智能优化算法及人工神经网络在催化裂化模型分析中的应用进展
2020-09-27金继民
杨 帆,周 敏,金继民,曹 军
(1.四川大学 计算机学院,四川 成都 610065;2.联想集团数据智能应用实验室,四川 成都 610041;3.四川轻化工大学过程装备与控制工程四川省高校重点实验室,四川 自贡 643000;4.华东理工大学 机械与动力工程学院,上海 200237)
随着原油的重质化和劣质化,作为重油加工的核心工艺之一,催化裂化工艺(Fluidic catalytic cracking,FCC)受到越来越多的关注。目前,中国催化裂化装置生产的柴油和汽油约占成品柴油和汽油总量的30%和70%左右[1-4]。催化裂化是一个由多种高度非线性和相互强关联因素影响的复杂工艺过程,包括原料油性质、反应再生催化剂性质,以及反应操作工况条件等在内的多种因素都会影响到反应过程和产物收率,对其工艺过程和产品收率优化的数学建模分析一直是石油加工领域研究的热点和难点[5-6]。建立完善的催化裂化工艺过程模型,可缩短新工艺的开发周期、优化工程设计方案及装置的操作,实现装置的在线优化,提高原料利用率和目标产品的产率。
目前,对催化裂化进行模型分析的方法主要是机理建模法[7-8]。机理建模建立在对工艺原理和其物理、化学过程描述的基础上,能够有效地反映工艺过程与反应规律,具有工程背景清晰,可解释性强、可追溯性强的特点,已经形成了关联模型[9]、集总动力学模型[10]和分子尺度动力学模型[11]等分析方法。由于催化裂化过程的原料和产物是由大量烃类和非烃类化合物组成的复杂混合物,工艺过程涉及到反应众多的复杂反应体系,考虑到模型建立的复杂程度和在工业中的实用性,集总动力学模型是机理分析层面最为常用的研究方法。
集总动力学模型可以有效简化复杂工艺的反应体系,将复杂的原料和产物组成归纳为有限组分,从而进一步对产物分布及其影响机制展开分析,对优化操作工艺有重要意义,已经有学者分别开展了多种不同集总数量的模型构建与分析[12-13]。尽管集总动力学模型对于催化裂化工艺的分析已经发挥了重要的作用,但是依然面临着2个问题:
第一,模型求解过程存在的问题。在催化裂化的集总动力学建模过程中,求解模型方程的动力学参数是重要的步骤。由于集总反应动力学模型参数估计的计算量很大,计算过程也非常复杂,直接求解非常困难,需要配合有效的优化算法才能达到优化模型参数的目的。常用的经典优化算法有拟牛顿算法中的变尺度BFGS法以及Gauss-Newton法等。这些算法通过代入多组实验数据后形成的超定方程组,往往不相容。同时,还容易陷入局部最优值,无法找到全局最优值,而且对参数矩阵初值有较大的依赖性。
第二,模型精度和时效性的问题。由于催化裂化过程的原料和产物是由大量烃类和非烃类化合物组成的复杂混合物,工艺过程是反应众多的复杂反应体系,考虑到模型建立的复杂程度和在工业中的实用性,机理建模往往要做一些简化假设,有选择地忽略掉一些次要因素。这些简化会带来模型精度的损失,且单个反应单元的简化累积起来容易造成误差的逐级放大,导致系统整体模型的收敛性和稳定性难以保证。此外,集总建模时效性较差,周期长,无法做到对工艺运行状态的实施更新分析。
近年来,随着数据采集技术和数据处理能力的进步以及计算力的提升,人工智能算法得到了迅速的发展,并已经在过程工业[14]、电力[15]、航空[16]以及医疗[17]等领域得到了广泛的应用。在催化裂化领域,一方面,以遗传算法(Genetic algorithm,GA)、粒子群算法(Particle swarm optimization,PSO)和模拟退火法(Simulated annealing,SA)等为代表的智能算法被广泛应用到催化裂化集总动力学模型的参数优化过程中[18-19]。这些智能计算通过不断地迭代,在搜索空间中寻找最优解,一定程度上克服了拟牛顿算法对于计算初值依赖性以及经典算法难以找到全局最优的问题,同时还保证了算法的收敛性。另一方面,随着催化裂化生产过程工艺流程控制系统的不断完善,各种原料油性质数据、催化剂性质数据以及操作工况参数等都能从装置的数据库平台中实时采集。这些数据记录了催化裂化反应过程的特征、性能和变化,是对反应过程全面细致的描述。通过以人工神经网络(Artificial neutral network, ANN)为代表的统计机器学习算法,直接基于大量数据建立模型,通过拟合操作变量和产物的分布关系,可以多角度全方位地对反应过程及其影响机制进行分析,避免了机理建模中对于大量因素的简化,已经在催化裂化工艺操作工况的优化、装置的故障预警和产品收率的预测方面体现出巨大的优势[20-22]。
基于以上分析,人工智能算法已经成为催化裂化模型分析中的强大工具和重要组成部分,但目前对相关研究进行汇总整理的文献尚鲜有报道。笔者从智能算法在催化裂化集总动力学模型的求解,及以神经网络为代表的机器学习算法直接构建催化裂化分析模型2个方面,回顾人工智能在催化裂化生产过程模型分析中的应用,以期对后续研究提供帮助。
1 智能算法用于求解催化裂化集总动力学模型参数
对于催化裂化的集总反应动力学模型,其系数矩阵的计算量非常大,计算过程也很复杂,需要配合有效的优化算法才能实现模型参数的优化。拟牛顿法是一种对于求解非线性优化问题非常有效的方法。其中,BFGS算法作为拟牛顿算法中的一种,己被证明拥有十分优异的非光滑优化性能。其优异的收敛性、超线性的收敛速率保证了求解的精度和速率,在催化裂化动力学模型的优化求解中得到了广泛应用。王连山等[23]根据集总理论和催化重整的反应机理建立了三十八集总模型,利用分层策略与BFGS算法确定了86个待估模型参数,计算值与实际值吻合较好。李斌等[24]采用BFGS算法,对其建立的新型深度催化裂化DCC动力学模型的参数进行了求解。吴飞跃等[25]采用四阶变步长的龙格库塔法及BFGS算法,对其建立的九集总反应动力学模型中的反应动力学常数进行了求解。虞正恺[26]建立了FDFCC工艺过程的重油提升管十集总和汽油提升管七集总动力学模型,采用BFGS法来求取模型的动力学参数,得到的动力学参数符合反应规律和工艺特点。
尽管以BFGS算法为代表的经典算法已经在集总动力学模型参数的求解中体现出了巨大的优势,然而,经典算法容易陷入局部求解最优值,无法寻找全局最优值,且对矩阵初值的依赖性较大。遗传算法、粒子群算法和模拟退火算法等智能算法通过不断地迭代,在搜索空间中寻找最优解,一定程度上克服了经典算法依赖初值以及难以寻找全局最优的问题,同时还保证了算法的收敛性。下面将对几种智能算法在催化裂化集总动力学模型构建中的成果进行介绍说明。
1.1 遗传算法
遗传算法(Genetic algorithm, GA)[27]是一种通过模拟自然选择和生物进化过程,搜索最优解的进化算法。GA的算法框架如图1所示。
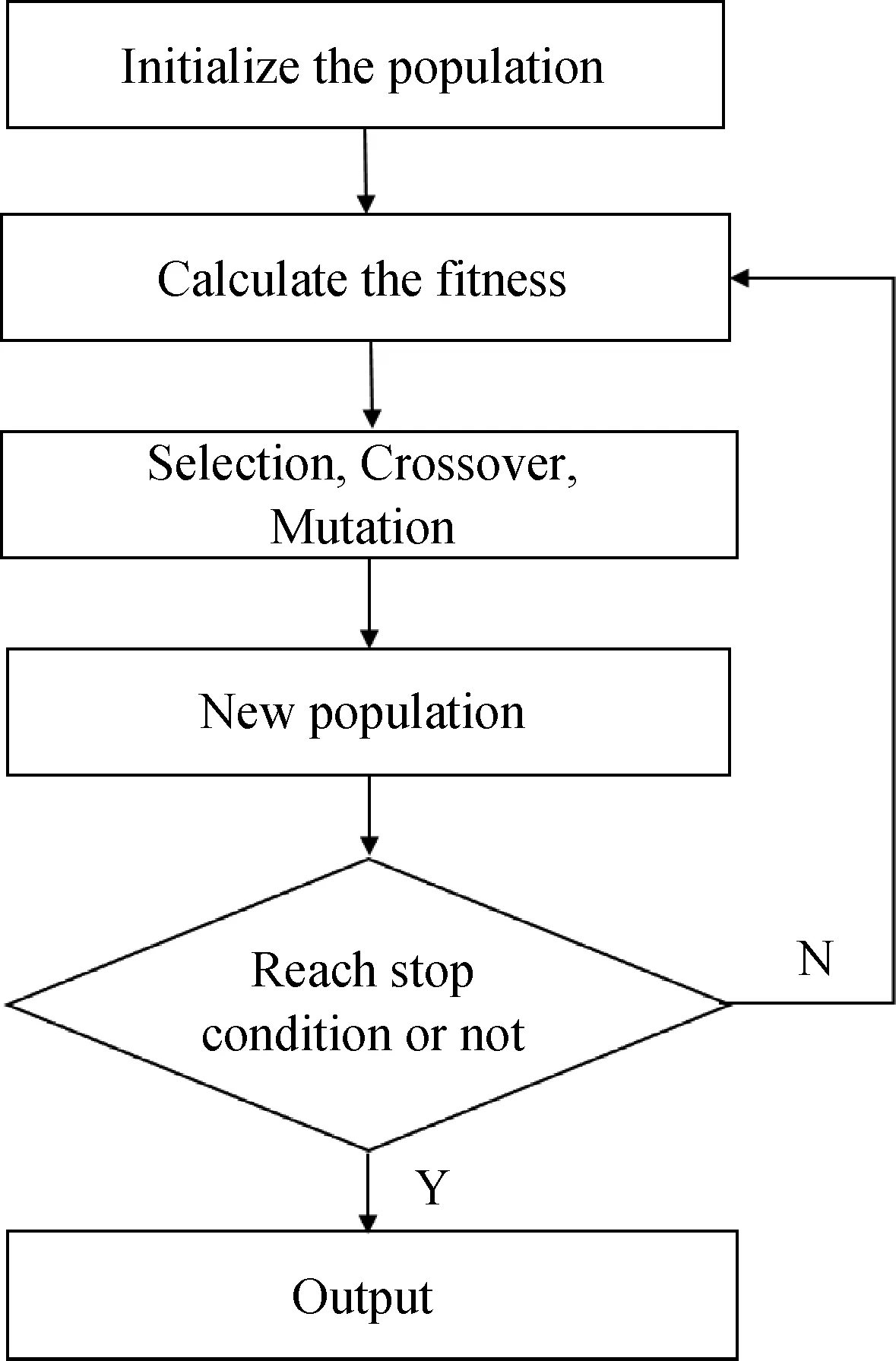
图1 遗传算法框架图
在搜索最优解的过程中,遗传算法首先初始化一定数量的个体,并根据适应度函数计算每个个体的适应度。在迭代的过程中,其通过“选择”、“交叉”、“变异”等操作生成新群体,而当满足一定条件时,停止迭代。遗传算法通过对搜索空间中的多个个体进行评估,降低了陷入局部最优的风险。
在构建催化裂化模型的过程中,遗传算法可以用于优化催化裂化模型的参数,从而提升模型的准确性。许闽等[18]结合遗传算法和多重退火交叉提出了改进的遗传算法,并将该算法用在包含复杂组分和反应过程的深度催化裂化(DCC)集总动力学模型的优化研究中,发现改进的算法运算速率更快,优化结果更准确。黄帅[28]基于实测工业数据,构建了MIP-CGP工艺的八集总反应动力学模型,运用龙格库塔法计算反应动力学方程组,并使用遗传算法估算了22个反应动力学参数,在对模型进行验证之后,对反应温度和剂/油比进行了优化预测计算。郁浩等[29]则提出了亲子竞争和最优个体保护策略相结合的新遗传算法,并将该算法用于估计催化裂化集总动力学动态模型参数,而且通过对比工业实际数据来验证模型参数。结果表明该模型对产物的预测值与实际测量值的平均相对误差为1.71%,取得了良好的预测效果。
通过以上研究可以看到,遗传算法在催化裂化集总动力学模型参数的计算方面发挥出巨大的优势。一方面,可以仅通过遗传算法估算模型参数;另一方面,也可以将遗传算法与其他算法结合,提高遗传算法估算模型参数的能力,从而进一步提升催化裂化模型的预测准确性和运算速率。
1.2 粒子群算法
粒子群算法,也称为粒子群优化算法(Particle swarm optimization,PSO),是由Kennedy和Eberhart于1995年提出的一种进化算法[30]。该算法最初源于对鸟群捕食行为的研究,将寻找问题最优解的过程比作鸟群寻找食物的过程。图2展示了粒子群算法的框架。
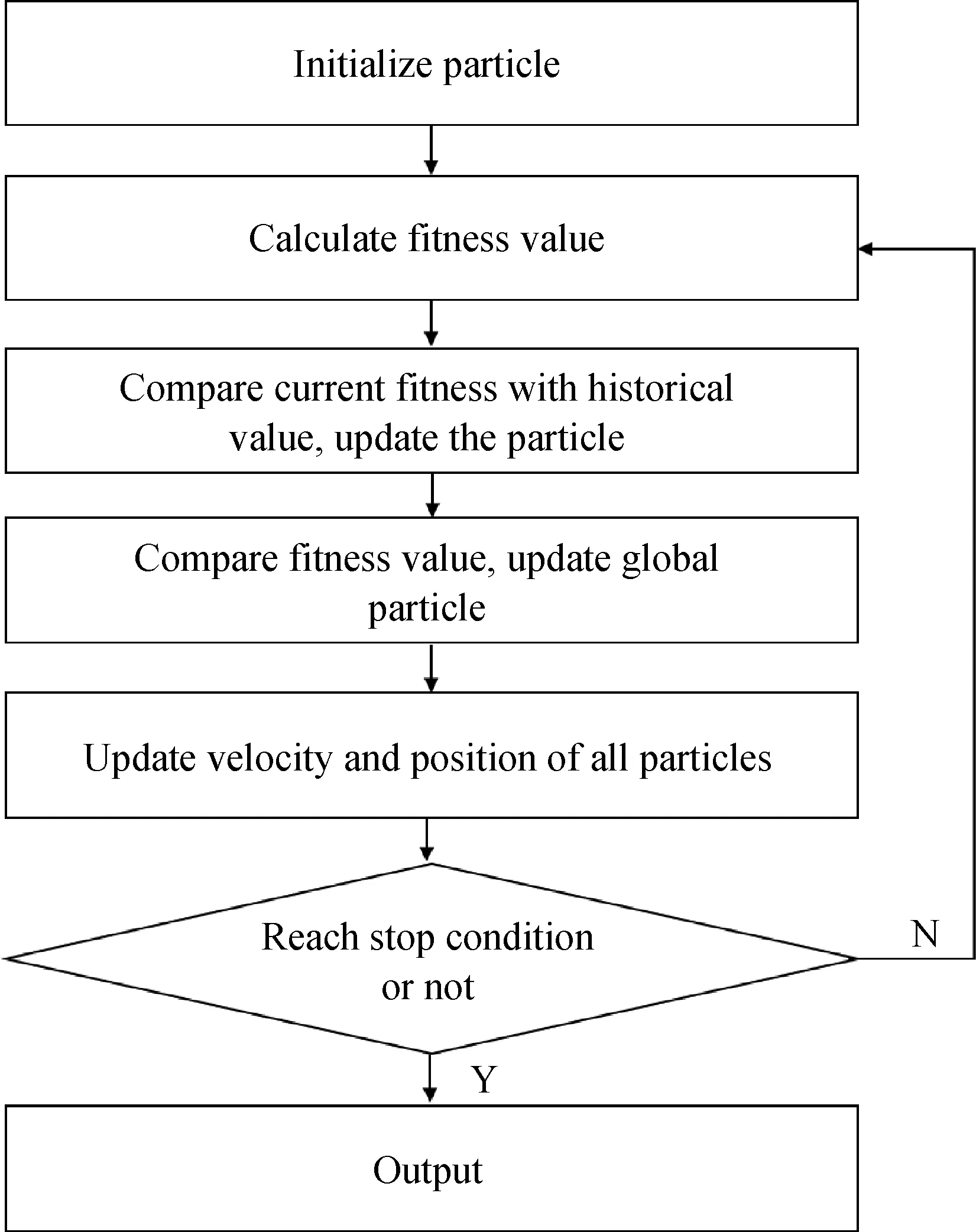
图2 粒子群算法框架图
在寻找最优解的过程中,该算法首先初始化一群粒子,每次迭代时,每个粒子通过跟踪自身的最优解和种群当前最优解进行自我更新,当满足一定条件时停止迭代,种群的最优解即为问题的最优解。
从计算过程来看,PSO具有较强的全局收敛能力,但依然存在收敛速率和收敛性能较低等不足,在实际使用中,需要结合其他算法来弥补其不足。在催化裂化中,PSO常常被用来计算集总动力学模型的参数。Sani等[31]比较了非支配排序遗传算法II(NSGA-II)和混沌粒子群优化算法(C-PSO)对二十七集总动力学模型参数进行估计时的性能。结果表明,从计算时间和全局寻优的角度,C-PSO粒子群算法都具有更出色的表现。Chen等[32]采用混合粒子群优化算法(HPSO)结合进化算法,对八集总催化裂化动力学模型的21个动力学参数进行了求解,得到的模型动力学参数结果与实验结果表现出良好的一致性。栗伟等[33]在所构建的FCC集总模型中,采用结合Levenberg-Marquardt算法的PSO算法来计算动力学参数,还考察了其他多种优化算法的实际运算效果。结果表明,粒子群算法不仅简单易用,得到的动力学参数也非常精确。综上可知,通过将粒子群算法与其他算法进行结合,可以很好地弥补粒子群算法自身的不足,并极大地提升粒子群算法的寻优能力,从而显著地提高催化裂化模型的准确性。
1.3 模拟退火算法
模拟退火算法(Simulated annealing, SA)[34]是一种基于蒙特卡罗迭代求解策略的启发式随机寻优算法。模拟退火算法将组合优化问题的求解比作物理中固体退火的过程,基本框架如图3所示。
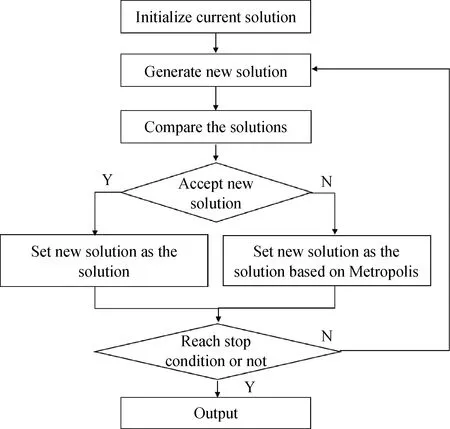
图3 模拟退火算法框架图
模拟退火算法在搜索最优解的过程中引入随机因素,以一定的概率接受次优解,从而降低陷入局部最优的风险,伴随着迭代次数的增加,其接受次优解的概率逐渐降低,从而保证算法的收敛性和稳定性。
在优化催化裂化模型的过程中,模拟退火算法经常与局部最优算法联合使用,从而在不同层面上寻找模型参数的最优值。杜玉朋[35]通过模拟退火法(全局)-最小二乘法(局部)-模拟退火法(全局)3层逐层寻优算法,对两段提升管催化裂解多产丙烯(TMP)的完整数学模型进行了模型参数估计,完成了十集总动力学模型的构建。结果表明,模型能够很好地对TMP技术在不同操作条件下的产物分布进行预测。在分子尺度的计算中,模拟退火算法也表现出良好的适用性。王胜[36]采用了模拟退火法优化了基于深度催化裂化(DCC)工艺而建立的分子尺度模型。闫昊等[37]利用结构导向集总与Monte Carlo模拟方法相结合,构建了废弃油脂催化裂化反应的分子尺度动力学模型,并利用模拟退火算法对原料矩阵进行优化。结果表明,模型可以很好地对原料性质和产物分布进行预测。由以上分析可知,通过模拟退火算法以及将模拟退火算法与其他算法进行结合,有助于降低模型预测值与真实值之间的差异。
综合所述,在催化裂化集总动力学模型参数的求解过程中,遗传算法、粒子群算法以及模拟退火算法存在许多相似之处,通过不断地迭代在可行解空间中寻找最优解,并采取相应的策略以避免陷入局部最优,从而保证算法的收敛性和稳定性。但是在寻找最优解的过程中,遗传算法、粒子群算法和模拟退火算法所采取的策略大不相同。因此,3种算法在模型求解寻优中各有所长,实际应用过程中,应根据具体的问题灵活选择。
2 基于人工神经网络的催化裂化过程模型构建与分析
2.1 人工神经网络方法对于催化裂化工艺的分析
机器学习是现代人工智能研究中的核心技术之一,能够在过程机理不明或过于复杂的情况下,寻找系统过程输入数据和输出数据之间的相关关系。在石油化工领域,钱锋等[38]回顾了石油和化工行业在生产全流程的信息检测、建模、优化控制,企业经营管理决策以及故障监测和安全环保等几个方面的进展,阐述了石化行业智能优化制造的需求,探讨了石化行业智能优化制造的新课题和挑战。李鹏等[39]在中国石化开发的炼油技术分析与远程诊断平台上,运用大数据处理技术进行了数据挖掘与分析,对催化裂化装置报警、结焦等问题进行了研究与分析,解决了催化裂化装置报警问题、结焦问题和收率问题,从而进一步提升了催化裂化装置运行水平,证明人工智能算法在石化领域应用的优势与可行性。催化裂化生产过程具有多变量、非线性的特点,目前在该领域使用最多的机器学习模型是人工神经网络。
基于以神经网络代表的机器学习算法构建催化裂化分析模型的一般步骤主要包括:数据处理、特征筛选、模型构建以及模型预测。数据处理主要包括数据采集、数据清洗和样本构建,保证数据质量并生成样本。特征筛选用来挖掘影响目标变量变化的特征,删除冗余的特征。模型构建一般包含损失函数的选取、网络结构的设计和模型的训练。模型预测是一个将待预测样本输入模型,模型输出预测值的过程。神经网络的学习过程,是一个根据训练样本数据不断调整网络参数的过程,其“学”到的规律蕴含在网络参数中。图4所示为典型的BP算法神经网络结构和训练过程示意图[40]。
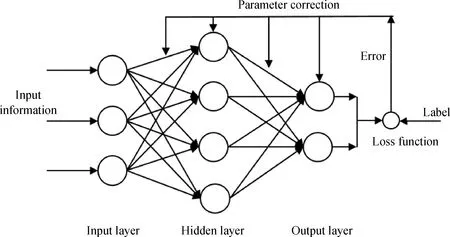
图4 BP神经网络结构和训练过程示意图[40]
由于从炼油厂DCS及LIMS系统采集到的相关数据种类繁多,一般超过上百种,而输入变量的选择对基于神经网络构建的催化裂化模型准确性有着较大影响,因此需要对输入变量进行筛选,以降低学习任务的难度。常见的特征选择方法包括过滤式(Filter)、包裹式(Wrapper)和嵌入式(Embedding)。相关性分析作为过滤式特征选择中分析特征重要程度的一种手段,对催化裂化操作变量的选择具有重要作用,常见的相关性分析包括皮尔逊相关系数、互信息等。从线性相关性分析特征的重要程度,通常考虑采用皮尔逊相关系数表示特征的重要程度,Pearson相关系数的表达式为:
(1)
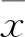
基于相关性分析和特征选择之后,可大大减少神经网络的输入变量,从而降低学习任务的难度,更有利于神经网络学习生产工艺与产品之间的关系。赵媛媛[41]以数据预处理所得数据为基础,采用SPSS软件中Pearson相关系数分析和工艺生产经验的联合方法,对催化裂化装置原料油、催化剂和反应-再生系统的所有变量进行变量筛选,降低了神经网络的复杂程度。Dasila等[42]采用人工神经网络模型,以密度、蒸馏温度、残炭(CCR)、硫含量和总氮含量等常规性质为输入,采用Levenberg-Marquardt(LM)训练算法,研究了几种不同神经元数目的BP神经网络,利用催化裂化装置十集总动力学模型,成功模拟了几种不同进料的装置性能,对催化裂化进料的详细组成进行了预测。Jiang等[43]基于广义回归神经网络(GRNN)和自适应增强算法,建立了17个输入变量的神经网络预测模型。结果发现,模型预测汽油产量与实际产量的均方误差为2.46。吕翠英等[44]也通过构建神经网络模型,对催化裂化产物分布进行了预测;在此基础上,对反应-再生系统进行优化,获得较优产品产率下的操作条件。由上可知,神经网络基于数据统计的规律,在不依赖机理解释的情况下可以实现对产物的预测,是现有基于催化裂化过程反应机理的集总动力学模型的一种有益补充。未来随着炼化企业数据资源的日益完善,以神经网络为代表的催化裂化分析模型必然会发挥越来越重要的作用。
2.2 人工神经网络结合智能优化算法对催化裂化工艺的分析
在构建神经网络的过程中,一般通过引入非线性激活函数来增强网络的拟合能力,同时神经网络的求解成为一个非凸优化问题,致使优化算法很难找到全局最优解。对于催化裂化工艺,原料油性质、催化剂性质、操作条件与产品收率之间的神经网络模型是一种极其复杂的数学函数,可利用结合智能优化算法的方式来优化神经网络参数或操作条件,从而实现对神经网络的更好应用。
在神经网络结合遗传算法应用方面,用遗传算法优化BP神经网络参数的初始值,可以避免BP神经网络陷入局部极小值的问题。图5为遗传算法优化BP神经网络的算法流程示意图[40]。
在采用遗传算法优化神经网络的过程中,首先确定神经网络并对网络参数进行初始化,用遗传算法对神经网络参数初始值进行编码,其次通过“选择”、“交叉”和“变异”等操作寻找网络参数的最优值,直至满足约束条件,最后根据遗传算法找到网络参数的最优值并更新神经网络参数。华东理工大学的欧阳福生教授团队在利用BP神经网络结合遗传算法分析催化裂化过程方面开展了大量的工作[45-47]。
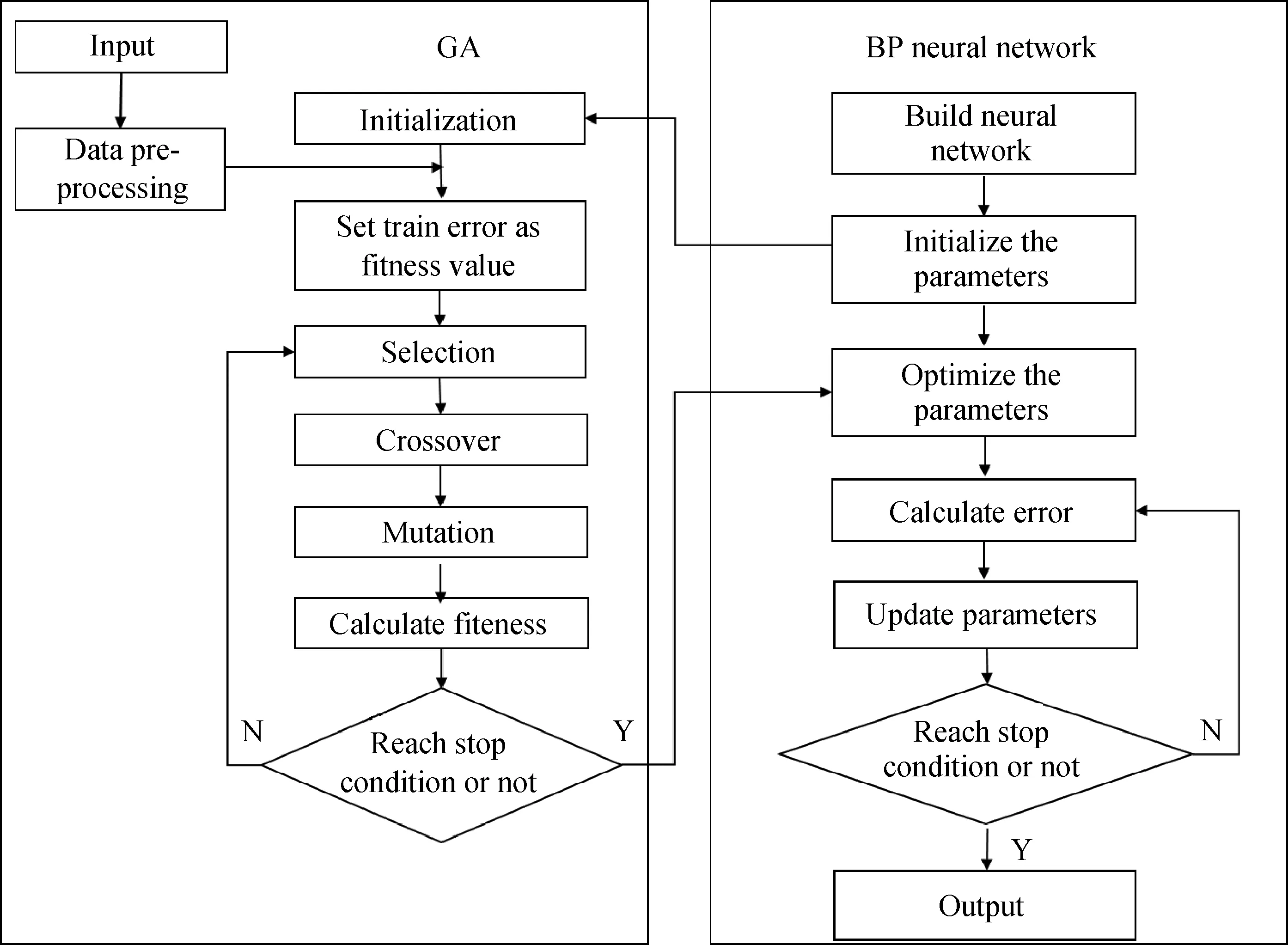
图5 遗传算法优化BP神经网络算法流程图[40]
方伟刚[48]选取包括原料油性质、催化剂性质和操作条件的19个变量作为神经网络的输入,选取液化气、汽油、柴油、焦炭的收率作为神经网络的输出,搭建了19-24-4结构的BP神经网络,同时利用遗传算法对神经网络进行优化,获得了最优汽油收率下的反应-再生系统的操作条件。赵媛媛[41]采用BP神经网络对MIP装置全部数据和聚类后的数据分别建立汽油收率的神经网络模型,最终得到了最佳结构的神经网络模型,并利用遗传算法优化了汽油收率模型。苏鑫等[49]分别将BP神经网络和经遗传算法优化的BP神经网络(GA-BP)的预测结果与工业数据进行对比。结果表明,经遗传算法优化的预测模型无论在预测结果的准确性还是稳定性方面效果均更好。此外,还通过考察原料残炭、反应温度等单一关键参数对焦炭产率的影响,进一步证明了经遗传算法优化的BP神经网络预测模型的准确性。Wang等[50]建立了基于模糊神经网络(FNN)与遗传算法(GA)相结合的FNN-GA方法,将输入值(即原料组分、操作变量)与输出值(即升级汽油的产量和其中的烯烃组分)进行关联,然后利用遗传算法对操作变量的输入进行优化,使不同原料的烯烃限制汽油达到最大化。实验结果与预测结果吻合较好,优化的操作条件对汽油收率有显著的改进。可以看到,遗传算法借鉴生物进化规律,通过选择、交叉和变异等操作直接对优化对象进行操作,自适应地调整参数的搜索方向,具有较好的全局收敛性。当其与神经网络深入结合之后,可以为神经网参数的初始化搜索到更为合理的参数值,进而优化模型的学习能力,极大地提高神经网络的稳定性和准确性。
神经网络结合粒子群算法(PSO)也表现出了良好的适用性。高玉梦等[19]建立了催化裂化反应-再生的 5-11-1 BP神经网络结构,利用粒子群算法对神经网络的初始最优权值和阈值进行寻优,相比于未经寻优的模型,PSO-BP神经网络的预测精度得到了极大的提升。商雨青等[51]将交叉前置式粒子群优化算法(PSOPC)应用在催化裂化装置干气中C3含量软测量的建模中,发现基于PSOPC的神经网络C3含量软测量模型具有更高的精度和更好的泛化能力。王学武等[52]建立了基于主元分析的神经网络模型和PSO-BP神经网络模型,并对其仿真结果进行分析和比较。结果显示,基于PSO-BP神经元网络的软测量模型预测效果优于带主元分析(PCA)人工神经元网络的软测量模型预测效果,所建软测量模型可以较好地反映出干气中C3以上烃类总含量变化的趋势及数值,满足实际生产过程操作的要求。
对于神经网络与模拟退火算法的结合,也有研究者进行了尝试。唐佳瑞[53]基于广义回归神经网络和Adaboost算法,建立了MIP装置汽油产率预测模型,并分别采用基于个体行为优化算法中的模拟退火算法和基于群体行为优化算法中的遗传算法,对汽油产率预测模型进行优化,结果发现,两个算法均能够计算得到最优汽油产率,但是模拟退火算法陷入了局部最优,不能在每次优化时均得到最优值,说明模拟退火算法的稳定性差,最终选择改进的遗传算法作为优化算法进行汽油产率优化。
2.3 人工神经网络结合机理模型对催化裂化工艺的分析
从以上的分析可以看出:一方面,集总动力学等机理模型有利于抓住催化裂化过程的本质特征和主要矛盾,对于反应的主要影响机制展开分析,但在模型构建过程中,考虑到模型的复杂性和计算成本,不得不对装置结构及工艺过程进行适度的简化,且单个反应单元的简化累积起来容易造成误差的逐级放大,系统整体模型的收敛性和稳定性难以保证。另一方面,对于单纯通过数据驱动的神经网络建模,通过大量分析历史数据,从中获取潜藏在数据中的信息和规律,进而找到原料油性质、催化剂性质以及操作工艺条件等“因”和目标产物收率这一“果”之间的映射关系。然而,单纯的神经网络建模法是一种数据驱动的“黑盒子”方法,对于工艺中的传递与反应过程描述不清晰,可解释性较差,且该方法完全由数据驱动,计算结果往往严重依赖于数据样本的数量和质量,容易对环境噪声过拟合,造成预测泛化能力差的后果,难以对过程机理进行深层次的分析和解释。
根据催化裂化工艺的高度非线性和影响因素相互强关联的特点,将机理驱动的集总动力学模型与数据驱动的神经网络模型相结合,构建机理-数据混合驱动的分析模型,能够充分利用已有的经验知识,挖掘数据中的有效信息,提高建模的效率和精度,进而对催化裂化工艺进行优化,提升模型对产品分布的预测能力。
按照模型之间的连接方式,混合建模可以分为串联、并联和混联。其中,串联指输入变量首先进入机理模型进行运算,机理模型的输出再作为非机理模型的输入,非机理模型的输出作为最后输出。并联指机理模型和非机理模型对输入数据进行并行计算,在单独使用机理模型所输出数据误差较大的情况下,可利用合适的非机理模型进行误差学习,总输出为机理模型和非机理模型输出的结果之和,使输出误差减小。混联建模可同时将几个机理模型和几个非机理模型集成在一起,自由度大,很适合复杂的石化生产过程建模。串联和并联建模的示意图如图6所示[54]。
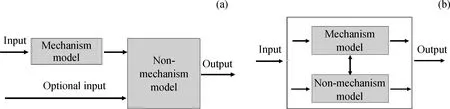
图6 混合建模方式示意图
Bollas等[55-56]开发了催化裂化机理与神经网络结合的混合模型,与来自希腊炼油厂的工业数据对比后发现,相比于单纯的机理模型和单纯的神经网络模型,混合模型能够很好地提高预测精度。刘永吉[57]以MIP工艺为研究对象,构建了八集总的反应模型并计算了产物分布。在此基础上,构建神经网络,选取主要的原料性质、催化剂性质及操作条件共14个变量作为BP神经网络的输入,将集总动力学模型计算获得的柴油、汽油、液化气、干气和焦炭收率预测值和工业实际值之间的误差共5个变量作为BP神经网络的输出,建立了14-7-5结构的BP神经网络混合模型,并计算得到了相应的误差值。文献中虽然没有进一步讨论,但如果将混合模型得到的误差值与集总模型对产物分布的预测值相结合,最终得到的产物预测值无疑会与工业实测值更加接近,从而具有更好的预测精度。从以上文献可以看出,将机理驱动的集总动力学模型和数据驱动的神经网络模型结合的混合模型,兼顾了两种方法的优势,对于进一步提升催化裂化产物预测模型的准确性和精度有良好的效果。
3 结论与展望
以遗传算法、粒子群算法和模拟退火算法等为代表的智能算法一定程度上克服了经典算法对初值依赖性,对于集总动力学模型的发展起到了极大的促进作用。此外,以神经网络为代表的机器学习算法以数据为驱动,通过分析大量历史数据,从中捕捉原料、生产工艺与产品之间的变化关系,并对未来的产物分布进行预测,已经成为构建催化裂化分析模型的一种新型并且有效的手段。神经网络结合智能算法,则进一步提升神经网络的收敛性和稳定性,并在优化操作工艺和筛选最优操作条件方面发挥了巨大的作用。此外,对结合机理模型和神经网络的混合模型在催化裂化中的应用也开展了一定的研究,结果表明,其比单纯使用数据驱动的神经网络具有更好的准确性和产物预测精度,表现出巨大的潜力。
总之,人工智能算法已经成为催化裂化工艺模型求解与分析的重要手段和方法。在未来的研究中,结合机理模型和人工智能算法的混合模型有望成为更加全面准确分析重油催化裂化工艺过程以及预测产品分布的有力工具,得到更大的发展。
