基于聚类分析算法的垃圾邮件识别
2020-10-16盖璇
盖 璇
(东北石油大学计算机与信息技术学院,黑龙江 大庆 163318)
0 引 言
现今,电子邮件已经成为人们日常生活中不可或缺的一种重要工具,主要用于多种信息交互[1]。电子邮件的快速发展和相关业务的开发,使得电子邮件用户数达到惊人的数量,随之而来的就是垃圾邮件在网络上的泛滥[2-4]。垃圾邮件主要来自匿名的转发服务器、一次性账户和僵尸主机等。一些人为了推销自己的产品或宣传网站等,通过乱发电子邮件来达到自己的目的,使得垃圾邮件远远超过正常邮件数量,占用大量用户邮箱空间和网络带宽,影响用户使用的同时,损耗广大用户的合法权益,给邮件服务提供商带来沉重的经济负担和社会压力[5-7]。这已经不仅仅是技术性问题,也不仅仅是政策法律问题,而是一个全球性、综合性的问题。因此,如何快速有效地解决垃圾邮件问题具有比较大的现实意义[8-9]。
现在有很多垃圾邮件识别方法,如溯源法、统计法等,这些方法有的基于服务器,有的基于邮件传输代理,也有基于邮件客户端的[10-11]。目前国内外采用的电子邮件识别技术主要有基于IP地址的识别技术和基于关键词匹配的识别技术。基于IP地址的识别方法主要利用路由器的访问控制链表,使用比较简单,可以用于各个层次;基于关键词匹配的识别技术主要针对邮件的内容进行识别,往往更加灵活[12-14]。以上2种方法各有优点,但是在如今大数据时代,面对垃圾邮件内容更新速度快的情况,以上2种方法在垃圾邮件的识别上存在词汇识别精度差的问题,识别方法的实际应用水平需要进一步加强。针对这一情况,本文提出一种基于聚类分析算法的垃圾邮件识别方法,利用聚类分析算法处理和组织大量的文本数据,解决上述2种识别方法中存在的问题。
1 基于聚类分析算法的垃圾邮件识别
基于聚类分析算法的垃圾邮件识别方法主要是将邮件文本中关键分词作为聚类分析算法中的聚类中心,依次将垃圾邮件从庞大的邮件集合中识别出来。具体的识别流程如图1所示。

图1 基于聚类分析算法的垃圾邮件识别流程
依照图1中显示的识别流程,逐步实现垃圾邮件的识别。
1.1 邮件预处理
电子邮件是一种特征的、半结构化的文本形式,一个标准的邮件样本包含邮件头、邮件体,部分邮件还包含附件,各个邮件的格式并不统一。因此在邮件识别前预处理邮件,主要是对邮件文本内容进行分词和去除停用词处理。
文本分词处理的主要原因是垃圾邮件中的部分词语没有明显的区分标记,对这样的词语进行分析是邮件内容处理的基础和关键[15]。使用Rwordseg分词工具,引用Ansj包,实现邮件内容分词、用户自定义词典等[16]。分词之前需要注意的是Rwordseg只有在Java(JDK)环境变量设置成功后才能在R环境下被调用[17]。分词主要分为3种情况。
1)中文分词:
>library(rJava)
>library(Rwordseg)
####实现中文分词
>segmentCH("我是实验小学的一名学生")
分词结果为“我是、实验、小学、一名、学生”。
2)中文姓名的识别:
####isNameRecognition用来识别人的名字
>getOption("isNameRecogntion")#默认是不进行人名识别时,输出FALSE,通过姓名识别的功能,将邮件文本内容中的姓名单独分离出来。
3)用户自定义词典:在对一些专业性相关的邮件文本分析时,需要用户自己定义一个与其相关的词典,创建独立的词库再进行分词。在使用Rwordseg包时可以导入输入法的细胞词库,在做分词处理时遇到专业词汇,这时在输入法的词库中寻找相关的词典,安装到R中,从而达到分词的目的[18]。
邮件系统在提取邮件内容时,为了节省存储空间自动忽略了某些字或词,这些就是停用词[19]。这些词出现在邮件文本中比较频繁,对垃圾邮件的识别没有太大的作用,将这些词去除掉,能够避免对垃圾邮件的识别产生影响。
在后续识别垃圾邮件时,利用的是垃圾邮件与正常邮件不同的特征,在分词完成之后,将分词中不能作为特征的词和字剔除掉,采用降维的方法筛选出邮件文本特征[20-22]。
计算出划分的分词在邮件文本中出现的频率,如果这个词在这个邮件文本中出现的频率比较高,在其它邮件文本中出现的频率比较低,则这个词可以被认为是一个关键词[23-25],具有很好的被识别能力。利用公式计算此时该分词的权重:
(1)
公式(1)中ψi,j表示分词i在邮件j中出现的频率权重,ri,j表示分词i在邮件j中出现的次数。通过上述过程将无用的分词剔除掉,为邮件特征的提取与聚类做准备。
1.2 邮件特征空间构建
邮件经过预处理后,分词信息有些是连续信息,有些是不能直接使用,需要特征化的信息。为此,构建邮件特征空间中选择的特征属性包含邮件的结构特征属性,邮件的特征属性及属性说明等内容如表1所示。
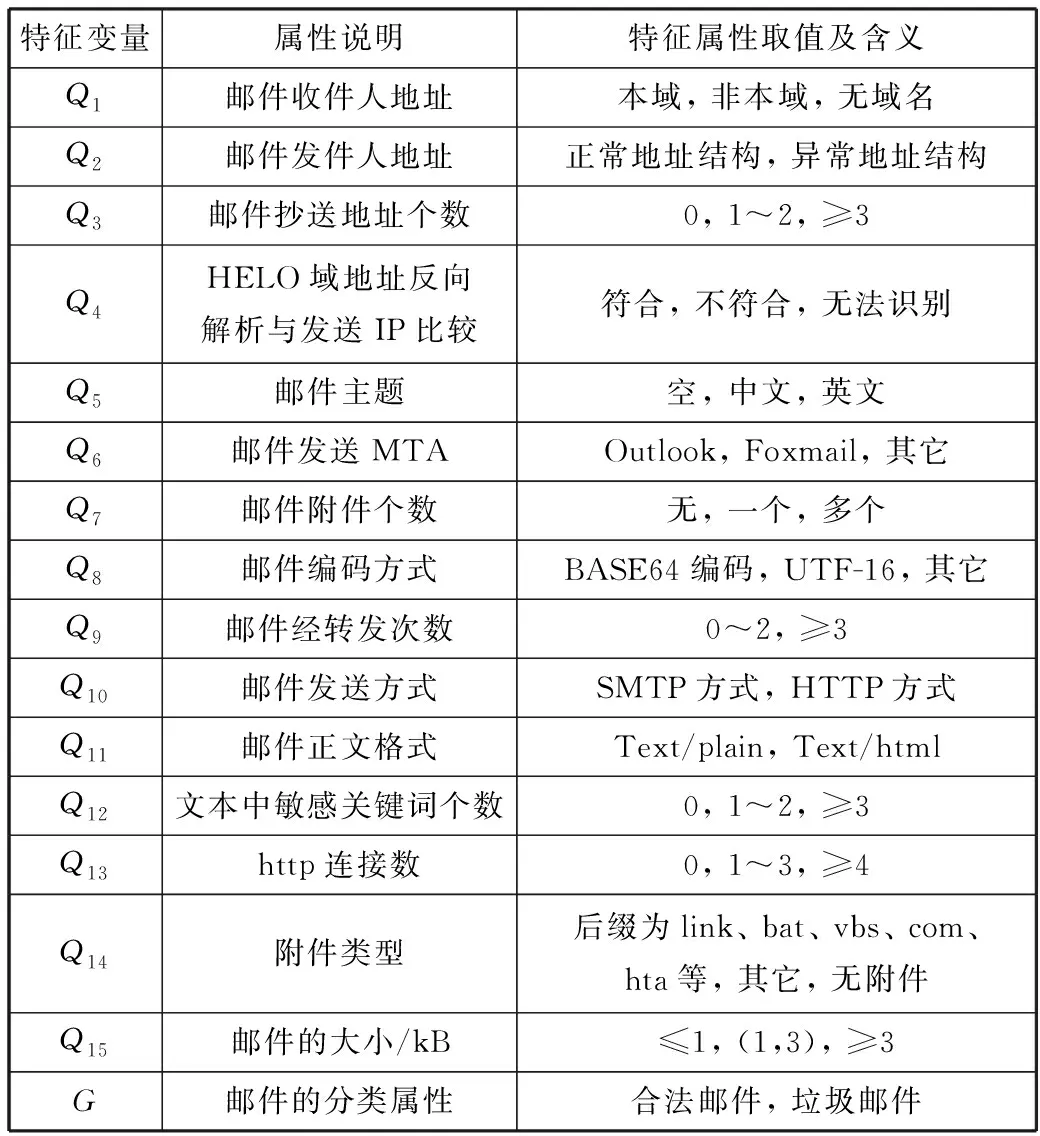
表1 邮件特征属性
依据表1中的内容确定特征集合,表中内容在邮件中均以分词的形式展示出来,选取经过预处理后的分词组成特征集合。
将分词作为描述邮件内容的基本特征,得到该邮件文本中包含的所有特征,对多个邮件段落的特征集合进行合并,得到包含多个邮件特征的特征集合。将各个邮件视为特征向量,投影到特征集合代表的向量空间中,其中向量空间的维度与特征集合中的特征一一对应。若邮件含某特征一次,则在该特征对应的维度上,赋予邮件特征向量的权重值,起始为0,之后逐渐加1,最终一封邮件中某分词对应向量维度的值约等于该词语在邮件文本中出现的频次。
1.3 邮件特征提取
在提取邮件特征之前,若仅使用邮件特征空间,无法避免常用词语对特征表示的影响,因此利用计算得到的分词权重ψi,j为分词赋值,赋值公式为:
(2)
公式(2)中w(i,j)表示赋值,ki表示所有文本中包含分词i的文本数[20,26-27]。经过赋值后,考虑邮件样本中包含的词语数过于庞大,因此,邮件向量化后得到的结果是高维的向量。针对高维向量,在优化特征结构的同时,实现对高维数据的降维。
假设邮件样本集为S,维度为c,样本数量为z,则样本表示为S={s1,s2,…,sz}。记si=(si1,si2,…,sic)T,则协方差矩阵为:
(3)

(4)
公式(4)中ηj为协方差矩阵的特征值,对应的特征值在协方差矩阵的特征值之和所占的比重为贡献率,UT表示第j列与之对应的ηj特征值向量构成的矩阵。
通过公式(4)设定单个分词对整个邮件文本的累积贡献率,使累积达到一定阈值的主成分代替原有的特征,作为降维后的特征集合。

(5)
通过公式(5)进行特征提取,得到所要提取的b个主成分H[28]。
通过特征提取,降低了特征的维度,邮件样本被量化为由更精简特征表示的特征向量,将特征向量作为聚类分析算法中的聚类中心,通过迭代计算达到识别垃圾邮件的目的。
1.4 垃圾邮件识别
将提取出来的邮件特征作为初始聚类中心,计算出每个邮件样本与初始聚类中心之间的距离,找出距离最近的聚类中心,将其赋值给最近的簇,重新计算每个簇的平均值。在上述过程中,不断进行迭代计算,直到准则函数收敛。采用平方误差准则得到聚类结果,平方误差准则如下:
(6)
公式(6)中en表示第n个类的聚类中心,要想识别出垃圾邮件,就要计算出全局最优解,必须满足迭代的最大次数,找出其中使F最小的聚类结果。在此情况下,计算出初始聚类中心与其它样本的欧氏距离,计算公式如下:
(7)
重复计算欧氏距离及赋值过程,直到达到最大迭代次数或新计算的F值与上一次迭代得到的F值的差别小于一个给定的阈值,结束计算后,输出结果即为识别出的垃圾邮件。至此,基于聚类分析算法的垃圾邮件识别方法设计完成。
2 垃圾邮件识别方法实验研究
2.1 实验环境及要求
由前面设计可知,垃圾邮件处理的基础是对邮件的分词处理,根据分词结果,通过聚类算法来实现对邮件的分类,因此实验包括2个环节:分词提取实验和邮件分类实验,具体实验环境、实验内容及结果分析指标如下:
1)实验环境:通过VB编写程序,Microsoft Access为数据库平台,Matlab为数据处理、分析工具。
2)实验数据:24 h内,监控某网络中心的邮件服务器所有邮件。
3)实验内容:基于聚类分析算法与基于IP地址的识别方法及基于关键词匹配的垃圾邮件识别方法在分词识别准确率、垃圾邮件分类准确率的对比实验。
4)分析指标:分词准确率和垃圾分类准确率。分词准确率即为算法提取的分词占所有准确分词的比例,垃圾分类准确率即为算法提取垃圾邮件占所有垃圾邮件的比率,用百分比表示。
2.2 实验准备
垃圾邮件识别方法的实验研究中使用大量邮件样本数据,其来源于网络中心的邮件服务器,为了更贴近真实,尽可能正确反映目前网络上垃圾邮件和合法邮件的比例。在实验准备中,邮件样本的选取采用多次随机抽样的方式,监听点与邮件服务器处于同一网段,对邮件服务器的端口25进行监听,对监听到的内容通过SMTP协议分析后将邮件还原,提取出邮件样本特征信息,建立训练样本库和测试样本库。邮件样本选取的过程如图2所示。

图2 邮件样本的选取
在研究中样本数据的收集使用网络监听的方式,每隔半个小时选择监听到的前20封邮件拷贝作为样本数据,重复上述过程,收集2000封训练样本数据和1000封测试样本数据。在实验准备过程中,利用代码编写一个监听程序对邮件服务器端口进行监听,系统平台使用Windows 10。监听到的结果如图3所示。
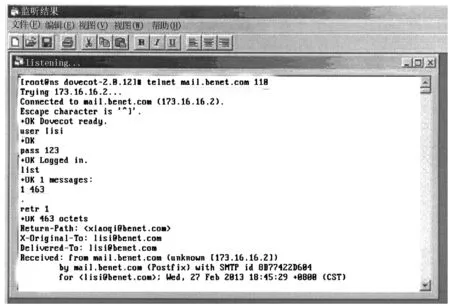
图3 监听到的邮件
监听到的邮件经过特征提取后,作为样本数据应用在后面的实验中,作为实验研究中的学习训练数据。在实验中使用Microsoft Access作为后台数据库。
2.3 邮件文本关键词提取实验分析
在垃圾邮件识别中,提取邮件文本关键词是关键的一步,在实验研究中,使用不同的垃圾邮件识别方法提取邮件文本中的关键词,关键词的提取与文本的长度有密切关系,以邮件文本的字符数作为变量,计算出不同识别方法提取的关键词的准确率。在实验中引用的对比识别方法分别是基于IP地址的识别方法和基于关键词匹配的垃圾邮件识别方法。实验结果如图4所示。

图4 不同识别方法提取关键词准确率实验结果
从图4中结果可以看出,随着邮件文本字符数的逐渐增加,2种常规方法的关键词提取准确率只在0.2~0.6之间,本文的垃圾邮件识别方法结果准确率在0.8~1.0之间,相比之下,本文的基于聚类分析算法的垃圾邮件识别方法关键词提取更加准确。
2.4 邮件文本分词精确度实验分析
邮件文本分词精确度是一项影响垃圾邮件识别方法的重要指标,通过一个简单的对比试验来分析不同识别方法的实际识别性能,利用少量的邮件来说明提出的基于聚类分析算法的垃圾邮件识别方法的优点。实验中的邮件样本如表2所示。
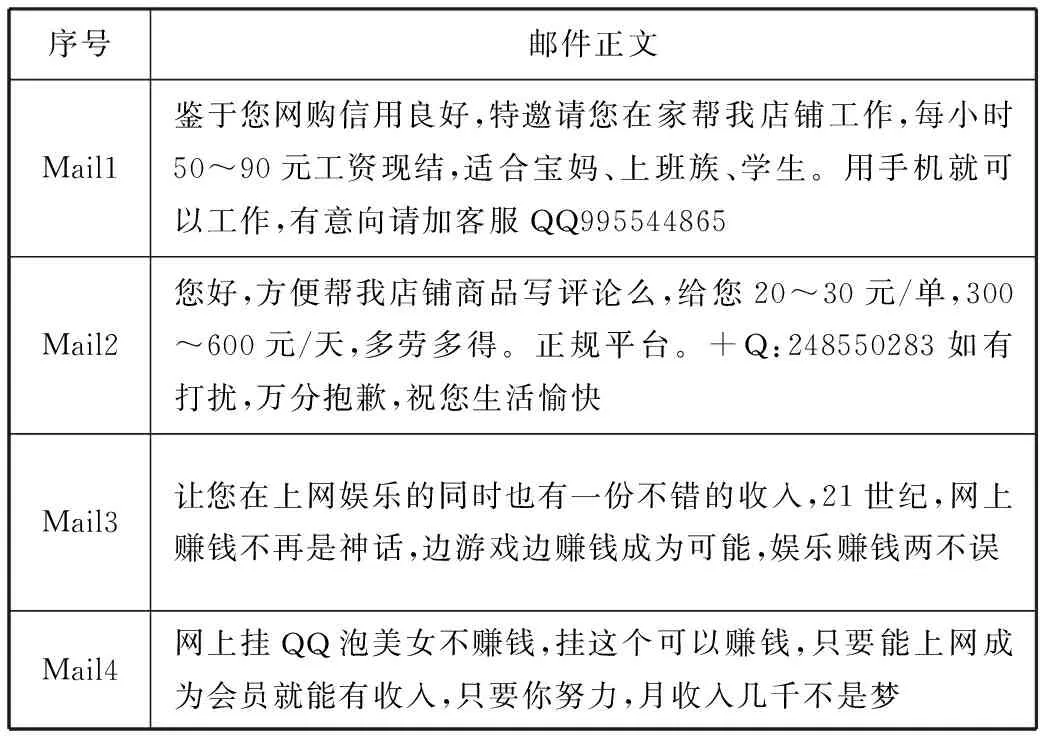
表2 邮件样本正文内容
使用不同的识别方法对表2中的邮件样本进行分词处理,处理后得到的分词结果如表3所示。
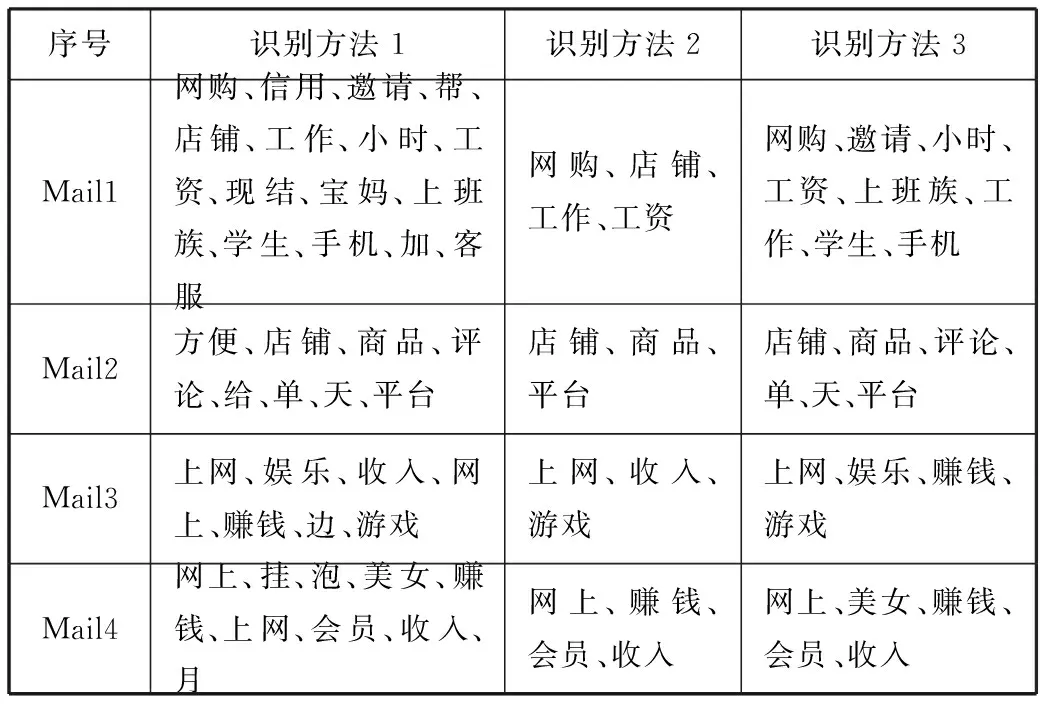
表3 不同识别方法邮件样本分词结果
表3中识别方法1对应的是基于IP地址识别方法,识别方法2对应的是关键词匹配的识别方法,识别方法3对应的是本文的基于聚类分析算法的垃圾邮件识别方法。对比观察表3中结果可知,识别方法1的邮件样本分词结果存在很多歧义词,识别方法2中分词过于简单,正常邮件与垃圾邮件没有明显的区别特征,识别方法3的分词结果更简单、精准,适合作为垃圾邮件识别的关键词。
2.5 邮件分类实验分析
邮件分类实验主要是对不同识别方法的识别性能进行进一步的分析与判断。在实验中使用Matlab软件和VB软件,随机选取实验样本,输出分类结果。结果如图5所示。

(a) 基于IP地址的识别方法邮件分类结果

(b) 基于关键词匹配的识别方法邮件分类结果

(c) 本文基于聚类分析算法的识别方法分类结果
图5中显示的圆点和三角点分别代表2类样本数据,其中三角点表示正常邮件样本,圆点表示垃圾邮件样本。观察图中结果,可直观地看出常规的2种识别方法均存在正常样本与垃圾邮件样本混淆的情况,而基于聚类分析算法的垃圾邮件识别方法分类结果中没有出现混乱的情况,所有样本数据均分类成功。结合上述实验研究中的关键词提取结果和分词结果,可知,本文的基于聚类分析算法的垃圾邮件识别方法对邮件内文本处理更加精准可靠,垃圾邮件的识别有效性更强。
3 结束语
全民信息化程度的加深使得垃圾邮件越来越泛滥,给用户和企业带来了很大困扰,因此,可通过识别垃圾邮件的方式来缓解这种情况的发生。在本文研究中主要根据垃圾邮件的分词特征,识别出邮件集合中其它垃圾邮件,在此过程中,借助了聚类分析算法的实时判别能力,达到了识别垃圾邮件的目的。但是研究过程中依然存在一些不足之处,如聚类的精度和效率之间的平衡问题,还需要进一步研究。
