基于改进随机森林算法的不平衡数据分类方法研究
2020-10-14杨霞霞苏锋黄戌霞
◆杨霞霞 苏锋 黄戌霞
基于改进随机森林算法的不平衡数据分类方法研究
◆杨霞霞 苏锋 黄戌霞
(宁德职业技术学院 福建 355000)
传统的分类算法难以满足不平衡数据的分类要求,研究一种有效、准确率高的不平衡数据分类算法具有重要意义。目前的研究主要以欠采样和过采样以及对应的一些改进方法提供实验数据。然而大多数实验方法不是使用范围有限就是侧重点不同,使少数类分类性能不佳,同时也难以区分强弱分类器。本研究从数据分布入手,提出一种改进随机森林分类算法。即先采用ADASYN算法进行过采样,再采用ENN算法进行欠采样。为了能更好区分强分类器和弱分类器的分类性能,最后采用加权投票机制。实验结果表明,该算法有较好的分类性能和准确度。
不平衡数据;欠采样;过采样;随机森林;分类算法
1 引言
分类是机器学习中的一种重要手段,它的作用主要是查找分类器,根据约束条件对一部分训练样本集构建一个抽象的模型,然后用这个模型对新的样本数据进行归类。常见的分类算法有决策树、神经网络、KNN算法、RF、朴素贝叶斯等算法[1]。这些分类算法通常假定数据集是平衡的,但现实生活中大部分数据集是分布不平衡的。例如,地震监测、医疗诊断、网络攻击检测、信用卡欺诈监测等信息[2]。而传统的分类算法难以满足不平衡数据的分类要求,因此,研究一种有效的不平衡数据分类算法十分有意义。
近年来,大量学者对于不平衡数据集的分类处理方法主要分为两个方面,即数据分布和算法改进[3]。从数据分布层面而言,主要是通过欠采样和过采样的改进。通过增加小众训练样本数的过采样和减少大众样本数的欠采样使不平衡样本分布较为平衡,从而提高分类器对小众的识别率。过采样需生成新样本,如果数据不平衡则会有小众样本被复制多份,导致训练出来的分类器会有一定的过拟合。SMOTE是典型的过采样算法,虽然增加了原始数据中小众的比例,但增加了类之间重叠的可能性,模糊了正负类边界,且容易生成一些没有提供有益信息的样本。而欠采样是通过舍弃部分多数类实例平衡训练集,可能会导致决策边界失真。
目前,随机森林算法被广泛应用于各领域。杨宏宇等人选取Permission和Intent两类信息特征属性进行优化选择,可以区分强、弱分类器,但对于其他特征如API、指令特征等没有检测[4]。郑建华等人提出了过采样和欠采样的混合策略的改进随机森林不平衡数据分类算法[5],该算法有利于不平衡比例较大的数据集,但对没有噪声的训练集不能够生成少数类样本。本文从数据分布入手,先采用ADASYN算法进行过采样,再采用ENN算法进行欠采样。为了能更好区分强分类器和弱分类器的分类性能,最后采用加权投票机制,该算法简写为AEIRF(ADASYN ENN Improved Random Forest)。实验表明,该算法有较好的分类性能和准确度。
2 随机森林算法
随机森林算法由Leo Breiman于2001年提出[6],该算法是由多棵相互独立的决策树分类器集成的大规模、高维度数据学习分类器。每棵决策树都是一个分类器,用重采样技术和随机抽取特征属性分类,最终通过投票原则确定较高准确率的测试样本类别。随机森林算法具体如下:
(1)应用bagging重采样技术从原始训练集S中有放回地随机抽取m个自助样本集,并设M个特征属性;
(2)在每一棵树的每个节点处随机抽取Mtry个属性,并对抽取的训练子集建立决策树;
(3)不断重复有放回地训练n次,直到建立所需的N棵决策树生成多棵分类树组成的随机森林;
(4)测试样本集中每棵决策树,均按该算法投票原则进行分类,最终确定分类结果。
对于一个含有m个样本的训练样本集随机采样中,n次采样都没有被采集到的概率为(1-1/m)n。当n趋向于无穷大时大约36.8%的样本没有被采集,这部分样本称为袋外数据,从而保证了训练样本集的差异性。
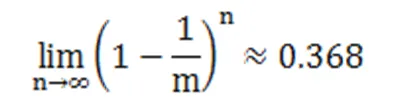
3 随机森林的改进算法
随机森林算法虽然有较高的准确率,对于缺省值问题也能够获得良好的结果,但采用的决策树投票原则,没有考虑强、弱分类器的差异,决策树采用相同的投票权重,不能充分利用分类效果好的决策树。因此,本文结合欠采样和过采样的混合采样策略和加权投票原则,对随机森林算法进行改进。在决策树的生成过程中,使用过采样和欠采样的混合采样方法生成训练子集,然后对各决策树通过加权投票方式,选出票数最多的样本为最终分类结果。算法具体如图1:
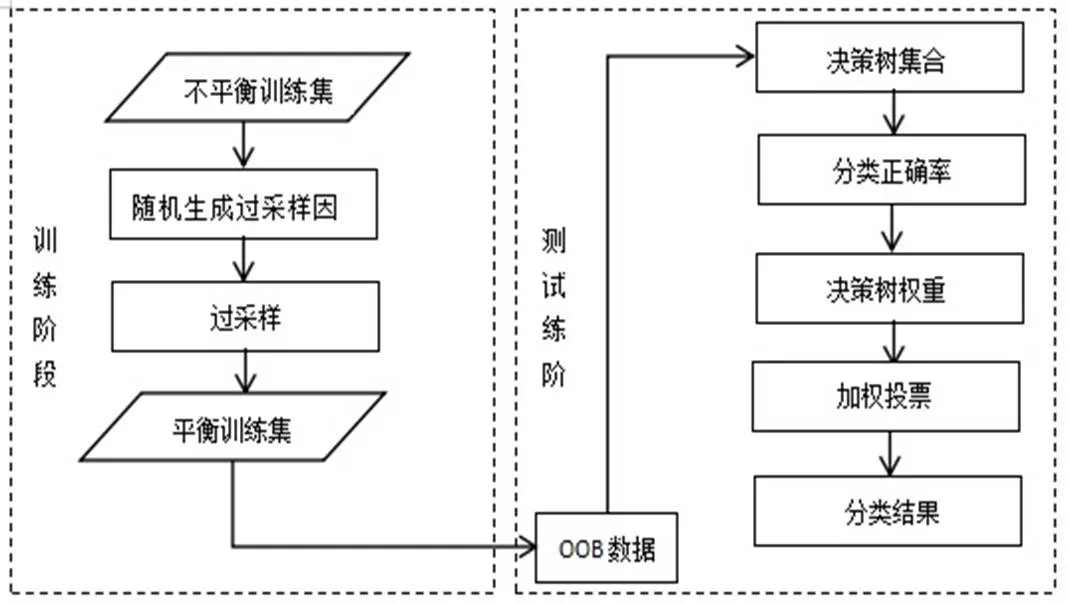
图1 改进的随机森林算法流程
4 实验与分析
4.1 数据集和评价指标
本研究使用的实验数据集是UCI中不同实际应用背景的6组公开数据集。其样本信息如表1所示。
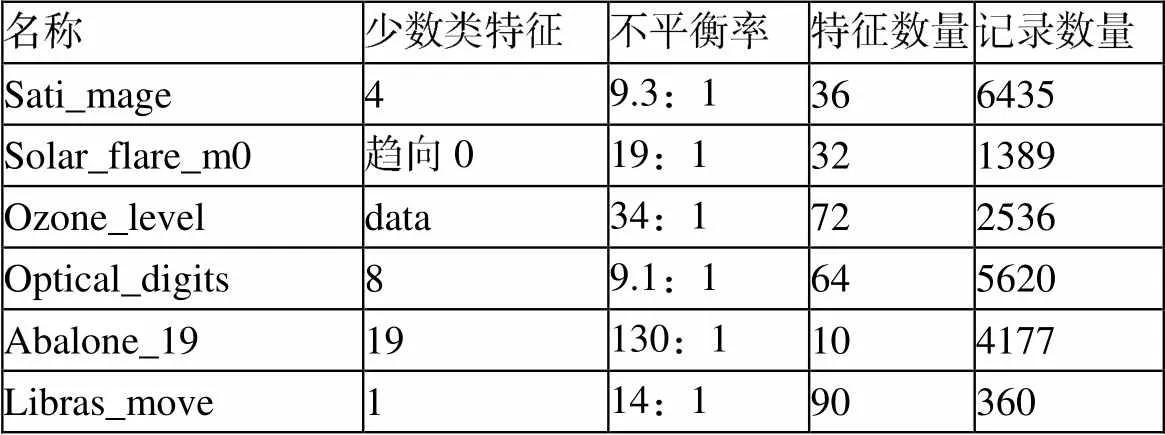
表1 实验数据集
对于不平衡数据集的分类性能评价以少数类分类的准确率和召回率作为评价标准。本文采用ROC曲线特征和坐标轴围成的区域面积来衡量准确率,当区域面积越大,分类器的预测性能越好。采用G-mean作为召回率评价指标,G-mean表示正类和负类召回率情况,只有当G-mean值高时,分类器性能越好。参数如表2。
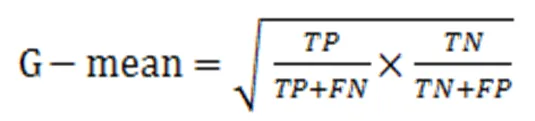
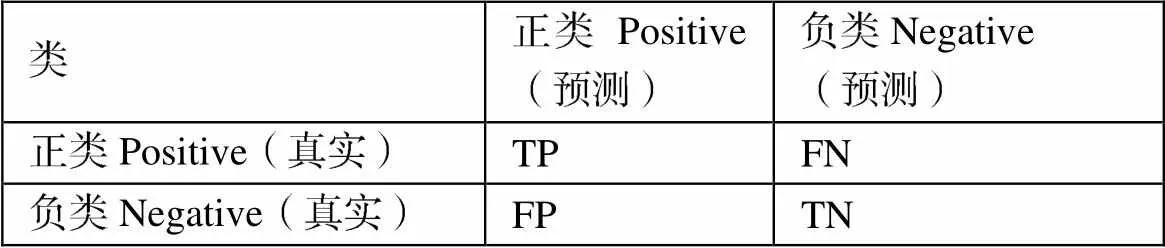
表2 混淆矩阵
4.2 实验设计及结果
本文选用4种常见的处理不平衡数据的分类算法,分别是CART、ADASYN、SMOTE+ ENN、RF。将其与本文提出的改进算法进行分类比较,分别计算各种分类器的两种评价指标。本实验过程中过采样因子都是取最大值,并按照表1所示的顺序样本集进行分类,结果如表3所示。
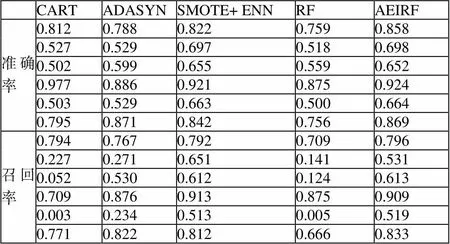
表3 相关分类算法准确率和召回率的结果比较
从表3可以看出,本算法的准确率高于其他3个数据集,与另外3个数据集相当;召回率有4个取得最优结果,在另外2个数据集上排名第二。该算法相比上述分类算法而言,分类性能提升了不少。比如在Sati_mage数据集上,AEIRF算法的准确率比SMOTE+ENN算法提升4%,比ADASYN和RF算法提升7%左右。
5 结论
为了研究不平衡数据集的有效分类算法,本文提出了一种改进随机森林分类算法。一方面结合决策树分类得到较好的分类效果,另一方面利用随机森林算法的加权投票原则进行处理。实验表明在6个数据集上,该算法有较好的分类性能和准确度。该实验的数据集不够完备和全面,今后的研究可进一步扩展数据集和提取更多地分类特征进行实验验证和分析,以便提高检测效率,也可以将该算法用于应用领域,并验证其泛化能力。
[1]王彩文,杨有龙.针对不平衡数据的改进的紧邻分类算法[J].计算机工程与应用,2020(07):30-38.
[2]杜臻.基于特征提取和异常分类的网络异常检查方法[D].南京:南京邮电大学,2019:6-7
[3]赵楠,张小芳,张利军.不平衡数据分类研究综述[J].计算机科学,2018,46(6A):22-27.
[4]杨宏宇,徐晋.基于改进随机森林算法的Android恶意软件检测[J].通信学报,2017,38(4):8-16.
[5]郑建华,刘双印等.基于混合采样策略的改进随机森林不平衡数据分类算法[J].重庆理工大学学报(自然科学),2019,33(7):113-123.
[6]BREIMAN L.Random forest[J]. Machine Learning,2001,45(1):5-32.
