基于距离和密度的PBK-means算法
2020-09-18魏文浩唐泽坤
魏文浩,唐泽坤,刘 刚
(兰州大学 信息科学与工程学院,兰州 730000)
0 概述
数据挖掘是指从大量的数据中通过算法搜索隐藏于其中信息的过程,已广泛应用于大中型企业、军事、银行、医学等领域[1]。聚类是数据挖掘中将物理或抽象对象的集合分成由类似的对象组成的多个类的方法。由聚类所生成的簇是一组数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其他簇中的对象相异[2]。在自然科学和社会科学中[3],存在着大量的分类问题。
在现实世界中存在着越来越多的无标签数据,因此使用无监督学习方法解决问题就显得非常重要[4],而无监督学习中的聚类则可以利用数据自身特征对无标签数据进行分类。文献[5]提出一种基于简单观测的迭代方法,由数据集导出K个簇的质心作为中心点,即K-means聚类算法。K-means算法因思想较为简单且易实现的特点,成为应用最广泛的聚类算法[6],它将距离作为相似度把数据集分为若干个类[7-8],在同一类中,数据间的相似度更高,在不同的类中,数据间的相似度更低。但是K-means算法也有局限性,如算法初始中心设置的随机性使聚类结果易陷入局部最优解,并且聚类结果不稳定,易受噪声点影响。
近年来,研究人员提出了很多新的聚类算法,其中多数是对于K-means算法初始聚类中心选择的优化。文献[9]通过将数据集划分为几个最佳子集,然后在每个子集选择中心点,解决了K-means算法中心点选择的随机性问题,但中心点的合理性取决于数据集划分的好坏。文献[10]将数据集存储在kd-tree中,根据距离选择中心点,未考虑密度对聚类效果的影响。除使用kd-tree减小算法时间复杂度外,R*-tree[11]和X-tree[12]也被用来存储数据集,但也相应地增加了空间复杂度。文献[13]提出基于统计相关性的区分因子算法,通过引入Pearson指标[14]决定聚类过程,可以自动确定簇数,但多次BWP指标的计算增加了算法时间复杂度。文献[15-17]提出了WK-means算法,该算法通过特征加权[18]选择中心点,考虑了数据特征对聚类效果的影响,但是没有考虑特征值的尺度和特征权重之间的直接关系,因此文献[19]提出MWK-means算法,采用异常簇初始化的方法解决上述问题,但当数据集更加复杂时,MWK-means算法需要更多时间进行特征加权。文献[20]提出一种邻聚类算法,利用图熵的概念可以对复杂数据集进行有效聚类,DBSCAN[21]和OPTICS[22]根据密度选择核心对象进行聚类分析,但这3种算法都对阈值的设定存在一定敏感性。2014年,《Science》杂志发表一篇基于密度峰值的快速聚类算法[23],但没有给出明确的阈值设定,文献[24]提出了DCK-means算法,利用数据集特征选择初始聚类中心,参数设置更加合理,但当数据集规模变大时算法时间复杂度会大幅提升。
针对以上问题,本文提出一种PBK-means算法。该算法考虑密度和距离对聚类效果的影响,将得到的初始聚类中心作为K-means算法的输入参数,解决K-means算法易陷入局部最优解和抗噪能力差的问题。同时采用构造满二叉树的方法并行产生聚类中心,以降低算法的时间复杂度。
1 相关算法
Bisecting K-means算法是一种无监督学习算法,由STEINBACH、KARYPIS和KUMAR于2000年提出,该算法通过对待切分簇的选择和切分结果的优选来获得高质量的初始聚类中心。如图1~图3所示,为了得到K个簇,将数据集所有点作为一个簇,放入簇表中,不断地从簇表中选择簇使用K-means算法进行二分聚类,从所有二分实验中选取具有最小SSE值和的2个簇,更新簇表,直到产生K个簇。
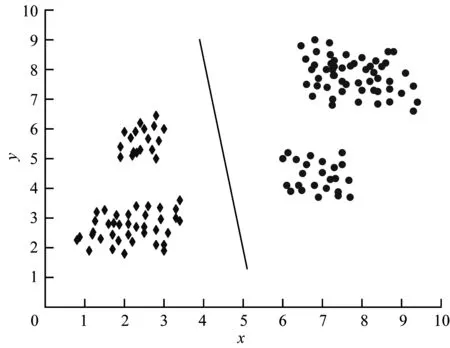
图1 K-means算法二分聚类步骤1
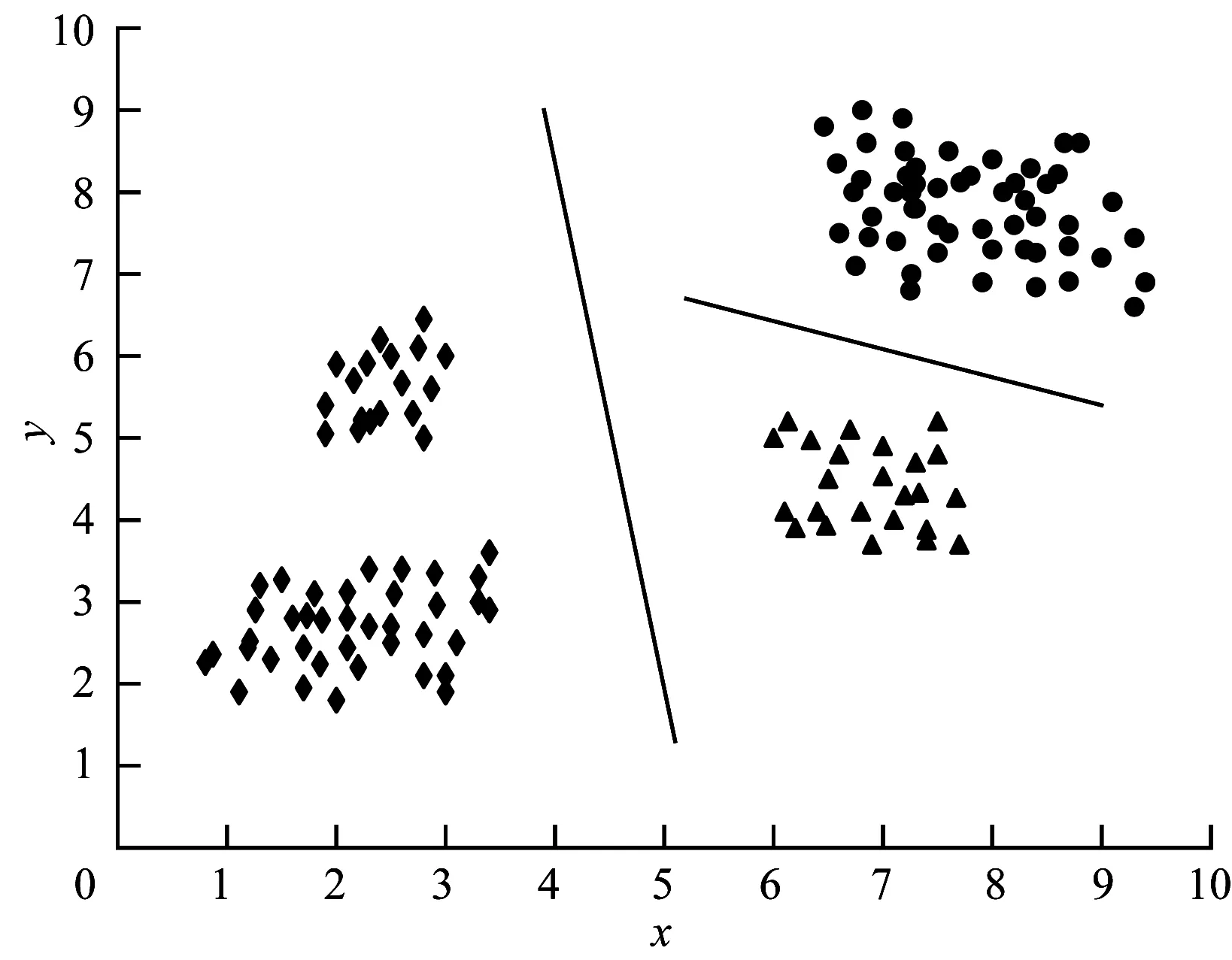
图2 K-means算法二分聚类步骤2

图3 K-means算法二分聚类步骤3
算法1二分K-means算法
输入数据集D,聚类数K
输出聚类结果
1.initialize the Array List
2.compute the center S of mass of D
3.add S to the central point sets C
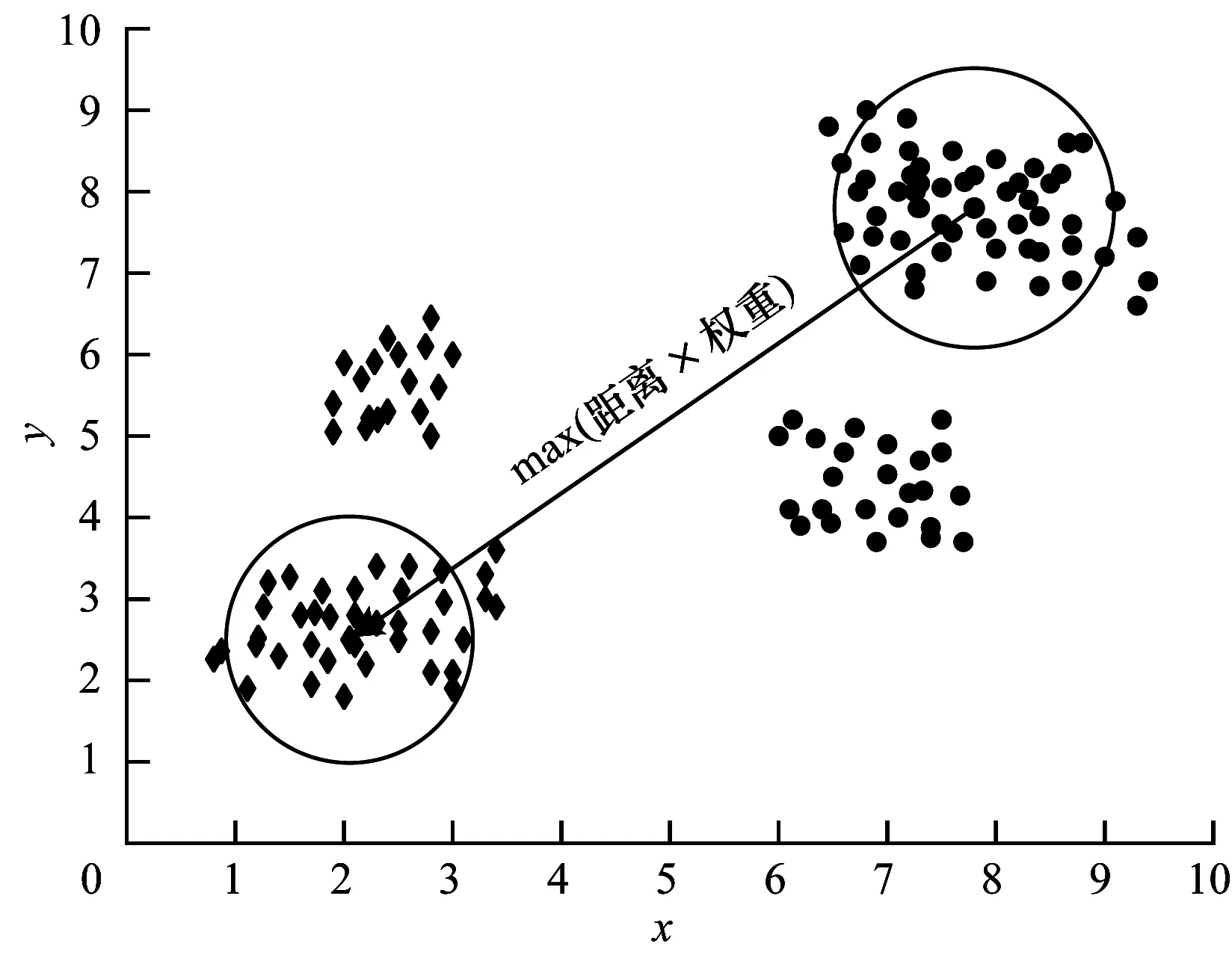
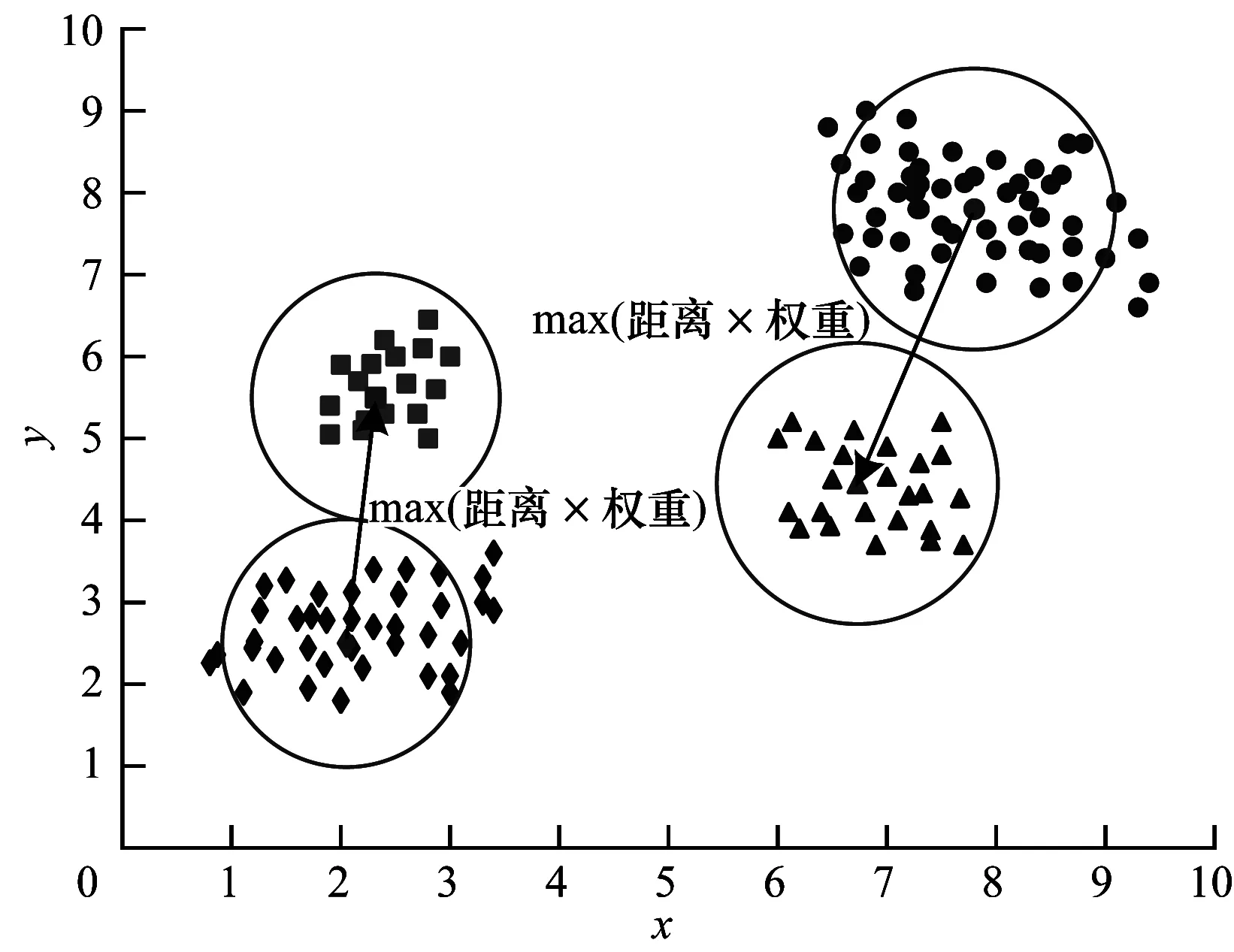
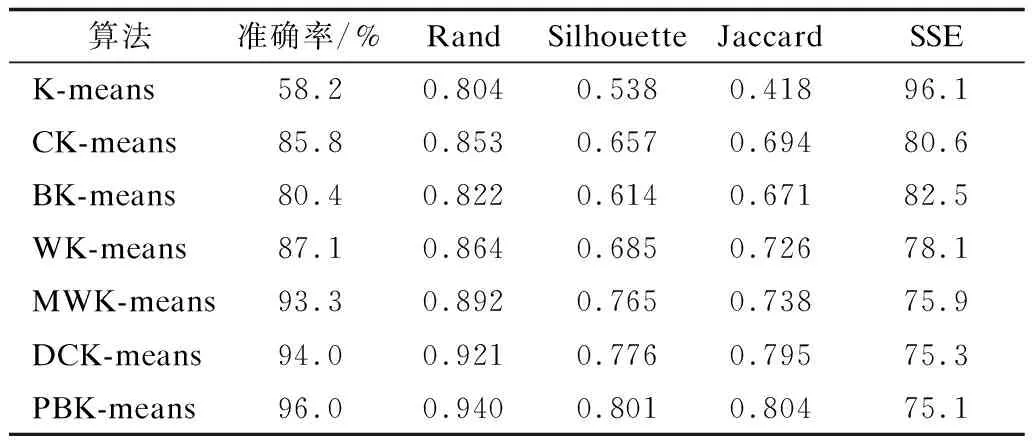
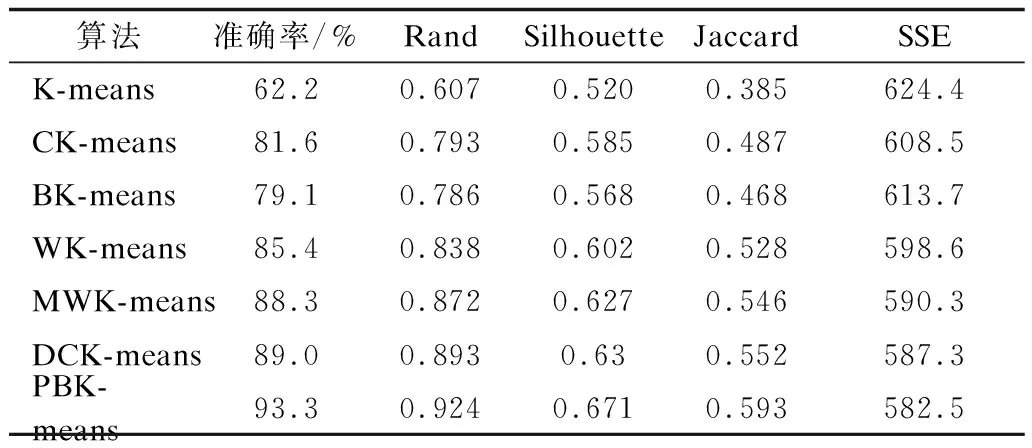
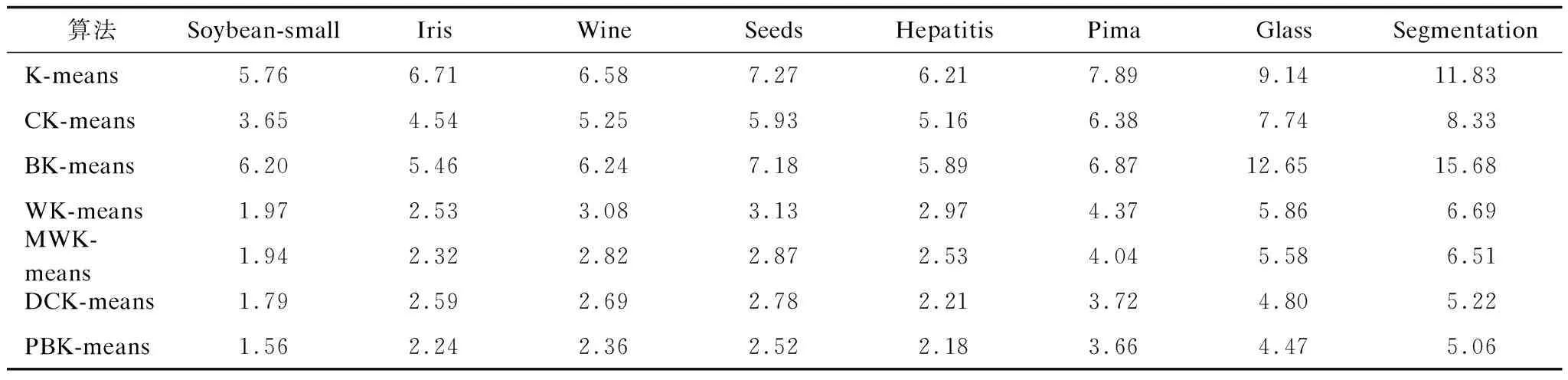
4.WHILE(size of C 5. FOR(each sample i∈C){ 6. K-means(Di,2) 7. get the data sets Di1,Di2belonging to i1,i2 8. compute the SSE values of D 9. }END FOR 10. select j1,j2with minimum SSE values 11. remove j in sets C 12. add j1,j2to sets C 13.}END WHILE 14.PRINT(sets C,D after classification) 算法具体步骤如下: 步骤1给定聚类数K和数据集D={x1,x2,…,xn}。 步骤2计算D的质心,并把它加入中心点集合C中。 步骤3遍历C中的全部中心点,使用K-means算法将每个中心点代表的类分为两类,并计算分类后数据集D的SSE值的和。 步骤4选择SSE值最小的簇群,用新生成的两个中心点覆盖C中的生成这两类的中心点。 步骤5重复步骤3和步骤4,直至得到K个中心点。 对于含有K个中心点的集合C,ci为簇Ci的聚类中心,x为该簇中的一个样本,d(x,ci)表示x与ci之间的欧氏距离,SSE指标的计算公式为: SSE指标的计算增加了算法时间开销,同时,使用K-means算法将簇一分为二会受到K-means算法随机性的影响,不能保证收敛到全局最优值。因此,本文提出一种基于距离和密度的并行二分K-means算法,取消了SSE指标的计算,加入权重的概念,在保持数据集空间划分合理性的前提下解决了中心点选择的随机性问题。 对于给定数据集D={x1,x2,…,xn},每个样本元素可表示为xm={xm1,xm2,…,xmr},1≤m≤n,其中,r是样本元素的维度,d(xi,xj)代表样本元素xi和xj之间的欧氏距离。 定义1数据集D的平均样本距离定义为[24]: (1) 定义2数据集D的特征空间大小定义为: (2) 其中,maxi和mini分别代表数据集第i个特征上的最大值和最小值。 定义3样本元素i的密度参数定义为[25]: (3) 定义4观察式(3)很容易发现p(i)是以数据样本i为圆心,以MeanDis(D)为半径的圆内的数据样本数量。计算数据样本i与圆内全部数据样本的距离,结合数据集特征空间大小,样本元素i的距离参数定义为: (4) 定义5样本元素i的异类参数定义为: (5) 其中,m是密度参数大于样本数据i的样本数据数量。 定义6样本元素i的权重定义为: (6) 其中,w(i)的大小与p(i)和a(i)成正比,与t(i)成反比。t(i)与a(i)的设定相对文献[24]的参数设定进行改进,利用Range参数将每个数据对t(i)的贡献度控制在[1,1+r]之间,a(i)计算了密度参数比i大的全部数据点与i的平均距离,规范化密度和距离对聚类的影响,考虑了全局的数据点分布,有利于发现全局最优而不是局部最优。p(i)值越大,点i的MeanDis(D)半径内的点越多,t(i)值越小,点i的MeanDis(D)半径内的点越密集,a(i)值越大,两个以MeanDis(D)为半径的圆差异越大。因此,每次根据权值w选取下一个中心点可以保证数据集空间划分合理性,同时,p(i)的设定可以明显提高算法的抗噪能力。 首先将数据集一分为二得到两个簇,然后以每个簇为起点再一分为二,如此重复,第r次获得2r个簇,此过程与细胞分裂过程类似。细胞分裂式的二分给予每个簇均等的切分机会,每次迭代都要对所有的簇进行切分,这个过程可以并行实现,最后会产生一棵完全二叉树。 显然,对于K=2r的数据集,PBK-means算法可以直接得到结果,对于2r-1 虽然都采用了二分思想,但二分K-means算法与本文提出的算法差别依旧明显,二分K-means算法通过计算SSE值确定要切分的簇,每次迭代只切分一个簇,完成聚类需要多次计算SSE值,增加了时耗。PBK-means算法通过结合权值保证每次对簇的切分都得到较好的效果,第r次迭代同时对2r-1个簇进行切分,同时并行实现的特点使本文算法的执行时间大幅减少。 根据式(6)计算样本的权重,如果满足条件max(p(i)/t(i)),则将样本元素i作为第1个聚类中心,计算所有样本元素与当前聚类中心的距离,小于MeanDis(D)的样本元素不能参与下一次聚类中心的选择,将此距离与权重相乘,选择相乘后最大值样本元素作为第2个聚类中心。通过产生的2个中心点生成2个簇,然后对产生的全部子簇重复上述过程,在迭代过程中不断更新子簇的MeanDis(D),直到产生的子簇数大于或等于需要的类数K。通过最大权重选择中心点的并行二分方法步骤如图4和图5所示。 图4 本文算法并行二分方法步骤1 图5 本文算法并行二分方法步骤2 算法2PBK-means算法 输入数据集D,聚类数K 输出聚类结果 1.initialize the Array List 2.initialize Central point sets C//创建中心点集合C 3.compute Range(D) 4.WHILE(size of C 5. get the data sets Dici//将D中的元素分配给ci//生成Di 6. computeMeansDis(Di)//计算Di相关参数 7. FOR(each center ciC){ 9. compute p(j) and t(j) 10. } 11. select center ci1←sample max(p(j)/t(j))//通过最//大权重原则选择2个新的中心点 13. compute a(j) 14. compute w(j)=p(j)*a(j)*1/t(j) 15. } 17. compute d(j,ci1) 18. IF(d(j,ci1)>MeanDis(Di)){ 19. center ci2←sample max(d(j,ci1)*w(j)) 20. } 21. } 22. FOR(each center ciC){//更新中心点集合C 23. remove ciin sets C 24. add ci1,ci2to sets C 25. } 26.}END WHILE 27.update C//合并更新中心点集合C 28.K-means input(C,K)//将中心点集合C和类别数K//作为输入参数执行K-means算法 29.WHILE(new center!=original center){ 31. FOR(each centercjC){ 32. Compute d(i,cj) 33. } 34. IF(MinDis=d(i,cj)){ 35. centercj←sample i 36. } 37. }END FOR 38. compute new center ci=Mean(sample(i&&(icenter ci))) 39.}END WHILE 40.PRINT(Cluster C) 算法具体步骤如下: 步骤1给定数据集,根据式(6)计算所有样本的权重,选择满足条件max(p(i)/t(i))的c1作为第1个聚类中心,并将c1加入到集合C中。同时,与c1的距离小于MeanDis(D)的样本不能参与下一次聚类中心的选择。 步骤2计算剩余样本与c1之间的距离,选择满足条件max(w(i)×d(i,c1))的样本元素设为c2,并将其加入到集合C中。 步骤3根据距离将所有样本元素分配给c1和c2,得到2个簇。然后重新计算这2个簇的MeanDis(D)和簇中全部样本元素的w。对于产生的2个簇,并行执行步骤1和步骤2,产生4个新的聚类中心c3、c4、c5、c6。删除集合C中的c1和c2,并将c3、c4、c5、c6加入集合C中。 步骤4根据距离将对应的样本元素分配给集合C中的m个中心点,产生m个簇,更新每个簇的MeanDis(D)和簇中的样本元素权重,对产生的m个簇并行执行步骤1和步骤2,删除集合C中原有元素,将得到的2m个聚类中心添加到集合C中。 步骤5重复步骤4直至集合C中的元素个数大于或等于类数K。迭代q次后会得到2q个聚类中心,如果大于K,则使用PCA将2q个中心点减少至K个。 传统K-means算法的时间复杂度可以被描述为O(nKT),n是样本集中的样本元素个数,K是分类数,T是算法迭代次数。本文提出的PBK-means算法时间复杂度为O(n2+nr+nKT),文献[24]提出的DCK-means算法时间复杂度为O(n2+nS+nKT),r是使用二分法的迭代次数,r值较小,约等于lbK,S是寻找中心点的迭代次数,大小约为K,T是产生的初始聚类中心执行K-means算法的迭代次数,O(n2)是使用最大权重法耗费的时间复杂度。将本文提出算法得到的初始聚类中心作为K-means算法的输入参数时,需要的迭代次数T明显小于传统K-means算法随机选取聚类中心所需的迭代次数T,因此,PBK-means算法的时间复杂度主要由数据集规模n决定。在处理规模中小型数据集时,本文算法在聚类效果和耗时方面都有较好的表现。当数据集规模增大到一定程度时,本文算法的时间复杂度约为O(n2)。目前提出的改进聚类算法由于结合密度或距离,算法时间复杂度均在O(n2)~O(n3)之间,本文算法由于结合了并行实现的特点,初始中心点的选择过程耗时更短,效率更高。 对本文提出算法以及对比算法进行的实验由以下3个部分组成: 1)算法中心点合并策略; 2)测试本文算法与对比算法在实验数据集上的精准度等聚类指标; 3)比较本文算法与对比算法在实验数据集上聚类所用的时间。 实验环境为8 GB内存、Intel®CoreTMi5-7500、3.40 GHz,Windows10操作系统。 本文实验用到了UCI数据集,从UCI 网站获取,数据集参数如表1所示。 表1 实验数据集参数 3.2.1 中心点合并策略 当实际聚类数为k时,若k正好为2r,则本文提出算法在r次迭代后得到的中心点可直接作为初始中心点执行K-means算法。若2r-1 图6 不同合并方法精度 从图6可以看出,PCA在合并策略中表现最好,在5个UCI数据集上均取得了最高的聚类精度,PCA方法的原理是将中心点集数据矩阵转置后把原先的2r个特征用数目更少的k个特征取代,从旧特征到新特征的映射保持原有数据特性。t-SNE比其他3种方法表现都好,但与使用PCA时的聚类精度平均相差2.36%。在类别数和样本数较少时,通过聚类特征对簇进行合并产生的聚类效果较差。 3.2.2 聚类效果 聚类效果通过准确率、兰德系数(Rand)、轮廓系数(Silhouette)、Jaccard系数、SSE指标评判。Canopy-Kmeans算法表示为CK-means,二分K-means算法表示为BK-means,本文提出的算法表示为PBK-means。本文算法与DCK-means算法得到的聚类结果是固定的,对其他5种对比算法分别进行100次实验,取实验结果的平均值。表2~表9为算法在UCI数据集上的实验结果。 表2 Soybean-small数据集聚类结果指标 表3 Iris数据集聚类结果指标 表4 Wine数据集聚类结果指标 表5 Seeds数据集聚类结果指标 表6 Hepatitis数据集聚类结果指标 表7 Pima数据集聚类结果指标 表8 Glass数据集聚类结果指标 表9 Segmentation数据集聚类结果指标 通过表2~表9对聚类结果各项指标的比较发现:本文提出的算法在Segmentation数据集上与DCK-means算法基本相同,原因是Segmentation数据集不同类别的数目差异较大,数据分布分隔明显,由于DCK-means算法与本文算法都考虑了距离与密度,因此都能得到较好的结果。而在其他数据集上PBK-means算法各项指标均是最优的,本文提出算法在上述8个UCI数据集上的聚类结果准确率比传统K-means算法高27.1%,比Canopy-Kmeans算法高13.6%,比Bisecting K-means算法高14%,比WK-means算法高9.4%,比MWK-means算法高5.8%,比DCK-means算法高3.3%。无论是二分类任务或者多分类任务,PBK-means算法都能得到较好的聚类效果,证明了算法思想和参数设置的合理性。本文提出的PBK-means算法通过结合距离与密度,每次将选择的向量空间一分为二,相比于其他算法,更好地考虑了样本集全部数据的分布情况,初始中心点的选择结合了距离与密度,可以更快地收敛至全局最优。 3.2.3 聚类时耗 本节比较了PBK-means算法与6种对比算法在UCI数据集上聚类所用的时间,具体耗时如表10所示。 表10 UCI数据集聚类耗时 通过对表10的分析,可以得出以下结论: 1)传统的K-means算法随机选择初始聚类中心,Canopy-Kmeans算法已选取中心点固定半径内的点不能选为中心点,但中心点的选取仍是随机的,Bisecting K-means算法第1个中心点选取数据集质心,但后续对簇的二分过程相当于面对二分类任务时的传统K-means算法。以上3种算法选取初始中心点的随机性造成后续迭代多次才能得到稳定的聚类结果,因此聚类耗时较大。 2)在面对多分类任务时,二分K-means算法计算SSE指标值的大量耗时使其聚类时间最长。由于并行实现的特点,本文提出的PBK-means算法所需聚类时间最少,通过权衡距离与密度,在保证聚类效果的前提下避免了SSE指标的计算耗时。在面对二分类任务时,PBK-means算法略优于DCK-means算法,明显优于WK-means算法和MWK-means算法,得到的初始聚类中心在执行K-means算法时迭代次数明显小于其他算法。 由于标签信息的缺乏,无监督学习在数据挖掘中越来越重要,聚类在网络入侵检测、自然灾害监测等方面有广泛的应用。本文提出一种PBK-means算法,根据数据分布情况对数据集进行分类,将距离和密度相结合从而快速处理中小型规模的数据集。实验结果表明,该算法面对大型数据集时在效率和精度方面都有较好的表现。为获得最佳初始聚类中心,将PBK-means算法与Mapreduce框架相结合以及寻找更好的中心点合并策略将是后续研究的内容。2 PBK-means算法
2.1 基本定义

2.2 并行二分原则
2.3 最大权重原则
2.4 算法时间复杂度
3 实验数据
3.1 实验数据集参数

3.2 实验结果







4 结束语
