卷积神经网络与迁移学习的颅脑癌症识别方法的研究
2020-10-12蒋佳旺陈艳王佳庆
蒋佳旺,陈艳,王佳庆
淮安市第二人民医院 设备科,江苏 淮安 223002
引言
颅内肿瘤又称脑肿瘤、颅脑肿瘤,是指发生于颅腔内的神经系统肿瘤,包括起源于神经上皮、外周神经、脑膜和生殖细胞的肿瘤,淋巴和造血组织肿瘤等[1-3]。研究表明颅脑肿瘤占全身肿瘤的5%左右,其中占儿童肿瘤的70%,且呈现逐年急剧上升的趋势,由于颅脑肿瘤膨胀的浸润性生长,迫使脑肿瘤压迫脑组织,导致中枢神经受损,临床表现主要为头痛,呕吐,视乳头水肿、视力减退,头昏、可发癫痫,甚至昏迷危及生命[4]。
脑瘤的诊断主要依赖于临床症状、体征、神经系统检查、眼底检查、头颅X 线摄片的阳性结果,采用头颅CT检查或磁共振成像进行复检,CT 检查具有分辨率高,并易于显示颅内肿瘤含有的钙斑、骨骼、脂肪和液体,CT可同时显示脑室、脑池、硬脑膜和颅骨,利于了解肿瘤与毗邻的解剖关系等优点,是目前诊断颅脑肿瘤的常见手段。根据影像学诊断,通常视颅脑肿瘤恶性程度可将肿瘤分为O 级、I 级、II 级、III 级以及IV 级五类分型[5-7]。高效、准确地检出颅脑肿瘤,提高颅脑肿瘤分型速度和准确率,不仅有助于本病的早期发现,同时可综合判断,制定有效的治疗措施。本文旨在使用颅脑肿瘤CT 层扫图像,采用卷积神经网络(Convolutional Neural Network,CNN)和迁移学习(Transfer Learning,TL)的方法对颅脑肿瘤不同分型进行自主学习、自动分型,以更好的满足临床需求。
1 模型与方法
1.1 卷积神经网络
CNN 是一种深度前馈人工神经网络,其实质是一种多层感知器,是一个具有多层的神经网络,而且这些层次之间具有明显的先后关系,是由输入层、隐含层、输出层组成。CNN 的特点在于隐藏层分为卷积层和池化层[8]。近年来,随着计算机运算速度的快速提高,CNN 取得了突破性的进展,现在,CNN 已经成为众多科学领域的研究热点之一,现已被广泛应用于语音识别、人脸识别、图像分割、医学图像处理等模式分类领域[9-10],CNN 结构图如图1 所示。

图1 卷积神经网络结构图
卷积层的主要作用是特征的提取,把输入的图像经过多个卷积核的卷积计算,可以得到多个卷积特征图,图像特征更多关注图像局部特征,因此卷积核大小一般小于输入图像大小[11]。当输入图像大小为Wi×Hi×Di(长×宽×通道数),指定卷积核数量K、卷积核大小F、步长S以及边界填充P后,经卷积后可得到特征图像Wo×Ho×Do,见公式(1)。
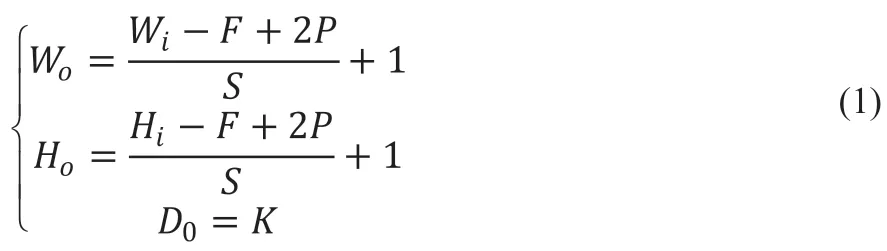
在CNN 中,卷积与卷积之间一般都会存在一个池化层,其作用主要为降维、扩大感知野、实现平移、旋转和尺度不变性,池化操作和卷积操作十分相似,也使用卷积算法实现,目前使用比较多的池化操作主要有最大池化以及平均池化[12]。
1.2 迁移学习
TL 是指一种学习对另一种学习的影响,或习得的经验对完成其他活动的影响,近年来得到持续的关注,被认为是机器学习的后续研究方向。在传统的图像分类学习中,为了保证训练后的网络具备较高的识别率,常规处理方式是网络使用独立同分布的训练集和测试集,此外可增加训练集图像数量,然而在实际应用中,同时满足上述两者的却很难做到[13-15]。
CNN 模型参数训练需要大规模的训练集进行训练,然而,对于医院而言,对脑肿瘤诊断而言,缺少大规模的标记样本,因此,脑肿瘤模式识别需要采用TL 的方法进行处理。TL 是将一个已经训练好的模型参数迁移到另一个新的神经网络模型中,并使用迁移来的参数辅助新的神经网络模型进行训练。目前所用的TL 可分为三部分:同构空间基于实例的TL,同构空间下基于特征的TL 与异构空间下的TL[16]。
1.3 Caffe框架介绍
Caffe 框架是深度学习的主要框架之一,是一种基于C 语言编写的开源框架,并提供面向命令行,同时设有Python 和Matlab 接口。Caffe 是通过Layer 来完成所有运算的,当Caffe 定义多层Layer 网络模型时,网络模型从Data Layer 开始、以Loss Layer 结束[17]。
1.4 ImageNet数据集与TL模型搭建
深度CNN 需要大量的数据样本对网络进行训练,来优化各节点参数,以完成模式识别的精确分类,为了使的学习的特征具有代表性和鲁棒性,大量的训练样本是模型优劣关键因素,而TL 得到广泛的应用得益于庞大的ImageNet 数据库的支持,该数据库于2009 年在网上公布。因为它规模足够大(包括120 万张图片),有助于训练普适模型,现在已经被广泛的训练集。
对CNN 而言,通过卷积核不断的对图像进行卷积运算,逐层对图像特征进行学习和提取,并将低层图像特征通过不断卷积核池化转变成高层表达,随着CNN卷积层数的增加,会导致图像特征过度学习、过度拟合现象的产生。因此,本文使用Caffe 框架搭建CNN,使用ImageNet 图像大数据集对网络进行预训练,训练过程中可以将预训练模型当做特征提取装置来使用,具体的做法是,将输出层去掉,然后将剩下的整个网络当做一个固定的特征提取机,从而应用到新的数据集中。使用ImageNet 预训练的模型可从Caffe Model Zoo 网站下载、修改和使用。接着,基于不同的数据集进行训练、验证和测试。这是一个微调的过程。最后,我们将网络参数设置为迭代次数104,动量因子为0.9,衰减参数为0.0005,初始的学习率为0.001,其它参数保持不变。得到CNN 网络参数和权重后将模型迁移至我院采集的脑肿瘤CT 序列图像数据训练集进行进一步训练,并及时修正模型权重和偏执值。最后使用训练后的模型对脑肿瘤CT 序列图像数据测试集进行测试。模型搭建过程见图2 所示。

图2 模型搭建结构图
2 实验设计与结果
2.1 图像预处理
本文采用的实验数据均来自淮安市第二人民医院影像科提供的720 幅颅脑CT 层扫图像,其中O 级、I 级、II 级、III 级、IV 级患者各144 例,图像大小均为1360×1024,均为RGB 三通道图像。本文使用小波变换对各颅脑肿瘤CT 层扫图像去除噪声,对感兴趣区域进行预处理,主要包括四步:① 手动标注感兴趣区域,并计算其最小外接矩形;② 使用OTSU 对图型进行二值化,最大连通区域予以保留,并进行一次开运算、一次闭运算和孔洞填充;③ 使用图像对比度方法利用指定的窗口的均值像素强度值来计算图像中每个像素的对比度对颅脑肿瘤区域进行增强,提高颅脑肿瘤区域显著性;④ 对图像进行扩增,基于颅脑疾病对体位(旋转)的不敏感假设,经过步长18o进行20 次旋转变换,对数据集进行增广处理,得到14400 例CT 图像。
2.2 实验设计
随机将预处理后的颅脑CT 图像按照7:1.5:1.5 分为训练集,测试集和验证集,即10 080 例CT 图像进行训练,2160 例CT 图像进行测试,2160 例CT 图像进行验证,在数据增强之前,训练图像、测试图像和验证图像均独立分开,彼此没有重叠。为了验证实验结果的有效性,本文安排了八组深度的学习模型:CNN 模型,包括FCNN、CNN、AlexNet、VGGNet 以及GoogLeNet 使用颅脑CT 图型进行实验,随机初始化网络参数;CNN+TL 模型:包括使用AlexNet、VGGNet 和GoogLeNet 模型在已标记的数据集ImageNet 上进行训练,然后使用颅脑CT 图像进行微调、优化网络,最后使用有优化后的网络模型进行测试,网络的性能评估采用灵敏度、特异性以及准确率进行评定。
2.3 评价指标
本文使用灵敏度(Se)、特异性(Sp)、准确率(Acc)作为评价指标,不同于二分类评价指标,定义灵敏度、特异性、准确率见公式(2)。

其中max为颅脑肿瘤分类总数,TP(True Positive)为真比例,真实类别为正例,预测类别为正例;FP(False Positive)为假正例,真实类别为负例,预测类别为正例;FN(False Negative)为假负例,真实类别为正例,预测类别为负例;TN(True Negative)为真负例,真实类别为负例,预测类别为负例。
2.4 实验结果
本文使用Caffe 框架,Tesla V00 GPU 上训练,训练时间约为5 h,实验结果如图3 和图4 所示。结果显示,在不使用TL 的情况下,AlexNet-TL 模型、VGGNet-TL 模型、GoogleNet-TL 模型在灵敏度、特异性以及准确率上均显著高于随机初始化网络参数的FCNN 模型、CNN 模型、AlexNet 模型、VGGNet 模型以及GoogleNet 模型。在数据集ImageNet 训练后的GooleNet-TL 模型颅脑癌症识别准确率达93.4%,AlexNet-TL 以及VGGNet-TL 模型识别准确率为86.9%和90.2%;未使用TL 的FCNN 模型、CNN 模型、AlexNet 模型、VGGNet 模型以及GoogleNet模型模式识别率分别为70.2%、76.5%、82.7%、80.9%以及82.5%。

图3 不同模型识别颅脑癌症结果对照图
GoogleNet-TL 网络训练损失曲线以及验证曲线,见图4。横坐标为GoogleNet-TL 模型的训练迭代次数,主纵坐标为训练过程中损失值,次纵坐标为验证过程中的准确率,当GoogleNet-TL 模型迭代4100 后训练Loss 收敛,训练过程中的颅脑验证集验证准确率达96.5%。

图4 GoogleNet-TL迁移学习网络训练损失曲线以及验证曲线
3 讨论与小结
肿瘤的良恶性以及具体分类的金标准诊断依据通常为“病理检查”,该诊断为后验性诊断方法,即在手术之后,切下的肿瘤组织送至病理科加以显微镜检查,根据肿瘤细胞形态做出最终的“确诊”,未经手术的患者,对肿瘤的诊断,通常借助于CT 或者MRI 对肿瘤进行初步“临床诊断”,准确的“临床诊断”和分类不仅有助于颅脑癌症的早期发现,可为颅脑肿瘤病情的综合判断,同时也有利于制定有效的治疗措施。然而,“临床诊断”通常受限于临床医生的经验[18]。
医学图像模式识别,图像分割等一直是医学影像学研究的重点和难点,常规的医学图像模式识别,通常需要提取图像特征集,但医学图像质量不仅受限于患者年龄、性别、身高、体重,同时还受病灶组织形状、位置,大小等方面的影响,因此常规图像处理方法很难完整的提取图像的特征,这也是医学图像模式识别准确率经久不高的原因之一[19]。随着计算机技术、大数据技术、云计算技术的不断发展,大规模数据运算、深度学习逐渐应用于各个领域,联合TL的CNN通过深度卷积获取医学图像“深度特征集”,联合TL 的CNN 现已被应用于医学图像分类,疾病诊断,必然是未来智慧医疗发展的主要载体[20]。本文通过对颅脑肿瘤CT 图像进行降噪、增广等预处理,并构建了八组深度的学习模型,其中五组为随机初始化网络参数的CNN,三组为经过ImageNet 训练的CNN 模型,实验结果表明,引入TL 的各种模型颅脑肿瘤模式识别准确率、特异性和灵敏度性能均得到显著性的提高,GoogleNet-TL 准确度达93.4%,图像识别度得到较大的提升。
然而,在进行机器学习辅助诊断的研究过程中,我们发现了一些值得注意的地方:医学图像的采集和诊断实质上是分开进行的,在人工智能、机器学习辅助诊断系统构建过程中,规范和建立医学图像质量评估系统有助于提升医学图像诊断系统的整体效能;目标分割是医学领域中一个重要课题,如何使用分割算法代替手动勾画已经成为机器学习辅助诊断的难点和重点;交叉验证是关键,在课题组研究过程中采集的图像具有单一性,即单型号设备采集的CT 图像,在研究过程中往往会经过人工剔除问题图像、病灶形状等问题图像,而选择“优质图像”进行处理,对于跨设备、跨数据集以及算法移植将会带来不可预知的困难。当然,联合TL 的深度CNN 一直不断在更新和改进中,针对目前飞速发展的医学影像学,机器学习辅助诊断系统的研究仍需多学习、多中心协作,以获取大样本的医学影像数据能够使得深度学习模型距离临床应用更近一步。
