弱光照条件下交通标志检测与识别
2020-09-21孙若灿
赵 坤,刘 立,孟 宇,孙若灿
北京科技大学机械工程学院,北京 100083
近年来,人工智能的快速发展极大的加快了无人车技术的研究进程,特别是深度学习[1]在环境感知、路径规划、决策控制等关键技术上的研究与应用,使得自动驾驶时代在不久的将来真正成为可能. 交通标志检测与识别是智能交通领域环境感知[2]系统的一个重要分支,对于保证交通安全具有十分重要的研究意义,逐渐成为国内外学者的研究重点. 近几年虽然对交通标志检测与识别的研究取得了较为满意的结果,但是在实际应用中仍然存在较多问题,针对应用场景下的交通标志检测与识别方法仍需进一步深入研究.
目前交通标志检测与识别方法主要分为两大类:基于传统手工特征和机器学习分类的方法以及基于深度学习的方法.
(1)基于传统手工特征和机器学习的方法.
基于传统手工特征和机器学习的方法大致可以分为以下三个子类:1)应用颜色和边缘信息;2)应用形状信息;3)应用机器学习机制. 在第一类方法中通常先用颜色分割图像,然后进行边缘检测,最后使用随机一致性采样(RANSAC)或Hough变换等方法处理,从边缘图中识别特定的形状[3−4].第二类方法只依靠边缘信息,在文献[5]和[6]中实现了一种基于径向对称性的快速算法,该算法可以适应各种规则形状,包括三角形、正方形、菱形、八边形和圆形. 第三类方法应用机器学习技术,其中神经网络、支持向量机(SVM)和AdaBoost是最常用的方法. 例如文献[7]对输入图像进行颜色分割后提取出块,然后使用线性SVM将其分类为不同的形状. 文献[8]应用AdaBoost方法使用一组考虑颜色和位置的Haar小波特征检测交通标志.
基于传统手工特征和机器学习的方法需要针对不同的标志设计不同的手工特征,且无法同时识别所有类别的交通标志,算法的实时性无法得到保证.
(2)基于深度学习的方法.
近年来,深度卷积神经网络在目标检测任务中取得了巨大的成功. Girshick等[9]提出了用于精确目标检测和语义分割的丰富特征层次结构区域卷积神经网络(Regions with CNN,R-CNN),利用选择性搜索(Selective search,SS)[10]代替传统滑窗法在图像上提取2000个目标候选区,然后采用深层卷积网络对目标候选区进行分类. 但由于其对每个候选区都执行卷积运算而不是共享计算,因此检测速度较慢. 文献[11]提出了空间金字塔网络(Spatial pyramid pooling network,SPPnets),通过共享卷积特征图来提高速度. 快速区域卷积神经网络(Fast R-CNN)[12]能够对共享卷积特征进行端到端训练,提高了检测精度与速度. 但是SPPnets和Fast R-CNN仍然使用SS方法生成目标候选区,此阶段成为提高实时性的瓶颈. 更快区域卷积神经网络(Faster R-CNN)[13]引入了区域提案网络(Region proposals network, RPN)生成目标候选区,极大的提高了目标检测的速度. YOLO (You only look once)[14]将目标检测任务重构为一个从图像像素直接到边界框坐标和类概率的回归问题. 单阶段多盒检测器(Single shot multibox detector,SSD)[15]利用特征图上的小型卷积滤波器来预测边界框位置中的目标类别和偏移,以提高目标检测的性能.
随着以上目标检测框架逐渐成熟以及大型国外交通标志数据集的出现,已出现许多基于深度学习的交通标志检测与识别实证研究[16−19],研究结果显示出了深度学习在交通标志检测与识别领域的优越性,基于深度学习的交通标志进行检测与识别方法成为当前的研究主流.
当采用上述较为成熟的深度学习框架检测交通标志时,发现检测失败的样本通常为阴天、傍晚或背光等弱光照条件样本,具有亮度或对比度低的特点;检测失败的表现形式为漏检和定位不准、置信度较低. 在无人驾驶应用中,不可避免的出现很多复杂的弱光照情况,因此需要对弱光照条件下交通标志检测与识别方法进行深入研究,以提高其在实际应用中的效果.
针对以上的问题,本文提出了用于提高弱光照条件下交通标志检测与识别性能的增强YOLOv3检测算法. 首先提出了实时自适应图像增强算法,调整图像亮度和对比度,便于降低后续检测漏检率;然后采用YOLOv3框架检测增强后的图像并优化了损失函数和先验锚点框聚类算法,提高交通标志边框回归精度和置信度;此外,开发了复杂光照中国交通标志数据集用于对中国交通标志检测与识别方法的研究.
1 弱光照中国交通标志数据集
目前对交通标志检测与识别的研究,研究者多采用比较知名的公共交通标志数据集对算法性能进行测试,如美国交通标志数据集(LISA)[20]、德国交通标志数据集(包括检测基准数据集GTSDB和识别数据集GTSRB)[21]和比利时交通标志数据集(BTSRB)[22]. 但以上数据集仅限于欧洲交通标志且样本大多是在光照条件良好的情况下采集的,国内相关机构还没有开发和公布大型完备的复杂光照中国交通标志数据集以用于检测中国的交通标志. 因此研究中国交通标志识别与检测方法以及后续算法的应用必须具备大型复杂光照中国交通标志数据集.
本文采集并标注了北京市道路交通主要类别的交通标志组成数据集,包括警告类、禁令类、指示类等7种交通标志. 数据集中包含雨雪天气,阴天及傍晚等光照条件复杂的交通标志图像,部分图像如图1所示. 数据集共包括6258张图像(内含8675个交通标志,无负样本,数据分布如图2所示),涵盖了目前常出现的城市道路交通标志,与现有大型欧洲交通标志数据集相比图像数量略少但基本可保证数据量充足.

图1 不同天气及光照条件的图像样本. (a)阴天; (b)雨雪天; (c)光照充足; (d)光照不足Fig.1 Image samples under different weather and illumination conditions:(a) overcast; (b) rain and snow; (c) sufficient illumination; (d) insufficient illumination

图2 交通标志数据分布示意图Fig.2 Data distribution diagram for traffic signs
数据集构建过程具体如下:
1)数据采集. 样本主要通过两种方式获得,一部分通过百度地图剪裁,主要为光照充足的样本;另一部分在阴天傍晚等情况下通过拍照实地(北京市北三环与北四环之间的交通主干道)采集,主要为弱光照样本. 为了提高数据集的普适性,从不同的角度和距离对同一个交通标志进行多次采集.
2)数据处理. 参照2.1中的分类原则,按照强度均值将图像分类为偏暗类(2621张)和明亮类(3637张). 为了保证数据大致均衡,对其中500张明亮类图像进行了随机调暗处理,最终偏暗类图像和明亮类图像分别为3121张3137张.
3)标注方法及内容. 采用LableMe软件标注每幅图像,标注信息包括交通标志的类别属性,图像的光照情况,标志边框的左上坐标和右下坐标(像素单位),信息保存在xml格式下的文件中.
4)数据划分. 分别将偏暗类图像和明亮类图像按照约1∶1的比例划分组成训练集和测试集.为了增加数据量,训练时采用数据增广对初始图像随机平移.
2 增强 YOLOv3 算法
2.1 自适应图像增强
弱光照交通标志图像数据集中主要存在以下四种情况的图像:整体亮度较低、半明半暗且交通标志在偏暗区、半明半暗且交通标志在偏亮区以及整体亮度良好的图像,光照条件较为复杂. 而图像增强的目的就是针对不同光照条件的图像合理的均衡化像素分布范围,调整图像亮度和对比度,提高交通标志与背景间的区分度.
现有的方法一般采用直方图均衡化全局图像[23],但采用全局加强的方法可能会导致图像部分过加强或欠加强;也有局部加强方法,Celik和Tjahjadi[24]提出局部加强技术对图片部分进行不同程度的强化,但其未考虑全局亮度信息.
Gamma校正常用于调整图像的整体亮度,传统的Gamma校正对所有的图像都采用同样的处理方式,使得图像质量好的图像被过度地处理. 对此,本文提出自适应Gamma校正(Adaptive Gamma correction,AGC),可对不同光照程度的图像进行自适应处理. 首先将图像转换到HSV颜色空间,然后对V通道进行自适应Gamma处理以调整图像亮度,最后再将图像转换到RGB颜色空间进行后续检测,主要流程如图3所示. 其中,对图像进行自适应Gamma校正处理时,图像强度变换函数设置为:

式中,s为输出图像的强度,R为输入图像的强度,γ为控制输入输出曲线的参数,c为修正系数,两参数共同控制曲线形状. 对于不同光照下的图像,参数c和γ有不同的计算方式.
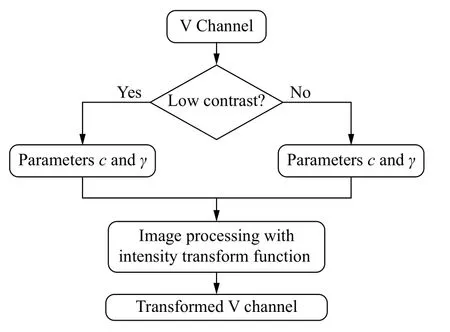
图3 自适应 Gamma 校正流程图Fig.3 Flow diagram of adaptive gamma correction
图像标准差反映了像素值与均值的离散程度,标准差越大图像质量越好,因此,本文先采用图像强度标准差对图像分类,判别公式如下所示:

式(2)中,σ为图像标准差,p为图像对比度衡量系数,根据实验发现,取p=3能够作为分类不同对比度图像的标准;IL表示低对比度图像,IH表示中高对比度图像.
同一对比度类别的图像也会有不同的亮度,需要对图像进一步划分. 图像强度均值反映了图像的亮度,均值越大图像亮度越大,本文采用λ表示图像强度均值. 经过多组实验发现,图像强度均值小于0.5时,亮度不佳,大于等于0.5时,亮度良好. 因此,本文设置λ=0.5作为区别图像亮度高低的界限,最终图像分类类别如表1所示.
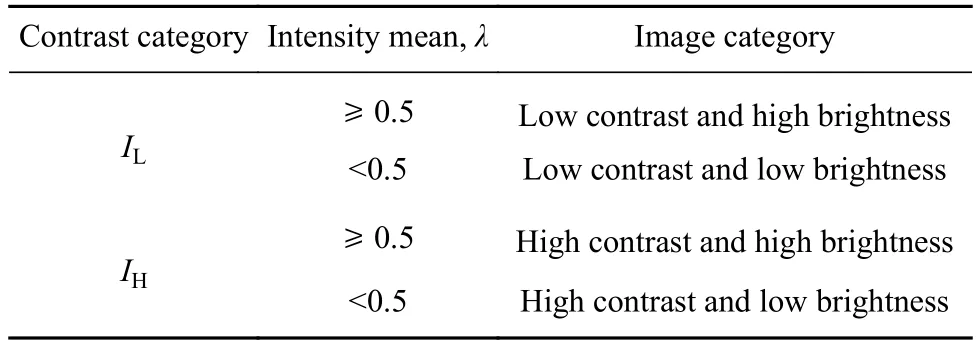
表1 图像分类Table 1 Image classification
2.1.1IL类图像处理
IL类图像σ值小,图像中的大部分像素有相近的强度值,聚集在小的像素范围内,对于这样的图像,需要使像素分布扩展到更大的范围以提高对比度. 在Gamma校正中,γ值越大,相应的图像强度越大,对比度也越大. 在本文的自适应Gamma校正中,对于IL类别图像采用下面的公式计算γ值:

对于系数c值,传统的Gamma校正方法通常取1,本文针对不同对比度图像采用不同的c值:

式中,α有以下定义:
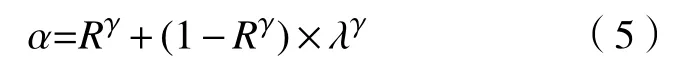
ε(0.5−λ)为阶跃函数:

这样处理γ和c值使得算法能够对IL类别中亮度不同的图像分别采取合适的变换.
IL类别中亮度高的图像(λ≥0.5),算法主要是要增加其对比度,突出图像更多的细节,因此根据式(4),此时c=1,式(1)转化为:

为了增加这类图像的对比度,变换曲线需要扩展图像的像素范围,分布一定的亮灰度值到暗灰度范围,在自适应Gamma算法中,根据式(2)和(3)证明得,γ大于 1.
IL类别中亮度低的图像(λ<0.5),通常其大部分像素值分布在暗灰度水平,且聚集在较小的范围内,对于这类图像,变换曲线需要将一部分暗灰度值扩展到更亮的灰度范围,此时的变换曲线会落在s=R曲线之上. 结合式(4)和(5),式(1)变换函数转化为:
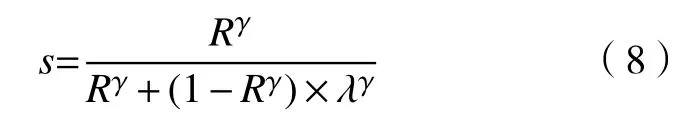
2.1.2IH类图像处理
IH类图像σ值大,图像像素值在动态范围内明显呈分散分布,相比加强其对比度,亮度调节显得更加重要,输出图像的强度和c值依然如式(1)和(4)所示,γ值控制输入输出曲线的斜率,γ值越大,图像对比度越大,因此,对于IH类别的图像,γ值的计算调整为:

可以看出,对于此类图像,γ值的变化不大,对图像对比度的影响相对较小. 由式(9)分析可知,γ值的取值范围为[1,1.649].
IH类中亮度高的图像(λ≥0.5)质量较好,亮度和对比度也合适,对这类图像算法主要目标是保留图像原有的质量,s、c和γ值的计算均同式(1)、(4)和(9).
IH类别中亮度低的图像(λ<0.5),λ+σ≤1,由于λ和σ的值均小于 0.5,所以γ≥1. 分析可知,这类图像的输入输出曲线必定落在s=R这条线性曲线之上的,算法会使这类图像中的偏暗的像素转换到亮度大一些的范围内,图像的亮度分布更为均匀. 对于亮度稍微偏低但强度均值较大的图像来说,变换曲线非常接近s=R曲线.
在实时性方面,以处理 416 像素×416 像素的图像为标准,在本文的实验平台上,自适应图像增强阶段的耗时约为32 ms,较为影响整体检测实时性,为此本文对图像增强过程进行了如下改动:分离出图像V通道后,先将V通道的尺寸压缩到原图的四分之一,然后进行上文自适应Gamma校正处理后再将尺寸恢复到原图大小. 对于压缩的插值方式,本文进行了测试,发现采用双线性插值法的时间和效果较其他插值方法好. 这种处理方式的唯一缺点是造成了图像轻微模糊,但对后续检测结果影响不大,且大大提高了图像增强的实时性,改动后图像增强处理一张图像只需要9 ms.
2.2 YOLOv3 锚点框聚类算法优化
YOLO框架将目标检测看作回归问题,YOLOv3[25]替换了YOLOv1直接从图像像素中得到边界框的思想,借用RPN的方法生成锚点框. 而先验锚点框的尺度比例和数目对计算速度和最终的边界框回归效果有较大影响[13]. 不同于Faster R-CNN,SSD的人为设定,YOLOv3延用YOLOv2[26]的方法,采用k-means聚类分析法聚类出均值先验锚点框. 但是实际应用时发现,聚类结果与样本统计结果存在一定偏差,影响了后续检测性能,因此本文对先验锚点框的聚类算法进行了优化,增加了对聚类结果的随机修正处理:
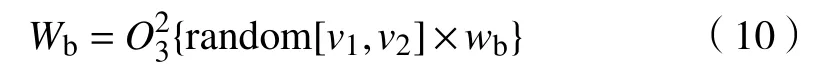
对本文构建的交通标志数据集,首选确定聚类中心数目Q,根据聚类统计平均交并比(Intersection over union, IOU)结果,结合 YOLOv3 框架中多尺度预测的特点,分别取Q=6,9,12三个值做训练,权衡回归速度和准确度后,选择Q=9,如图4所示.
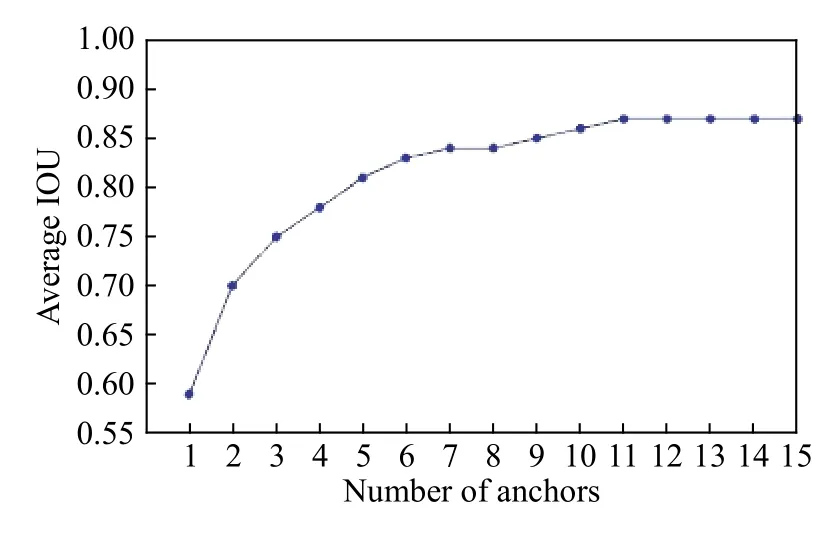
图4 聚类中心数目测试结果Fig.4 Test results of number for cluster centers
聚类10次取平均后锚点框的尺寸为(14, 21)、(19, 32)、(25, 38)、(29, 55)、(30, 43)、(37, 56)、(41, 70)、(55, 77)、(73, 108). 括号中数字分别表示锚点框的宽和高,观察发现上述聚类结果的宽高比最小是0.527,最大是0.714. 而对于本文的数据集,统计训练样本的宽高比发现,70%的样本宽高比在0.72~1之间,20%的样本宽高比在0.6~0.7之间,10%的样本宽高比小于0.6,可见聚类结果与统计结果存在一定偏差. 通过如式(10)所示的处理,先验锚点框的聚类结果得到修正. 如图5所示,对比优化前后训练损失值发现,优化聚类算法后网络的损失值明显低于优化前的损失值,说明优化后的锚点框提高了对交通标志的边框归回精度和置信度.
2.3 YOLOv3 损失函数优化
在交通场景中,相比于行人或车辆,交通标志物理尺寸较小且大部分样本中最多出现3个交通标志,前景与背景比例严重失衡,应用One-stage目标检测器时,大部分的边界框不包含目标,这些无目标边界框的置信度误差比较大,前景的损失淹没于背景的损失中. 因此本文在原有损失函数的基础上进行了优化,主要思路是自适应的均衡前景与背景的损失. 损失函数包括两大部分,分别为回归损失和分类损失,具体计算公式如下所示:

式中,S为特征图的宽和高,本文中特征图的大小有三种:52×52,26×26,13×13,B为每个锚点位置先验框的数量;表示该锚点框是否负责预测目标,如果负责,那么,否则为0;表示不负责预测目标;xgt、ygt、wgt、hgt为真值,xp、yp、wp、hp为预测值,表示目标的坐标以及宽和高(以像素为单位);Cgt和Cp分别表示真值置信度和预测置信度;Pgt和Pp分别表示分类真值概率和分类预测概率;ω分别表示各个损失部分的权重系数,对于权重的取值本文的设定为:ωcoord=5,ωobj=1,ωnoobj=0.5,这样设置的目的是减小非目标区域的损失,增大目标区域的损失;为了进一步避免背景的损失值对置信度损失的影响,本文将Cp也作为权重的一部分自适应调整背景框的损失值.
3 实验
3.1 网络结构、参数设置及训练过程
本文采用YOLOv3框架作为检测算法的基础,分别训练了两个网络,其中一个是标准YOLOv3网络,将其作为本文方法的对比方法,详细的网络结构和参数细节见文献[25];另外一个是本文构建的网络,网络结构如图6所示.

图5 优化前后损失值示意图Fig.5 Loss value before and after optimization
对于以上这两个网络,本文都采用未经图像增强的原始样本进行训练. 为了使模型适应多种尺度的测试图片,训练过程中采用多尺度训练的方式,每10个批次(batch)更改一次图片尺寸,优化器采用自适应性矩估计(Adaptive moment estimation,Adam),学习率设置为 10−5,迭代训练 1000 次. 本文实验平台为:NVIDIA 1080Ti GPU 加速运算,11 G显存,16 G 内存.
3.2 图像增强对比实验
为了验证本文自适应图像增强算法的有效性,对三种不同光照条件下含交通标志的图片进行测试,结果如图7至图9所示.
图7是整体亮度和对比度都低的图像处理前后对比,经自适应图像增强后,从像素概率直方图看出像素值分布在更广的范围内,图像的对比度和亮度明显提高,图像的细节也能凸显出来,这对于交通标志的检测和识别是有利的.
图8是局部光照不均的图像处理前后对比,处理前图像的对比度相对较高,但交通标志处在阴影位置,不便于检测与识别. 经自适应图像增强后,像素概率直方图中暗区分布减少,整体直方图分布更加均匀,图像中光照不足的部分被加强,标志被凸显出来,且没有出现过处理的现象.
图9是亮度和强度均值都相对适中的图像样本处理前后对比,经自适应图像增强后,从像素值概率直方图和处理后的图像能看出,仅仅只是蓝色背景区域稍微加深,其余部分均无较大改变,原图像质量基本得以保留,符合本文自适应算法的要求.
通过对以上三种不同光照情况的增强对比分析,本文提出的自适应增强算法能有效提高多种复杂光照条件下的图像质量,为后续检测提供质量良好的样本,有利于检测性能的提升.

图6 网络参数图Fig.6 Network parameter diagram

图7 整体光照不足的图像. (a)图像处理前;(b)图像处理后;(c)图像处理前的像素概率直方图;(d)图像处理后的像素概率直方图Fig.7 Images with low overall illumination:(a) image before processing; (b) image after processing; (c) pixel probability histograms of image before processing; (d) pixel probability histograms of image after processing
3.3 实验检测结果及分析

图8 局部光照不足图像. (a)图像处理前;(b)图像处理后;(c)图像处理前像素概率直方图;(d)图像处理后像素概率直方图Fig.8 Images with low local illumination:(a) image before processing; (b) image after processing; (c) pixel probability histograms of image before processing; (d) pixel probability histograms of image after processing
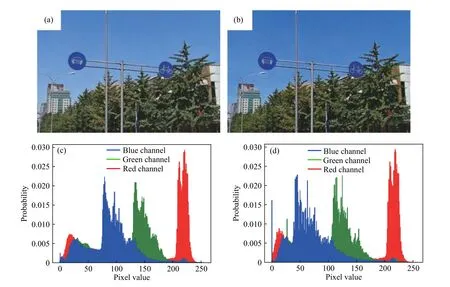
图9 光照充足图像. (a)图像处理前;(b)图像处理后;(c)图像处理前像素概率直方图;(d)图像处理后像素概率直方图Fig.9 Images with sufficient illumination:(a) image before processing; (b) image after processing; (c) pixel probability histograms of image before processing; (d) pixel probability histograms of image after processing
由于目前没有公开的弱光照交通标志数据集,本文进行了两组测试实验,首先在公开的LISA数据集上对改进YOLOv3算法(2.2和2.3节中对YOLOv3算法的改进,不包含自适应图像增强算法)进行测试验证,然后在本文开发的弱光照中国交通标志数据集(测试集)上对本文提出的增强YOLOv3算法进行对比验证. 对于检测结果的评判,本文设置置信度阈值为0.8,即置信度超过0.8时认为检测到的目标是交通标志,设置IOU阈值为0.7,即IOU超过0.7时认定为正样本,否则为负样本.
(1)LISA 数据集.
LISA数据集是以美国交通标志为基础构建的数据集,数据集中共包含6610个样本,47类7855个交通标志,标志尺寸从 6 像素 × 6 像素到 167 像素 × 168 像素不等,图像尺寸从 640 像素 × 480 像素到 1024 像素 × 522 像素不等. 由于 47 类交通标志的数量不平衡,本文只选取了停止(Stop)和人行道(Pedestrian crossing)两个数量较多的类别进行训练和测试,其中行人标志1085个,停止标志1821个,按照约1∶1的比例划分组成训练集和测试集,测试集中标志个数为1446个. 改进YOLOv3算法和YOLOv3算法的测试结果如表2所示.

表2 在 LISA 数据集上的测试结果(阈值=0.8,IOU=0.7)Table 2 Test results on LISA dataset (threshold = 0.8, IOU = 0.7)
从表2可以看出,在召回率上改进YOLOv3算法较YOLOv3高2.56%,但都只有90%左右,说明两种方法的漏检标志数量较多;准确率方面,两种方法相差不大,说明两种方法很少出现错检的交通标志. 造成这种现象的原因主要是LISA数据集中的样本通过车载相机采集,车辆运动和抖动造成图像较为模糊,从而对检测的召回率造成较大的影响.
在LISA数据集上对YOLOv3和改进YOLOv3算法的部分检测结果进行了可视化展示,如图10所示. 通过图 10(a,b)和图 10(c,d)对比发现,尽管YOLO3成功的检测到了图中的交通标志,但其检测置信度较改进YOLOv3算法的置信度略低,约为0.9~1之间,而改进YOLOv3的检测置信度基本都接近于1;此外,YOLOv3对交通标志的回归误差也较改进YOLOv3算法略大. 以上实验数据说明本文的改进YOLOv3算法不仅能够降低检测漏检率,还能提升检测正确情况下的检测效果.
(2)弱光照中国交通标志数据集.
本文构建的弱光照中国交通标志数据集(测试集)共包含样本3130张,内含4478个交通标志,在此数据集上分别测试了标准YOLOv3网络和增强YOLOv3算法的检测性能并进行对比分析,对比实验结果如表3所示.

图10 不同算法测试结果可视化对比. (a, b)标准 YOLOv3;(c, d)改进 YOLOv3Fig.10 Visual comparison of different algorithm for test results:(a, b) standard YOLOv3; (c, d) improved YOLOv3

表3 在弱光照交通标志数据集上的测试结果(阈值=0.8,IOU=0.7)Table 3 Test results on weak illumination traffic signs dataset (threshold = 0.8, IOU = 0.7)
从表中可看出,标准YOLO3对偏暗类图像、明亮类图像的检测召回率分别为96.30%和98.49%,偏暗类图像的召回率较明亮类图像的召回率低2.19%,说明标准YOLO3并没有很好的学习到弱光照交通标志的特征;而从第4行中可看出,本文提出的增强YOLO3算法对偏暗类图像、明亮类图像的检测召回率分别为98.06%和98.70%,偏暗类图像和明亮类图像的检测召回率相差不大,只有0.64%,说明本文提出自适应图像算法可以有效提高图像质量,凸显交通标志特征,降低后续检测漏检率.
从上表可看出,增强YOLOv3算法对偏暗类、明亮类和全部图像的检测召回率较标准YOLOv3方法分别高1.76%、0.21%和0.96%;在准确率方面,两种方法对两类图像的交通标志误检数量都较少,基本持平,增强YOLOv3较标准YOLOv3高0.48%.
本文对标准YOLOv3和增强YOLOv3算法的部分检测结果进行了可视化展示,如图11所示.图 11(a)和(b)显示标准 YOLO3在弱光照情况下对交通标志的检测置信度和回归结果并不理想,存在置信度低(72.9%和53.83%)和回归精度差的现象;而图11(c)和(d)显示本文提出的增强YOLOv3算法对交通标志检测的置信度为99.5%和96.8%,且边框回归准确.
以上数据表明本文提出的增强YOLOv3算法可以提高偏暗类图像的检测精度,有效解决弱光照条件下的交通标志检测与识别问题.
在实时性上,以416像素 × 416像素的图像为基准,标准YOLOv3和本文的增强YOLOv3方法检测一张图像分别需要 33 ms和36 ms,基本上保证了每秒 30 帧(30 frames per second,30 fps)的检测频率,达到了实时性的需求.
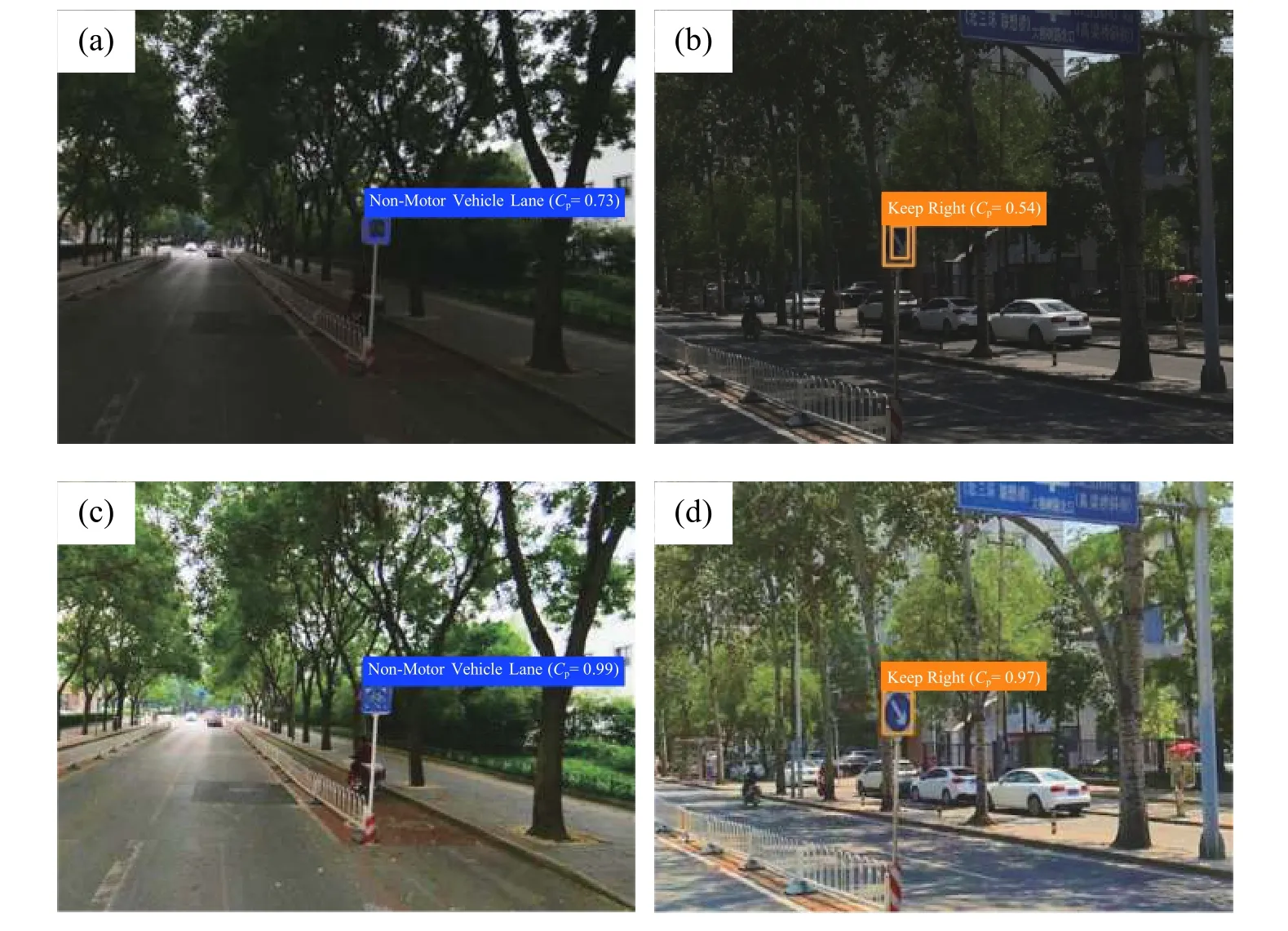
图11 不同算法测试结果可视化对比. (a, b)标准 YOLOv3;(c, d)增强 YOLOv3Fig.11 Visual comparison of different algorithms for test results:(a, b) standard YOLOv3; (c, d) enhanced YOLOv3
4 结论
本文针对通用目标检测框架不能很好解决弱光照条件下的交通标志检测与识别问题,提出了采用图像增强技术与YOLOv3框架结合的交通标志检测与识别方法. 通过将其与标准YOLOv3算法进行性能对比分析实验,得出如下结论:
(1)本文提出的自适应图像增强算法能针对多种复杂光照条件下的图像样本做出合理的调整,降低了后续检测算法的漏检率;
(2)通过改进YOLOv3聚类算法与损失函数,使训练后的检测模型更加稳定,最终检测结果置信度更高,回归位置更精确;
(3)通过将本文提出的方法与标准YOLOv3算法进行检测性能对比实验分析,验证了将弱光照条件下的交通标志检测问题分解为图像增强和交通标志检测两个任务具有更好的检测效果,为解决此类问题提供了另外一种解决思路.
由于本文提出图像增强算法较为耗时,虽然在实时性方面做了改进,达到了实时增强图像的效果,但其是在牺牲图像部分清晰度的前提下实现的. 因此在未来的工作中,需要进行基于深度学习的实时图像增强技术研究,并将图像增强与目标检测网络整合为端到端的框架,进一步提高弱光照条件下交通标志检测与识别的性能.
