融合语义特征的加权朴素贝叶斯分类算法
2020-09-29邱宁佳贺金彪薛丽娇赵建平
邱宁佳,贺金彪,薛丽娇,王 鹏,赵建平
(长春理工大学 计算机科学技术学院,吉林 长春 130022)
0 引 言
数据分析和挖掘已成为文本分类领域内研究的重点。朴素贝叶斯算法进行分类既简单又高效,但由于算法本身的属性条件独立性假设回避了关联关系,使得算法的分类效果有所降低,因此在提高朴素贝叶斯的分类性能问题上大多数学者做了广泛的研究和改进。目前特征处理方面的改进主要有选出最优特征集[1-3]、结合特征选择方法修改权重[4-6]等方法,以提高算法的分类精确度;罗慧钦等在隐朴素贝叶斯模型中加入文本属性的依赖性和独立性约束条件,从而提高了文本情感分类的准确性[7]。此外,针对提取的不同关键特征重要程度的判定问题,一些学者通过构建相应的加权函数计算各特征的不同权值[8-10],用于区分不同特征类别的贡献度来改善朴素贝叶斯模型的性能。Jiang等提出根据不同类中属性分配特定权重的细粒度加权方法,使模型在分类性能上具有一定优势[11];Yu和Lee分别使用属性值之间差异计算和KL测度方法,对特征项的权值分配相应权重,显著提高了朴素贝叶斯的性能[12,13]。
上述研究均在不同程度上提高了朴素贝叶斯算法的分类性能,但缺少语义关联性研究方面的探讨,在此基础上本文综合考虑特征处理和属性加权,提出一种融合语义特征的加权朴素贝叶斯分类算法。首先在传统TextRank算法(图模型排序算法)的基础上,将特征间的语义相关性引入到图模型中,通过Google距离求解节点的初始权重。然后使用特征加权的方法来降低独立性假设的影响,最后利用改进的加权朴素贝叶斯模型进行分类。
1 特征提取
基于图模型的TextRank算法在计算时单纯的设定所有分词初始权值均等,忽略了分词本身的属性,直接影响分类的效果。本文利用词语间语义相关性重新计算节点权值,实现TextRank算法的改进工作。
1.1 TextRank算法原理
传统的TextRank算法是由PageRank改进而来,将每个词语作为网页节点根据重要程度进行连接构造带权网络图模型,并利用投票机制对节点进行排序,最终选择TOP-K个词语作为候选关键词。TextRank是一种有向带权图模型,表示为G=(V,E), 其中V是图模型构成的节点集合,E是图模型构成的边集合,具体的图模型如图1所示。
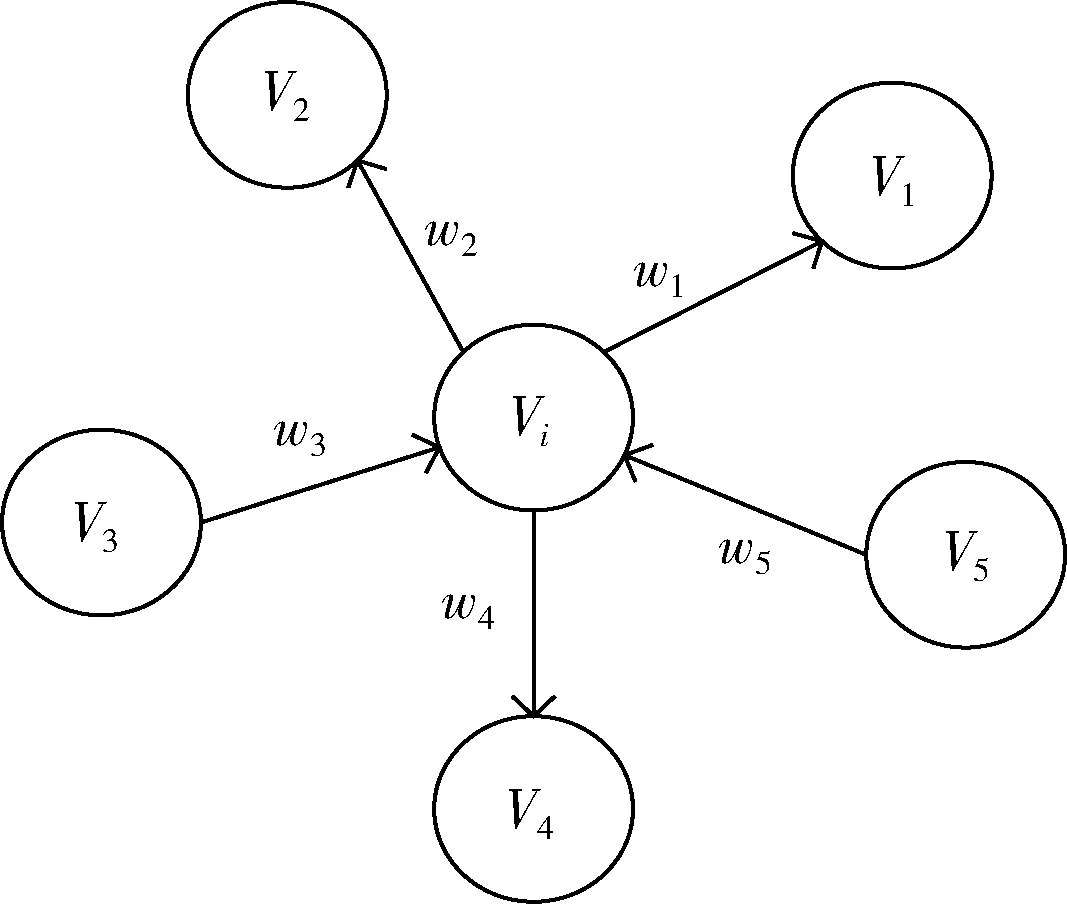
图1 TextRank关键词图模型
图中wji为任意两节点Vi与Vj之间边的权重,对于给定的任意节点Vi,In(Vi) 表示Vi节点的所有入度节点集合,Out(Vj) 表示Vi节点的所有出度节点集合,δ为阻尼系数,表示当前节点能够跳转到其它任意节点的概率,节点S(Vi) 的权重计算公式为
(1)
1.2 NGD-TextRank特征提取算法
在TextRank算法中认为任意两个节点之间的联系是相同的,设定初始权重均等,忽略了节点间语义关联性对节点自身产生的影响。针对上述问题本文采用节点间的语义相关性来表示节点间的权重,Google距离通过衡量语义相关性,应用于搜索引擎的结果匹配程度上具有较高的精确度,在处理分析文本概念间相关性和语义标注领域能取得较好的效果。本文使用Google距离计算节点间语义相关性作为节点间的初始权值,通过TextRank模型迭代训练至收敛得到各节点的最终权重值,再根据最终结果进行TOP-K排序提取关键特征。
设定存在文档集合D={d1,d2…,dn}, 第n个文档内特征集合V={v1,v2,…,vi,…,vj}, 利用Google距离计算词语vi,vj在当前文档中出现频率的高低来测量概念间的语义距离,分析语义层面上的联系程度。词语间的语义距离越小,表明相关联系越紧密,反之越疏远。因此,使用Google距离计算两个不同特征间的语义相关性来表示权重wji, 其任意两个特征的语义相关性可表示为
(2)
式中:df(vi) 代表包含了词语vi的文档数量,df(vj) 代表包含了词语vj的文档数量,df(vi,vj) 代表同时包含了词语vi和词语vj的文档数量,N代表文档集的总数。
最终的权重计算公式为
wji=(wNGD(vi,vj)+1)-1
(3)
与传统算法相比,上述wNGD计算方法从语义层面上反映了词语之间的联系程度,引入语义联系计算节间点的权值不仅能弥补设定初始权值相等的不足,还能在一定程度上减少不相关冗余特征的出现,而具有高相关性的词语能够获得更高的权值。使用改进的NGD-TextRank算法得到的关键特征相较于原算法质量更高,更适用于分类。下面给出特征提取的算法流程:
算法1: NGD-TextRank算法
输入: 数据文档集合D={d1,d2…,dn}, 关键特征集合T, 关键特征个数K
输出: 更新后的关键特征词集合T={t1,t2…,ti}
(1) 预处理得到词语集合V={v1,v2,…,vi,…,vj}
(2) setT=∅ //设定初始关键特征词集合为空
(3) setK//设定取前K个关键特征词
(4) for eachD
(5) for eachvi,vjinV
(6) 通过式(2)计算词语间语义相关性wNGD(i,j)
(7) end for
(8) end for
(9) 根据式(3)计算初始权重wji
(10) for eachviinV
(11) 计算S(Vi)
(12) end for
(13) 对vi按S(Vi) 值降序排序
(14) 取TOP-K特征加入特征集合T
(15) 输出更新后的关键特征词集合T={t1,t2…,ti}
2 特征加权朴素贝叶斯算法
2.1 朴素贝叶斯算法
朴素贝叶斯算法是假设各特征相互独立的分类方法,求解特征项ti在相互独立出现的条件下属于各个类别cj的概率P(cj|ti), 则将归属类别的最大概率结果作为待分类文档的真正类别,具体的朴素贝叶斯公式为
(4)
然而,朴素贝叶斯公式在分类过程中属性之间相互独立在现实生活中往往很难满足。在文本分类中,各特征项之间必然会存在一定的联系,忽视朴素贝叶斯算法特征独立的假设会降低算法的分类性能。
2.2 加权朴素贝叶斯算法
Hellinger距离具有对称性可以衡量两个概率之间的距离,因此能够作为两个分布之间差异的适当度量函数。本文采用该距离函数对某个特征项在分类过程中所含信息量的多少进行度量,表示为文本类别在某个特征词出现前后时概率之间的差异,具体的计算公式为
(5)
式中:p(cj|ti) 表示含有特征词ti的cj类文本在整个文本集中的概率,p(cj) 表示cj类文本在整个文本集中的概率,n表示类别总数。
上述Ht衡量了同一特征在不同类别间的影响程度,其值越大代表该特征携带的信息量越大,越具有类别代表性,说明该特征在划分类别能力上的贡献度越大。然而上述加权过程忽略了特征词在某一类别内的集中情况,即词频集中度对特征权重的影响;同时没有体现该类包含特征项的文档分布,以及文档空间内不同特征个数对特征词类别代表性的影响,因此应该从文档差分度上考虑特征词在分类过程中的重要性。
本文考虑词频集中程度对特征词权重的影响去构建加权函数,以类别cj中特征词ti的数量占总特征词的比例表示特征词ti在类别cj中出现的可能性,并根据特征词ti在待分类文本中的词频,定义了词频集中度加权函数,具体公式表示为
(6)
式中:cj_tf(ti) 表示在类别cj中特征词ti的词频,cj_tf表示类别cj中的特征词总数,d_tf(ti) 表示在当前文档中特征词ti的词频。从词频集中度可以量化该特征词在某一类中的分布情况,如果特征词的词频集中度较高,说明此特征词具有较均匀的类内分布,就越能代表该类别。
在某个给定的类别中,包含特征项的文档出现频率以及文档中含有的不同特征词数量的差异,在很大程度上体现特征词分类能力的高低。在考虑类内文档分布情况时,本文关注了含有特征词ti的文档空间内不同特征的个数,即文档特征空间大小,以此为依据定义了文档差分度加权函数,具体公式表示为
(7)
式中:cj_df(ti) 表示在类别cj中含有特征词ti的文档数,cj_df表示类别cj中的文档总数,cj_d(tfavg) 表示类别cj的各文档中不同特征词的平均数,即文档特征空间的大小。分类能力强的特征词应该分布在该类的多数文档中,也就是该类中包含特征词ti的文档占文档总数的比例越高,特征词越具有类别代表性;同时该类各文档中不同特征词的数量越少,说明该类文档的特征空间越小,此时特征词分类的贡献程度越强。
结合上述思想,本文提出特征加权朴素贝叶斯公式,考虑特征词在类别间的信息量大小,并分析词频集中度和文档差分度对特征词重要性的影响,综合计算特征项的权重值,最终得到改进的加权朴素贝叶斯公式和权重计算公式如下
(8)
w(i,j)=Ht×TCF×TDS
(9)
其中,w(i,j) 值越大,特征词获得的权重越高,对分类的贡献程度越大;反之,w(i,j) 值越小,特征词获得的权重越低,对分类的贡献程度越小。使用上述特征加权方法是对每个特征项约束条件的放宽处理,通过对每个特征项重新估量分配不同的权值,能够弥补传统朴素贝叶斯算法在分类过程中各属性相互独立假设的不足,以提高分类器性能。
3 NTWNB算法
属性独立性假设一直是朴素贝叶斯分类算法面临的问题,解决属性独立假设问题对最终的分类结果影响较大。本文提出一种融合语义特征的加权朴素贝叶斯分类算法(NTWNB),首先对分类文本进行数据预处理,并使用Google距离重新计算词语间相互关联程度来代替原始权重改进TextRank算法进行特征提取,然后以提取的关键特征词集合构建向量模型,并从特征词信息量、词频集中度和文档差分度3个方面分析特征词的综合权重,使用改进的加权朴素贝叶斯分类算法进行分类,整体解决方案如下:
(1)数据预处理。将训练文本经过数据解析、进行分词、过滤停用词等操作后得到初始词语集合。
(2)关键特征选取。依次对初始集合中词语使用Google距离计算语义相关性得到新的权重,将新的权重值带入到TextRank中重新计算,根据计算结果进行排序选取前TOP-K作为关键特征集合。
(3)向量模型构建。使用(2)中的NGD-TextRank算法提取出的关键特征进行向量化表示,构建特征向量模型。
(4)综合权重计算。分别使用Ht,TCF和TDS表示特征信息量、词频集中度、文档差分度,综合分析得到特征项的权重表示w(i,j), 并计算每个特征项的权重值。
(5)特征加权改进。根据(4)中的计算权重方法改进传统朴素贝叶斯公式,得到加权朴素贝叶斯算法。
(6)文本类别输出。对待分类文本使用(5)中分类器模型进行类别预测。以输出结果作为该文本类别。
完整的算法结构如图2所示。

图2 算法结构
4 实验及结果分析
4.1 实验环境和数据
实验在Pycharm平台上使用Python3.6语言开发,实验配置为IntelCore i5-7500 @3.40 GHz四核,16 GB内存,windows10操作系统。为了验证本文提出的算法可行性,本研究采用的热线咨询数据来自于某运营商客服热线平台数据库,该平台每月统计的用户咨询文本数量在 5-10 万条不等,便于研究选取训练集30 000条文本、测试集6000条文本作为数据集对象,每条文本中记录了用户整个通话过程的全部内容。设计实验时具体的数据集特征见表1。

表1 数据集特征内容
4.2 评价指标
本文使用上述实验数据进行二分类,为了对上述算法的优劣性进行评估,选取ROC(receive operating characte-ristic)曲线及曲线下面积AUC(area under curve)值作为本文提出的算法评估标准,由式(10)、式(11)可以看出使用伪正率(FPR)和真正率(TPR)分别作为横纵坐标绘制曲线并计算AUC值,可以得出数值越大算法分类性能越好。
以用户查号意向监测为例,设TP表示用户意向为查号且被分类为查号的情况,FP表示为用户意向为非查号但被分类为查号的情况,FN表示为用户意向为查号但被分类为非查号的情况,TN表示为用户意向为非查号且被分类为非查号的情况。则伪正率表示为在所有实际意向为非查号的样本中被错误地预测为查号的比例,公式为
(10)
真正率表示为在所有实际意向为查号的样本中被正确预测为查号的比例,公式为
(11)
4.3 改进算法实验验证
实验1:特征提取效果对比分析。
本文分别使用改进前后的特征提取算法对同一数据集30 000文档数据做特征提取分析,表2列出了两种算法选用特征词数量50为间隔进行对比,分析特征数量变化时因提取的特征词不同造成的覆盖文档数和准确率变化对比。
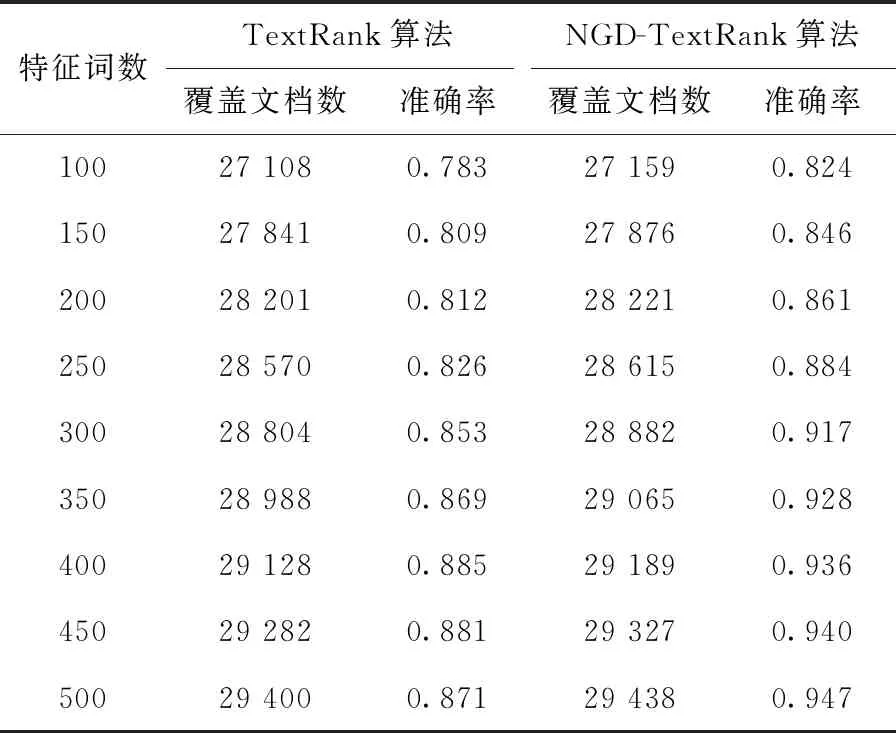
表2 2种特征提取算法对比
通过表2可以发现两种算法都能够有效地利用词之间的关联性取得较好的效果,而在相同维度下改进的NGD-TextRank算法与传统算法相比提取到的关键特征文档覆盖率更高,这是因为基于语义距离计算的特征权重充分体现词之间在文档中相关联系的重要性,引入语义距离对相关特征节点图边权重进行重新计算能够获得更重要关键特征,表明在特征提取时融入语义相关性具有更好的特征提取效果。从不同特征维度分析,可以看出改进后的算法随着特征词数量的增加整体呈现上升的趋势,而原始算法则随着特征词的增加准确率上升到某一最高点后逐渐开始下降,这种现象是因为特征词中含有部分关联性弱、代表性差的冗余特征造成。当特征词维度为400时传统算法准确率达到最高值,而改进后的算法在特征维度为250时已经实现原始实验的分类效果并在后期持续上升,说明改进后的算法可以筛选出具有高分类能力的代表特征,剔除冗余属性。上述对比可以看出改进后的算法具有降维的作用,用更少的语义特征可以得到更准确的分类效果。
实验2:加权效果验证。
为了验证权重前后变化的合理性,表3展示了部分特征词以及它们在权重计算前后的对比结果。同时考虑本文改进算法的有效性,设计实验使用传统TextRank-NB算法以及其加权形式和融合形式进行ROC曲线分析和AUC值比较结果如图3所示。

表3 加权前后特征权重对比

图3 改进算法ROC曲线和AUC值对比
由表3可以看出选取的特征词通过使用Hellinger距离衡量了特征词的信息量大小,信息量越大说明其分类贡献度越大,并根据特征词在某一类别中集中度的提高来提升类别代表能力,以及分类贡献度高的特征词其文档差分度越高来体现特征词分类贡献程度的差异。综合考虑上述因素共同作用下得到的最终权重可以看出改进后的“想查”、“查下”等权重提升较大,更能反映出类别的代表能力,反之“电话”、“医院”等权值相应降低,由此可以看出对类别代表能力弱的特征词经过重新计算后权重都有相应下降变化,说明了特征词权重变化的合理性。通过图3可以看出,在使用NB或WNB相同分类模型时,结合改进的NGD-TextRank特征提取算法得到的ROC曲线要优于传统TextRank算法,对应的AUC值也提高了2%,这主要是因为改进算法考虑语义重新计算后提取的特征词更能发挥分类作用,明显提高算法的分类性能。在使用TextRank或NGD-TextRank相同特征提取算法时,使用改进的加权朴素贝叶斯分类器要比传统的分类器ROC曲线效果更突出,改进分类器的AUC值相应提高了7%,说明了传统朴素贝叶斯算法由于其条件独立假设限制了特征词的作用而影响了分类的性能,通过特征词的信息量、特征分布情况和文档特征数量的加权实现了分类器综合考虑特征的权重,增强了分类过程中特征词之间的差异性以提高分类性能。NGD-TextRank-WNB算法的ROC曲线和AUC值均高于其它算法表现,表明本文算法能够保证提取特征词的优越性时,同样也解决了传统朴素贝叶斯方法没有根据不同特征词其重要程度进行衡量影响分类准确率的问题,因此在进行分类时具有优势,是一种较好的分类算法。
实验3:多数据集普适性验证。
为了更好地体现本文提出的NTWNB算法的分类效果,通过对比各算法在不同数据集上的实验结果进一步分析。实验选取了表1中4个具有代表性的数据集,其中前两个数据集为二分类不平衡数据集;选取的数据集3和数据集4分别是二分类和多分类平衡数据集,同时数据集的样本存在明显差异。在各类型数据集上设计实验与文献中提到的LAWNB[14]和TWNB[15]以及传统NB算法进行对比,表4记录了算法在各数据集上的分类性能对比结果,4种算法的F值综合评价指标如图4所示。

表4 4种分类算法性能对比

图4 不同数据集各算法F值对比
通过表4可以看出,4种算法在不同数据集上的分类性能具有明显的不同,这主要因为数据集分布情况对分类结果具有较大影响,但是本文改进的NTWNB算法在各数据集上表现最优,使用特征词的信息量、特征分布情况和文档特征数量的加权改进处理相应数据集得到的准确率、召回率都高于其它算法,说明本文提出的特征加权算法是提高朴素贝叶斯分类性能的一种有效方法。由图4可以看出,在4个不同数据集中传统的朴素贝叶斯算法F值皆为最低,经过相应改进的算法均有所提高。在不平衡数据集上,其它改进的算法性能提升到85%,而本文提出的分类算法性能提升更为明显达到了92%,充分验证了针对数据集样本差异考虑词频集中度和文本差分度进行特征加权的重要性。在二分类和多分类平衡数据集中,本文改进的算法在分类表现上提升幅度相近,从而体现出本文提出的算法既适用于二分类又适用于多分类。综合对比本文提出的算法具有更好的分类效果。
5 结束语
本文针对传统特征提取算法忽略语义相关性以及传统朴素贝叶斯算法的条件独立假设性而引起的分类准确率降低问题,提出一种改进的NTWNB算法。首先融入词语间语义相关性对TextRank算法节点初始权重进行重新计算,提取出具有相关代表性的关键特征;然后在分类过程中以特征词的Hellinger信息量作为初始权重,结合特征和文档分布情况求解最优的加权函数组合;最后使用加权函数改进朴素贝叶斯分类模型。采用ROC和AUC作为本文算法的评价指标,通过与其它算法在不同数据集上的实验对比,最终得到本文改进的算法具有更高的分类效果。但是本文的方法在多分类数据集上的表现仍有待提升,下一步将针对多分类问题进一步研究,扩大本文算法的普适性。
