一种基于文本卷积神经网络的推荐算法
2020-10-16王月海豆震泽
杨 辉,王月海,豆震泽
(北方工业大学信息学院,北京 100144)
0 引 言
随着云时代的到来,电子商务、在线新闻和社交媒体数据呈现爆炸式增长,据IDC预测,到2020年全球将拥有35 ZB的数据量[1]。这些海量的数据给人类社会带来了变革性的发展,但同时带来了“信息过载”和“长尾效应”问题,如何从这些纷繁复杂的数据中获取有价值的信息,成为当今大数据处理的难题。推荐系统作为解决这些问题的方法之一发挥着关键的作用,但同时也面临一些问题,比如用户对物品评级稀疏性的不断增加,以及如何去处理这些海量数据,这些都是影响推荐系统质量的主要因素。
协同过滤是推荐算法中最成功的算法之一,特别是基于模型的协同过滤算法因为其可扩展性强、精确、可以比较好地处理稀疏问题而得到大量的研究[2]。
传统的矩阵模型是协同过滤算法中的一种比较常见的建模方法。它是将原来的评分矩阵,近似地分解成2个小矩阵的乘积,将用户和物品的特征分别映射到各自的潜在空间中。在实际推荐中不再使用原来的大矩阵分析,而是用这2个带有用户特征和物品特征的小矩阵进行推荐。因为矩阵分解模型的简单和可拓展性,其得到了广泛的研究。随之涌现出了大量相关的算法,如比较经典的LFM算法,因为它只要求变成2个矩阵,从而避开了需要填充稀疏性矩阵的问题。虽然此方法比较简洁,但效果一般,原因是考虑的信息太少,无法学习到用户与项目间的深层次特征。之后Koren等人考虑到用户评分偏好问题,比如一些用户习惯性打低分,这些错误的偏好会对推荐的准确度有很大影响。基于此,Koren等人[3-4]在原来的矩阵上增加了用户和用户的偏置项,即BiasSVD。但针对LFM算法出现的问题仍没有得到有效的解决,数据的高稀疏性和海量数据处理仍是推荐系统需迫切解决的难题。
近年来,神经网络被大量运用于自然语言处理[5-6]、图像处理[7]、语音识别[8]中,并取得了卓著的效果。深度学习不仅具有自学习的能力,而且具有强大的特征提取和组合能力,因而可以解决传统矩阵分解的一些问题,比如稀疏性、维度风险、计算量、不能有效提取特征信息、可解释性等。基于此,深度学习被广泛运用到推荐系统中,成为近些年研究的热点。
为了解决数据高稀疏问题,一些推荐算法考虑加入辅助信息来提高评级精确度。例如文献[9]提出一种神经协同过滤模型(NCF),加入用户和物品ID信息。文献[10]提出一种深度协同推荐,把项目内容和用户行为信息结合起来,通过使用深度学习技术深层次表达用户特征,以此解决文本稀疏的问题。文献[11]提出卷积矩阵分解推荐模型,利用卷积网络来提取文本中的信息。文献[12]将循环神经网络(RNN)应用到推荐系统中,文献[13]用长短期记忆网络来记忆以前特征,达到精准推荐。
卷积神经网络广泛应用于图像分类、目标识别、语音识别等领域[14],并取得了很好的效果。同样地,在推荐领域,也需要一种复杂度不高、能够高效地处理海量数据的网络,所以本文采用文本卷积神经网络来改进Netflix推荐大赛冠军Koren等人[3-4]的BiasSVD模型。本文将针对此算法做出改进,结合深度学习具有强大的从样本中学习数据集本质特征的能力,以及能够从多源异构数据中进行自动学习的能力,采用词嵌入结合前馈神经网络的方法和文本卷积神经网络组合来提取用户和物品特征,最后采用神经网络并联方式输出预测评分项。本文算法经实验表明在面临极其稀疏的数据集,表现也比其它协同过滤算法要好,而且由于利用了用户对物品的交互信息,从而有了可解释性。本文算法在MovieLens-1M和MovieLens-10M数据集上进行的广泛对比评估表明,在RMSE和MAE指标上有了很大的提升。
本文工作主要如下:
1)提出词嵌入结合前馈神经网络方式和文本卷积神经网络组合来提取用户和物品的描述信息和交互信息,可提高提取特征的能力。
2)对BiasSVD算法进行改进,成功地将该算法对用户评分偏好的处理方式和本文算法结合起来,可提高评级预测的精度。
3)在MovieLens-1M和MovieLens-10M这2个真实的公开数据集上做算法对比实验,验证算法的可靠性。
1 方法描述
1.1 BiasSVD算法
矩阵分解是通过物品评分矩阵来推断表征用户和物品特征的,因为用户和物品特征之间具有高度一致性,所以能够进行推荐。这些矩阵分解的方法能够迅速流行起来源于它们有良好的可扩展性和比较精确的特性,而且也为很多建模的实际情况提供了很大的灵活性。矩阵分解模型将用户和项目特征映射到维度为ω的联合潜在因子模型,设对每个项目i相关联的向量qi∈Rω,每个用户u相关联的向量pu∈Rf,qi表示项目拥有的特性,消极的或积极的,而pu表示用户对这些项目的感兴趣程度,rui表示用户对项目的评分,则其预测值为:
(1)
这个模型源于SVD,当在处理稀疏的评分矩阵时,传统矩阵分解带来不确定性,即会出现很大偏差,所以在计算时往往需要对评分矩阵进行填充。然而遇到大量数据时这种方法既费时又不容易实现,而且处理较少项目时还容易过拟合,所以出现了改进版本:
(2)
其中,l表示数据集,λ为控制正则化程度的参数,采用随机梯度下降优化参数:
误差项:
(3)
按梯度下降对qi和pu进行优化:
qi←qi+γ(euipu-λqi)
(4)
pu←pu+γ(euiqi-λpu)
(5)
其中,γ为学习速率。因为存在用户偏好问题,这些因素的存在都严重影响了最后结果的精确性。例如,假设所有电影的平均评分为3.2分,即式(6)中的μ,小明是个挑剔的人,他倾向于对电影的评分要比电影平均评分低0.5分,即式(6)中的bu,而《泰坦尼克号》是一部很好的电影,它的评分要比平均评分高1.3分,那么bui=3.2-0.5+1.3=4,因此估计小明对《泰坦尼克号》的评分为4分。所以就有了显式隔离项:
bui=μ+bi+bu
(6)
其中,μ表示全局偏移量或平均评分,bi表示与项目有关的偏移项,bu表示与用户有关的偏移项。所以式(2)可以改写为:
(7)
由于偏差往往能捕捉到大部分观测到的信号,因此它们的精确建模至关重要。因此,其他研究提供了更精细的偏见模型[3-4]。
1.2 深度学习与BiasSVD算法的结合

图1 本文算法模型流程图
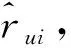
(8)
最后经过Adam算法优化:
(9)
得到电影特征矩阵和用户特征矩阵后用Top-N[16]推荐。
2 实验分析
2.1 数据分析
本文实验采用MovieLens数据集,MovieLens数据集包含多个用户对多部电影的评级数据,也包括电影元数据信息和用户属性信息。这个数据集经常用来做推荐系统,机器学习算法的测试数据集,尤其在推荐系统领域,很多推荐算法文献都是基于这个数据集的[2-4,17-20]。
表1与表2分别给出了MovieLens数据集MovieLens-1M和MovieLens-10M的数据分布。

表2 MovieLens-10M数据集情况
如图2所示,在对MovieLens整个数据集进行统计分析时,发现用户评分随着年龄的增长呈现递增趋势,这表明在此数据集上年龄越大对电影的评分标准越低。为了使算法对用户的情感分析更加精准,所以在提取特征时加上了年龄因素这个隐性特征。

图2 用户年龄—评分情况
如图3所示,在对电影年代和用户评分之间进行统计分析时,发现用户评分随着电影年代的递增呈现递减趋势,这表明在MovieLens整个数据集上大量用户可能更青睐于年代久一点的电影。这些都是影响用户评分的因素,所以在对算法进行评估时也加上了这一隐性特征。
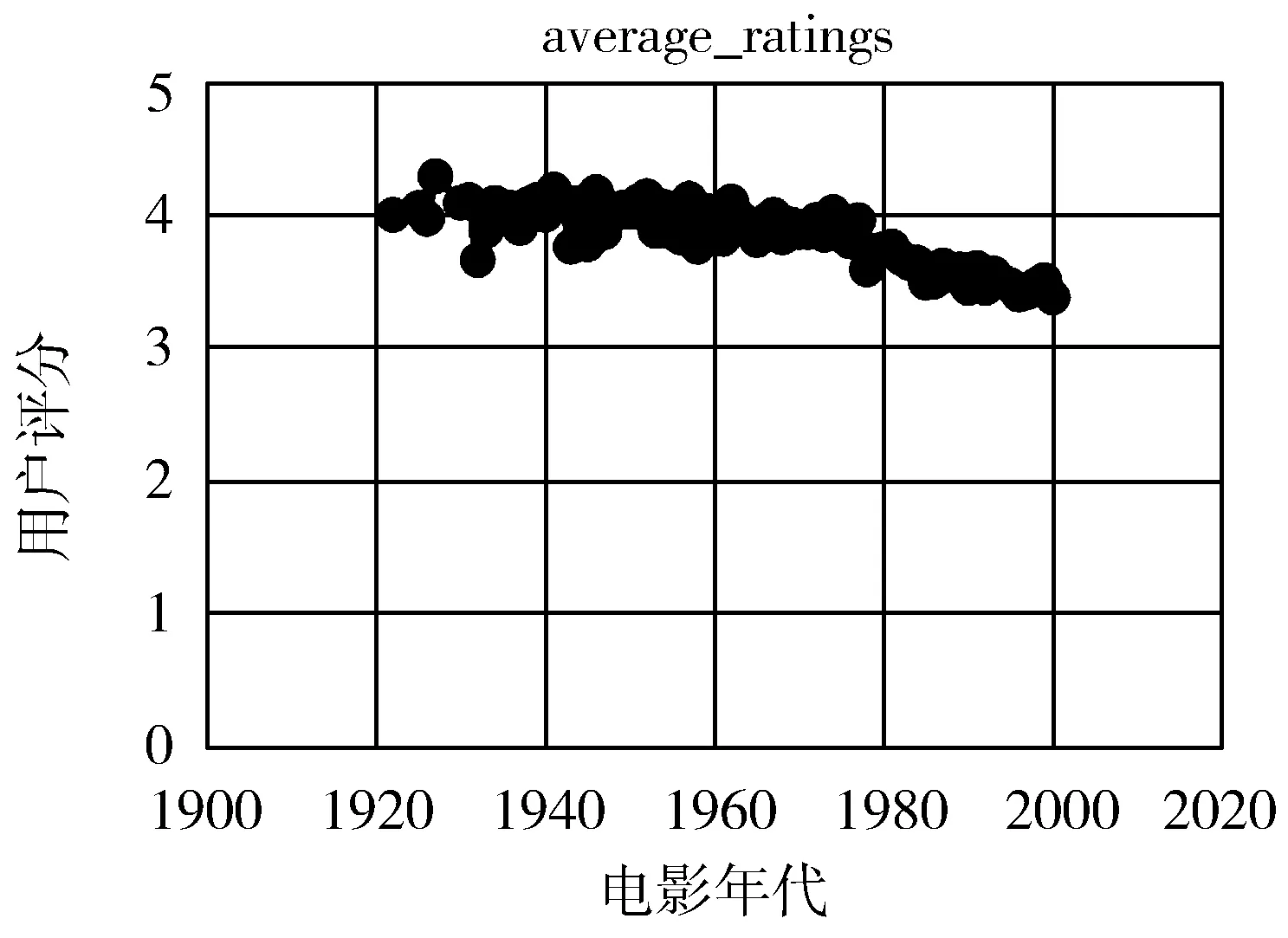
图3 电影年代—评分情况
2.2 评价指标
本节给出评价指标:均方根误差(RMSE)和平均绝对误差(MAE)经常被各种推荐系统用来评价系统优良的指标[2-3,11,17-19,21-23],百度、Netflix、阿里巴巴等公司举办的推荐系统大赛也用此指标。

(10)
MAE测量的是预测值和实际值之间的差值的绝对值。
(11)
2.3 实验结果与分析
将本文算法与7种常用的算法进行比较,这7种算法分别是:

2)SVD++。Koren[3]在2010年将显式反馈和隐式反馈集成到一个模型中,在当时实现了最先进的性能。
3)CDL (Collaborative Deep Learning)。Wang等人[10]在2015年发现利用辅助信息可解决用户对评分矩阵的稀疏问题,而协作主题回归表现得更好。
4)MLP (Multi-layered Perceptron)。He等人[9]在2017年将基于多层感知机网络加上ReLU激活函数,用于推荐。
5)ConvMF (Convolutional MF)。Kim等人[11]在2016年将卷积神经网络(CNN)集成到概率矩阵分解的算法。
6)NeuMF (Neural Matrix Factorization)。He等人[9]在2017年结合多层感知机MLP和广义矩阵分解GMF得到的算法。
7)LSTM模型。Yu等人[2]在2019年利用LSTM(长短期记忆神经网络)增强系统的可靠性。
由表3可以得到,在MovieLens-1M数据集上本文算法的RMSE较最先进的LSTM算法提升约19.75%以上,MAE约提升17.82%以上。表中提升比例的计算方法为:(LSTM算法值-本文算法值)/LSTM算法值。
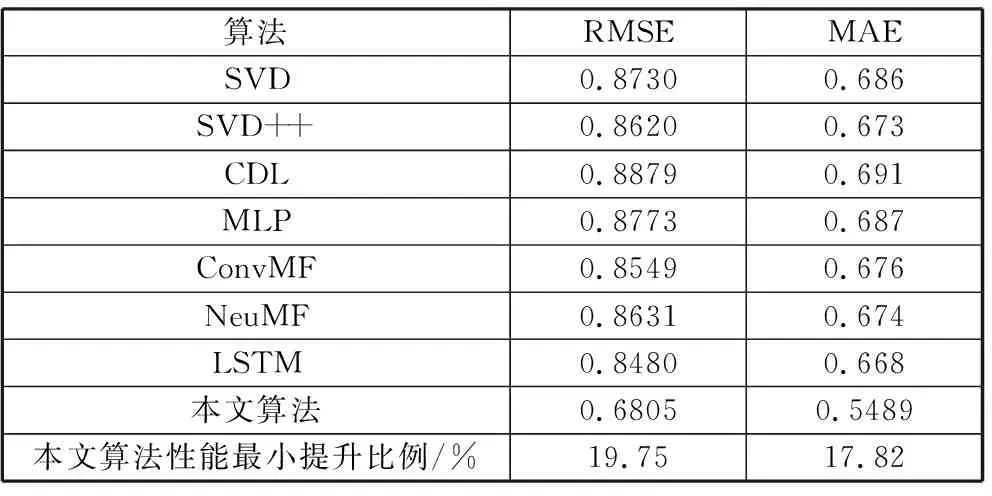
表3 MovieLens-1M数据集上各算法的RMSE与MAE
在表4中本文对用户与物品的交互信息tags做了处理,结果本文算法较LSTM算法的RMSE约提升35.6%以上,MAE约提升47.4%以上,可以得出用户与物品的交互信息在给用户推荐时起到非常重要的作用。

表4 MovieLens-10M数据集上各算法的RMSE和MAE
由表3与表4可以看出ConvMF算法表现较好,且与本文算法较为类似,也比较易于实现,故在图4中将本文的改进算法与ConvMF算法在MovieLens-1M数据集上进行了对比实验。其中Epochs在深度学习中表示全数据集迭代次数。

图4 本文算法与ConvMF算法在MovieLens-1M数据集上
由图4可以明显地看出,在预测观众喜好的准确性上,本文对BiasSVD算法改进的算法要明显优于ConvMF算法。
为了使实验结果更具说服力,本文分别对神经网络的迭代次数与学习速率进行了实验,如图5与图6所示。

图5 本文算法在不同数据集上不同迭代次数时

图6 本文算法在不同数据集上不同学习速率时
在图5与图6中可以看到学习速率对算法的影响明显,MovieLens-1M和MovieLens-10M数据集分别在学习速率为0.00001和0.001时达到最佳。
通过大量实验验证,可以看到本文的算法在MovieLens-1M数据集上相较效果最好的LSTM算法的RMSE提升约19.75%以上,MAE提升约17.82%以上,在MovieLens-10M数据集上RMSE提升约35.6%以上,MAE提升约47.4%以上。综上,可以得到,本文的算法在对用户情感、喜好的理解程度比效果最好的ConvMF算法与LSTM算法要深,更能满足用户的需求。
3 结束语
传统的矩阵分解算法因为只是简单地将物品与用户矩阵作内积,不能有效地提取用户与物品特征,卷积矩阵分解ConvMF与长短期记忆神经网络LSTM先后对其改进,但对用户与物品文档上下文理解不够,导致评级预测精度较差,本文提出用词嵌入结合前馈神经网络和文本卷积神经网络组合来提取特征的方法对BiasSVD算法进行改进。在MovieLens的2个真实数据集上进行广泛的实验对比,发现本文算法评级预测更加准确,验证了用户对物品的交互信息更加能反映用户的喜好,所以基于深度学习的用户和物品信息的提取仍然值得深入研究。
