基于遗传算法的钠冷快堆堆芯流量分区优化设计方法
2020-09-16王晓坤齐少璞张东辉
王晓坤,王 端,齐少璞,胡 赟,张东辉
(1.中国原子能科学研究院 反应堆工程技术研究部,北京 102413;2.核工业研究生部,北京 102413)
压水堆采用开式组件,主要通过堆芯功率展平实现堆芯出口温度展平,获得尽可能高的堆芯平均出口温度。钠冷快堆采用封闭组件,展平堆芯出口温度的方法既有功率展平,又有流量分区[1-3],通过组件管脚开孔实现组件间的流量分配,不同流量区的组件流量不同,高功率的组件流量大而低功率的组件流量小,从而使不同组件出口温度接近。
目前,国内外钠冷快堆堆芯流量分区优化设计的常用方法有枚举法、最大差值法、最小差值合并法[4-6],后两种是半经验方法。堆芯组件数和分区数少时,上述方法很有效,特别是枚举法可精确得到全局最优解。但随着反应堆功率水平的提高和组件数量的增加,传统方法的计算量将呈指数增长。
我国正在开展1 200 MW电功率的钠冷快堆(CFR1200)设计,初步方案中堆芯活性区有852盒燃料组件,使用传统方法进行流量分区优化设计的难度很大。未来我国还将设计建设更大规模的快堆电站,所以研究大型快堆电站堆芯流量分区的快速优化设计算法很有必要。
理论上钠冷快堆每盒组件的流量可互不相等,从而使所有组件的出口温度相等,获得最好的堆芯出口温度展平效果。实际工程中,组件种类越多制造成本越高,为以较少的组件种类达到较好的堆芯出口温度展平效果,需对堆芯进行流量分区,每一分区内各组件的流量相等,每一分区的流量由分区内最热(功率最高)组件决定。
对应确定的分区数,都存在一种最佳的分区方案,在满足最热组件的包壳温度和燃料温度均不超过限值的约束条件下,使堆芯总流量最小,同时堆芯出口平均温度最高。
实际反应堆设计中,堆芯出口平均温度是重要的设计目标参数,通常预先设定,于是流量分区的优化设计目标就转化为找到堆芯出口平均温度达到目标值的最小流量分区数以及相应的可行分区方案。通常,堆芯出口平均温度达到目标值且分区数等于最小分区数的分区方案不唯一,可在诸多可行方案中选择包壳温度裕量最大的作为最优方案。本文探讨使用遗传算法实现钠冷快堆堆芯流量分区优化设计的一般方法。
1 数学模型和算法设计
堆芯流量分区的数量通常不会太多,中国实验快堆(CEFR)堆芯(活性区)分4个流量区,百万千瓦级的反应堆堆芯流量分区也不超过30区,这就使从1开始逐个检验,找到最小可行分区数的方法成为一种有效的方法。此方法具体计算步骤[7]如下:
第1步,从c=1(分区数的下限)开始迭代;
第2步,对某一确定的分区数c,首先随机生成初始分区方案,即随机将每个组件分在1至c中的某一区;
第3步,用遗传算法求分区数c对应的堆芯活性区总流量Q的最小值Qmin。
Qmin的数学模型为:
(1)
其中:mi为第i个组件所属的流量区;n为堆芯组件数;Q为堆芯流量,是所有组件流量分区的函数;qi为第i个组件的流量;Pj为第j个组件的功率;Tc,limit为包壳温度限值;Tf,limit为燃料温度限值;函数g(P,Tc,limit,Tf,limit)为使功率为P的组件包壳最高温度不大于Tc且燃料最高温度不大于Tf所需的最小流量,约束条件表示第i个组件的流量qi由与其同流量区的组件中功率最大的组件决定。
考虑到本文主要讨论使用遗传算法实现堆芯流量分区设计的一般方法,而非对堆芯热工程序的研究,g(P,Tc,limit,Tf,limit)采用模型较为直观的单通道程序[8]。忽略燃料和包壳的轴向导热和环向导热,燃料和包壳的温度方程简化为极坐标下的扩散方程:
(2)
其中:ρ为密度,kg/m3;cp为比热容,J/(kg·K);T为温度,℃;t为时间,s;r为径向坐标,m;k为热导率,W/(m·K);φv为体积功率,W/m3,忽略包壳释热时,包壳控制方程中φv=0。
边界条件为:
(3)
其中:Tu为燃料表面温度,℃;Tci、Tco分别为包壳内壁和外壁温度,℃;Tm为冷却剂温度,℃;ku、kc分别为燃料和包壳热导率,W/(m·K);hg为堆芯-包壳间隙换热系数,W/(m2·K);h为包壳与冷却剂间对流换热系数,W/(m2·K);ru为燃料芯块外径,m;rci、rco分别为包壳内径和外径,m。
快堆燃料热导率经验公式[1]为:
ku=(0.042+2.71×10-4T)-1+
6.9×10-11T3
(4)
快堆包壳材料为不锈钢,计算中热导率取常数,即kc=21.46 W/(m·K)[8]。堆芯-包壳间隙换热系数取经验值,hg=5 678 W/(m2·K)[8]。包壳与冷却剂间对流换热系数由Seban-Shimazaki关系式[9]计算:
Nu=5+0.025Pe0.8
(5)
其中:Nu为Nusselt数;Pe为Peclet数。
忽略冷却剂导热,冷却剂的控制方程为:
(6)
其中:Az为流道截面积,m2;q为冷却剂流量,kg/s;z为轴向坐标,m。
燃料和包壳控制方程采用一阶中心差分,冷却剂控制方程采用一阶迎风差分,沿流动方向逐层求解,在每一层求解燃料温度、包壳温度、冷却剂温度的方程组。
组件内燃料棒间呈现一定的功率分布特征[10-11],组件内的流动特性按子通道分布[12],分析中以热通道因子表示功率和流量的不均匀性,即以组件内平均通道的计算值叠加组件热管因子后得到比焓升最大的子通道[11]。轴向功率分布使用平均值。
遗传算法的具体实现过程如下。
1) 编码。使用格雷码对组件流量区mi编码,每个组件所需的编码长度是log2c向上取整值,记为l,全部组件的流量区信息长度L=nl,即染色体长度。例如分为3个流量区需要2位格雷码,假设共有5个组件,其格雷码示例列于表1。
2) 计算适应度。适应度函数定义为:
F=Fit(Q(m1,…,mn))=

(7)
在不同的分区方案中,组件流量的最大值是相同的,由全堆芯功率最大的组件决定:
(8)
显然,maxqi是常数。适应度函数的定义保证了其函数值随Q单调递减。
3) 进行遗传操作:赌盘选择、双点交叉、基本位变异。
(1) 赌盘选择
首先,依次累计群体中各个体的适应度:
(9)
其中,M为群体中个体数量。
然后,在区间[0,SM]内产生均匀分布的随机数r;依次比较Si和r,第1个出现Si≥r的个体i被选为复制对象。
最后,重复该过程,直至产生M个新个体。
(2) 双点交叉
将M个个体随机配对,分为M/2组,设交叉概率为Pc,对每组个体在[0,1]内产生均匀分布的随机数r,若r≤Pc,执行双点交叉:在2个个体基因串中随机设置2个交叉点,交换2个个体在所设定的2个交叉点之间的部分。
(3) 基本位变异
设变异概率为Pm,对每个个体在[0,1]内产生均匀分布的随机数r,若r≤Pm,执行基本位变异:在该个体编码串中随机选择1位,改变其值。如果变异后得到无意义的个体(如要求分3个流量区,变异后某个组件的流量区为4),则认为变异失败,该个体恢复变异前的状态。
4) 执行最优个体保存。用迄今为止适应度最高的个体代替M个个体中适应度最低的个体。
至此,得到了新一代的M个个体。重复选择-交叉-变异的过程,并始终保留迄今为止的最优个体,直至满足收敛准则,即求出Qmin为止。
第4步,比较Qmin和Qr。Qr为堆芯流量的目标值,其定义的推导过程如下。
首先,堆芯出口平均温度Tout与堆芯总流量Q的关系为:
Tout=Tin+P/Qcp
(10)
式中:Tin为堆芯入口温度;P为堆芯功率。
通过改变堆芯流量区的划分,可得到Q的极小值Qmin和Tout的极大值Tout,max,Qmin和Tout,max满足:
Tout,max=Tin+P/Qmincp
(11)
以Tout,r为堆芯出口平均温度的设计目标值,其对应的堆芯流量即为Qr,当Tout,max≥Tout,r时,有Qmin≤Qr,两者是等价的。
若Qmin>Qr,则令c=c+1,转到第2步;否则,Qmin≤Qr,此时c值即为最小分区数,对应的分区方案即为最优分区方案。
2 算例分析
2.1 CEFR堆芯流量分区分析
CEFR堆芯活性区共81盒燃料组件,分4个流量区,CEFR堆芯功率分布和流量分区轴对称,图1为1/2堆芯的功率分布和流量分区。图中只给出了燃料组件,其他组件的冷却剂流量需根据实际情况采取合适的方法另行计算。
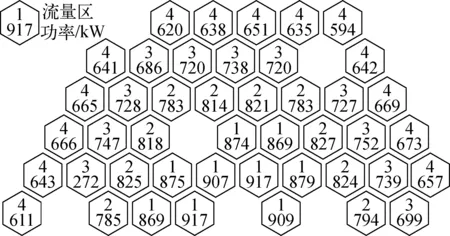
图1 CEFR 1/2堆芯流量分区和功率分布[12]Fig.1 CEFR 1/2 core flow zone and power distribution[12]
采用本文方法计算CEFR流量分区,分4区,每代的样本数为100,交叉概率为0.2,变异概率为0.05,计算结果与图2所示原设计结果一致。

反复计算统计,对于CEFR流量分区问题,遗传算法计算时间与枚举法计算时间的比在0.5~1之间,对于CEFR这样规模的问题,相比传统算法,遗传算法在计算时间上没有明显优势。

图2 CFR1200 1/6堆芯功率分布Fig.2 CFR1200 1/6 core power distribution
2.2 CFR1200堆芯流量分区设计

根据堆芯热工设计的结果,由于参数不确定性(包括输入参数中功率计算的不确定性以及制造公差、运行参数偏差、经验关系式的试验误差等)引起的燃料温度相对于名义值的均方根偏差σf为76 ℃,由于参数不确定性引起的包壳最高温度相对名义值的均方根偏差σc为16 ℃。高燃耗下快堆燃料熔点为2 630 ℃,正常运行的包壳温度限值为700 ℃[13-14]。考虑设计不确定性,燃料温度和包壳温度分别取3σ置信水平,并叠加一定的设计裕量,流量分区优化设计的边界条件确定为燃料中心温度不超过2 100 ℃和包壳中壁温度不超过630 ℃,同时以活性区平均出口温度不小于569 ℃为目标进行优化计算。使用遗传算法,每代的样本数为400,交叉概率为0.3,变异概率为0.05。从活性区流量分区数等于1开始检验,当活性区流量分区数等于8时,活性区出口平均温度为569.5 ℃,流量为2 166 kg/s,达到预定的活性区出口平均温度目标值。图3为堆芯流量分8区时的分区方案。
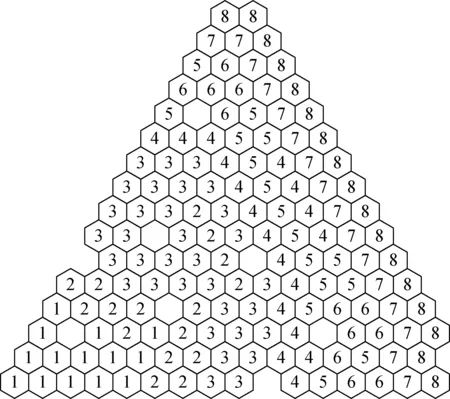
图3 CFR1200堆芯8区流量分区方案Fig.3 CFR1200 core 8-zone flow zoning solution
对输入参数做敏感性分析。随机选择5%的组件(7盒),将其功率增大10%,将增加的功率按功率比例分配到其他135盒组件,保持全堆总功率不变,重复流量分区计算。结果表明,当分区数达到8时,活性区出口平均温度达到优化目标。选取的组件不同,活性区出口平均温度的变化范围不超出2 ℃,具体的分区方案可能发生变化,特别是随机选中的组件为原方案某一分区的最热或最冷组件时,变化较为明显。由此证明了分析结果的稳定性,也说明了流量分区问题本身的稳定性。
至此,解决了CFR1200的堆芯流量分区优化设计问题。
进一步研究了不同分区数所能达到的活性区最小流量和活性区最大出口平均温度的关系,如图4所示。分析发现,活性区流量分区数越大,增加分区数对减小总流量和提高出口平均温度的贡献越小,结合经济性和安全性,适中的分区数应是较为理想的。

图4 不同分区数对应的活性区总流量和活性区出口温度Fig.4 Total active zone flow and active zone exit temperature for different numbers of zones
3 结论
钠冷快堆堆芯流量分区是堆芯热工设计的重要内容,随着反应堆功率的提高,传统方法的计算规模呈指数增长,本文通过建立数学模型,采用遗传算法解决了钠冷快堆堆芯流量分区的快速优化设计问题,为钠冷快堆堆芯流量分区优化设计提供了完全基于数学过程的设计方法。该方法可推广到采用封闭组件的反应堆堆芯流量分区设计。
通过CEFR算例验证了基于遗传算法的钠冷快堆堆芯流量分区优化设计方法的有效性,并应用于CFR1200,得到了活性区流量分区优化设计方案。进一步研究了CFR1200活性区总流量、平均出口温度和流量分区数的关系,得到了关系曲线。
