叶时受别人推荐的影响最小。同时可以分别计算200 种商品各自的评论-主题-权重分布,分析每种商品的具体情况,为调整商品特征结构提供参考信息。
2.3.2 直觉模糊决策矩阵
根据式(6)计算可得200 个农产品的直觉模糊数组成的TOPSIS 决策矩阵。这里只展示销售量前6名的商品的前10 个主题决策矩阵,如表3 所示。从表3 中可以看出,各个商品-主题-情感倾向分布,例如,商品1 中主题0(茶香)的直觉模糊矩阵[0.828,0.046],其中0.828 表示的是商品1 评论中属于主题0(茶香)的积极评论占比,0.046 表示的是商品1 评论中属于主题0(茶香)的消极评论占比。由此可见,商品1 主题0 中的积极评论数量要远远多于消极评论数量,商品1 的茶香这一商品特质符合了绝大部分购买此商品的消费者需求(如果有需要,笔者可以提供全部的数据)。

表3 直觉模糊矩阵Table 3 Intuitionistic fuzzy matrix
2.3.3 加权规范矩阵
根据式(7)将农产品的整体模糊数构造决策矩阵进行标准化处理,结合特征权重,计算加权规范矩阵,部分商品的加权规范矩阵如表4 所示。

表4 加权规范矩阵Table 4 Weighted gauge matrix
2.3.4 基于TOPSIS 的商品综合评价值
根据式(11)、(12)和(13),本文计算每种农产品在线评论情感倾向的正、负理解,以及每种农产品在线评论的情感综合评价值,本文选取了部分农产品的综合评价值,绘制了在线评论情感综合评价值表,具体见表5 所示。从表5 中可以看出,200 种商品的综合评价值最大的是第88 种商品,综合评价值为0.614;综合评价值最小的商品有多个,综合评价值为0。

表5 在线评论情感综合评价值Table 5 Online comments on the value ofcomprehensive emotional assessment
为了更直观地观测每种农产品在线评论情感综合评价值情况,本文绘制了200 种农产品在线评论情感综合评价值折线图,具体如图5 所示。从图5 中可以看出,200 种农产品的综合评价值呈现无规律的波动。对200 种农产品在线评论情感综合评价指数计算可得综合评价指数平均值为0.097,200 种农产品中有76 种农产品的综合评价指数超过了平均值,销售量前50 的农产品中只有9 种农产品的综合评价指数超过了平均值,由此可见,农产品的销售量并不是影响综合评价指数的主要因素。

图5 农产品在线评论情感综合评价指数趋势Fig.5 Agricultural products online review Sentiment comprehensive evaluation index trend
2.3.5 有效性分析
为验证基于LDA 主题模型和直觉模糊TOPSIS 的农产品在线评论情感分析方法的有效性,本文采用综合评价值与其他变量的相关性来验证,具体的指标包括综合评价值、月销量、积极情感值,其中积极情感值是指某农产品积极情感倾向的产品评论在该农产品全部文本评论中出现的比例,积极情感值越大,情感倾向越强。变量分析具体结果如表6 所示。从表6 可以看出,在0.001 水平上,综合评价值与店铺销量、积极情感值呈现显著的正相关性,说明本文的综合评价值具有合理性,评价方法是有效的。

表6 变量相关分析结果Table 6 Results of variable correlation analysis
3 结束语
本文提出了一种根据在线评论对商品进行排序的方法。该方法通过计算属性出现的次数计算权重,避免人为给定权重的主观性和不确定性;充分考虑到评论的聚类效果,利用混乱度来确定最佳主题数目。除此之外,本文还考虑了消费者对不同商品的多种情感,利用直觉模糊数全面反映消费者的情感倾向,更符合消费者的实际购买情况。实验结果表明,本文提出的方法得到的综合评价值与月销售量、积极情感值呈显著的正相关性,这说明了该分析方法具有合理性,评价方法是有效的。在实验过程中发现,通过情感词典的方法来判断农产品在线评论的情感倾向,这一方法十分依赖人工构造的情感词典,存在一定的主观性。所以,客观评价在线评论的情感倾向成为下一步工作的重点。
总的来说,本文结合LDA 主题模型和直觉模糊TOPSIS 理论,提出了一种农产品在线评论情感分析方法。本文提出的情感分析方法具有合理性和实际应用价值,可以帮助商家了解消费者的购物需求,及时调整产品结构,同时也为消费者挑选商品提供参考建议,为当今分析商品信息提供了一种新的思路。
