基于协同知识图谱特征学习的论文推荐方法
2020-09-18刘柏嵩刘晓玲黄伟明
唐 浩,刘柏嵩,刘晓玲,黄伟明
(宁波大学 信息科学与工程学院,浙江 宁波 315211)
0 概述
学术论文作为科研人员重要的学术资源,在整个科学研究过程中起到关键作用。在快速发展的互联网时代,学术论文发文量呈现爆发式增长态势,用户面临日益严重的论文信息过载问题,而学术论文推荐被认为是缓解该问题的有效途径,可帮助用户快速了解自身研究领域的学术前沿与动态。通过计算用户与论文的相关性生成Top-N推荐列表,以满足用户对新文章或经典文章的个性化需求[1]。
目前,常见的论文推荐方法一般分为基于协同过滤(Collaborative Filtering,CF)的论文推荐方法、基于内容过滤(Content-Based Filtering,CBF)的论文推荐方法和基于网络结构的论文推荐方法。基于CF的论文推荐方法应用最广泛,然而其面向海量论文时存在严重的数据稀疏性问题,并且还因为仅使用用户-项目交互数据计算推荐结果,导致论文相关性较低。基于CBF的论文推荐方法实现简单却依赖文本相似度判断推荐相关性,难以保证论文质量,而且对于海量论文的计算代价过大。基于网络结构的论文推荐方法存在冷启动问题,例如引文网络中前沿工作的引文较少,新文章在引文网络中被边缘化,并且该方法还忽视了文本内容价值和用户兴趣。总而言之,以上方法均不能有效解决协同过滤的数据稀疏性问题。此外,用户阅读行为通常存在很强的目的性,其阅读视野一般局限于个人掌握背景知识范围内的系列论文[2],因此在保证推荐列表与用户有较强相关性外,还需获取和扩展用户的潜在兴趣。
知识图谱(Knowledge Graph,KG)自提出以来在电影[3]、图书[4]、新闻[5-7]等推荐场景中取得了较好的效果,由于知识图谱内蕴含丰富的结构化知识、背景知识和实体的语义关联特征,因此知识图谱增强推荐成为目前的研究热点[7-9]。研究人员试图使用多任务学习[4]或联合学习[3]等方法从电影或图书知识图谱中将知识迁移到推荐过程,在一定程度上缓解了数据稀疏性问题。文献[3]结合推荐计算与链接预测,并借鉴基于翻译的知识图谱表示学习算法TransH统一推荐任务与知识图谱补全任务,提升了知识图谱的应用效果。文献[5]使用卷积神经网络(Convolutional Neural Network,CNN)模型的输出表示新闻特征和建模用户的历史兴趣,保持新闻中单词、实体和实体上下文的对齐关系,并将其作为CNN模型的3个输入通道,增强新闻文本单词在知识级别的表示。然而,论文知识图谱的实体数量庞大,多任务学习方法计算代价较大,并且若要达到论文单词和实体之间较好的对齐效果,则需要高质量的概念知识库。本文提出基于知识图谱表示学习的论文推荐方法(KIRec),使用基于翻译的知识图谱表示学习算法充分利用知识图谱中实体间的关系信息,以解决CF的数据稀疏性问题,并保证推荐结果的多样性。同时,利用文本信息引导用户节点特征及其邻域特征的融合生成最终用户特征表示,实现对用户与历史论文之间的交互进行有效表示。
1 相关工作
1.1 基于知识图谱的协同过滤
由于将知识图谱作为辅助信息引入到推荐系统中可以有效解决传统推荐系统存在的稀疏性和冷启动问题,因此本文主要研究基于语义路径和特征学习的知识图谱协同过滤方法。
1)基于语义路径的知识图谱协同过滤方法。文献[10-12]通过元路径计算相似路径下用户与项目的关联性,实现知识图谱的协同过滤。PER[10]方法沿着不同元路径扩散用户偏好,在矩阵分解(Matrix Factorization,MF)的语义假设下,输出用户和项目隐式表示。HINE[13]方法使用基于元路径的随机游走策略将节点序列集成到扩展的MF模型中。文献[6]提出通用的规则推导模块,即使用游走计算两个项目间路径的概率,提升了贝叶斯个性化排序(Bayesian Personalized Ranking,BPR)和神经协同过滤(Neural Collaborative Filtering,NCF)[14]等模型的性能,从而得到项目与项目的特征向量对,该方法通过自动学习知识图谱上的用户偏好规则完成现有神经网络模型的协同过滤。但以上方法的路径设计过程复杂,需要具备领域知识,并且忽略了用户-项目中存在的其他语义路径。
2)基于特征学习的知识图谱协同过滤方法。该方法将实体和关系映射为低维稠密向量,辅助增强用户和项目的表示。TransE-CF[15]融合了项目之间与对应实体之间的语义近邻,在一定程度上解决了冷启动问题。CKE[16]在协同过滤中同时融入文本信息、结构信息和图像信息,使用TransR学习结构信息的表示。DKN[5]在学习特定新闻语义时利用基于三通道的卷积神经网络,融合知识图谱的实体特征并基于知识感知进行新闻推荐。针对基于项目的协同过滤方法只使用协同相似性关系而忽略了真实场景中各项目之间多种关系的特点,RCF[9]基于项目和关系构建知识图谱,分层考虑关系类型和关系值。对于数据稀疏性和冷启动问题,文献[17-18]提出KGCN和KGCN-LS方法,研究卷积网络如何自动挖掘知识图谱用户以及项目高阶结构信息和语义信息,从而获取用户潜在兴趣。为充分利用项目或实例之间的关系,采用高阶关系建模的KGAT[8]基于用户-项目二部图和项目知识图谱构建协同知识图谱。MKR[4]是一种通用的交替学习框架,其主要思想为将交叉压缩单元作为知识图谱表示学习与推荐任务的信息交互通道,用于自动共享隐式特征。本文方法是一种基于特征学习的协同过滤推荐方法,其在用户表示过程时有选择性地融入了文本信息与结构信息,即将文本信息形式化为注意力权重,且在建模交互阶段采用多层感知机(Multi-Layer Perceptron,MLP)代替点积运算。
1.2 基于知识图谱的协同过滤应用场景
基于知识图谱的协同过滤方法在多种推荐场景中得到广泛应用。表1总结了基于知识图谱的协同过滤应用场景,可以看出其在电影和图书推荐中应用最多,主要原因为这两类推荐容易获得对应实体,而对于论文类学术文本的推荐,需构建分层的概念知识图谱,实现难度较大。

表1 基于知识图谱的协同过滤应用场景
2 协同知识图谱构建

定义2(协同知识图谱) 基于用户-项目交互图,融入论文知识图谱,形式上表示为CKG=
为获取论文相应的实体,需选择合适的知识库。本文从实体数量、数据质量和获取难易程度等方面考虑,最终确定两个开放论文知识库OAG[10-11]和Acemap[19]来作为构建知识图谱的原始数据链接源。基于SPARQL语句,以在线的方式从上述知识图谱中获取首次链接实体及若干关联后的实体与关系。协同知识图谱构建具体包括实体链接与消歧、关系类型筛选和三元组存储。
1)实体链接与消歧:根据论文标题将论文链接到知识库中的实体。由于论文实体的同名歧义问题,使部分查询结果不唯一,因此使用论文的多个元数据识别产生歧义的论文。另外,知识库的内容虽然丰富,但也存在实体链接不成功的问题,本文通过将用户视作特殊实体,在协同知识图谱中保留未找到关联的论文,即融合用户-论文二部图。
2)关系类型筛选:定义协同知识图谱模式,构建协同知识图谱。模式中的关系类型包括用户与论文的交互关系、论文与论文的引用关系、论文与作者的写作关系、论文与出版物的出版关系、论文与关键词的提及关系以及论文与领域的从属关系。
3)三元组存储:清洗查询数据和规范化三元组,通过TDB数据库工具存储协同知识图谱,并使用Jena接口进行查询和推理。
3 基于协同知识图谱的论文推荐
本文提出的KIRec总体框架如图1所示。KIRec框架主要分为三部分:1)将协同知识图谱中的节点(用户和论文等)映射为低维稠密向量;2)实现用户和论文表示,其主要工作为文本信息感知的知识图谱上的邻域融合;3)通过堆叠的MLP计算论文推荐得分并生成候选列表。
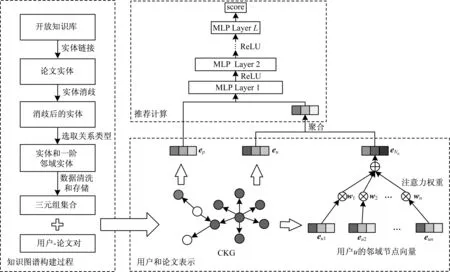
图1 KIRec总体框架
3.1 实体特征表示
协同知识图谱利用符号形式对用户和项目进行建模,在知识图谱上可以直观地表示两者的路径关联。通过元路径设计可以较容易找到用户感兴趣的待推荐论文,然而由于元路径的设计效率低且需要具备领域知识,因此本文选择分布式的知识图谱节点特征表示方式。知识图谱表示学习算法在保存知识图谱结构的同时将实体映射为低维稠密向量,其因为结构简单且高效的特点而受到研究人员的广泛关注,例如TransE[20]通过优化翻译准则eh+r≈et(其中,eh表示头实体,r表示关系,et表示尾实体),高效学习实体和关系的向量。然而,TransE算法难以处理多对多和多对一问题。在本文中,CKG中的同一个关系可能对应多个实体,或者同一个作者发表多篇论文,或者一篇论文对应多个作者。在CKG上应用TransR、TransH[21]、TransD等算法能有效解决上述问题。在协同知识图谱上使用TransH算法相当于将推荐任务转换为KG链接预测任务。在表示学习过程中,用户与项目之间潜在的偏好关系将通过其他关系进行体现,表示结果将蕴含用户对未阅读论文的偏好。
以用户实体eu和论文实体ep为例,基于超平面TransH翻译函数的三元组合理性计算公式如下:
(1)
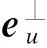
(2)
(3)
其中,Wr为投影矩阵,根据特定关系将实体映射到超平面。从CKG中学习到的实体向量主要包括待推荐论文表示向量ep,知识图谱上的用户表示eu和用户节点邻域集{eu1,eu2,…,eun}。
3.2 融合文本特征的用户表示
在用户兴趣建模阶段,融合知识图谱的用户节点以及该节点的一阶邻域节点,有利于获得用户更全面的特征表示。常用的邻域融合方法是直接对邻域表示向量求平均值,计算公式如下:
(4)
该平均方式将所有论文同等对待,但显然未对用户兴趣进行区分,而且只考虑了KG中包含的结构信息。为更好地衡量用户已阅读的文本信息对用户建模的影响,使用注意力机制计算邻域节点的权重,计算方法如图2所示,待推荐论文向量和历史论文向量即句子向量,权重在图1中使用wi(i=1,2,…,n)进行表示。该模块的主要思想在于计算待推荐论文与历史论文的文本匹配得分,衡量该论文对于用户兴趣的符合程度,可见注意力机制能有效感知用户面对不同论文时的感兴趣程度。

图2 基于注意力机制的邻域节点权重计算
ci=Φ(h∘wi:i+k-1+b)
(5)

为融合基于TransH表示的用户节点和基于注意力机制的节点邻域信息,文本使用双交互聚合方式[8]将eu和eNu聚合为最终的用户表示:
LeakyReLU(W2(eu+eNu))
(6)
其中,⊙为向量对应元素的乘积运算,W1和W2为可训练的参数矩阵,该聚合方式能对用户与历史论文之间的交互进行有效表示。
3.3 推荐计算

⋮
(7)
其中,ai(i=1,2,…,L)是多层感知机的激活函数,此处选择ReLU函数,Wj和bj(j=1,2,…,L)分别表示可训练的参数矩阵和偏置。最后使用输出函数计算得分:
sscore=φout(zL)=σ(hTzL)
(8)
其中,σ表示最后一层的输出函数,选择sigmoid函数σ=1/(1+e-x)。
4 实验结果与分析
4.1 实验环境与数据集
本文实验运行环境为Linux操作系统、64 GB内存、2 TB硬盘、NVIDIA TITAN Xp显卡、Python 3.6版本。为验证KIRec方法的有效性,实验使用公开获取的CiteULike-a数据集[24-25],包含用户和论文的交互记录210 518条,数据稀疏性为99.78%。该数据集通过虚拟论文资源共享平台CiteULike收集和整理而成,其允许用户在线创建和管理文献。首先,CiteULike平台的用户注册后可创建文献兴趣仓库,反映了真实场景下用户对文献的历史偏好,因此收集到的数据满足实验需求。其次,CiteULike-a数据集包含清洗后的用户-项目对、论文标题和摘要等数据,其论文标题在预处理后与知识库进行实体链接,具有较高的成功率,其文本内容也满足本文注意力机制的实验数据需求。最后,CiteUlike-a数据集的数据稀疏性较高,有效验证了CKG有助于提升协同过滤算法的性能。
对于数据集的预处理,实验参照常用处理方式[3,22,24],如果用户与论文存在交互则编码为1,否则编码为0。实验所需的额外实体和关系来自OAG和Acemap论文知识库,知识库基于图结构保存论文实体、论文元数据及它们之间的关系。针对知识库的查询实验设置关联次数为1,即查询结果包括应用实体链接技术获取的实体集合及该集合中所有实体的一阶邻域实体集合。查询结果以json格式的数据返回,经过数据清洗和数据消歧等操作后所得数据统计如表2所示。考虑到实验性能且为保证数据集质量,去除交互记录数量少于5的用户[3,14]及过滤出现次数低于阈值δ的实体以及对应的边。实验中选取δ=5得到形如(头实体,关系,尾实体)的三元组数量为1 184 131。将用户-论文隐式反馈对按照7∶3的比例划分为训练集和测试集,嵌入向量的维数d=100。

表2 实验数据统计
4.2 评估方法
在评估阶段,随机选取100篇用户未交互的论文,与测试集的论文同时进行排序。选择两种常用于衡量推荐结果排序质量的评价指标HR@N和NDCG@N,计算基准方法的平均得分。HR@N表示前N篇推荐论文中,正确预测用户偏好的论文在其中所占的比例,可直观地看出论文是否出现在推荐列表中。NDCG@N为归一化折损累积增益,衡量了推荐列表中前N篇论文的排序质量。对于用户感兴趣的论文,根据其位置累积增益,对于不感兴趣的论文则增益为0,最终对排序位置进行折损,将用户感兴趣的论文排在前面。
4.3 基准方法
本文选取两类基准对比方法:
1)基于MF与CBF的论文推荐方法。前者基于协同过滤的矩阵分解方法,广泛应用于多种推荐场景。后者基于内容过滤,实验主要评估论文标题和摘要的相似度指标。
2)基于知识图谱的论文推荐方法:CKE[16]和DKN[5]。前者结合项目结构信息、文本信息和图像信息的协同推荐算法,实验过程中应用项目结构信息和文本信息特征。后者通过融入知识图谱信息和文本信息的知识感知模型,并使用CNN进行实体向量和邻域向量的特征提取。
4.4 结果分析
表3显示了KIRec方法与基准方法在N=10时的实验结果,可以看出CF方法推荐效果较差,其主要原因可能为不同用户对于论文阅读感兴趣领域不同,只依赖协同关系的推荐列表在数据稀疏的情况下推荐结果会产生较大偏差。CBF方法相对CF方法推荐效果有一定程度的性能提升,其主要原因为用户阅读兴趣在很大程度上取决于其阅读过的文本与待推荐文本之间的语义相似性。由此可见,基于知识图谱的论文推荐方法效果优于基于MF与CBF的论文推荐方法,而KIRec方法能取得最优效果的原因主要与结构信息、文本信息的融合相关,基于注意力机制的DKN和KIRec方法比未使用注意力机制的推荐方法性能更好。

表3 5种推荐方法的实验结果比较
表4对比了4种基于翻译的知识图谱表示学习算法对KIRec方法的影响,可见KIRec+TransH方法的性能表现最好。此外,实验还对无邻域信息(withoutNu)的KIRec方法、通过求解领域信息平均值的方式代替注意力机制(Nuby Average)的KIRec方法和本文KIRec方法进行对比,实验结果如表5所示,可以看出这两种参数设置方式能有效提升KIRec方法的推荐效果。
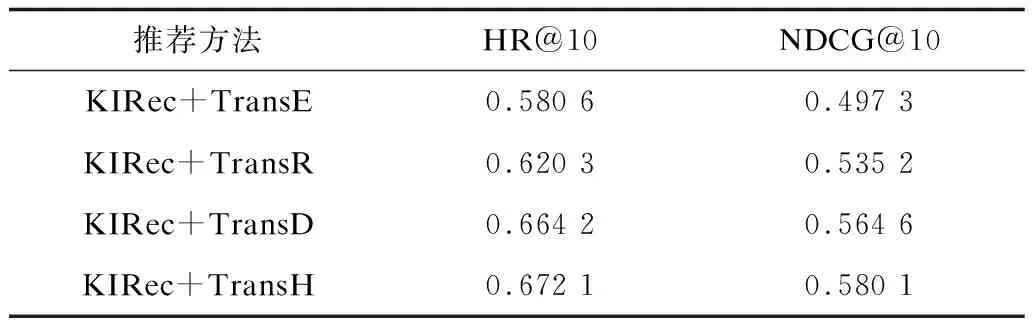
表4 基于知识图谱表示学习算法的KIRec实验结果比较
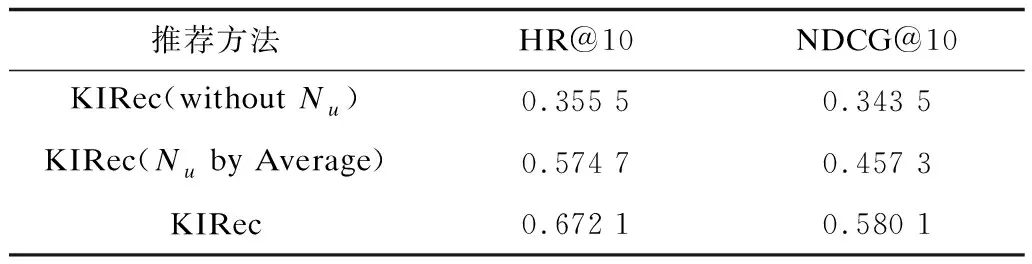
表5 不同参数设置方式的KIRec实验结果比较
5 结束语
在海量论文中为用户进行个性化论文推荐时,数据稀疏性问题严重影响了论文推荐质量。为此,本文提出基于协同知识图谱特征学习的论文推荐方法,采用协同知识增强方式加强语义关联性,利用结合文本信息与结构信息的注意力机制对用户偏好进行建模。同时,使用聚合函数融合用户在知识图谱上的邻域特征表示,并通过多层感知机的非线性变换提高用户与论文的推荐得分。实验结果表明,与传统推荐方法和基于知识图谱的推荐方法相比,该方法具有更好的推荐效果和排序质量。但本文构建的知识图谱中的关系类型较少而论文实体数量较多,且在获取知识库实体时仅选取关联次数为1的相关实体,后续将在研究多样化关系和用户偏好类型的基础上,增加知识库相关实体的关联次数,进一步提高论文推荐准确率。
