龙芯KVM虚拟机I/O中断子系统的优化①
2020-10-19毛碧波
朱 琛 王 剑 高 翔 毛碧波 李 星
(*计算机体系结构国家重点实验室(中国科学院计算技术研究所) 北京 100190)(**中国科学院计算技术研究所 北京 100190)(***中国科学院大学 北京 100049)(****龙芯中科技术有限公司 北京 100190)
0 引 言
随着CPU硬件辅助虚拟化技术的成熟,虚拟机技术得到了广泛的应用[1,2]。KVM(kernel-based virtual machine)是一种主流的基于Linux内核的虚拟机监控器(virtual machine monitor, VMM),有着优秀的可管理性和性能。配合CPU的硬件辅助虚拟化技术,在运算、访存密集型的应用中,能够达到宿主机相近的性能,是目前云计算使用的主流方案之一。在KVM虚拟机中,I/O(input/output)虚拟化目前应用最广泛的方式仍是不依赖硬件辅助的软件模拟。在I/O中断密集的场景中,软件模拟的I/O中断子系统成为影响虚拟机性能的瓶颈。本文以龙芯KVM虚拟机[3,4]为例介绍了虚拟I/O中断子系统的原理,对虚拟I/O中断子系统的性能瓶颈进行了分析,除了采用常规方式优化外,还在此基础上尝试使用多种手段对其性能进行进一步的优化,取得了较好的优化效果。
本文的内容如下:第1节以龙芯的GS464E[5]高性能CPU核为例介绍了I/O虚拟化和I/O中断虚拟化的基本原理。第2节分析了I/O中断子系统的性能瓶颈。第3节介绍了其他架构常用的优化方法,并对其进行了验证。第4节在常规优化方法的基础上进行了进一步的优化,并对效果进行了初步评估。第5节选择部分I/O中断密集的磁盘、网络测试项,验证了优化的效果。最后在第6节进行了总结。
1 背景
1.1 软件I/O虚拟化
I/O虚拟化指的是外设相关的虚拟化,因为从CPU的角度来看,外设是通过一组I/O寄存器来访问的[6]。I/O虚拟化的实质是虚拟机通过VMM构建的虚拟设备(以下简称VDEV)复用有限的宿主机外设资源。虚拟设备为虚拟机模拟真实外设访问的效果,其本身又是宿主机外设驱动程序的一个客户端,可以通过宿主机操作系统提供的API访问真实物理外设,实现对真实外设的复用[7]。
I/O虚拟化以CPU虚拟化技术为基础。以龙芯GS464E为例,该处理器有4种运行状态,即根模式用户态、根模式内核态、客模式用户态、客模式内核态。其中客模式的2个状态是专为虚拟化新增的。4种状态在一定条件下会相互转化,虚拟机在客模式运行,在执行部分特权指令和触发特定异常的情况下会发生例外陷入根模式内核态,其状态机如图1所示[8]。
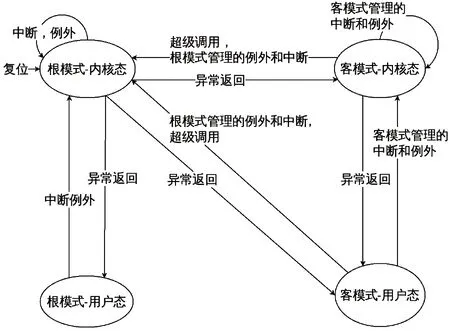
图1 GS464E 模式状态机
虚拟机在宿主机操作系统看来是一个用户进程。虚拟机通过该进程获取宿主机的CPU、内存、外设等物理硬件资源,并在不同线程之间共享。虚拟机的每个虚拟CPU(以下简称VCPU)有一个独立线程,虚拟机的内核和文件系统均在VCPU线程中运行。模拟VDEV的QEMU运行在根模式用户态。负责CPU、内存虚拟化的KVM则运行在根模式内核态,是宿主机内核的一部分。会引起客模式陷入根模式内核态的例外如表1所示。其中I/O虚拟化用到的主要是转译后备缓冲器(translation lookaside buffer, TLB)例外。

表1 GS464E中陷入根模式的例外
当虚拟机在VCPU线程中访问I/O端口时,由于该地址不在TLB中,引起TLB例外陷入根模式内核态,随后由KVM处理,KVM在判定地址不是内存且自己不能模拟后,会返回QEMU模拟。CPU与外设的交互手段,除了寄存器访问和I/O中断之外还有直接存储器访问(direct memory access, DMA)。虚拟机中的DMA是QEMU通过CPU内存拷贝模拟的。
1.2 I/O中断虚拟化
I/O中断虚拟机是中断虚拟化的一部分,支持硬件虚拟化辅助的CPU一般都会提供一定程度的中断虚拟化辅助。以GS464E处理器核为例,该处理器的协处理器0(co-processor 0,简称CP0,MIPS中负责处理例外的协处理器)中有用于客模式中断辅助的相关寄存器,如表2中所示。

表2 GS464E中的虚拟机中断辅助寄存器
其中Guest.Cause.IP(以下简称GCIP)记录虚拟机的中断状态。当GCIP被置位时,虚拟机会陷入客模式管理的例外,跳转到对应中断向量入口执行处理程序。该寄存器不能由软件直接置位,而是由GuestCtl0.PIP(以下简称GPIP)、GuestCtl2.VIP(以下简称GVIP)和硬件中断(以下简称HWIP)共同决定的。其中断逻辑图如图2所示。其中的n代表是第几位,取值范围为0~7。
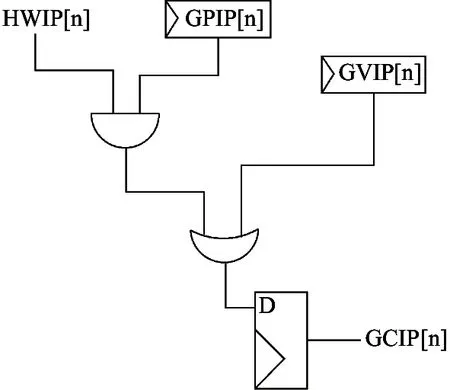
图2 GS464E 客模式中断逻辑
通过设置GPIP和处理器的硬件中断路由器也可以将特定物理外设的I/O中断直接注入给虚拟机,但虚拟机使用的大部分外设是软件模拟的,且GCIP只有8位,一般只有1位用于I/O中断,因此I/O中断采用的是软件注入方式,使用虚拟I/O中断控制器来管理多个虚拟外设中断。虚拟I/O中断控制器行为逻辑上模拟特定的物理I/O中断控制器,龙芯KVM虚拟机中使用的虚拟高级I/O中断控制器(以下简称VIOAPIC)模拟自龙芯7A桥片内置的高级I/O中断控制器。VIOAPIC自身也是一个虚拟外设。虚拟机I/O中断是VCPU和虚拟外设之间的一种同步手段。当虚拟外设发生了需要与VCPU线程同步的事件时,会将该请求通知VIOAPIC。VIOAPIC会根据中断触发逻辑置位GVIP寄存器。龙芯KVM虚拟机中断结构如图3所示。客模式中断被置位后,虚拟机会直接跳转到客模式内核对应的例外入口处理。
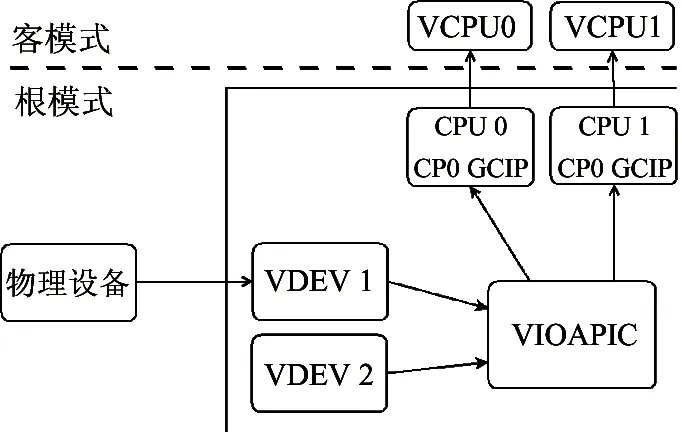
图3 龙芯KVM虚拟机中断结构图
从硬件结构上看,I/O中断控制器之后还有用于多核中断分发的中断路由器也需要模拟。在这里为了简化,将其看成是VIOAPIC的一部分,不单独分列。
VIOAPIC有中断线和中断消息(MSI)2种触发逻辑,两者在虚拟机中都是软件模拟,没有本质区别。本文使用中断线模式,后续的优化方法对MSI和中断线2种模式都有效。虚拟I/O中断控制器不直接涉及真实外设,如果不考虑中断注入延迟导致的外设空闲,可以认为其只消耗CPU资源。
2 影响性能的主要问题
一个I/O中断从虚拟设备发出请求,到最终处理完毕可以分成2个阶段:中断注入和中断响应。在宿主机和虚拟机都以1.2 G 龙芯3A3000单核运行并屏蔽其他中断的情况下,使一个虚拟设备连续触发I/O中断,分别测试虚拟机以不处理直接返回和正常I/O中断响应流程2种方式完成100万次循环所需的时间再除以循环次数,以此来估算中断注入和中断响应所需的时间。测试结果显示,100万次中断注入耗时2.68 s,以此估算一次完整中断注入流程实测需要约3 217个时钟周期。而一次中断注入加一次中断响应流程则耗时76.48 s,需要约91 769个时钟周期。减去中断注入流程消耗的时钟周期,一次中断响应需要88 552个时钟周期。因此影响I/O中断子系统性能的主要是中断响应。
虚拟I/O中断响应与宿主机I/O中断响应在客模式运行的代码是完全一致的,CPU的主要行为区别是I/O寄存器的访问。一次I/O中断处理流程需要8次访问VIOAPIC的寄存器,如果增加1次冗余的寄存器读取,一次中断响应流程增加约6 886个时钟周期。以此估算,访问VIOAPIC的寄存器消耗了中断响应流程62.2%的时间,是影响虚拟I/O中断子系统性能的主要因素。
龙芯7A的中断响应流程如图4所示。流程图中的(A)、(B)、(C)、(D)步骤均有对I/O寄存器的访问。其中(A)、(B)、(D)中访问的是VIOAPIC的寄存器,(C)中访问的是VDEV的寄存器。
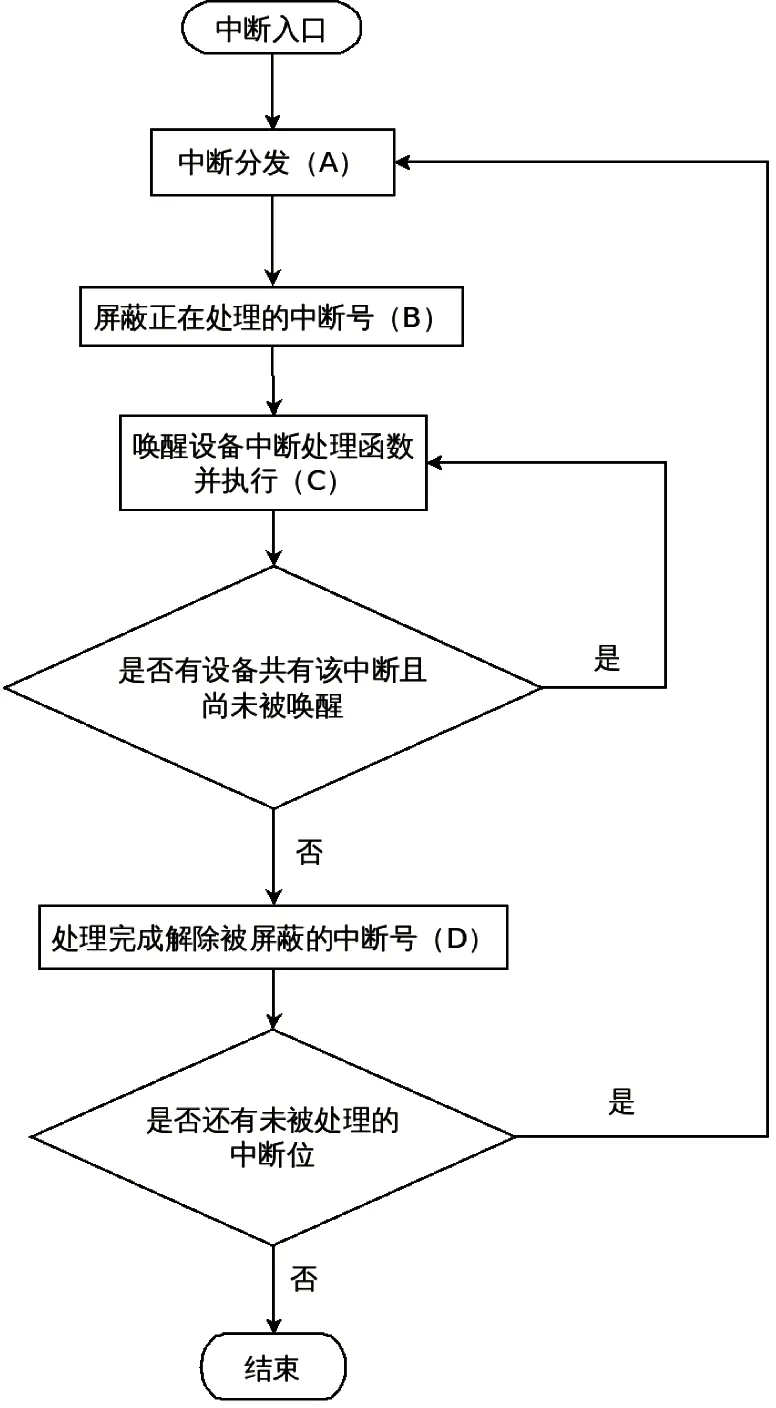
图4 龙芯7A I/O中断响应流程图
虚拟机中断处理的数据流图如图5所示。图中的(A)、(B)、(C)、(D)与流程图中的符号相对应。数据流图中的粗线表示会引发CPU例外或状态切换的动作,其中实线代表访问VIOAPIC的寄存器,虚线代表访问的VDEV的寄存器。本文中后续数据流图的含义也与此相同。由于(C)中对VDEV寄存器的访问不是本文的重点,且没有变化,后续的数据流图略去了这一部分。

图5 7A I/O中断处理流程数据流图
从图5可知,VCPU对VIOAPIC的一次寄存器访问需要经过VCPU->KVM->QEMU->KVM->VCPU的流程,其中每个步骤都需要保存恢复CPU的若干状态信息和线程信息,这是模拟开销大的主要原因。
3 常用优化方法
优化I/O模拟的常用优化方法是将I/O外设放到KVM中模拟,在KVM中模拟VIOAPIC,中断注入区别不大,但在中断响应流程中,VCPU访问VIOAPIC的寄存器,KVM可以直接将数据返回给VCPU,不需要再经过QEMU,模拟流程简化为VCPU->KVM->VCPU。经测试,访问一次KVM中模拟的VIOAPIC寄存器的开销约为2 265个时钟周期,一次完整的I/O中断响应消耗大约37 985个时钟周期,比在QEMU中模拟减少了57%的CPU开销,访问中断控制器的寄存器耗时占比从62.2%下降到47.7%。优化后的数据流图如图6所示。

图6 在KVM中模拟VIOAPIC的数据流图
4 进一步优化
虽然在KVM中模拟VIOAPIC明显提升了I/O中断响应的速度,但其中仍有近一半的耗时用于访问VIOAPIC的寄存器,还有继续优化的空间。
4.1 使用物理内存模拟寄存器读取
龙芯GS464E对寄存器访问的操作都是用普通访存指令完成的。在中断响应过程中,VCPU对寄存器的读是为了获取中断控制器的状态,这些状态在中断产生前就已经到达了KVM。可以提前将其保存到虚拟机可以访问的内存中,避免VCPU陷入根模式模拟。部分写寄存器由于涉及到GCIP的状态同步,仍需要被KVM捕获。VCPU通过0xe010000000~0xe010000fff的地址访问VIOAPIC的寄存器。而在0xe010000000~0xe01000ffff的地址空间没有任何内存或其他设备。因此可以将寄存器的值填入一个4 kB的物理内存页中,将该页映射到虚拟机的0xe010000000~0xe01000ffff地址,并将该页在虚拟机页表中设置为只读属性,这样就能实现VCPU直接读取内存获得寄存器的值,而对相关地址的写会陷入KVM。
虚拟机的页表填入过程需要4个地址:虚拟机虚拟地址(guest virtual address, GVA),虚拟机物理地址(guest physical address, GPA),宿主机虚拟地址(host virtual address, HVA),宿主机物理地址(host physical address, HPA)。GS464E的虚拟机和宿主机共用页表项,虚拟机和宿主机的页表项用2个辅助标识MID和VPID区分,其中MID区分宿主机和虚拟机,VPID区分是哪一个虚拟机。虚拟机的页表项只保存GVA到HPA的对应关系。
内核中利用MIPS的非缓存物理地址窗口访问寄存器[9],如0xe010000000对应的访问地址就是0x90000e010000000,即内核访问的GVA。修改后虚拟机中断响应的数据流图如图7所示。在页表项没有被换出的情况下,对VIOAPIC寄存器的读操作都不需要陷入KVM,直接访问内存,只有寄存器写操作需要陷入KVM模拟。需要说明的是,GS464E中虚拟机访问地址的缓存属性不受MIPS的非缓存和缓存窗口的约束,而是由页表属性决定的。
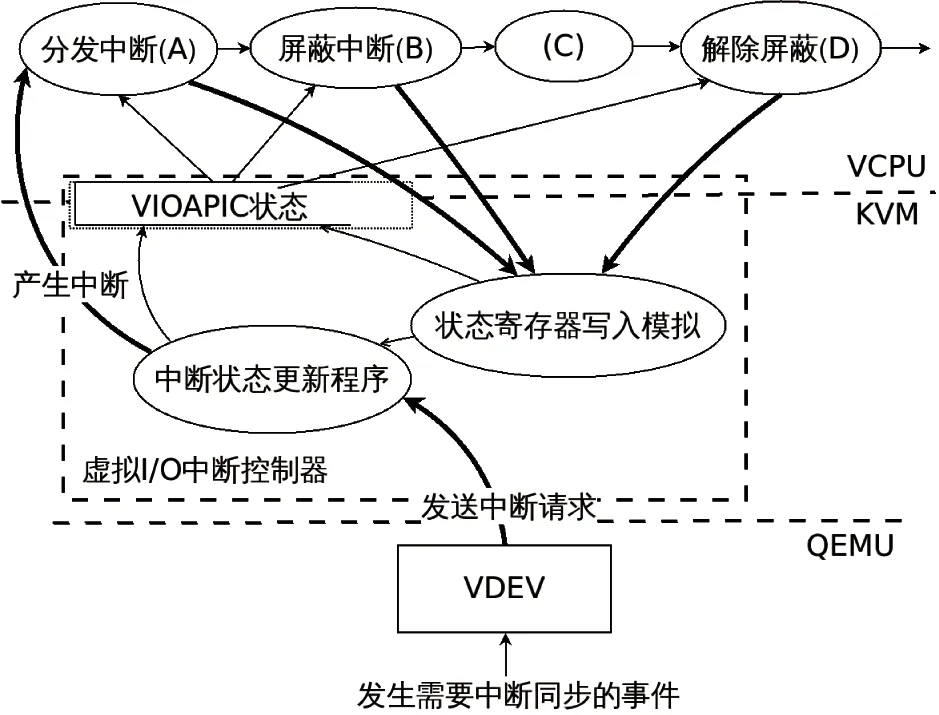
图7 使用只读页表优化后的中断响应数据流图
优化后的一次完整I/O中断响应流程消耗大约23 227个时钟周期,较单纯的KVM模拟减少了38.9%,I/O中断控制器的寄存访问消耗占比进一步下降到了29.2%左右。这一优化不需要改动虚拟机,保持了虚拟机内核和宿主机内核的兼容性。
4.2 优化虚拟机的I/O中断控制逻辑
在I/O虚拟化中,在保持虚拟机用户态程序和宿主机完全兼容的情况下,通过修改少量内核态逻辑使其更适合虚拟化环境的方法,被称为类虚拟化。通过分析本文认为类虚拟化的方法也适用于VIOAPIC的优化。在中断线模式下VIOAPIC 3个最核心寄存器是中断请求寄存器(interrupt request register, IRR),中断状态寄存器(interrupt status register, ISR)和中断屏蔽寄存器(interrupt mask register, MASK),其三者的逻辑关系为:
ISR=IRR&(~MASK)
其中中断响应过程中VCPU主要访问ISR和MASK寄存器,IRR寄存器由VDEV更改。如果有任何新的中断请求VIOAPIC会先更新IRR,再根据上述逻辑关系更新ISR最终更新目标VCPU所运行的物理CPU的GVIP寄存器。而对于VCPU来说,只能通过MASK来更新ISR。
I/O中断响应过程中,VCPU更新MASK主要有2个作用:即屏蔽中断和解除中断的屏蔽。
由于GCIP是VIOAPIC软件注入的,只需确保下次VIOAPIC更新GVIP时,MASK的值能够被VIOAPIC正确得知即可,因此屏蔽中断不需要同步操作。解除中断的屏蔽会实时更新ISR,需要同步操作。
可以将MASK拆解为2个不同的寄存器:MASK和UNMASK。VCPU访问MASK寄存器屏蔽I/O中断,使用UNMASK寄存器解除屏蔽。其中MASK虚拟机访问的是一个VCPU可读写的内存地址,TLB命中时不需要陷入。而UNMASK会按照常规的寄存器模拟,MASK写1代表该位的中断被屏蔽,UNMASK写1代表该位的中断被解除屏蔽。当IRR发生变化更新ISR时的逻辑关系仍为ISR=IRR&(~MASK),但在VCPU写UNMASK寄存器陷入KVM后,VIOAPIC会按照如下步骤:
(1)MASK = MASK&(~UNMASK)
(2)ISR=IRR&(~MASK)
完成对MASK、UNMASK和ISR寄存器的同步操作。需要注意的是,同时只能有一个线程更新ISR或访问MASK和UNMASK,因此需要在虚拟机和KVM中使用锁进行保护。优化后的数据流图如图8所示。
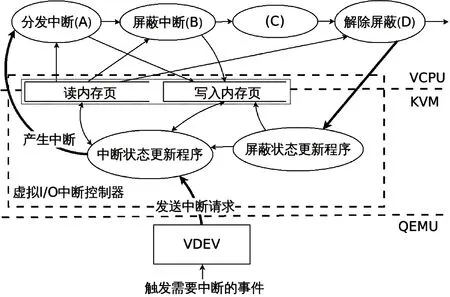
图8 采用类虚拟化方法优化后的数据流图
和4.1节中的只读页表优化一样,VIOAPIC相关寄存器的状态放在读页中,MASK寄存器放在新增的写页中。MASK更新时,先从内存写页中读出旧值,再与新的需要屏蔽的中断位取或后重新写回内存。修改后的响应过程VCPU只在解除屏蔽时写UNMASK寄存器需要陷入KVM。经测试优化后一次完整中断所需的时钟周期约为18 647个时钟周期,其中访问VIOAPIC的寄存器消耗了约12.1%的时钟周期,连续处理100万个中断耗时从76.5 s缩短到18.4 s,吞吐量提升了超过3倍,相较于单纯的KVM模拟,也提升了近1倍。
MSI模式的I/O中断也可以用这种方法优化,只是优化的寄存器逻辑略有不同,在这里不作赘述。
5 性能测试
为了验证优化后的模拟I/O中断控制器,本研究选择了I/O中断密集的部分磁盘、网络测试项,测试优化前和优化后的效果,其中只读页表优化和中断处理逻辑优化都是以将中断控制器放置在KVM中模拟为基础的。测试环境如表3所示。

表3 龙芯KVM测试环境
磁盘测试中比较了龙芯平台优化前后的性能。网络测试不仅比较了龙芯优化前后的性能,还与商用计算机的KVM虚拟机进行了简单的效率对比。选择网络测试与商用计算机进行对比是因为网络测试在虚拟机和宿主机使用地址转换模式(NAT)连接时,并不需要通过真实外设交互,全过程只涉及软件,可以屏蔽由于外设性能差距带来的干扰。而测试所用的netpef TCP_RR和TCP_CRR测试项经性能分析工具分析在虚拟机和宿主机使用NAT连接时95%以上的时钟周期都用于中断逻辑模拟,对比的商用计算机使用AMD的FX8300处理器,该处理器的单核同频性能与GS464E相当[10]。为了测试方便,将核心数和核心频率设置为与3A3000相同,测试分值就可以直接反映I/O中断模拟的效率。具体测试环境如表4所示(以下将对比的商用计算机简称FX8300)。

表4 商用计算机KVM测试环境
磁盘测试中使用dd命令循环将0写入文件,源数据使用/dev/zero,文件数据块大小从8 kB到10 MB,测试使用iflag=direct参数,循环次数为10 GB/块大小。测试结果如表5所示,结果的单位为MB/s。本节中测试栏中的KVM代表在KVM中实现VIOAPIC。
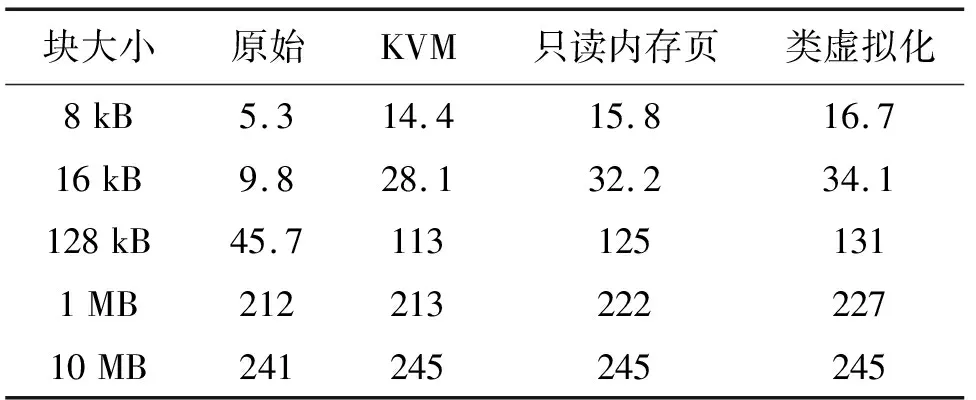
表5 磁盘性能测试结果
在磁盘测试中,数据块较小时的优化效果明显。以8 kB数据块为例,相对于原始成绩,通用优化的提升幅度最大,提升了171.6%,而只读页表优化和类虚拟化优化在通用优化的基础上又分别提升了9.72%和15.97%,相对于原始成绩则提升了198.1%和215.1%。在16 kB、128 kB的测试中的结果也与之相似,但在1 MB、10 MB的测试中,优化前后的性能没有明显变化。这是因为虚拟机与半虚拟化的磁盘设备主要通过环形缓冲区进行交互,在环形缓冲区未阻塞时不需要使用I/O中断同步[11]。数据块较大时,每次拷贝VCPU的准备时间长,磁盘写入的时间也较长,交互次数少,环形缓冲区很少出现阻塞。小块数据拷贝时,虚拟机和虚拟外设交互频繁,环形缓冲区经常阻塞。
网络测试中,虚拟机与宿主机使用NAT方式连接。使用Netperf中的TCP_RR、TCP_CRR方式测试,server运行在宿主机上。测试结果如表6所示。
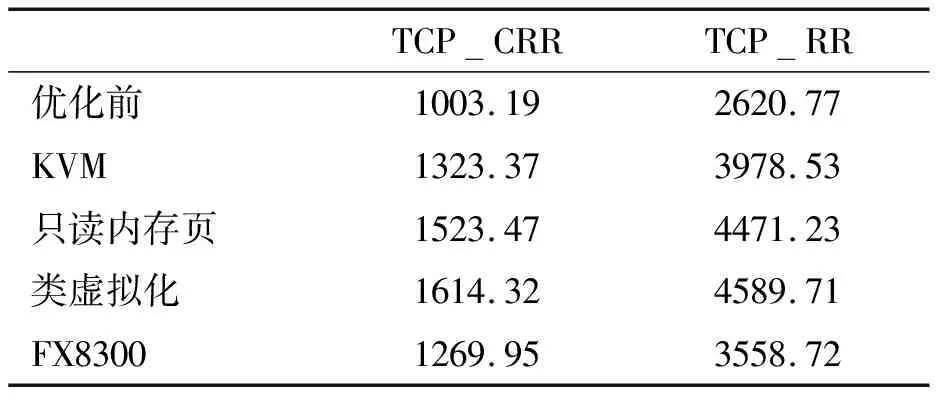
表6 网络性能测试对比
通过网络测试的结果可知,优化前龙芯的I/O中断效率明显低于FX8300,测试成绩仅为FX8300的73.6%~80%。在同样使用KVM模拟I/O中断控制逻辑的情况下,龙芯的模拟效率超过了FX8300,测试成绩达到了FX8300的104.2%~111.7%,在使用只读页表和类虚拟化优化后,模拟效率又有了进一步的提高。在使用只读页表时,达到了FX8300的120%~125.6%。使用类虚拟化优化方法时,达到了FX8300的127.1%~128.9%。
与优化前相比,龙芯KVM在中断较为频繁的测试项目中,性能提升了60.9%~215.1%,其中最主要的是在KVM中模拟VIOAPIC带来的性能提升,占到了其中的52%~78%。另外22%~48%的性能提升是只读页表和类虚拟化优化带来的。
6 结 论
I/O中断模拟的效率较低是I/O虚拟化中普遍存在的问题。虽然半虚拟化I/O设备通过使用环形缓冲区能够有效地减少虚拟机I/O中断的次数,但在部分场景下虚拟机仍会触发较多的虚拟I/O中断,影响性能和用户体验。尤其在面对万兆网卡等高速I/O外设时,虚拟机将会面临更大的I/O中断压力。如果虚拟机使用传统的模拟I/O中断,部分场景下会损失40%左右的峰值性能[12]。为I/O中断虚拟化添加硬件辅助,可以有效地提升虚拟机的I/O中断性能,相对于纯软件模拟有性能优势[13]。在没有硬件辅助的情况下,通过模拟流程和处理逻辑的优化,也可以较大幅度地提升I/O中断的性能。
本研究一方面参照其他架构的优化方法在KVM中实现I/O中断子系统的模拟,并验证了其有效性;另一方面探索让虚拟机直接使用内存读取I/O寄存器数据,优化虚拟机中断处理逻辑,进一步提升了虚拟机处理I/O中断的性能。实测虚拟机的I/O中断吞吐率有了较大的提升,一次I/O中断的处理事件缩短了80%。对于部分I/O中断较频繁的场景,龙芯KVM虚拟机的性能有了成倍的提高。优化后的I/O中断吞吐量能够满足龙芯虚拟机使用半虚拟化设备时的需求。其中将I/O寄存器映射到内存只读页、优化虚拟中断控制器逻辑的优化方法也可以用到其他架构的虚拟机上。
