改进型支持度函数的WSN 水质监测数据融合方法
2020-10-21季云峰平震宇陈北京
匡 亮,施 珮,季云峰,平震宇,陈北京
(1. 江苏信息职业技术学院物联网工程学院,无锡 214153;2. 南京信息工程大学计算机与软件学院,南京 210044;3. 中国水产科学研究院淡水渔业研究中心,农业部淡水渔业和种质资源利用重点实验室,无锡 214081;4. 江南大学物联网工程学院,无锡 214122)
0 引 言
无线传感器网络(Wireless Sensor Networks,WSN)以其灵活的部署、低成本,小体积等优势被广泛应用于军事侦察、工业监测、农业监测和医疗监控等各个领域[1-7]。在水质监测中,通过部署传感器节点来收集水质数据,实现监测区域内水质参数的实时监控。然而,当监测区域较大时,由于监测区域中水质参数值分布不均匀的问题,使得单一位置的监测数据不能很好的体现整个监测区域的真实情况[8]。同时,传感器网络中数据的丢失、异常情况时有发生[9],而水下环境的复杂性增加了异常情况处理的难度。为了实现水质的准确监测,保障数据的准确性和可靠性,正确评估水体实际情况,需要利用数据融合技术对不同位置的传感器数据进行融合,从而提高水质监测系统的鲁棒性。
数据融合可以有效地减少数据冗余、提高数据质量[10-12]。基于不同理论的数据融合方法在使用过程中会呈现各自的局限性[13-14]。目前较为常用的数据融合方法包括统计型算法、人工智能型算法和信息论型算法等。以贝叶斯理论为代表的统计类算法需要在融合多传感器数据之前获取先验知识和概率分布来计算传感器的可靠性[15]。以人工神经网络(Artificial Neural Networks,ANN)为代表的人工智能型算法可以处理不清楚、不确定的非线性系统的问题,但复杂的结构和随机参数会导致融合结果不稳定[16]。基于支持度函数的融合算法是典型的信息论型算法,该方法能够获得数据间的关系,避免不可信数据对融合结果产生的不良影响[17]。国内外学者已经对支持度函数的数据融合算法展开了深入地研究。Luo等[18]提出一种支持度函数,它利用置信概率距离来表征数据间支持度值,从而构建数据的关联矩阵完成数据融合。然而这种支持度函数需要进行积分运算,函数计算量较大。罗本成等[19]基于肖维涅统计思想构建的支持度函数,依据设置好的传感器数据偏差的阈值来计算传感器一致性矩阵。该支持度函数在计算时依赖于人为设置的阈值,数据融合误差不稳定。Yager[20]利用指数衰减型支持度函数获取传感数据间的支持度矩阵,再通过幂均方加权计算数据融合结果。该方法能够有效地避免支持度函数非1 即0 的绝对性问题,但指数衰减型支持度函数在参数的设置和计算复杂度上还有待改进。熊迎军等[21]运用灰色系统接近度思想提出了一种改进指数衰减型支持度函数。该算法不能对时间序列型数据进行分析,数据融合过程忽略了数据在时间上的特征。段青玲等[22]对指数衰减型支持度函数进行了改进,然而该算法在实际应用中的融合精度有待提高。
针对上述支持度函数融合算法存在的问题,本研究提出一种基于改进的动态时间弯曲距离支持度函数(Improved Dynamic Time Warping Distance Optimized Support Function,IDTW-SF)的加权融合算法。利用灰关联分析理论改进传统指数衰减型支持度函数中的指数运算,降低指数运算复杂度。同时,改变单一时刻点支持度的计算为时间段内支持度的计算,并利用动态时间弯曲距离(Dynamic Time Warping Distance,DTW)算法度量时间段内互支持度值。再通过时间分割策略来降低算法复杂度,从而实现WSN 水质数据的融合。
1 WSN 数据融合算法
由于同类传感器不同位置感知数据在时间和空间上的相关性,本研究在无线传感网络水质监测系统中,采用数据融合机制来提高数据质量,其主要步骤包括:
1)通过数据的一致性检测操作对感知的原始数据进行检测,在检测离群值的基础上对丢失数据进行重新构建,获得新的数据集。
2)当无线传感网络中某个传感器发生故障时,利用基于IDTW-SF 支持度函数的数据融合算法对故障传感器的异常数据进行融合校正。其融合过程如图 1 所示,N个传感器节点采集的数据经过一致性检测后构成数据集X={X1,X2, …,XN}。若传感器1 为故障传感器,则系统利用融合机制将传感器节点X2= {x21,x22,…,x2t},X3= {x31,x32,…,x3t}和XN= {xN1,xN2,…,xNt}进行处理,并获取融合数据X1’,其中t为采集时刻。
3)基于融合机制的水质监测系统使用融合结果X1’来替换故障传感器1 中的数据X1,从而提高数据质量,为后续的数据分析和监测提供更可靠的信息。
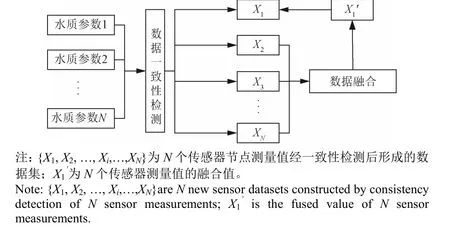
图1 水质监测系统数据融合流程Fig.1 Process of data fusion in water quality monitoring
1.1 数据的一致性检测
在水质监测中,传感器在水下受到的影响因素远比在空气中多。复杂的影响因素使得传感器更易发生故障和传输错误。对于传输中丢失的数据,采用线性插值法[23]对这些数据进行修补。同时,利用自滑动移动平均模型( Model Average Moving Integrated Autoregressive ,ARIMA)[24]实现感知数据的一致性检测,其主要步骤包括:
1)首先对水质参数时间序列数据间的相关性进行分析,测试各感知数据Xi的稳定性,本研究以水体溶解氧浓度为例。
2)确定ARIMA 模型的自回归阶数p和移动平均阶数q,基于设定的参数构建最优ARIMA 模型。
3)利用确定的ARIMA 模型获取判定数据异常的置信区间PI,如式(1)所示

式中oi(t)为t时刻的传感器感知数据,xi(t)为 ARIMA 模型的预测值,C为代价函数[25]。式(2)为预测值x的PI预测区间。
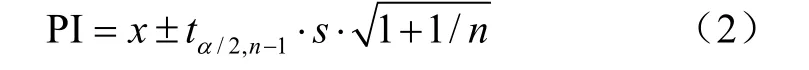
式中n是样本大小,s为标准偏差,t分布为遵循自由度为(n-1)的分布函数。
1.2 改进支持度函数
1.2.1 支持度函数
基于支持度函数(Support Function,SF)的融合算法是一种使用较为广泛的数据融合算法。它能够有效地获取数据间的潜在关系,进而获得数据间的支持度。支持度函数即sup(a,b),用于表征两元素a和b之间的接近程度[26]。当进行数据融合时,可信度高的数据拥有高的权值,可信度低的数据则拥有低的权值。
目前,较为常用的支持度函数为高斯型支持度函数(Gaussian support function,G),也可称作为指数衰减型支持度函数[20,27],如式(3)所示
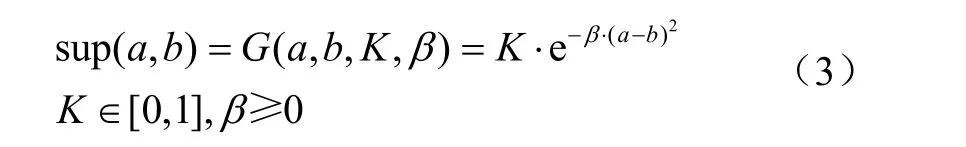
式中K为函数的振幅,β为函数的衰减系数。当两元素间接近程度越高时,函数的支持度值也越高。当a=b时,sup(a,b)= K。即,a、b间差距越大,则sup(a,b)越趋近于0。
由于该支持度函数具有对称性,且运算过程是基于指数运算,故sup(a,b)的计算也相对复杂和耗时。刘思峰等[28]利用灰色关联分析理论表达两元素间的接近程度,即支持度。本研究在这种思想的基础上提出一种支持度函数,对高斯型支持度函数进行改进,从而降低函数的计算复杂度,其函数表达式如式(4)所示
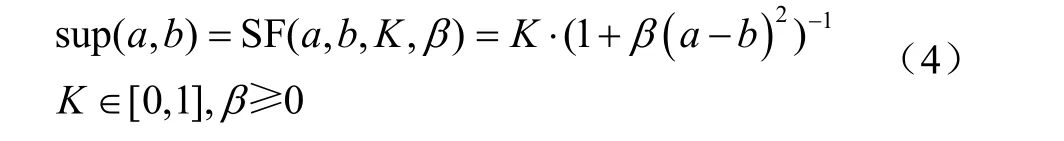
水质监测中,同一深度的溶解氧浓度的数据差异<2 mg/L,即(a–b)∈[–2, 2]。则本研究所提出的支持度函数 SF(a,b,K,β)其特性曲线如图 2 所示。(a–b)为不同溶解氧传感器感知数据的差值。为了更有效地获取数值间偏差影响,体现各信息权重对支持度的影响,本研究中确定参数K=1,β=3。
图 2 显示,G(a,b,1,3)、D(a,b,1,3)[21]、SN(a,b,1,3)[22]和 SF(a,b,1,3)分别表示各支持度函数的特性曲线,且当(a–b)∈[–1, 1]时,SF(a,b,1,3)能够更好的接近G(a,b,1,3)。事实上,在水质监测中,溶解氧浓度的差异值大多数集中在[−1,1]。在水质监测中使用本研究提出的支持度函数SF(a,b,1,3)能够较好地反映传感网络数据之间的关系。
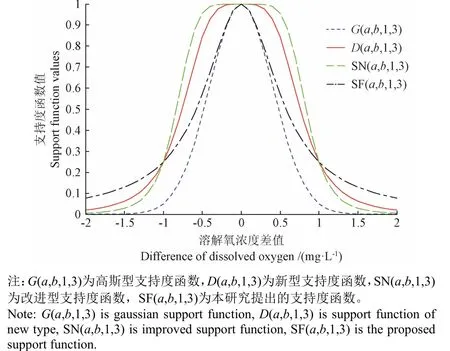
图2 不同支持度函数特性曲线Fig.2 Characteristic curve of different support functions
1.2.2 动态弯曲距离改进支持度函数
在高斯型支持度函数中,t时刻2 个元素间的接近程度为sup(a,b),其表达式如式(3)所示。然而在处理时间序列数据时,会丢失数据前后之间的关联信息。考虑到水质参数序列数据在时间上的连续性,本研究对 2 个时间序列U和V之间的接近程度进行分析,完成时间序列间接近程度sup(U,V)的度量,从而提出基于时间序列的动态弯曲距离改进的支持度函数(DTW-SF)。DTW 是一种广泛用于度量时间序列之间相似性的算法之一[29]。本研究选择DTW 来度量2 个序列数据之间的接近程度,结合SF 支持度函数,从而获得DTW-SF 支持度函数,其表达式如式(5)所示
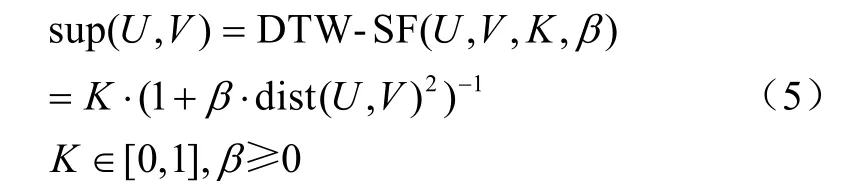
式中 dist 表征时间序列U= {u1,u2, …,up, … ,um}(1≤p≤m)和序列V= {v1,v2, …,vq, …,vn} (1≤q≤n)的动态弯曲距离,m和n分别为序列的维数。S(U, V)表征2 个时间序列的相似度,即dist 距离,其表达式如式(6)所示
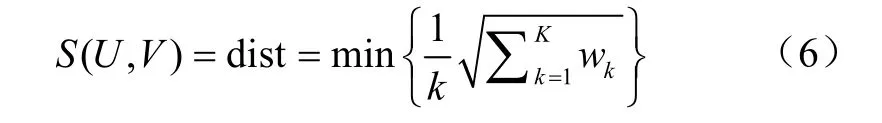
式中w= {w1,w2, ...,wk}为DTW 中的规整路径,wk为w中的第k个元素;dpq=(up-vq)2。为了获得最小路径距离,定义dist 为累加距离,dist(U, V)为当前格点dpq距离的总和[30]。
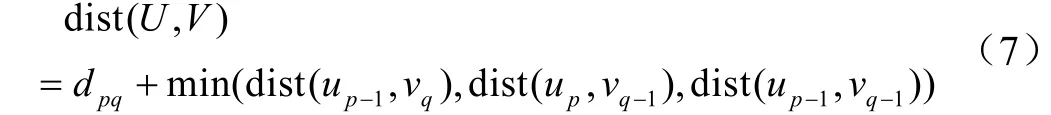
1.2.3 优化的动态弯曲距离改进支持度函数
在传统DTW 中,使用较为常见的欧氏距离来测量m维空间中两点间距离。然而水质数据时间序列的相似度测量具有时间连续性,单纯采用欧式距离度量各维度数据的相似性往往会忽视各维度之间的内在相关性,故本研究选择马氏距离替代欧式距离来改进DTW 算法。同时,DTW算法的复杂度较高,故引入时间序列分割策略[31],从而降低DTW 算法的时间复杂度,提高运算效率。通过该分割策略,将两个时间序列划分为若干子序列,完成时间序列的分割,并构建优化的动态弯曲距离改进的支持度函数(IDTW-SF)。
在IDTW-SF 支持度函数中,设置分割时间序列长度T=L。则在时间T内,由式(7)可得时间序列U(T) 和V(T)之间的支持度函数,其表述式如式(8)所示
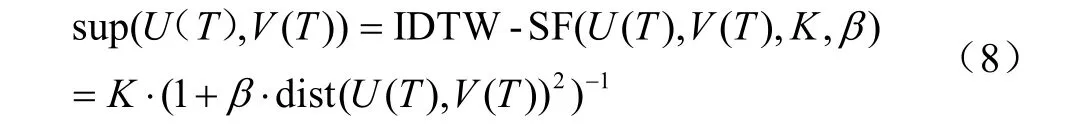
1.3 基于优化的动态弯曲距离改进支持度函数的WSN 数据融合
在水质监测中,溶解氧传感器的感知数据经过一致性检测后构成Xi。在时间间隔T内,可得传感器i和传感器j的数据分别Xi(T)和Xj(T)(i,j∈{1,2,…,N}),传感器间的相互支持度sij可表达为式(9)所示
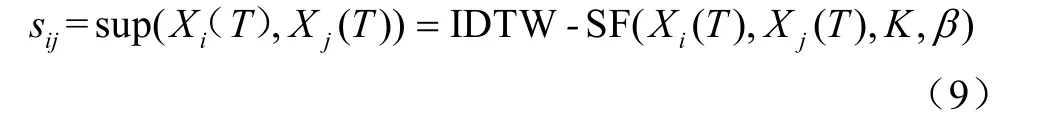
由此可获得各传感器之间的相互支持度矩阵如式(10)所示
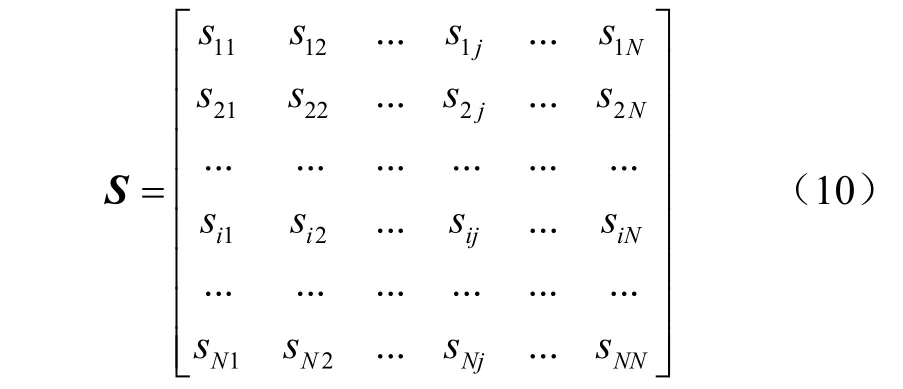
则在N个传感器组成的传感器组中,T时间间隔内的N-1 个传感器对传感器i的支持度之和如式(11)所示
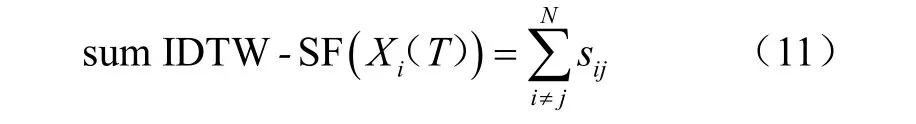
利用加权融合算法,则传感器i的融合估计值如式(12)所示

2 试验与分析
2.1 数据来源
本研究以江苏省无锡市南泉养殖基地试验池塘水质监测系统采集的溶解氧数据为试验对象,获取2017 年5月 24 日至 2017 年 5 月 29 日 6 d 的溶解氧数据。图 3a 所示试验池塘长80 m,宽50 m。根据养殖专家的经验分别在池塘的不同位置部署 5 个溶解氧传感器和增氧机。它们的部署深度相同,均位于水下 0.6 m 处,其位置分布(图 3)。其中,1 号传感器数据控制1 号、2 号和3 号增氧机,2 号传感器数据控制4 号增氧机,5 号传感器数据控制 5 号增氧机。当某一传感器发生故障时,系统则通过数据融合机制对其余传感器的数据进行融合,获取高质量的融合数据。各传感器节点每10 min 采样数据,共计 864 个数据点。所有数据经网关发送至上位机存储,并供后台数据处理软件进行分析处理。
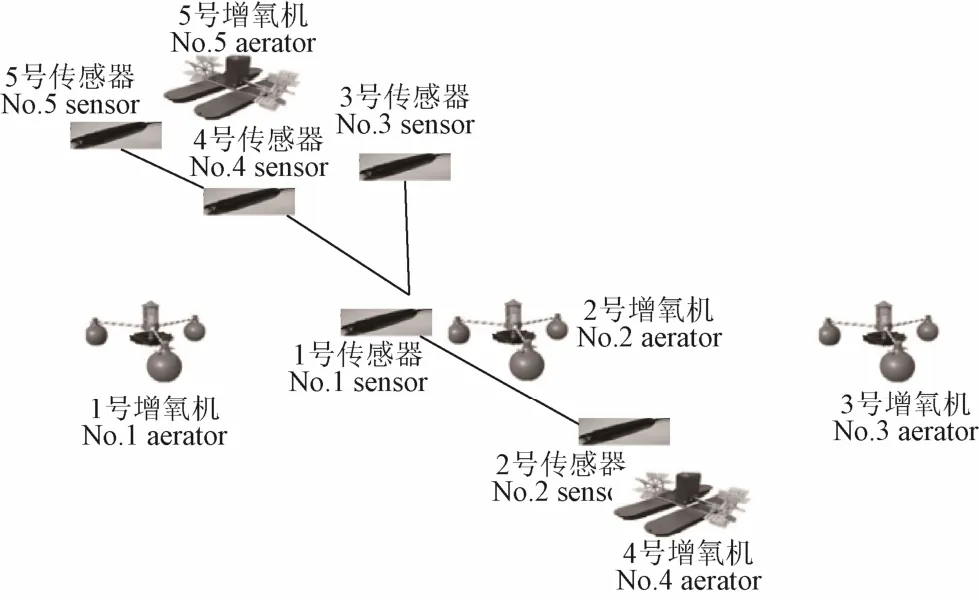
Fig.3 养殖池塘的水质监测设备部署图Fig.3 Deployment diagram of water quality monitoring devices in the aquaculture pond
2.2 一致性检测分析与时间序列分割
本研究使用ARIMA 完成864 个样本数据的一致性检测,其中异常数据共35 个,丢失数据16 个。通过仿真试验对样本数据进行测试,设置置信区间为 95%,获得样本数据的异常检测率(Detection Rate,DR,%)为94.29%。其中,异常检测率 DR=TP·100%/(TP+FN);正确率(True Positive,TP,%)为异常数据被正确检测出的个数;准确率(False Negative,FN,%)为异常数据被错误检测的个数。本研究中所有试验程序均在MATLAB 2014a 环境下上运行和实现,计算机操作系统为Windows 10 (64 bit),运行内存为16 GB,CPU 频率为2.7 GHz。
本研究选择平均绝对误差(Mean Absolute Error,MAE)和运行时间(Time,s)作为数据融合算法性能评估的指标。6 d 内基于IDTWS-SF 支持度函数的融合算法的性能结果(图4)。
如图4 所示,6 d 内IDTWS-SF 的融合精度MAE 值随着分割长度的不断增大无明显变化,处于较稳定状态。而运行时间参数随着分割长度的不断增大几乎呈线性变化趋势。由此可见,分割长度对融合精度MAE 值的影响较小,对算法运行时间有较大的影响。即分割长度越小,IDTWS-SF 支持度函数的综合性能越好。综上所述,本研究确定时间序列的分割长度L=2。
2.3 结果与分析
2.3.1 支持度函数性能分析
基于上述参数设置情况,使用基于 IDTWS-SF 支持度函数的加权融合算法对水质参数数据进行融合,本研究以溶解氧浓度为例进行试验。6 d 内溶解氧浓度的融合输出曲线如图5 所示,IDTWS-SF 支持度函数融合输出值能较好的拟合观测值,6 d 内融合值曲线与观测值曲线较为一致,无明显的融合异常情况。图6 为IDTWS-SF 支持度函数加权融合算法的融合误差率,图中所有测试样本的融合误差率均低于 0.25,且大部分样本点的融合误差率低于0.05。试验结果证明,该算法有较好的融合效果,能有效地实现水质参数溶解氧浓度的多传感器数据融合。
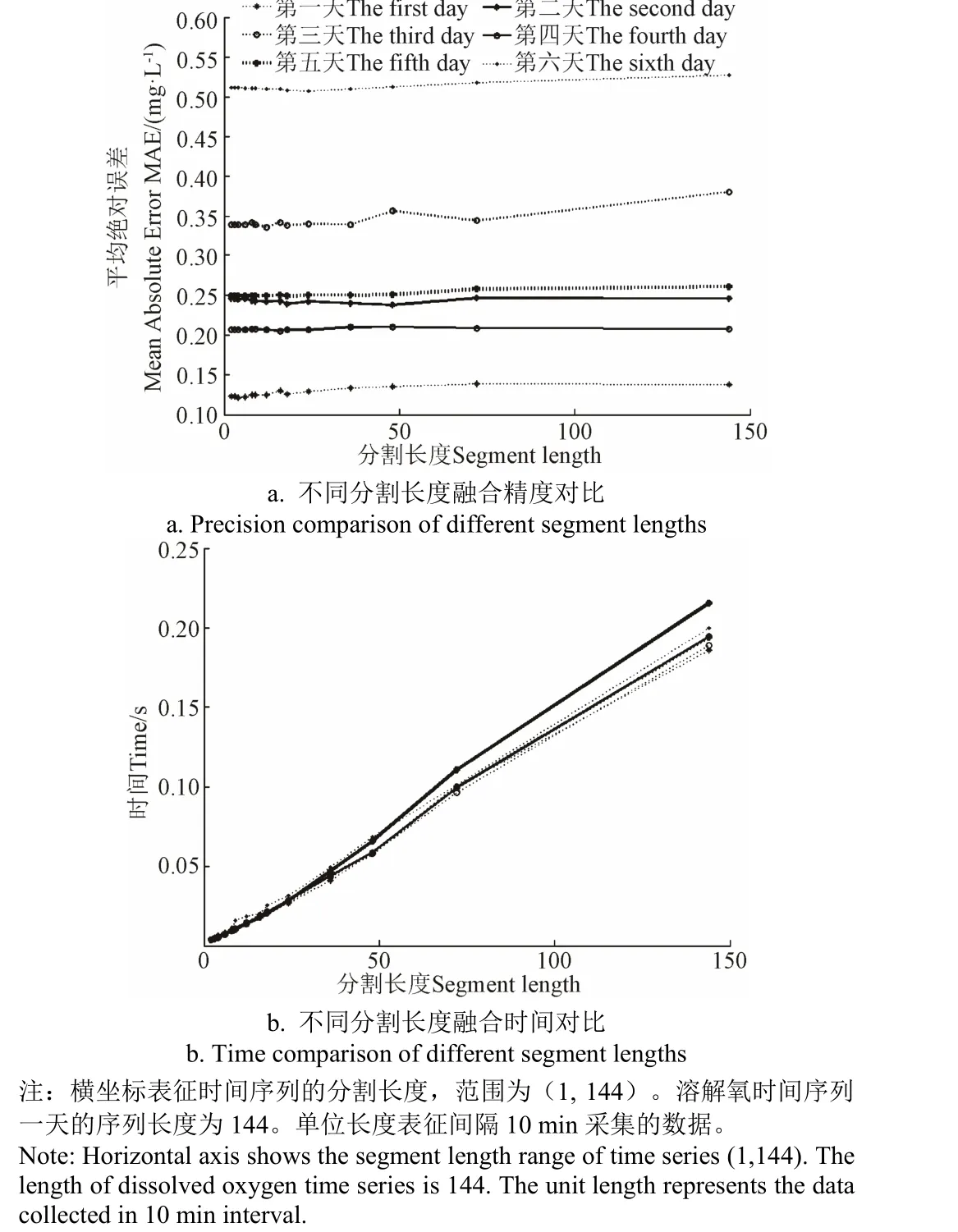
图4 优化的动态弯曲距离改进支持度函数六天内不同分割长度融合性能对比图Fig.4 Performance comparison of IDTWS-SF with different segment lengths in six days
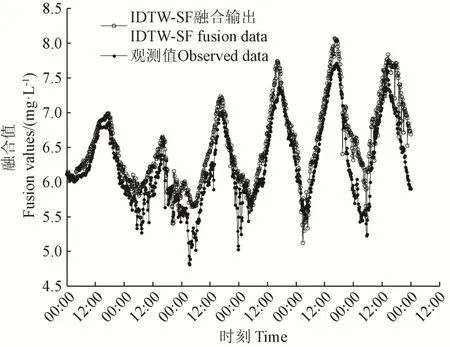
图5 优化的动态弯曲距离改进支持度函数加权融合结果Fig.5 Results of IDTWS-SF support degree function weighted fusion
为了有效地评估IDTW 算法对支持度函数SF 的改进效果,分别选择SF 支持度函数、余弦夹角[32]改进SF 支持度函数(Cosine Angle Improved SF Function, Cos-SF)、传统DTW 改进SF 支持度函数进行对比试验。对6 d 内的水质参数溶解氧浓度的融合残差值进行对比,融合残差结果(图7)。
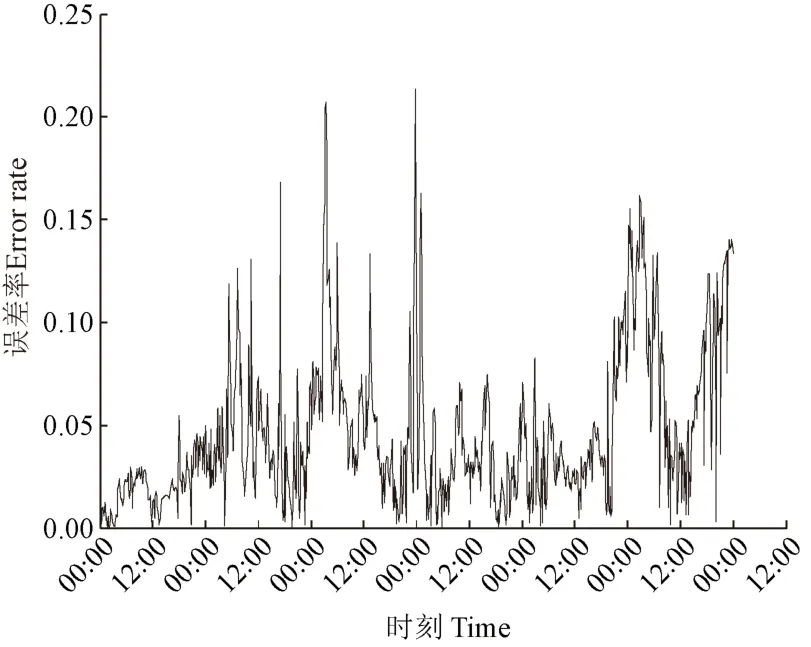
图6 优化的动态弯曲距离改进支持度函数融合误差率Fig.6 Fusion error rate of IDTWS-SF
图7 为不同的改进SF 支持度函数的加权融合算法的融合残差结果对比图。通过观察这4 种支持度函数融合算法的残差曲线的浮动范围可以发现,6 d 内测试数据集中Cos-SF 支持度函数融合算法的残差浮动范围明显大于其他3 个支持度函数。SF、DTW-SF 和IDTW-SF 3 种支持度函数的融合残差浮动情况较为接近。为了更好地对4 种支持度算法的性能进行对比分析,对支持度函数融合精度指标MAE 和时间进行计算,各支持度函数融合结果(表1)。
表1 显示IDTW-SF 支持度函数加权融合算法的性能明显优于其他3 个支持度函数融合算法。就MAE 指标而言,IDTW-SF 的MAE 值相较于DTW-SF、Cos-SF 和SF分别降低了6.308 7%、54.214 5%和16.306 9%。由此可见,改进的DTW 方法能够有效地提高支持度函数的融合精度。在运行时间上,IDTW-SF 比DTW-SF 快3.576 s,相较于Cos-SF 和SF 支持度函数融合算法仅慢0.001 1 s和0.003 5 s,运行速度相差很小。
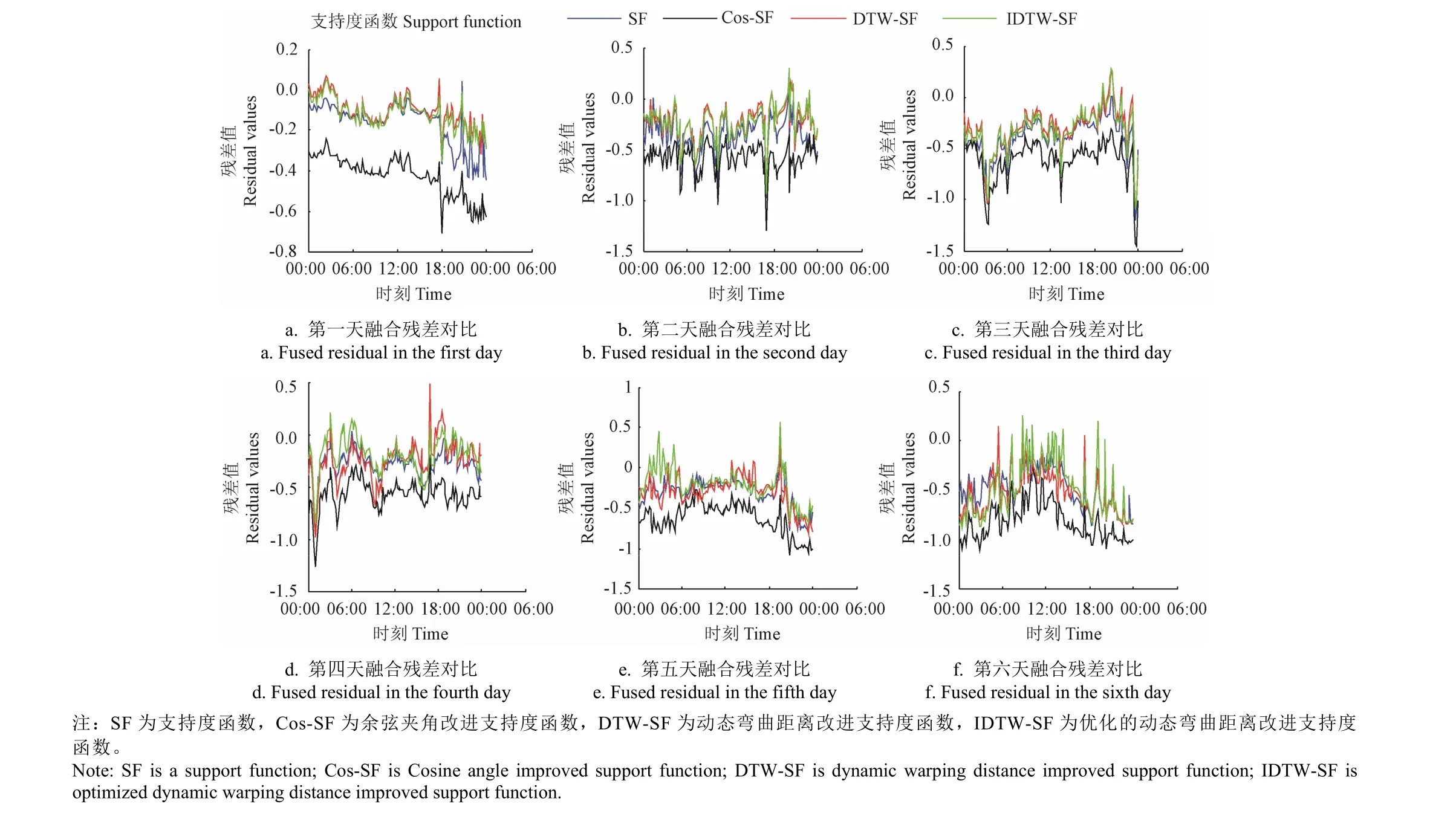
图7 不同的改进支持度函数SF 的融合残差对比图Fig.7 Comparison of different optimized SF support degree functions for fused residual
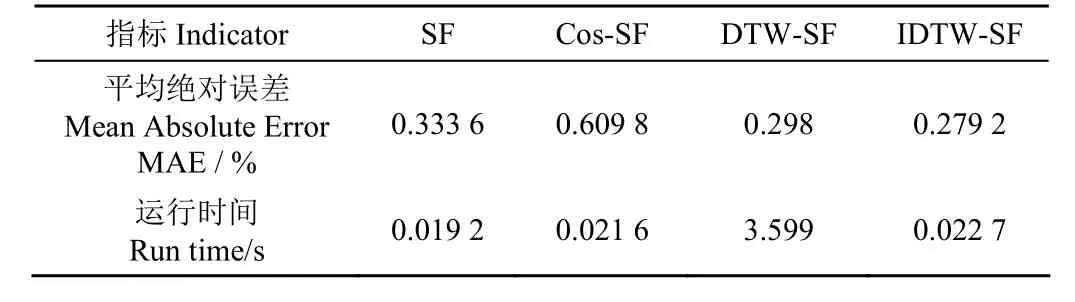
表1 不同的改进SF 支持度函数算法的融合结果Table 1 Weighted fusion results of different optimized support degree functions
DTW-SF 与Cos-SF、SF 支持度函数融合结果的对比试验发现,DTW-SF 支持度函数有较高的MAE 值。这一结果表明,DTW 比余弦距离和欧式距离更适用于度量时间序列间的支持度,它与 SF 支持度函数的结合能够有效的提高融合精度。而马氏距离和时间分割策略改进的 DTW 算法,不仅提高算法的融合精度,而且保障了算法的运行效率。综合融合精度和效率两方面考虑,IDTW-SF 支持度函数更适用于水质监测数据的融合。
2.3.2 不同的支持度函数融合结果分析
为了深入评估本研究提出的IDTW-SF 支持度融合算法的效果,选择高斯型支持度函数G函数[20]、改进支持度函数D函数[21]、改进支持度函数SN 函数[22]3 种支持度函数作为对比函数。将6 d 内4 种支持度函数的溶解氧融合结果残差值进行对比分析(图8)。
图8 为4 种支持度函数的加权融合结果的残差对比图。通过观察 4 种支持度函数融合算法的残差曲线浮动范围可以发现,尽管IDTW-SF 支持度函数的融合残差值的浮动范围比其他 3 个支持度函数大,但其残差值更接近0。结果表明,该算法的融合值与实际值差异更小。其他 3 个支持度函数融合残差浮动范围则较为接近,无明显的差异度。为了深入分析各支持度函数性能,将指标MAE 和运行时间作为评价指标,获得如表2 所示的支持度函数融合性能结果。
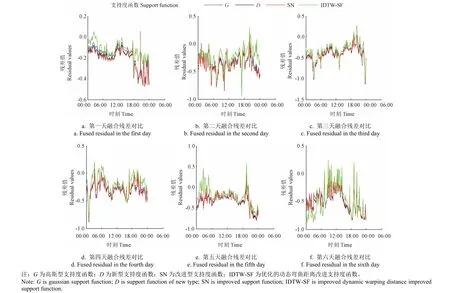
图8 4 种支持度函数融合残差对比图Fig.8 Comparison of four support degree functions for fused residual
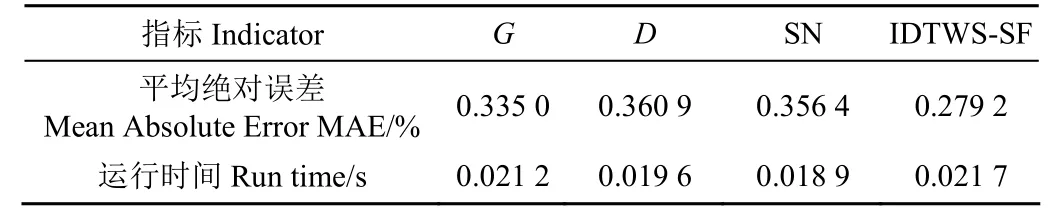
表2 四种支持度函数的融合性能对比Table 2 Weighted fusion results of four support degree functions
由表2 可以清楚地发现,相较于其他3 种支持度函数,IDTWS-SF 的融合性能有明显的优势。就MAE 值而言,IDTWS-SF 相较于G函数、D函数和SN 函数分别降低了16.656 7%、22.637 9%和21.661 1%。在算法运行速度上,IDTWS-SF 比G函数、D函数和SN 函数分别多耗时0.000 5、0.002 1 和0.002 8 s,运行时间差异较小。D函数和 SN 函数均为高斯支持度函数改进后的支持度函数。2 种支持度函数的融合运行时间比高斯函数快0.001 6和0.002 3 s,在融合精度上差异较小。
上述结果表明,将改进的DTW 算法引入到SF 支持度函数中可以有效地提高加权融合算法的融合性能。基于型支持度函数 IDTWS-SF 的数据融合算法拥有较好的融合性能,更适用于实际的水质监测。
3 结 论
针对水质监测系统对多传感器数据融合的高精度、快速响应要求,本研究提出一种采用IDTW-SF (Improved Dynamic Time Warping Distance Optimized Support Function)支持度函数的数据融合算法。该支持度函数在改进传统指数衰减支持度函数的基础上,对时间段内传感数据间互支持度进行计算。IDTW-SF 无需自行设定阈值,能够有效的避免传统支持度函数非1 即0 的问题。在IDTW-SF 中,DTW 算法对SF 函数的改进能够有效地获取时间序列数据在时间上的关联性。同时,引入的马氏距离和时间序列分割策略能够降低 DTW 算法的复杂度,提高算法的融合精度。基于IDTW-SF 支持度函数融合算法有较高的融合精度,其融合平均绝对误差值为0.279 2%。算法的运算效率较高,运行时间仅0.021 2 s。本研究以江苏省无锡市南泉养殖基地试验池塘水质参数为试验对象,对引起鱼类异常死亡重要因素之一的溶解氧数据进行融合,结果表明IDTW-SF 支持度函数的融合效果相较于指数衰减型支持度函数和其他对比的支持度函数有较大程度的提高,能够应用于无线传感网络水质监测系统中,对提高鱼类存活效率,降低渔民养殖风险有重要意义。
