国密SM9 算法R-ate 对计算的优化设计*
2020-09-27王明东何卫国
王明东,何卫国,李 军,梅 瑞
(成都三零嘉微电子有限公司,四川 成都 610041)
0 引言
基于标识的密码系统(Identity-Based Cryptograph,IBC)是在传统的PKI 基础上发展而来的,将用户的唯一标识(如手机号、邮箱地址)用作公钥,从而帮助用户不再频繁申请和交换证书,极大地降低了证书和密钥管理的复杂性。国密SM9 标识密码算法[1]于2016 年发布为国家密码行业标准(GM/T 0044-2016)。在标识密码系统中,用户的私钥由密钥生成中心(Key Generation Center,KGC)根据主密钥和用户标识计算得出,用户的身份标识用以生成用户的公、私密钥对,不需要通过第三方保证其公钥的真实性,主要用于数字签名、数据加密、密钥交换以及身份认证等[2]。相比于传统密码体系,SM9 密码系统的最大优势是无证书、易使用、易管理,在5G 时代物联网等领域的数据安全应用拥有得天独厚的优势。但是,基于双线性对运算的SM9标识密码算法,相较于SM2、RSA 等公钥算法,算法复杂度较高且占用了较多硬件资源,制约着SM9算法在轻量级设备以及密码卡、服务器端等的高速实现。因此,SM9 算法的高性能研究与设计是目前SM9 算法实际应用面临的较大挑战。
1 SM9 算法参数及R-ate 双线性对
SM9 算法推荐参数采用BN 曲线,曲线方程为E:y2=x3+b,其中b=5,嵌入次数k=12。基域特征q,曲线阶r,通过参数t来确定:
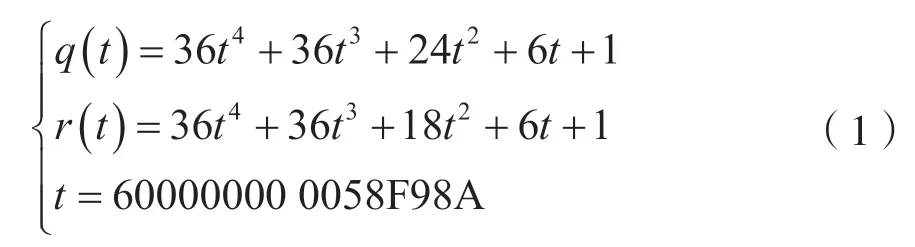
Fq12域上元素采用1-2-4-12 的塔式扩张,扩张方式如下所示:

双线性对运算推荐采用BN曲线下的R-ate对,算法描述如下。


2 算法优化性设计
R-ate 双线性对为SM9 签名、加解密等算法的核心运算,整体采用Miller 算法结构,πq、πq2为Frobenius 自同态,gT,Q、gT,T为直线函数运算。算法1 中计算f=f(q12-1)/r是双线性对性能的瓶颈。若12次塔式扩张域模幂运算对指数直接采用传统二进制扫描方法进行运算,指数(q12-1)/r的比特长度为256×11=2 816,计算复杂度大,效率偏低,采用Fq12域上的直接模幂运算方式不可取。经研究分析,可采用如下指数分解以及模幂与模逆优化等加速设计手段,有效提高算法效率。
2.1 指数分解

2.2 模逆运算优化
对于式(6)中的第一部分m=f(q6-1),因为f∈Fq12,根据共轭运算和有限域元素的唯一性性质,有其中为f的共轭运算。
因此,第1 部分可简化为:
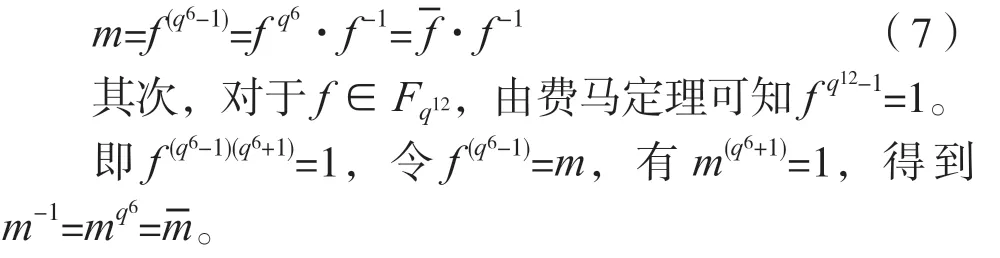
所以,f经过(q6-1)次模幂运算后,求逆运算可直接优化为简单的共轭运算,无需采用费马定理或欧几里得算法进行复杂的求逆运算,即式(6)中的hard part 中的模逆运算等价于共轭运算。
2.3 q 次模幂运算
SM9 算法推荐参数的Fq2、Fq4、Fq12塔式扩张域上的q次幂运算有如下快捷计算方式[3-4]。
算法2:Fq2域上q次幂运算
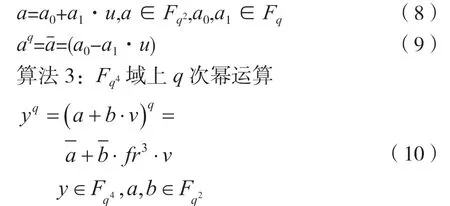
其中,fr为Frobenius 常数,fr=u(q-1)/6,可预计算存储。
算法4:Fq12域上q次幂运算

其 中,fr为Frobenius 常 数,fr=u(q-1)/6,fr、fr2可预计算存储。
因此,第二部分s=m(q2+1)=(mq)q·m采用Fq12域上q次幂优化性计算,可直接转化为简单的共轭运和模乘运算。
2.4 hard part
模幂的hard part 为第3 部分,f=s(q4-q2+1)/r。经研究分析,可采用如下优化运算:


3 性能评估及验证
3.1 性能评估
对R-ate 双线性对以及f=f(q12-1)/r涉及的模乘运算以及模加运算进行评估,统计结果如表1 所示,M、A 分别代表Fq域上的模乘与模加运算,塔式扩张域的模乘运算采用Karatsuba[5-6]算法。
从表1 的统计结果看到,本文的优化方案f(q12-1)/r的运算量为6 063 次模乘以及30 513 次模加运算,性能较传统方法提升近37 倍,R-ate 双线性对运算优化为111 321 次模乘以及474 787 次模加,性能整体较传统方法提升近3 倍。

表1 R-ate 双线性对运算性能评估表
3.2 仿真验证
如图1 所示,采用verilog 硬件描述语言对论文的优化算法正确性进行仿真验证。仿真环境实现了完整的1-2-4-12 塔式扩张域上的模加、模减、模乘、模逆、标量乘、直线函数以及R-ate 双线性对等运算,其中res12 为R-ate 双线性对仿真运算结果,与国密标准的参考样本数据一致,从而验证了本论文优化算法的正确性。

图1 R-ate 双线性对仿真验证结果
4 结语
本文对R-ate 对中的f(q12-1)/r模幂运算进行优化设计,对模幂指数采用指数分解、模逆运算转换为简单的共轭运算、q 次模幂快速算法设计以及hard part 的快速模幂运算,完成了R-ate 的快速实现。相较于传统实现方式,显著提升了算法性能,为R-ate 双线性对的软硬件高性能设计提供了算法支撑,同时用verilog 硬件描述语言仿真验证了本论文优化算法的正确性,证明其是一种可行的优化算法。
