基于注意力机制和LSTM的电力通信设备状态预测
2020-10-16吴海洋蒋春霞李霁轩朱鹏宇
吴海洋,陈 鹏,郭 波,蒋春霞,李霁轩,朱鹏宇
(国网江苏省电力有限公司信息通信分公司,江苏 南京 210024)
0 引 言
近年来,我国智能电网的覆盖规模迅速扩展,作为相应配套承载的电力通信网络也迅速发展,设备数量逐年增多。现代电力通信网络不仅承担了电网管理功能,还需要对关键设备的运行状态进行记录和维护。因此,电力通信网络设备的健康运行本身的重要性也与日俱增。传统的电力通信网络设备维护仍然基于周期性巡检或者故障告警等手段[1],响应慢且故障代价高。而随时监控设备运行状态,通过运维记录对可能出现的设备故障进行预警正逐渐成为电力通信网运维的重要手段[2-3]。
虽然在工业领域对于设备运行状态的在线预测问题已经有很多相关研究[4],然而对于电力通信网络设备的状态预测仍然是一个挑战性问题。这主要是因为此类设备的相关数据来源复杂,不仅包括现场各类传感器数据,还包含了各类网络运维记录,且考虑到相关节点的数据对于目标节点上设备状态的预测同样有辅助作用,最终所需要考虑的输入数据维度往往很高;而相对地,数据数量则不是很多,且大部分数据模式单一。
传统的基于现场有限数据进行状态预测的一些手段[5],往往依赖于手工的特征设计,需要有很具体的技术经验背景,在不同的场景下用途有限。而另一个思路是在原始数据的基础上首先使用一些数据降维手段进行预处理,然后通过训练支持向量机[6-7]或者决策树[8-9]等回归预测模型实现状态预警[10]。此类方法的局限性在于,一般的降维手段只能作为预处理独立使用,不能和预测模型进行端到端的联合学习,对于有效信息的挖掘效率受到限制,最终导致性能有限。
针对这些问题,本文提出基于注意力机制和长短时记忆(Long Short-Term Memory, LSTM)模型构建端到端的设备状态预测框架,对网络节点上的设备运行状态进行在线预测。作为深度学习领域[11]常见的特征提取和序列预测手段,注意力机制和LSTM模型在自然语言处理[12]、视频内容检测[13]等场景中都有非常成功的应用。本文主要解决将此类需要海量数据驱动的复杂模型应用于有限数据场景时的一些具体问题。通过数据生成以及分阶段训练等手段成功地实现端到端的模型训练,提升最终的预测性能。
1 背景资料
1.1 注意力机制
注意力机制[14]可以充分发掘信号中的自相关性,突出信号中与最终预测任务相关的部分特征,并降低信号混淆程度。由于从现场多种数据来源采集的信号普遍存在信号源之间的相关性以及信号源内部通道间的相关性,因此在传统注意力机制的基础上,本文进一步引入通道注意力模块[15]和传统的注意力模快构成的混合注意力模块,如图1所示。
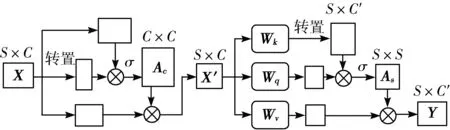
图1 混合注意力模块
该模块由通道注意力模块和传统注意力模块串联而成,兼具了相关性提升和信号降维的作用。给定输入X∈RS×C,其中S为信号长度,C为每组信号的通道数,σ为softmax函数产生的非线性关系。首先在前半部分通过一个通道注意力模块,将特征与其转置矩阵相乘得到不同通道的自相关阵,该矩阵通过一个softmax函数后即可作为通道注意力矩阵AC∈RC×C对原始信号进行加权。通过该模块后,原始特征通道间的相关性下降,而有用的信息被突出,进一步输入紧随的降维注意力模块。
对于降维注意力模块而言,其输入X′∈RS×C被3个映射矩阵Wk、Wq和Wv投影到一个低维空间RS×C′上,通过类似的方法产生自注意力矩阵AS∈RS×S,对输入信号进行加权。降维注意力机制可以简单表达如下:
(1)
最终得到降维后的输出Y∈RS×C′。
在该模块中,仅有3个需要学习的C×C′维参数矩阵:Wk、Wq和Wv。在第3章的实验环节中可以看到,仅采用少量的参数就可以将输入特征的维度大幅降低,实现状态预测。
1.2 LSTM模型
长短时记忆LSTM模型[16-17]是一种常见的递归神经网络实现,多用于顺序信号的状态预测[13,18-20]。一个标准的LSTM单元由4个门函数和一个记忆细胞构成,分别是输入门i、输入调制门g、遗忘门s、输出门o和记忆单元c。给定t时刻的输入xt∈RSC′,输出为zt∈RN,传递的隐藏状态为ht∈RN,其中N为隐藏单元数;实际运行时,注意力单元的输出Y被拉直以后作为LSTM的输入使用。如果将内部各门函数和记忆单元上的非线性激活函数统一用fλ(·),λ∈{i,g,s,o,c}表示,而输入输出分别用xλ和yλ表示,则LSTM的前向计算可简单表示为:
yλ=fλ(Wλxλ),λ∈{i,g,o,s}
(2)
yc=fc(ys⊙ct-1+yi⊙yg)
(3)
zt=ht=yo⊙yc
(4)
其中⊙表示向量点积。对于LSTM而言,需要学习的参数主要为4个门函数上的线性加权参数Wλ,实际使用中可以通过标准的时序反向传播方法[21]对模块进行训练。
2 方法设计与模型训练
通过将上述混合注意力机制和LSTM进行串联,本文提出如图2所示的电力通信设备状态预测方法。其中从现场各类传感器以及运行记录中所得到的原始数据经过填充到固定长度以后进入预处理模块,通过常见的归一化以及中心化等处理形成系统输入。通过图1所示的混合注意力模块后输入LSTM单元实现时序预测。最终通过最后一个全连接(Fully Connected, FC)层输出预测结果。
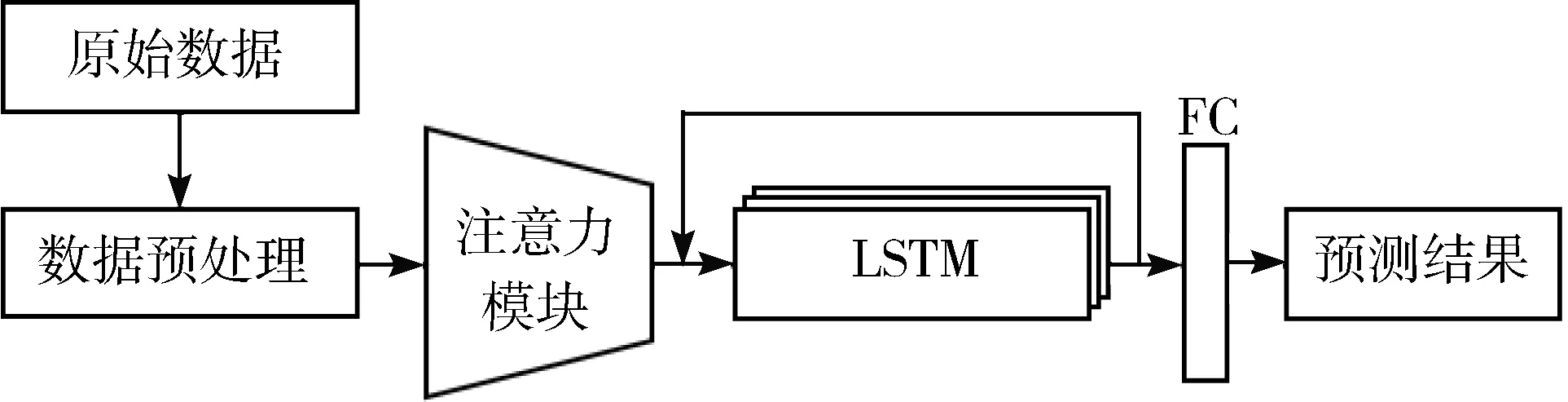
图2 预测系统架构
对于如图2所示的预测模型,如果直接使用常见的反向传播方法进行训练,所面临的问题主要有2个:首先,可供训练的样本维数很高,然而数量并不充分;其次,大部分训练样本模式单一,实际运行中通信设备异常状态的出现并不常见。使用这样的数据直接驱动模型学习往往会导致过拟合,预测效果并不好。因此在实际进行模型训练时,本文采用2阶段的方式对模型进行逐步学习。
在第1阶段,首先通过可变分自编码器(Variational Auto-Encoder, VAE)[22]方式对混合注意力模块进行预训练,同时得到一个生成模块用于产生同分布的采样样本补充进入训练样本库。VAE基于传统的自编码器提出,其区别在于在降维后的中间隐层对表示均值和方差的低维向量添加随机噪声,并保证生成模块在随机噪声的影响下仍然能够复原输入样本。本文使用一个如图1所示的注意力模块串联一个三层神经网络构成一个VAE,保证C维特征在被降维至C′维后再恢复为C维生成特征。再与训练时使用生成特征和原始输入的最小均方误差作为损失函数训练VAE。当训练完成后,一方面可以得到一个预训练完成的注意力模型,另一方面通过对原始样本增加小随机噪声在VAE中生成新样本补充进样本库进行下一阶段学习。在第2阶段,对如图2所示的完整预测模型进行端到端训练。在训练时模型前段的注意力模块使用第1阶段结果进行参数初始化,与后段LSTM模块以及FC层进行联合训练。同时,将第1阶段的生成样本补充进入样本库以后,通过优化传统的交叉熵损失[23-24]完成模型训练。
3 实验与分析
3.1 数据来源及算法实现
实验部分的数据主要由每个电力通信网络节点上的设备履历信息、检修记录、缺陷记录以及传感器传回的实时监测信息构成。同时作为通信网络节点,其运行特征诸如光功率、抖动、飘移、误码率、误码秒以及信噪比等也是判断其状态的重要参数。
本文实验中从每个标准节点提取一组特征向量,将网络拓扑结构上与该节点最接近的3个节点对应的特征向量取出同样用于当前节点的状态预测。所有数据经过抽取、拉直并对空位进行填充后每个节点上得到一组2048维的特征向量,将4组向量输入图2所示预测模型进行状态预测。
本文采用Pytorch深度学习框架实现上述注意力以及LSTM模块。实验所用数据采集于2年内的电力通信网络运营数据,其中2/3作为模型的训练数据,其余1/3作为测试数据使用。每组实验中同样配置的方法进行5次实验,以检查随机初始化带来的模型性能的细微变化。
3.2 注意力模块参数比较
由于注意力模块的主要作用是将每组2048维的高维特征映射到一个低维子空间,并突出和预测相关的有效特征,在预训练阶段首先要对降维后子空间的维数做一些测试。过低的子空间维数不足以保持足够的预测特征,而过高的子空间维数则会直接影响后续LSTM模块的复杂度。因此实验部分首先基于VAE训练方法比较了采用不同子空间维数时在测试集上生成的样本和原始样本的均方误差。实验采用32个样本为批次处理大小,在训练集上训练20个周期,最终比较结果如表1所示。
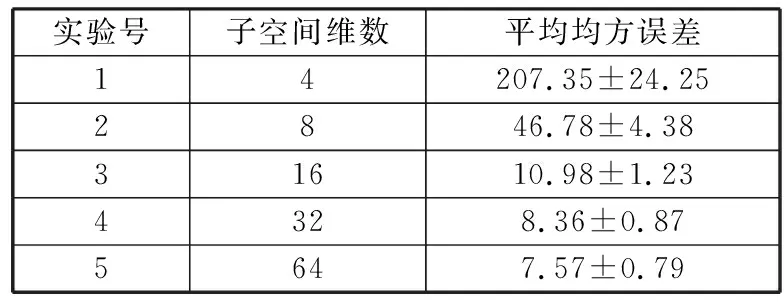
表1 注意力模型子空间维数结果比较
从表1的比较中可以发现,子空间维数在8维以上时才有可能产生比较有意义的信号重建,也意味着比较有效的特征信息被完整地保留下来。而子空间维数增长到32维以上时,平均均方误差的下降则不明显,而带来的复杂度提升则比较严重。因此在端到端训练阶段,主要考虑8、16和32维这3种维度和LSTM模块配合使用时的最终性能。
3.3 联合参数选择
在端到端训练阶段,上面筛选出的注意力模型参数和LSTM模块参数进行了联合筛选以找出最优的模型超参数。其中LSTM模块主要需要筛选的参数有时间步和隐层单元数量2个设置。表2列出了不同参数对应的最终预测精度,即正确预测数量占总测试样本的比例,以及每种配置需要的训练时间。作为模型效率的参考,此处训练时间仅为第2阶段端到端训练时间。其中每次实验同样采用32个样本为批次处理大小,在训练集上训练20个周期。
从表2的比较中可以看出,子空间维度达到16维以上,LSTM隐层单元数达到8以上,基本上可以得到性能较好的预测模型。相应地,LSTM时间步的增加也对最终的预测性能有正向增益。其中子空间维数为16,时间步和隐层单元数分别为10和16时,可以得到一个预测性能比较理想的模型。继续增加相关模块的复杂度,所带来的性能提升已不明显,且会带来细微的训练时间增加。
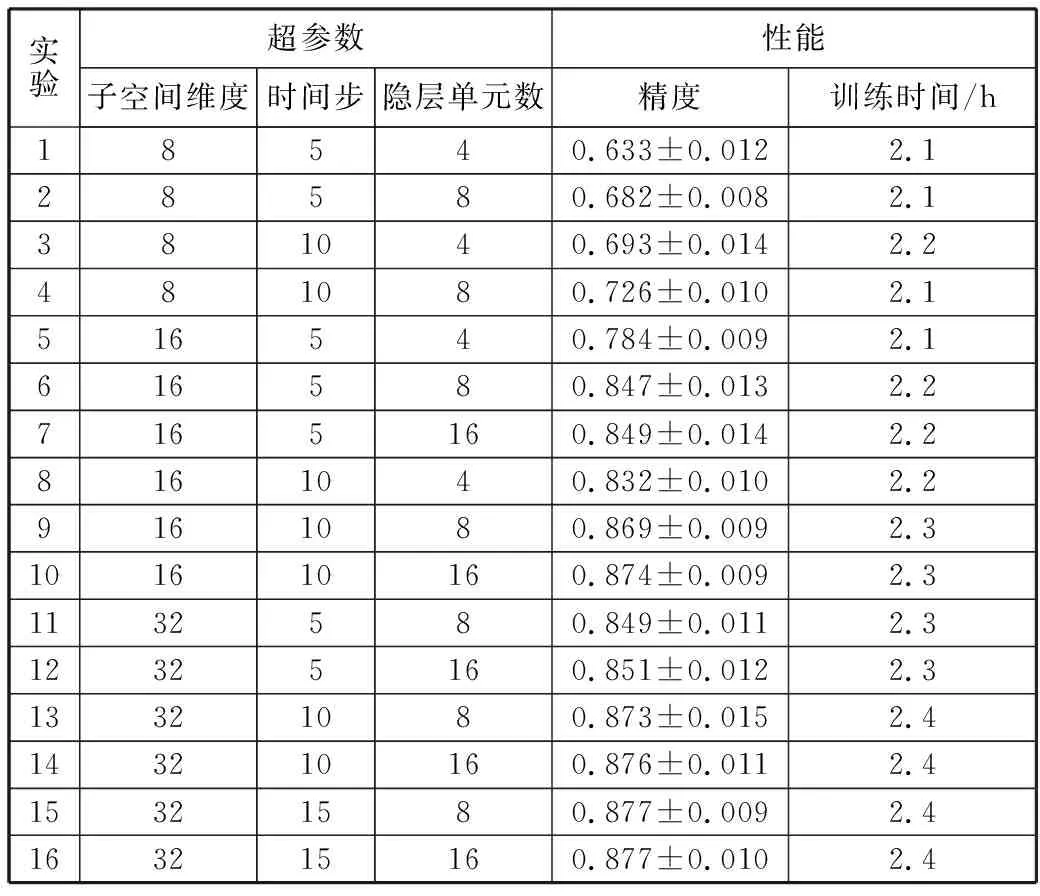
表2 模型超参数对最终性能和效率影响的结果比较
3.4 与相关方法的比较以及消融测试
为进一步验证所提方法的有效性,基于筛选出的最优参数,本文继续将所提模型和一些相关方法进行比较,并就不同的模块组合进行消融测试。参与比较的方法有:PCA+Logistic回归(P+L)、PCA+LSTM(P+LSTM)、注意力+Logistic回归(A+L)、卷积网络(Convolutional Neural Networks, CNN)+LSTM(C+LSTM)以及分别进行1阶段训练和2阶段训练的注意力+LSTM(A+LSTM1和A+LSTM2)。本文基于一维卷积层、池化层以及1个全连接层构建了1个9层CNN,并使用常见的批量标准化和非线性激活层。图3和表3分别比较了不同方法的查准率(Precision)、召回值(Recall)和训练时间。

图3 不同方法的查准率和召回值比较
从图3中可以看出,LSTM模块对于时序信号预测的作用比较明显,直接使用Logistic回归难以进行有效预测,而LSTM也需通过降维手段配合才能有效工作。在该问题中,将降维模块与LSTM串联直接进行1阶段端到端学习得到的模型性能有限,而基于VAE方法的2阶段训练则显著提高了最终性能。另一方面,直接使用CNN等流行的深度学习模型在此处的效果并不是十分理想。其原因可能是因为通常的卷积核尺寸有限,对于局部特征可以进行有效捕捉,对于比较稀疏的输入信号而言则无法直接对整个特征进行处理,而增大卷积核尺寸进行结构改进又将使模型复杂度变得过高。

表3 不同方法的训练时长比较
表3中比较了不同方法训练模型所需要的时长。对于本文所提的注意力+LSTM模型,由于需要采用2阶段训练方式进行训练,导致训练的总时长较长,然而测试阶段的模型前向效率是基本近似的。
4 结束语
本文提出了一种基于注意力机制和LSTM的预测模型,着重解决了电力通信设备状态的预测问题。模型使用端到端的方式进行训练,将原始特征数据的降维、信息挖掘与最终预测整合成一步完成,对于类似场景中数据维度高、特征稀疏以及训练数据量不足的问题有较好的效果。后续研究中还将进一步优化模型复杂度,以提升方法在线预测的时间效率。
