端对端SSD实时视频监控异常目标检测与定位算法
2020-10-22胡正平李淑芳赵梦瑶
胡正平,张 乐,李淑芳,赵梦瑶
(1. 燕山大学 信息科学与工程学院,河北 秦皇岛 066004;2. 燕山大学 河北省信息传输与信号处理重点实验室,河北 秦皇岛 066004)
0 引言
在智能化深入普及和公共安全被高度重视的今天,人们对于智能视频监控系统尤其是具有实现实时性视频大数据处理能力智能监控系统需求日益增长,视频异常检测技术也持续成为视觉计算研究热点。
视频监控系统异常目标检测与定位问题实际上可以看作特殊视频序列中目标检测问题或是特殊视频序列中行为识别问题,先前研究人员所提出算法更倾向于将这一问题作为特殊行为识别问题来解决,例如Radu Tudor Ionescu等人将视频序列均匀分割为10×10时空块,对时空块进行特征提取并采用一阶支持向量机实现异常目标检测和定位[1]。该方法对整个视频序列进行处理,计算量较为庞大的同时引入噪声,影响异常目标准确判别。更多异常检测方法采用均匀分割和光流结合方法对视频序列进行时空兴趣块提取,仅对时空兴趣块进行处理从而完成视频异常检测任务,例如,Zhou Shifu等人将整个视频的时空兴趣块直接输入三维卷积神经网络(3D ConvNets,C3D)进行特征学习,解决视频异常行为检测和定位问题[2]。类似的Sabokrou Mohammad等人采用级联三维神经网络方法,由三维自动编码器检测出时空兴趣块送入C3D中进行训练完成视频异常快速检测和定位[3]。考虑到监控摄像头往往以俯瞰方式拍摄监控视频,距离摄像头较近物体在监控画面中处于靠下位置并占据较大面积,而距离摄像头较远物体以较小面积处于视频画面中靠上位置。研究人员采用非均匀分割及光流结合方法对视频序列进行前景提取,更大程度上保证每个兴趣块中包含更少种类更多信息[4]。尽管非均匀细胞分割已在较大程度上提高定位和识别准确率,然而在现实分块时往往难以保证将每个行为完整分割到不同时空兴趣块中或是每个时空兴趣块中仅包含一种行为,同时,这种分步式方法较费时繁琐,不适用于实际场景运用。Mahdyar Ravanbakhsh等人在不对视频序列进行分割情况下,通过生成式对抗网络(Generative Adversarial Nets, GAN)中生成模型和判别模型之间博弈实现监控视频中端对端无监督异常行为检测与定位。采用生成式对抗网络对正常场景帧图像和对应光流图训练得到场景正常行为内部表示,并在测试阶段将测试数据外观表示和运动表示与正常数据进行比较,由于异常区域无论是外观表示或是运动表示都异于正常数据,因此通过计算局部符合程度可以检测出异常区域[5]。本文将异常检测任务看作特殊目标检测任务进行处理,采用目标检测方法实现端对端视频监控异常目标检测与定位。
深度学习不仅提高了普通二维图像分类问题的准确率,也为目标检测领域提供新思路和方法。研究人员提出基于区域的卷积神经网络(Region-based Convolutional Neural Networks,R-CNN)目标检测方法大大提高了目标检测精度,该方法先采用选择性搜索获取候选区域,然后对每个候选区域采用深度卷积网络进行特征提取并进行SVM分类,从而得到一个初始检测结果,最后再次使用深度卷积网络特征结合SVM回归模型得到更精确边界框[6]。基于R-CNN,研究者提出快速R-CNN(Fast R-CNN),该方法不再对候选区域进行卷积而是对整个图像进行卷积,通过一个双任务网络结构实现候选区域分类和边界框拟合同步完成,该方法训练、测试时间是R-CNN的1/9[7]。R-CNN和Fast R-CNN都是采用选择搜索获得候选区域。因此,研究人员提出更快速R-CNN(Faster R-CNN)直接通过卷积神经网络实现候选区域生成,该方法由两个卷积神经网络组成,即:区域候选生成网络(Region Proposal Network, RPN)及实现候选区域分类和边框回归的Fast R-CNN,Faster R-CNN与Fast R-CNN相比将训练和测试时间缩短近10倍[8]。尽管R-CNN、Fast R-CNN以及Faster R-CNN将目标检测精度和速度提高到新水平,然而这几种方法都是单独实现候选区域生成,使得目标检测过程较为繁琐和费时。针对这一问题,研究人员提出YOLO(You Only Look Once),该方法摒弃生成候选区域中间步骤,将输入图像用均匀网格划分并在每个网格单元预测边界框,并通过卷积神经网络实现边界框回归以及类别预测,真正意义上实现判定识别一步式完成[9]。YOLO精简目标检测流程,在测试图像时可实现每秒45帧,相比之前方法速度有很大提升,但是YOLO边界框预测局限性较大,每个单元格仅可预测两个边界框一个判别类别。此外,由于YOLO采用多层卷积后的高级特征完成目标识别,因此检测精度不够理想,尤其是对于小目标检测。为此,文献[10]融合YOLO和Faster R-CNN目标检测思路,提出单次多目标检测(Single Shot multibox Detector, SSD),该算法引入预测卷积滤波器,在不同6个特征图上使用2组3×3卷积核分别做分类和边界框回归,同时允许从卷积神经网络不同特征层进行检测结果预测,小目标可由底层特征层实现预测,而较大目标可由高层特征层进行预测,如此可适应不同大小目标检测要求。
本文期望采用目标检测思路解决视频监控系统中异常目标检测与定位问题,提出端对端SSD实时视频监控异常目标检测与定位算法,使用迁移学习训练方法,对输入视频帧进行单一卷积神经网络训练,同步实现特征学习、行为分类以及异常目标定位。
1 端对端SSD实时视频监控异常目标检测与定位算法
当采用卷积神经网络进行特征学习时,不同卷积层可得到不同尺寸特征图,一般来说,底层特征图对于边缘信息更为敏感,可提供较为丰富细节信息,而高层特征图可提供较为丰富的语义信息,对于监控视频异常目标检测来说,异常目标种类多样,若使用多尺度特征在多种特征图上进行预测理论上可获得更好的检测效果。如图1所示,为更准确地对不同尺寸异常目标进行检测,本文使用SSD算法,在6个卷积特征图中采用3×3的卷积核进行异常目标检测:conv4_3,conv7,conv8_2,conv9_2,conv10_2以及conv11_2。以图1中Conv4_3为例,分类器:Conv:3×3×(4×(类别+4))表示采用3×3卷积核设置目标预选框,其中3×3表示卷积核大小,第一个4表示本特征图中每个像素点生成4个预选框(6表示本特征图中每个像素点生成6个预选框),第二个4表示预测框4个坐标。本文算法网络框图如图1所示,在传统VGG-16网络基础上,将原先全连接层fc6和fc7层改为卷积层,同时删除全连接层fc8以及所有Dropout层,并将Pool5从2×2池化改为3×3池化,分别在Conv7、Conv8_2、Conv9_2卷积层特征图上对每个像素点构造6个尺寸不同的预测边界框,分别在Conv4_3、Conv10_2、Conv11_2层卷积层特征图上对每个像素点构造4个尺寸不同的预测边界框,然后根据置信度得到其类别与置信度,且过滤掉属于背景的预测框,对置信度小于阈值0.5的预测框进行滤除,并对剩下的预测框进行原视频帧映射,以获得预测框真实的位置信息,再对置信度降序排列,并保留部分预测框进行非极大值抑制(Non-Maximum Suppression,NMS),遍历消除重叠及不准确边界框,得到最终异常目标检测结果。
1.1 匹配策略
在进行训练时,需在先验框和真实标签框之间实现匹配,为表述方便,这里将先验坐标框称为源框,并将能够与真实标签框相匹配的源框认作正样本,其余认作负样本。SSD训练匹配策略采用两种匹配方法,双向匹配和预测匹配。双向匹配是将每个真实标签框和与它有最大交并比(Intersection Over Union,IOU)的源框相匹配,这种方法确保每个真实标签框仅与一源框匹配。在进行预测匹配时,首先进行双向匹配,对于没有进行匹配的源框,将它们与任意真实标签框尝试匹配,若二者IOU值大于阈值(本文阈值设置为0.5),视为二者相匹配。预测匹配可为每个真实标签框生成更多正样本先验匹配,从而使网络具备预测多个重叠目标预选框高置信度能力。在进行匹配时,将源框视为不可知类,即并不考虑源框真实类别,并在匹配后,将匹配到的真实标签保留,用于置信损失计算。
显然,匹配之后负样本数量会远多于正样本,训练时会存在网络过于重视负样本问题,从而导致损失不够稳定,因此,采用难负样本挖掘方法,将目标候选框按照置信度得分进行排序,并挑选得分较高预选框进行训练将负样本和正样本比例调整在3∶1左右,以达到更好训练结果。
1.2 目标预选框生成规则
目标预选框是在不同特征图上施加一组(4~6个)特定大小、具有不同纵横比和尺寸边界框,图2中给出8×8网格特征图和4×4网格特征图目标预选框示例。本方法采用基础特征(1×1)预测每个目标预选框偏移量Δ(x1,y1,x2,y2)及对所有类别置信度(c1,c2,…,cp)。在训练阶段,将先验框(源框)与真实标签框进行匹配,如图2所示,将目标预选框与骑自行车和小车相匹配,一个被认作正样本,一个被认作负样本,然后,通过对定位损失和置信损失加权计算得到最终损失,并将误差反向传播。
SSD中预选框生成是以特征图中每个像素中点为中心,生成一系列同心预选框,并将这些预选框从特征图位置映射回原输入视频帧位置。若使用m个不同大小特征图进行预测预选框时,fk表示第k个特征图大小,其中k∈[1,m],则每个特征图预选框边长为
(1)
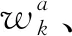
(2)
(3)
其中,αr表示纵横比,且αr∈{1,2,3,1/2,1/3}。当纵横比αr为1时,预选框大小为
(4)
即总共有6种不同预选框,预选框生成规则示例图如图2所示。若M×N特征图中每一像素点需预测q个目标预选框,且每个目标预选框需预测M×N×K个类别置信度及4(或6)个偏移量,则此特征图共预测M×N×K个目标预选框,且共有(q+4)M×N×K(或(q+6)M×N×K)个输出。本文所采用网络结构分别在卷积层Conv4_3、Conv7_2(fc7)、Conv8_2、Conv9_2、Conv10_2、Conv11_2特征图上进行异常目标检测,其中Conv7_2(fc7)、Conv8_2、Conv9_2进行目标预选框生成时每个像素点预测6个边界框,即生成6个偏移量,其余三层生成4个。因此在这6个卷积层特征图上分别获得38×38×4=5 776、19×19×6=2 116、10×10×6=600、5×5×6=150、3×3×4=36、1×1×4=4个目标预选框,整个网络共获得5 576+2 116+600+150+36+4=8 732个目标预选框。
1.3 损失函数
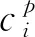
L(x,c,l,g)=Lconf(x,c)+αLloc(x,l,g),
(5)
其中,α为0.06,定位偏移损失Lloc为预测框坐标与真实标签框坐标之间l2范数:
(6)
本文算法采用多类逻辑损失作为类别置信度损失Lconf,其适用于每个类别相互独立但互不排斥的情况,可由下式计算:
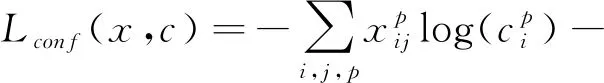
(7)
1.4 非极大值抑制
本文在多个卷积层特征图上进行异常目标检测与定位,会出现大量重叠或定位不准确边界框,采用设置IOU阈值方法可以滤除部分边界框,然而阈值过大会丢失部分检测目标产生目标漏检情况,阈值过小无法有效滤除重叠边界框。也就是说,仅依靠设置IOU阈值无法达到较为理想边界框过滤效果,因此采用非极大值抑制方法进行迭代优化以滤除IOU阈值方法无法滤除的边界框。
非极大值抑制通过置信度得分对局部最大值进行搜索,从而抑制非极大值。非极大值抑制过程如图3所示,首先将所有边界框按照置信度得分进行排序,并选取其中得分最高边界框,然后遍历其余边界框,计算当前被遍历框与当前得分最高框之间IOU值,示意图见图4,其定义式为
(8)
该值表示边界框和真实标签框重叠度,若IOU大于某一阈值,则将当前被遍历框抑制,再从未处理框中重新选择新得分最高框,如此迭代、遍历、消除。IOU值越大表示异常检测越准确,且IOU≤1,IOU值是边界框A与真实标签框B重叠面积占两者并集面积比值,即
(9)
2 实验仿真
本方法采用迁移学习方法进行训练,在已有模型的基础上进行新数据的训练,在进行匹配时,由已有模型的权重对新数据中的目标进行预选框生成从而和源框进行匹配,与重新进行训练相比,这种在已有模型进行训练的方法能够节约标签标注时间和精力,比随机生成的权重能够在更短的时间内得到更好的训练效果。首次模型训练时,迁移学习模型采用官方提供的预训练模型VGG_ILSVRC_16_layer_fc_reduced.caffemodel,之后采用首次训练得到的模型进行迁移学习训练。实验从UCSDPed1数据集14 000个视频帧中手动选取1 400帧进行标签标注,其中500帧用于网络测试,900帧用于网络训练,同时从UCSDPed2数据集4 560个视频帧中手动选取1 020帧用于网络训练,630帧用于网络测试。该方法能够保证通过较少训练数据达到适应性较强较为准确的异常目标检测与定位效果。由于对单个行人进行正常样本标注会导致正常样本数量远远大于异常样本,导致数据失衡从而无法得到较为有效异常检测效果,因此,本文对整个人群运动区域进行标注,在进行网络训练时,采用包括水平翻转、剪裁、放大在内多种数据增强方法,增加训练样本个数的同时构造多种形状大小的正常和异常目标,增加算法特征学习鲁棒性。
为评估异常检测有效性,本算法在行人数据集UCSD上采用不同评估准则与多种算法进行效果对比。
UCSD数据集包括两个子集Ped1和Ped2,分辨率分别为158×238、360×240,Ped1中包含34个用于训练的正常视频序列及36个用于测试含有异常的视频序列,每个视频序列帧长为200。Ped2包含16个用于训练的正常视频序列和12个用于测试的包含异常的视频序列,每个序列帧长120到170不等。UCSD数据集中训练样本只含正常行为即正常的行人,测试集中的某一帧中可能不存在、存在一个或多个异常行为,其中异常类型主要有:自行车、滑板、小型汽车,轮椅等。Ped1中的物体分辨率较低给识别造成一定的难度而Ped2中的遮挡问题比较严重,因此,UCSD是一个具有挑战性的拥挤场景下局部异常数据集。
实验采用的异常检测评估标准是受试者工作特征( Receiver Operating Characteristic, ROC)曲线、曲线下的等误差率(Equal Error Rate, EER)和曲线下的面积(Area Under Curve, AUC)。EER是ROC曲线上假阳性率(False Positive Rate, FPR)与假阴性率(False Negative Rate, FNR)相等的点即ROC曲线与ROC空间中对角线([0,1]-[1,0]连线)的交点。ROC曲线下EER越小AUC越大,表明算法性能越好。基于ROC曲线的评估标准分为3个级别:帧级准则,像素级准则及双像素级准则。帧级准则中,若检测出某一帧至少含有一个异常行为则记为异常帧。像素级准则中,若某一帧中所有真实异常行为所在像素块的40%以上被正确检测到,则视为异常帧。双像素级准则中若某帧被视为异常帧需满足:①此帧满足像素级准则标准;②被检测为异常的区域至少β%(本文采用10%)真实标签为异常[10]。这一准则不仅要求在时间和空间上对异常进行准确的检测和定位,对于假阳性错判也十分敏感。
在UCSDPed2中异常检测效果如图5所示,在UCSDPed1中异常检测效果如图6所示,其中框的左上角显示normal表示运动活动区域,显示abnormal表示异常所在位置,由图可见,本文算法对于UCSD数据集中的自行车、小型汽车、滑板等异常目标皆能做出较为准确的异常检测,同时得到的异常目标边界框较传统的分块方法如S-TCNN[2]更为适应,定位也更为精准。
帧级与像素级准则下对UCSD 数据集中异常检测效果同已有优秀方法比较如表1所示,Ped1中帧级准则EER为26.88%,与同样满足实时性异常检测的Binary Feature[17]相比仅落后1.54%,而在更严格的像素级准则下EER为30.21%,优于Binary Feature[17]17.89%,表明本算法在实现异常目标实时性检测与定位的同时能够实现较为准确的检测。Ped2中帧级准则下,EER仅落后Cascade DNN[3]3.6%,优于GAN[5]0.0381,像素级准则下EER为13.81%,分别优于OCELM[13]3.19%,优于Cascade DNN[3]5.19%,AUC为0.897 2优于S-T CNN[2]0.037 2,优于OCELM[13]0.096 2,显然本方法与近几年经典方法相比检测效果同样具有优越性。在Ped2帧级和像素级准则下,本算法与满足实时性检测的Binary Feature[17]方法相比,检测效果具有明显的优越性,表明本方法对于视频帧画面更为清晰,异常目标尺寸更大且人群走向为水平方向的Ped2视频场景能够实现实时性、较为准确的异常目标检测及定位。
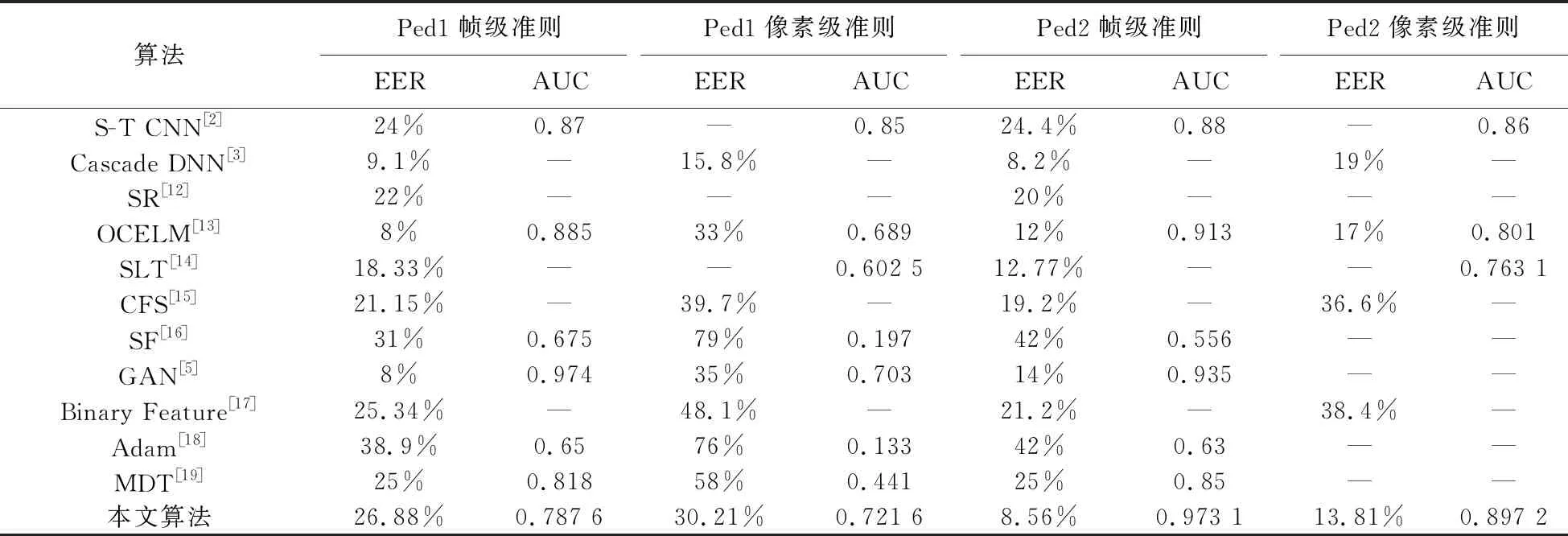
表1 UCSD中帧级和像素级EER、AUC比较Tab.1 EER and AUC for frame and pixel level comparisons on UCSD
双像素准则下,实验效果比较如表2所示。Ped1中EER是31.1%,落后Cascade DNN[3]6.6%,在Ped2中EER是14.09%,优于Cascade DNN[3]9.71%,优于Mohammad Sabokrou[11]13.41%,表明本方法在准确检测出异常行为的同时对正常行为误判概率也较低。
本算法在不同准则下ROC曲线图如图7所示,由图明显得出,本算法在Ped2中的效果优于Ped1,原因有以下几点: 1) Ped 2中帧图像尺寸更大,像素更高,目标尺寸也相对更大,对于特征学习更有利;2) Ped 2与Ped 1场景中人群走向不同,相对来说Ped 2中人群水平移动对于目标学习更有利;3) Ped 1中异常情况较Ped 2更为复杂,在进行训练时对于异常目标学习困难更大。
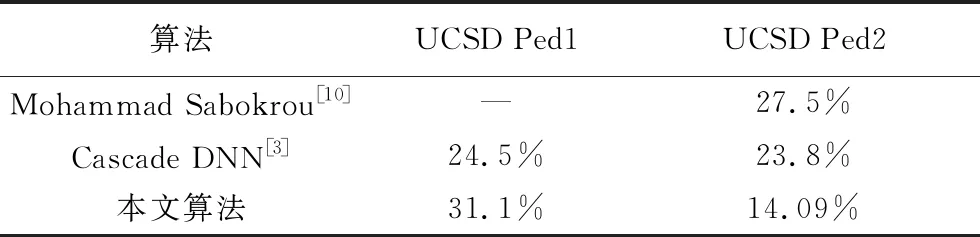
表2 UCSD Ped1、Ped2中双像素级EER比较Tab.2 EER for dual pixel level comparisons on UCSD Ped1 and Ped2
本算法在UCSD数据集中实时性对比如表3所示,SSD算法在训练时统一处理输入视频帧为299×299,因此本算法在UCSDPed1和Ped2中实时性效果一致,每秒可处理58帧视频,即每帧视频处理时间为0.017秒,实时性能力较其他算法具有明显优越性。本方法在Ped1中像素级准则下检测效果优于MDT[19],CFS[15],Binary Feature[17],OCELM[13],实时性较以上方法也具有优越性,在Ped2帧级及像素级准则下检测效果皆优于MDT[19],S-TCNN[2],C-DNN[3],CFS[15],Binary Feature[17],OCELM[13],且实时性也具有明显优越性。因此,本方法在满足实时性检测的同时能够实现较为准确的监控视频异常目标检测与定位。

表3 UCSD数据集运行时间比较
3 结论
本文提出端对端SSD实时监控视频异常目标检测与定位算法,借鉴目标检测思路,实现复杂场景下端对端实时视频异常检测。算法不再单独使用RPN网络实现目标检测,而是在不同6个卷积特征图上采用2组3×3卷积核实现异常分类和异常目标定位。这种从CNN不同特征层进行异常目标检测和定位方法,不仅简化异常目标检测流程,节约异常检测时间,同时从不同尺度对目标进行学习可适应不同大小目标检测要求。最后采用非极大值抑制方法对于大量存在重叠边界框进行有效剔除,得到异常目标在视频帧中的准确定位,该算法每帧可处理近58帧视频,满足异常检测实时性需求。
